






Text2SQL技术的兴起,标志着自然语言处理(NLP)与数据库管理的融合进入了一个新的阶段。
这种技术使得用户能够使用自然语言查询来代替传统的SQL查询语句,极大地简化了数据检索过程。以下是Text2SQL技术的一些关键优势:
1. 提高效率:用户无需具备深厚的SQL知识即可执行复杂的数据库查询,从而节省了学习和编写查询语句的时间。
2. 增强可访问性:Text2SQL降低了技术门槛,使得非技术背景的用户也能轻松访问和分析数据。
3. 促进决策制定:通过快速准确地从大量数据中提取有用信息,Text2SQL支持更快的决策过程。
4. 改善用户体验:自然语言查询更符合人类的交流习惯,使得与数据库的交互变得更加直观和自然。
5. 减少错误:自动将自然语言转换为SQL语句可以减少手动编写查询时可能出现的错误。
6. 支持复杂查询:Text2SQL工具能够理解和处理复杂的查询要求,包括多表连接、条件筛选和数据聚合等。
7. 适应多种数据库系统:这些工具通常设计有良好的兼容性,能够与多种关系数据库管理系统(RDBMS)如MySQL、PostgreSQL、Oracle等进行交互。
8. 推动数据驱动的文化:通过简化数据访问过程,Text2SQL鼓励更多的数据探索和创新,有助于形成数据驱动的组织文化。
9. 集成和扩展性:Text2SQL技术可以轻松集成到现有的数据分析流程和业务智能工具中,支持数据的进一步处理和可视化。
10. 持续学习和优化:随着机器学习模型的不断训练和优化,Text2SQL工具能够不断适应用户的需求,提供越来越准确的查询结果。
综上所述,Text2SQL技术不仅为数据检索带来了革命性的变革,也为数据分析和商业智能领域提供了强大的支持。随着技术的不断进步,我们可以期待在未来看到更多创新的应用和改进。
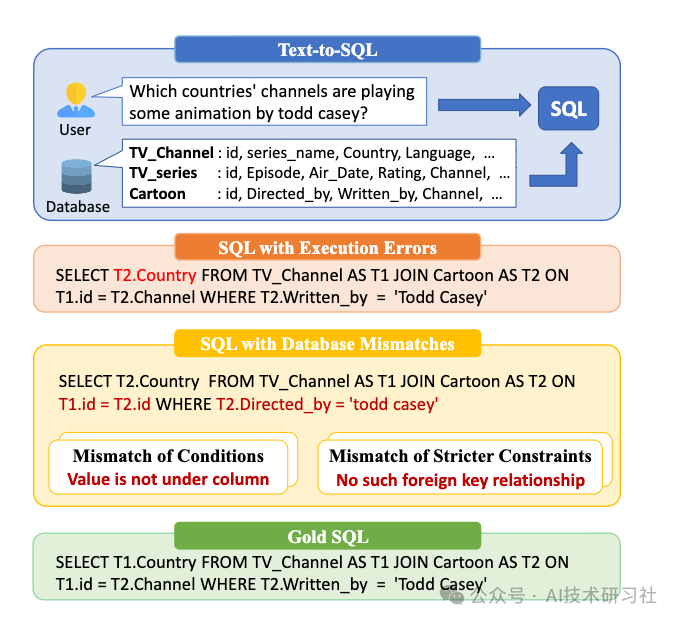
但是,我们遇到的最重大挑战之一是缺乏高效的 Text2SQL 系统所需的丰富上下文和元数据。

今天,我们介绍一个框架 — Vanna AI — 一个用于 SQL 生成、执行和可视化的开源 Python RAG(检索增强生成)框架。Vanna 是基于 Python 的 AI SQL 副驾驶。我们的初始用户是精通数据的数据分析师、数据科学家、工程师和使用 Vanna 自动编写复杂 SQL 的类似人员。
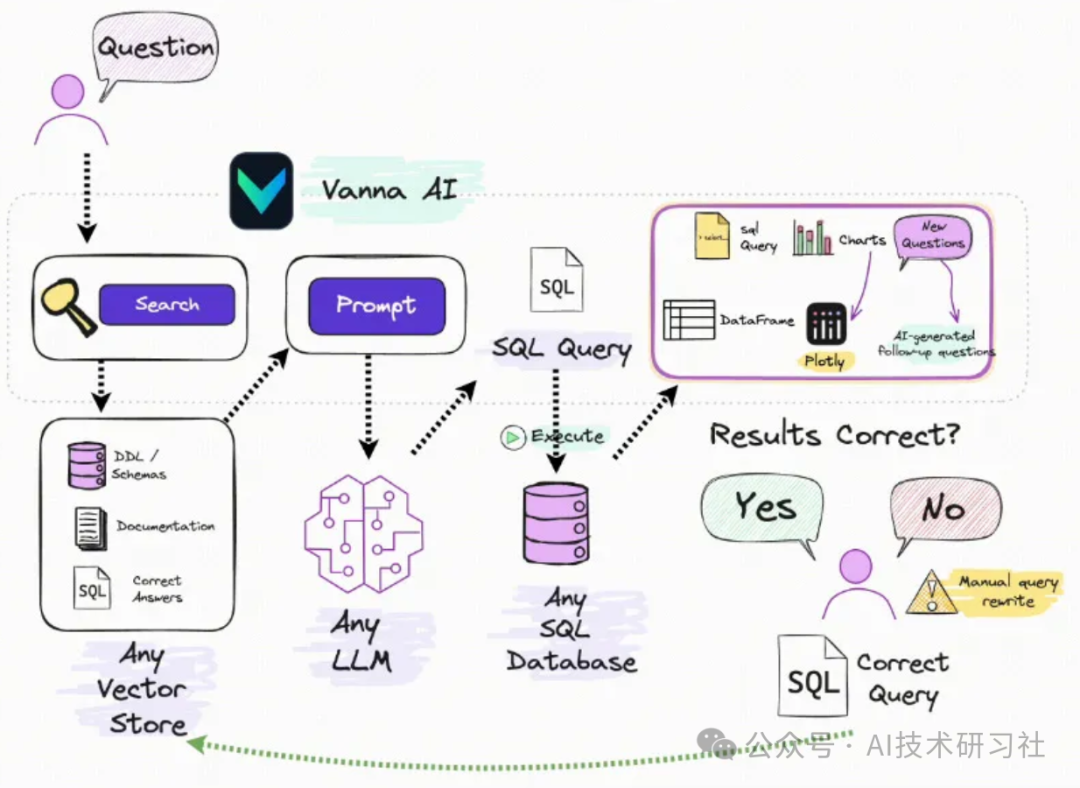
Vanna 通过两个简单的步骤进行操作 — 在您的数据上训练 RAG“模型”,然后提出返回 SQL 查询的问题。这些查询可以配置为在您的数据库上自动运行。
