






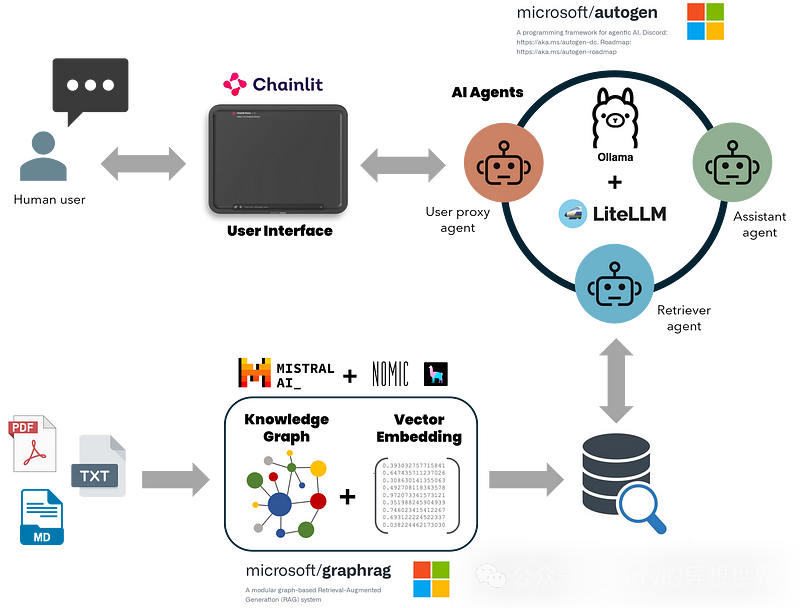
与依赖向量相似性搜索的传统 RAG 方法不同,GraphRAG 从原始文本构建结构化知识图谱,捕捉实体、关系和关键主张。这可以增强 LLM 理解和综合复杂数据集的能力,从而产生更准确和具有上下文依据的响应。将 GraphRAG 的检索增强生成(RAG)优势与 AutoGen AI 代理的对话和任务导向功能相结合,产生了能够高效处理详细查询、生成和执行代码、创建多页科学报告以及进行数据分析的强大 AI 助手。此外,Ollama 或 LM Studio 等离线本地 LLM 与 GraphRAG 和 AutoGen 的结合,确保了成本效益和安全的数据处理。本地 LLM 消除了与在线 LLM 相关的高成本和隐私风险,将敏感数据保留在组织内,并减少运营开支。
以下是该应用程序的关键组件:
- GraphRAG 的知识搜索方法通过函数调用与 AutoGen 代理集成。
- GraphRAG(本地和全球搜索)配置为支持来自 Ollama 的本地模型进行推理和嵌入。
- AutoGen 扩展以支持通过 Lite-LLM 代理服务器与非 OpenAI LLM 的函数调用。
- Chainlit UI 处理连续对话、多线程和用户输入设置。
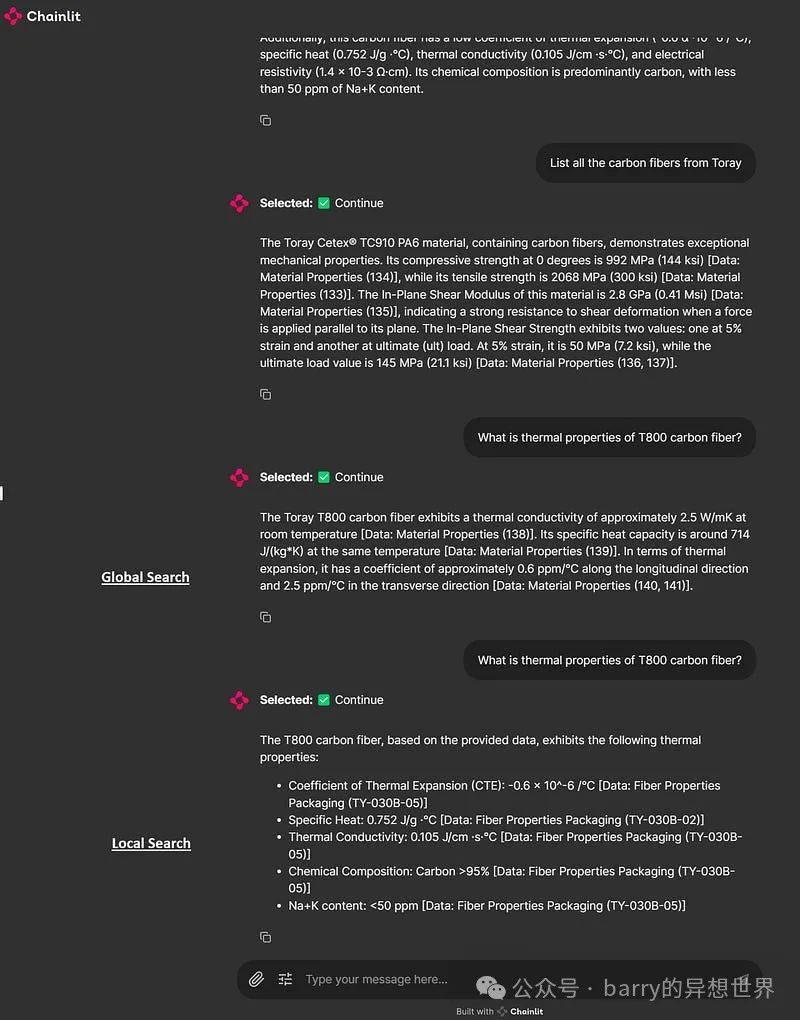
我通过询问与 ABAQUS 文档(一个有限元分析工程软件)和来自供应商 Toray 的碳纤维技术数据表相关的问题来测试这个应用程序。考虑到我在材料科学和计算建模方面的背景,这些是自然的选择。我渴望从科学期刊和该领域的数据中构建更复杂的知识图谱,测试高级工程代码生成任务,并利用对话助手来头脑风暴我专业领域的科学主题。应用程序的界面如下所示。
开发是在 Linux 环境中进行的,使用 Windows 子系统 Linux (WSL) 和 Windows 11 PC 上的 Visual Studio Code,配置为 i9 13 代处理器、64 GB RAM 和 24 GB Nvidia RTX 4090。为了获得最佳的应用开发和测试体验,建议使用 Linux 发行版或 WSL。我没有在原生 Windows 环境下进行测试。有关安装 WSL 和设置 Python 及 Conda 环境的指南,请参考本文 (这里)。本文末尾提供了额外的参考资料和相关信息。
这是源代码库的 链接。现在,让我们开始吧!!
一、安装模型依赖和克隆仓库
从Ollama安装语言模型以进行推理和嵌入
# Mistral用于GraphRAG推理
ollama pull mistral
# Nomic-Embed-Text用于GraphRAG嵌入
ollama pull nomic-embed-text
# LLama3用于Autogen推理
ollama pull llama3
# 在本地服务器上托管Ollama: http://localhost:11434
ollama serve
创建一个conda环境并安装这些依赖项
# 创建并激活一个conda环境
conda create -n RAG_agents python=3.12
conda activate RAG_agents
