







一、语义分割
1、什么是语义分割
语义分割将图片中的每个像素分配到对应的类别。在目标检测问题中,我们一直使用方形边界框来标注和预测图像中的目标。语义分割(semantic segmentation)问题重点关注于如何将图像分割成属于不同语义类别的区域。与目标检测不同,语义分割可以识别并理解图像中每一个像素的内容:其语义区域的标注和预测是像素级的。
下图展示了语义分割中图像有关狗、猫和背景的标签。与目标检测相比,语义分割标注的像素级的边框显然更加精细。
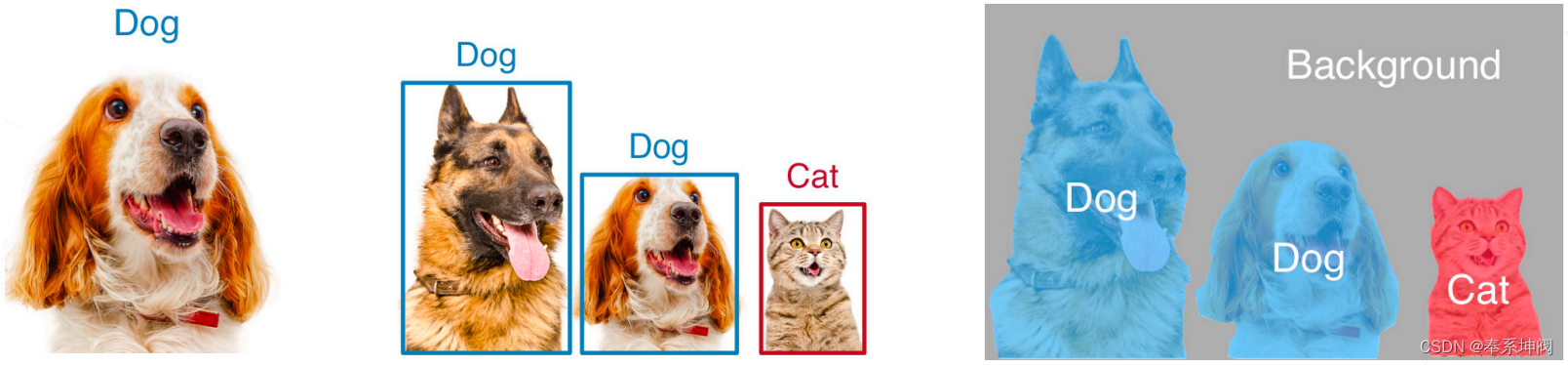
2、语义分割、图像分割和实例分割
计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割(image segmentation)和实例分割(instance segmentation)。我们在这里将它们同语义分割简单区分一下。
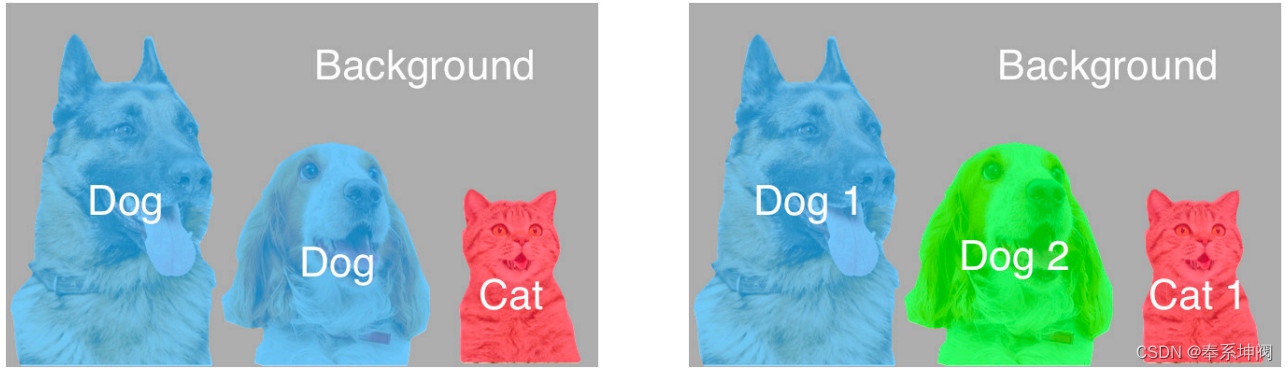
(1)图像分割:图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。以前面的图像作为输入,图像分割可能会将狗分为两个区域:一个覆盖以黑色为主的嘴和眼睛,另一个覆盖以黄色为主的其余部分身体。
(2)实例分割:实例分割也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的目标实例。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。
3、语义分割的应用
(1)背景虚化