Vanna 在编写 SQL 方面明显优于使用 ChatGPT 或类似工具,因为我们在您的数据上训练特定的 Vanna 模型。但 Vanna 的有效性取决于您训练它的程度。我们将深入探讨 Vanna 的工作原理以及如何有效地训练它,以便它能够最好地回答您的问题。下面是一个使用的简单示例:
!pip install vanna
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='chinook', api_key=vanna.get_api_key('my-email@example.com'))
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask('What are the top 10 artists by sales?')
from vanna.flask import VannaFlaskApp
VannaFlaskApp(vn).run()
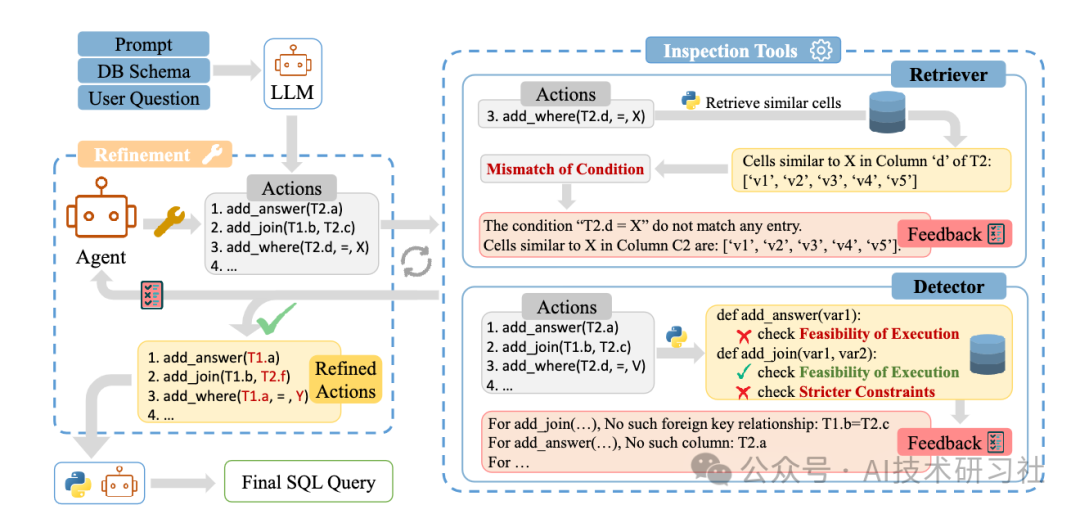
当您向 Vanna 提出问题时,以下是处理流程的总结:
-
搜索类似问题:系统首先在训练集中搜索与您问题类似的历史问题。
-
使用验证的 SQL:如果找到类似问题,系统会将这些问题中已验证的 SQL 语句传递给 Vanna 模型。
-
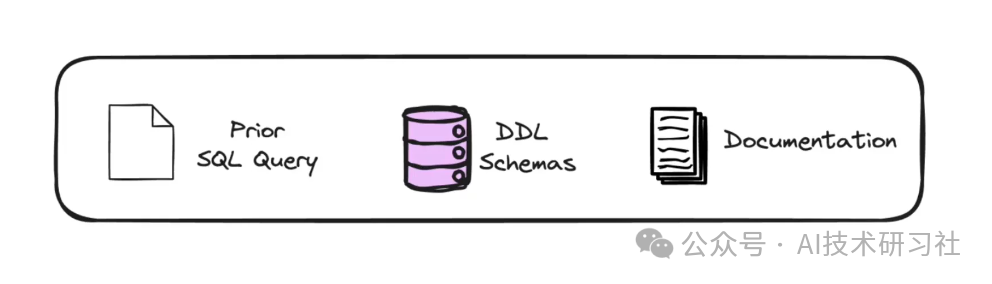
处理无相似问题:如果没有找到类似问题,系统会传入数据定义语言(DDL)、相关文档或引导查询。
-
生成 SQL:针对您的数据库架构,Vanna 模型生成相应的 SQL 语句,这是模型的核心功能所在。
-
验证 SQL:生成的 SQL 语句会被执行以验证其准确性。如果验证成功,该语句将被添加到训练数据中。
-
人工干预:如果 SQL 验证未通过,专业的分析师会介入,对 SQL 语句进行修正,并将其纳入训练数据。
-
持续学习:随着时间的推移,Vanna 通过不断学习和修正,增强了对数据库架构的理解,提高了问题解答的准确率。
这个过程展示了 Vanna 如何结合机器学习和人工审核,以提供准确的 SQL 查询生成服务,同时不断优化自身的性能和响应能力。
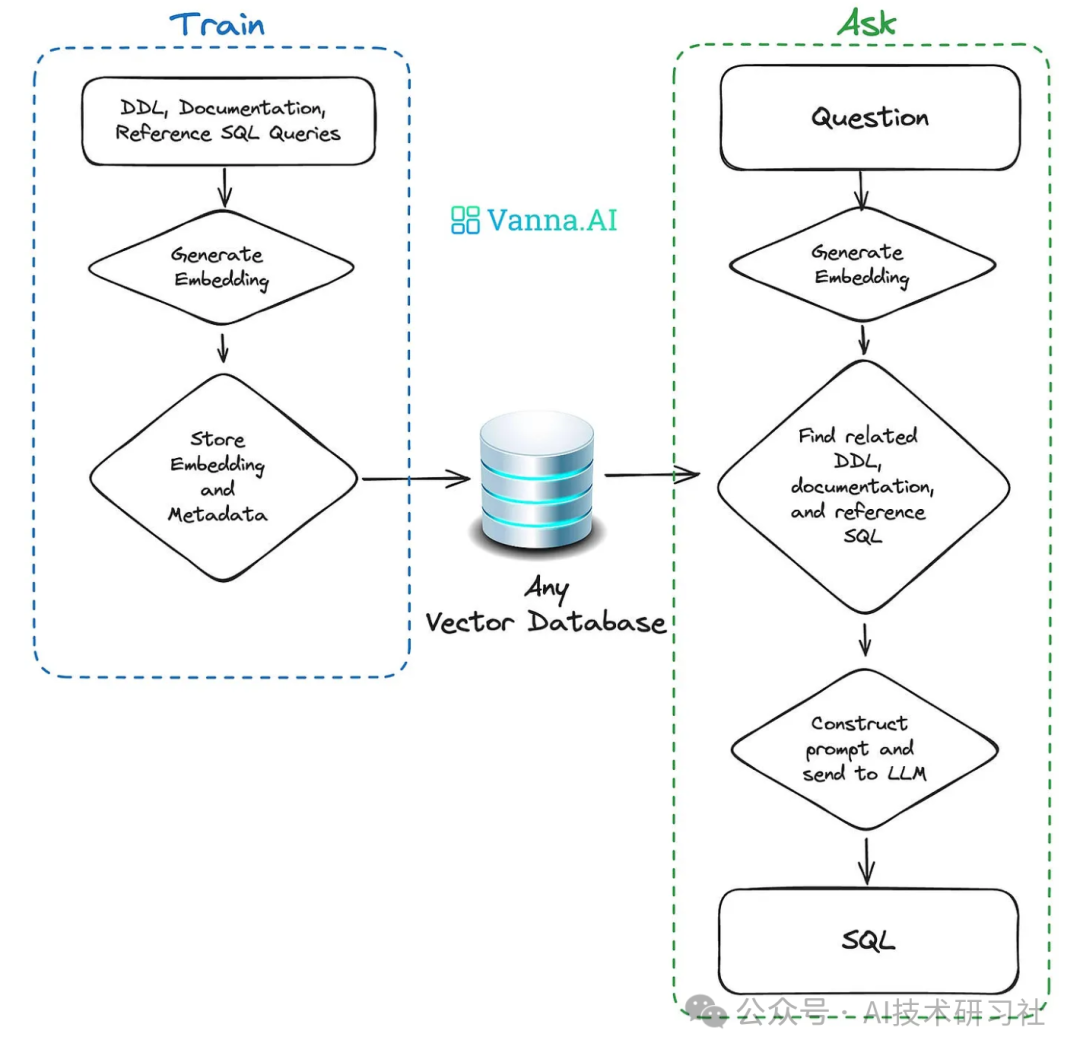
Vanna 使用一种称为 LLMs(大型语言模型)的生成式 AI。简而言之,这些模型是在大量数据语料库(包括一堆在线可用的 SQL 查询)上训练的,并通过预测对提示的响应中最有可能的下一个单词或 “标记” 来工作。Vanna 优化了提示(通过向量数据库使用嵌入搜索)并微调了 LLM 模型以生成更好的 SQL。
Vanna 正在使用和试验一系列不同的 LLMs 以获得最准确的结果。OpenAI 的 GPT 模型通常跑赢大盘,但在某些情况下,谷歌的 Bard、Meta 的 LLAMA 和 Falcon 模型是最好的。