# Lite-LLM代理服务器用于Ollama
pip install 'litellm[proxy]'
# 安装Ollama
pip install ollama
# Microsoft AutoGen
pip install pyautogen "pyautogen[retrievechat]"
# Microsoft GraphRAG
pip install graphrag
# 文本-令牌编码器-解码器
pip install tiktoken
# Chainlit Python应用程序
pip install chainlit
# 克隆我的GitHub仓库
git clone https://github.com/karthik-codex/autogen_graphRAG.git
# (附加) 将PDF文件转换为Markdown以供GraphRAG使用
pip install marker-pdf
# (附加) 仅在您安装了Marker-pdf的情况下,因为它默认删除GPU CUDA支持
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
您将在我的GitHub仓库中找到以下文件。
-
/requirements.txt— 包含上述所有软件包的列表 -
/utils/settings.yaml— 包含用于GraphRAG离线嵌入和索引的Mistral 7B和Ollama的Nomic-Text-Embedding的LLM配置。您将使用此文件替换在您的工作目录中首次初始化GraphRAG时创建的文件。 -
/utils/chainlit_agents.py— 包含类定义,包括AutoGen的助手和用户代理。这允许跟踪多个代理并在UI中显示它们的消息。(感谢Chainlit团队构建的模板。) -
/utils/embedding.py—包含用于Ollama的GraphRAG嵌入的修改过的嵌入函数,以便进行本地搜索查询。您将使用此文件替换GraphRAG包内的文件(更多信息如下) -
utils/openai_embeddings_llm.py—包含用于Ollama的GraphRAG索引和嵌入的修改过的嵌入函数。您将使用此文件替换GraphRAG包内的文件(更多信息如下)。 -
/appUI.py—包含设置代理、定义GraphRAG搜索功能、跟踪和处理消息以及在Chainlit UI中显示它们的主要异步函数。 -
/utils/pdf_to_markdown.py— 附加文件,包含将PDF文件转换为Markdown文件以供GraphRAG摄取的函数。
二、创建一个GraphRAG知识库
在仓库的根文件夹中初始化 GraphRAG
#make a new folder "input" to place your input files for GraphRAG (.txt or .md)
mkdir -p ./input
# Initialize GraphRAG to create the required files and folders in the root dir
python -m graphrag.index --init --root .