(2)路面分割

4、PASCAL VOC2012数据集介绍
PASCAL VOC2012是最重要的语义分割数据集之一。PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。
PASCAL VOC2012数据集有自己的格式,名为VOC格式,VOC格式是一种应用十分广泛的格式。在Pascal VOC数据集中主要包含20个目标类别,下图展示了所有类别的名称以及所属超类。
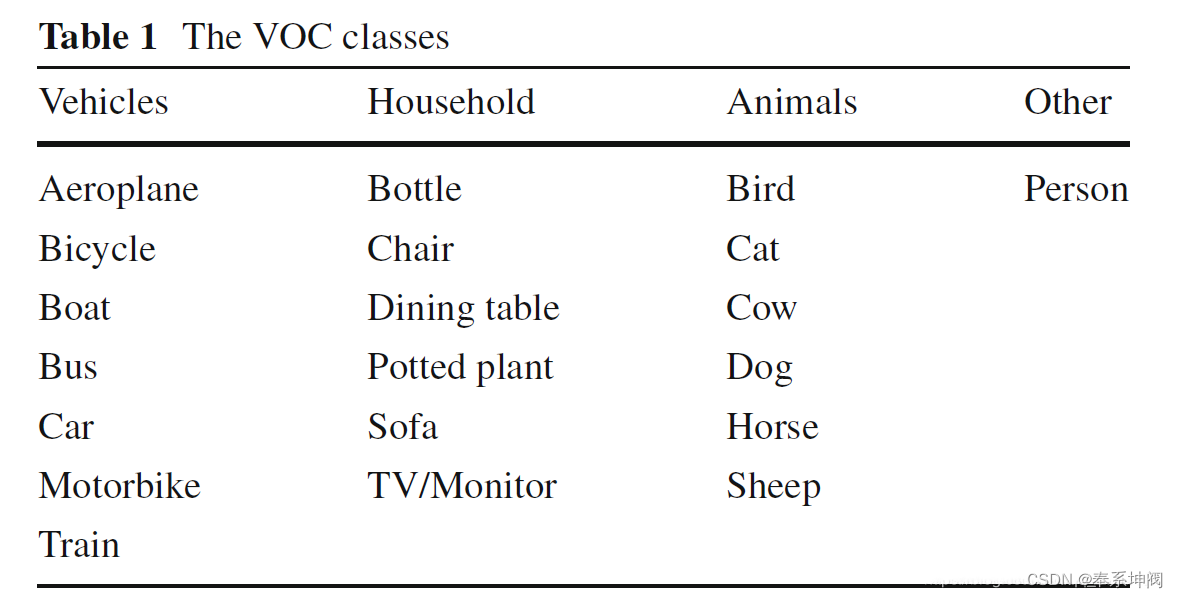
PASCAL VOC2012数据集下载地址:The PASCAL Visual Object Classes Challenge 2012 (VOC2012) http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
打开链接后如下图所示,只用下载 training/validation data(2GB tar file) 文件即可。