我们可以运行代码,从我们的问题 “销售额排名前 10 的客户是什么?” 生成 SQL。这会将问题发送给 Vanna,Vanna 使用 AI 生成 SQL,并将 SQL 发回。以下是有关 Vanna 工作原理的更多详细信息。
sql = vn.generate_sql(question='What are the top 10 customers by Sales?')
print(sql)
得到的结果是:
SELECT customer_name,
total_sales
FROM (SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales,
row_number() OVER (ORDER BY sum(l.l_extendedprice * (1 - l.l_discount)) desc) as row_num
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name)
WHERE row_num <= 10;
你只需要训练一次。除非您要添加更多训练数据,否则不要再次训练。
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
# vn.train(plan=plan)
下面给一个基于OpenAI完整的示例:使用 OpenAI 进行演示。
from vanna.openai import OpenAI_Chat
from vanna.qdrant import Qdrant_VectorStore
from qdrant_client import QdrantClient
class MyVanna(Qdrant, OpenAI_Chat):
def __init__(self, config=None):
Qdrant_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={
'client': QdrantClient(...),
'api_key': sk-...,
'model': gpt-4-...,
})
实例化 Vanna 代理后,您可以将其连接到您选择的任何 SQL 数据库。
vn.connect_to_postgres(host='my-host', dbname='my-dbname', user='my-user', password='my-password', port='my-port')
现在可以使用 SQL 训练并开始查询数据库。