# Move the settings.yaml file to replace the one created by GraphRAG --init
mv ./utils/settings.yaml ./
配置 GraphRAG 设置以支持来自 Ollama 的本地模型
以下是 settings.yaml 中的一个代码片段,展示了创建索引和嵌入的 LLM 配置。GraphRAG 需要 32k 的上下文长度进行索引,因此选择了 Mistral 作为模型。对于嵌入,选择了 Nomic-embed-text,尽管您可以尝试来自 Ollama 的其他嵌入。无需设置 ${GRAPHRAG_API_KEY},因为访问这些本地模型的端点并不需要。
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: mistral
model_supports_json: true
api_base: http://localhost:11434/v1
.
.
.
embeddings:
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: nomic_embed_text
api_base: http://localhost:11434/api
.
.
.
input: #Change input file pattern to.md, or .txt
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.md$"
您可以在根目录的“input”文件夹中指定包含输入文件的文件夹。可以使用文本和 markdown 文件。您可以使用 /utils/pdf_to_markdown.py 将 PDF 转换为 markdown 文件,然后将其放置在“input”文件夹中。处理多种文件格式的问题尚未解决,但这是一个可以解决的问题。
在运行 GraphRAG 进行索引、创建嵌入和执行本地查询之前,您必须修改位于 GraphRAG 包中的 Python 文件 openai_embeddings_llm.py 和 embedding.py。如果不进行此修改,GraphRAG 在创建嵌入时将抛出错误,因为它不会将 “nomic-embed-text” 识别为来自 Ollama 的有效嵌入模型。在我的设置中,这些文件位于 /home/karthik/miniconda3/envs/RAG_agents/lib/python3.12/site-packages/graphrag/llm/openai/openai_embeddings_llm.py 和 /home/karthik/miniconda3/envs/RAG_agents/lib/python3.12/site-packages/graphrag/query/llm/oai/embedding.py
您可以使用命令 sudo find / -name openai_embeddings_llm.py 定位这些文件。
创建嵌入和知识图谱。
最后,我们使用全局或局部搜索方法创建嵌入并测试知识图谱。完成嵌入过程后,您可以在 GraphRAG 工作目录的“output”文件夹中找到输出工件 (.parquet 文件) 和报告 (.json 和 .logs),在本例中,该文件夹是根文件夹。
# Create knowledge graph - this takes some time
python -m graphrag.index --root .