下载后将文件进行解压,解压后的文件目录结构如下所示:
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)标签中颜色相同的像素属于同一个语义类别
└── SegmentationObject 实例分割png图(基于目标)
注意,train.txt, val.txt 和 trainval.txt 文件里记录的是对应标注文件的索引,每一行对应一个索引信息。
二、代码实现
import os
import torch
import torchvision
from d2l import torch as d2l1、下载并解压数据集
数据集的tar文件大约为2GB,所以下载可能需要一段时间。
d2l.DATA_HUB['voc2012'] = (d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')2、读取数据集
下面将read_voc_images函数定义为将所有输入的图像和标签读入内存。下面是李沐老师的代码,在实际运行中可能会因为torchvision版本问题出现“RuntimeError: No such operator image::read_file”报错:
def read_voc_images(voc_dir, is_train=True):
"""读取所有VOC图像并标注"""
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = torchvision.io.image.ImageReadMode.RGB
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(torchvision.io.read_image(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg')))
labels.append(torchvision.io.read_image(os.path.join(
voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[14], line 17
13 labels.append(torchvision.io.read_image(os.path.join(
14 voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
15 return features, labels
---> 17 train_features, train_labels = read_voc_images(voc_dir, True)
Cell In[14], line 11
9 features, labels = [], []
10 for i, fname in enumerate(images):
---> 11 features.append(torchvision.io.read_image(os.path.join(
12 voc_dir, 'JPEGImages', f'{fname}.jpg')))
13 labels.append(torchvision.io.read_image(os.path.join(
14 voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
15 return features, labels
File d:\programme\Anaconda\envs\d2l\lib\site-packages\torchvision\io\image.py:222, in read_image(path, mode)
206 def read_image(path: str, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:
207 """
208 Reads a JPEG or PNG image into a 3 dimensional RGB Tensor.
209 Optionally converts the image to the desired format.
(...)
220 output (Tensor[image_channels, image_height, image_width])
221 """
--> 222 data = read_file(path)
223 return decode_image(data, mode)
File d:\programme\Anaconda\envs\d2l\lib\site-packages\torchvision\io\image.py:42, in read_file(path)
31 def read_file(path: str) -> torch.Tensor:
32 """
33 Reads and outputs the bytes contents of a file as a uint8 Tensor
34 with one dimension.
(...)
40 data (Tensor)
41 """
---> 42 data = torch.ops.image.read_file(path)
43 return data
File d:\programme\Anaconda\envs\d2l\lib\site-packages\torch\_ops.py:63, in _OpNamespace.__getattr__(self, op_name)
60 # Get the op `my_namespace::my_op` if available. This will also check
61 # for overloads and raise an exception if there are more than one.
62 qualified_op_name = '{}::{}'.format(self.name, op_name)
---> 63 op = torch._C._jit_get_operation(qualified_op_name)
64 # let the script frontend know that op is identical to the builtin op
65 # with qualified_op_name
66 torch.jit._builtins._register_builtin(op, qualified_op_name)
RuntimeError: No such operator image::read_file我后面使用了Python PIL库来进行读取和转换操作,问题得到解决,关于PIL的各模块可参考博客Python图像处理PIL各模块详细介绍:
from PIL import Image
import os
def read_voc_images(voc_dir, is_train=True):
"""读取所有VOC图像并标注"""
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = 'RGB'
transform = torchvision.transforms.ToTensor()
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(transform(Image.open(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg'))))
labels.append(transform(Image.open(os.path.join(
voc_dir, 'SegmentationClass', f'{fname}.png')).convert(mode)))
if(i==0):
print(Image.open(os.path.join(voc_dir, 'JPEGImages', f'{fname}.jpg')).mode)
print(Image.open(os.path.join(voc_dir, 'SegmentationClass', f'{fname}.png')).convert(mode).mode)
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)RGB
RGB下面我们绘制前5个输入图像及其标签。在标签图像中,白色和黑色分别表示边框和背景,而其他颜色则对应不同的类别。
n = 5
imgs = train_features[0:n] + train_labels[0:n]
imgs = [img.permute(1,2,0) for img in imgs]
d2l.show_images(imgs, 2, n)array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>], dtype=object)
3、列举RGB颜色值与类名
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']4、构建RGB颜色值到类别索引的映射
通过上面定义的两个常量,我们可以方便地查找标签中每个像素的类索引。我们定义了voc_colormap2label函数来构建从上述RGB颜色值到类别索引的映射,而voc_label_indices函数将RGB值映射到在Pascal VOC2012数据集中的类别索引。
def voc_colormap2label():
"""构建从RGB到VOC类别索引的映射"""
colormap2label = torch.zeros(256 ** 3, dtype=torch.long)
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
return colormap2label
def voc_label_indices(colormap, colormap2label):
"""将VOC标签中的RGB值映射到它们的类别索引"""
colormap = colormap.permute(1, 2, 0).numpy().astype('int32') # 传进来的是channel,h,w 然后permute之后是h,w,channel
idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256
+ colormap[:, :, 2]) # 3个通道,每个通道大小为h*w,R*256*256*256 + G*256*256 + B*256,然后相加
return colormap2label[idx]例如,在第一张样本图像中,飞机头部区域的类别索引为1,而背景索引为0。
y = voc_label_indices(train_labels[0], voc_colormap2label())
y[105:115, 130:140], VOC_CLASSES[1](tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]),
'aeroplane')未完待续...


















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