# You can add DDL statements that specify table names, column names, types, and potentially relationships
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
# You can add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")
# You can also add SQL queries to your training data. This is useful if you have some queries already laying around.
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")
# You can remove training data if there's obsolete/incorrect information.
vn.remove_training_data(id='1-ddl')
# Whenever you ask a new question, Vanna will retrieve 10 most relevant pieces of training data and use it as part of the LLM prompt to generate the SQL.
vn.ask(question="<YOUR_QUESTION>")
在数据分析领域,Vanna 以其独特的愿景和创新路径,正逐步成为 AI 数据分析师的首选工具。Vanna 的目标不仅仅是简化数据分析过程,而是要重新定义整个领域,通过其先进的 AI 技术,提供与人类数据分析师相媲美的准确性、交互性和自主性。
Vanna 的发展比预期快了一个月。这段时间内,用户数量增长了 600%。一些大型企业,包括财富 1000 强公司,已经开始使用 Vanna 进行数据查询。这表明 Vanna 已经成为一个可靠的解决方案,能够处理抽象的数据库交互。
为了提高可访问性和通用性,Vanna 决定开源其框架。此外,他们正在开发一个基于云的 Web 应用程序,方便用户使用并覆盖更广泛的用户群体。Vanna 未来的计划包括整合大语言模型 (LLMs)。这表明该公司致力于跟上人工智能技术的进步,并为用户提供更多选择。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试,不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