# Test GraphRAG
python -m graphrag.query --root . --method global "<insert your query>"
从终端启动 Lite-LLM 服务器并运行应用
下面是初始化服务器以运行应用的命令。我选择了 Llama3:8b 来测试这个应用。如果您的硬件允许,您可以使用更大的模型。有关 Lite-LLM 的更多信息,请访问此 链接。现在您可以从另一个终端运行应用程序。确保您在正确的 conda 环境中。
# start server from terminal
litellm --model ollama_chat/llama3
# run app from another terminal
chainlit run appUI.py
三、分解:appUI.py的核心组件
导入 Python 库
import autogen
from rich import print
import chainlit as cl
from typing_extensions import Annotated
from chainlit.input_widget import (
Select, Slider, Switch)
from autogen import AssistantAgent, UserProxyAgent
from utils.chainlit_agents import ChainlitUserProxyAgent, ChainlitAssistantAgent
from graphrag.query.cli import run_global_search, run_local_search
您将注意到从 chainlit_agents 导入了两个类。这些 AutoGen 代理的包装类使 Chainlit 能够跟踪它们的对话,并处理终止或其他用户输入。您可以在 这里 阅读更多信息。
配置 AutoGen 代理
AutoGen 代理通过 Lite-LLM 代理服务器利用来自 Ollama 的模型。这是必要的,因为 AutoGen 不支持通过非 OpenAI 推理模型进行函数调用。代理服务器使得可以使用 Ollama 模型进行函数调用和代码执行。
# LLama3 LLM from Lite-LLM Server for Agents #
llm_config_autogen = {
"seed": 40, # change the seed for different trials
"temperature": 0,
"config_list": [{"model": "litellm",
"base_url": "http://0.0.0.0:4000/",
'api_key': 'ollama'},
],
"timeout": 60000,
}
在聊天开始时实例化代理并输入用户设置
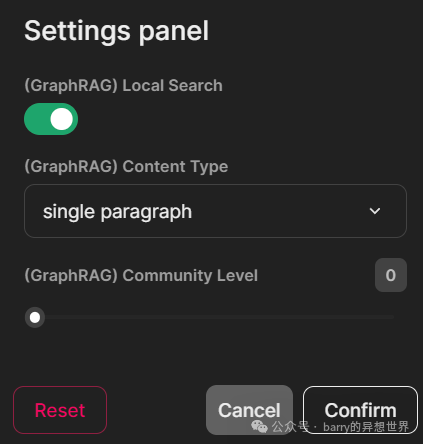
我创建了三个 Chainlit 小部件(开关、选择和滑块)作为用户设置,以选择 GraphRAG 搜索类型、社区级别和内容生成类型。当开关设置为开启时,开关小部件使用 GraphRAG 本地搜索方法进行查询。内容生成的选择选项包括“优先列表”、“单段落”、“多段落”和“多页报告”。滑块小部件选择社区生成级别,选项为 0、1 和 2。您可以在 这里 阅读有关 GraphRAG 社区的更多信息。
@cl.on_chat_start
async def on_chat_start():
try:
settings = await cl.ChatSettings(
[
Switch(id="Search_type", label="(GraphRAG) 本地搜索", initial=True),
Select(
id="Gen_type",
label="(GraphRAG) 内容类型",
values=["优先列表", "单段落", "多段落", "多页报告"],
initial_index=1,
),
Slider(
id="Community",
label="(GraphRAG) 社区级别",
initial=0,
min=0,
max=2,
step=1,
),
]
).send()
response_type = settings["Gen_type"]
community = settings["Community"]
local_search = settings["Search_type"]
cl.user_session.set("Gen_type", response_type)
cl.user_session.set("Community", community)
cl.user_session.set("Search_type", local_search)
retriever = AssistantAgent(
name="Retriever",
llm_config=llm_config_autogen,
system_message="""仅执行函数 query_graphRAG 来查找上下文。
当提供答案时输出 'TERMINATE'.""",
max_consecutive_auto_reply=1,
human_input_mode="NEVER",
description="检索代理"
)
user_proxy = ChainlitUserProxyAgent(
name="User_Proxy",
human_input_mode="ALWAYS",
llm_config=llm_config_autogen,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config=False,
system_message='''一个人类管理员。与检索器互动以提供任何上下文''',
description="用户代理"
)
print("设置代理。")
cl.user_session.set("Query Agent", user_proxy)
cl.user_session.set("Retriever", retriever)
msg = cl.Message(content=f"""你好!今天你想完成什么任务?
""",
author="User_Proxy")
await msg.send()
print("消息已发送。")
except Exception as e:
print("错误: ", e)
pass
我选择不使用 Chainlit 包装类来处理检索助手代理。这使我能够禁用对检索器输出的跟踪,并直接捕获来自 GraphRAG 函数的响应。原因是当响应通过检索器时,文本会失去格式,包括空格和段落缩进。当生成带有主标题和子标题的多页报告时,这个问题尤其明显。我可以通过绕过 Chainlit 包装并直接从 GraphRAG 函数检索输出来保留原始格式。您将看到我如何实现这一点。
更新输入设置的更改
此功能检测从设置中对选择、开关和滑块小部件所做的任何更改,以便在后续查询中反映这些更改。
@cl.on_settings_update
async def setup_agent(settings):
response_type = settings["Gen_type"]
community = settings["Community"]
local_search = settings["Search_type"]
cl.user_session.set("Gen_type", response_type)
cl.user_session.set("Community", community)
cl.user_session.set("Search_type", local_search)
print("on_settings_update", settings)
使用来自代理和用户的传入消息更新 UI。
这是应用程序的核心部分,它创建了一个包含两个代理的群聊,定义了一个“state_transition”函数来管理对话顺序,以及异步 RAG 查询函数。
您会注意到 INPUT_DIR ,ROOT_DIR, RESPONSE_TYPE, COMMUNITY 参数,这些参数根据布尔参数 LOCAL_SEARCH 被传递到本地和全局搜索 GraphRAG 查询函数中。ROOT_DIR, 被设置为 ’.’ — 如果您在不同的目录中初始化了 GraphRAG,请注意这一点。
异步函数 “query_graphRAG” 调用 GraphRAG 的全局或本地搜索方法。您会注意到在 async def query_graphRAG 函数内的行 await cl.Message(content=result.response).send() 直接从 RAG 查询中检索输出,并保持检索内容的文本格式。
@cl.on_message
async def run_conversation(message: cl.Message):
print("Running conversation")
CONTEXT = message.content
MAX_ITER = 10
INPUT_DIR = None
ROOT_DIR = '.'
RESPONSE_TYPE = cl.user_session.get("Gen_type")
COMMUNITY = cl.user_session.get("Community")
LOCAL_SEARCH = cl.user_session.get("Search_type")
print("Setting groupchat")
retriever = cl.user_session.get("Retriever")
user_proxy = cl.user_session.get("Query Agent")
def state_transition(last_speaker, groupchat):
messages = groupchat.messages
if last_speaker is user_proxy:
return retriever
if last_speaker is retriever:
if messages[-1]["content"].lower() not in ['math_expert','physics_expert']:
return user_proxy
else:
if messages[-1]["content"].lower() == 'math_expert':
return user_proxy
else:
return user_proxy
else:
pass
return None
async def query_graphRAG(
question: Annotated[str, 'Query string containing information that you want from RAG search']
) -> str:
if LOCAL_SEARCH:
result = run_local_search(INPUT_DIR, ROOT_DIR, COMMUNITY ,RESPONSE_TYPE, question)
else:
result = run_global_search(INPUT_DIR, ROOT_DIR, COMMUNITY ,RESPONSE_TYPE, question)
await cl.Message(content=result).send()
return result
for caller in [retriever]:
d_retrieve_content = caller.register_for_llm(
description="retrieve content for code generation and question answering.", api_style="function"
)(query_graphRAG)
for agents in [user_proxy, retriever]:
agents.register_for_execution()(d_retrieve_content)
groupchat = autogen.GroupChat(
agents=[user_proxy, retriever],
messages=[],
max_round=MAX_ITER,
speaker_selection_method=state_transition,
allow_repeat_speaker=True,
)
manager = autogen.GroupChatManager(groupchat=groupchat,
llm_config=llm_config_autogen,
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config=False,
)
# -------------------- 对话逻辑。编辑以根据您想完成的任务更改您的第一条消息。----------------------------- #
if len(groupchat.messages) == 0:
await cl.make_async(user_proxy.initiate_chat)( manager, message=CONTEXT, )
elif len(groupchat.messages) < MAX_ITER:
await cl.make_async(user_proxy.send)( manager, message=CONTEXT, )
elif len(groupchat.messages) == MAX_ITER:
await cl.make_async(user_proxy.send)( manager, message="exit", )
对于这个应用程序,我们只需要两个代理。您可以添加/修改代理并配置“state_transition”函数,以协调更复杂工作流中的对话发言者选择。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









