






数据集介绍
1.背景
根据《中国科学:信息科学》期刊上的一篇文章,量子通信包括多种协议与应用类型: 基于量子隐形传态与量子存储中继等技术,可实现量子态信息传输,进而构建量子信息网络,已成为当前科研热点,但距实用化仍然较远。
2. 数据集介绍
相关信息:复旦大学量子数据集是收集了1987到2020年3月份的基本专利信息
数据集列名:|序号|专利名称|专利名称中文翻译| 专利名称英文翻译| 摘要| 摘要中文翻译|摘要英文翻译| 权利要求主权项|权利要求项数|独立权利要求项数|PDF全文页数|申请号|申请日|公开号|公开日|首次公开日|国家/地区|专利类型|授权日|失效日|优先权|最早优先权日|国际申请|国际公布|进入国家阶段日|申请人|申请人归属地|申请人地址|申请人类型|申请人数量|专利权人|专利权人归属地|专利权人地址|专利权人类型|专利权人数量|发明人|发明人数量|审查员|代理人|代理机构|IPC分类号|主IPC分类号|IPC分类号数量|CPC分类号|主CPC分类号|CPC分类号数量|外观设计分类号|法律效力|是否曾经授权|公知公用状态|存活期|预期剩余寿命|转让状态|许可状态|质押状态|复审/无效状态|诉讼状态|基本专利族|基本专利族专利数量|本专利引用|本专利引用数量|本专利被引|本专利被引用数量|
整体架构流程

数据处理流程
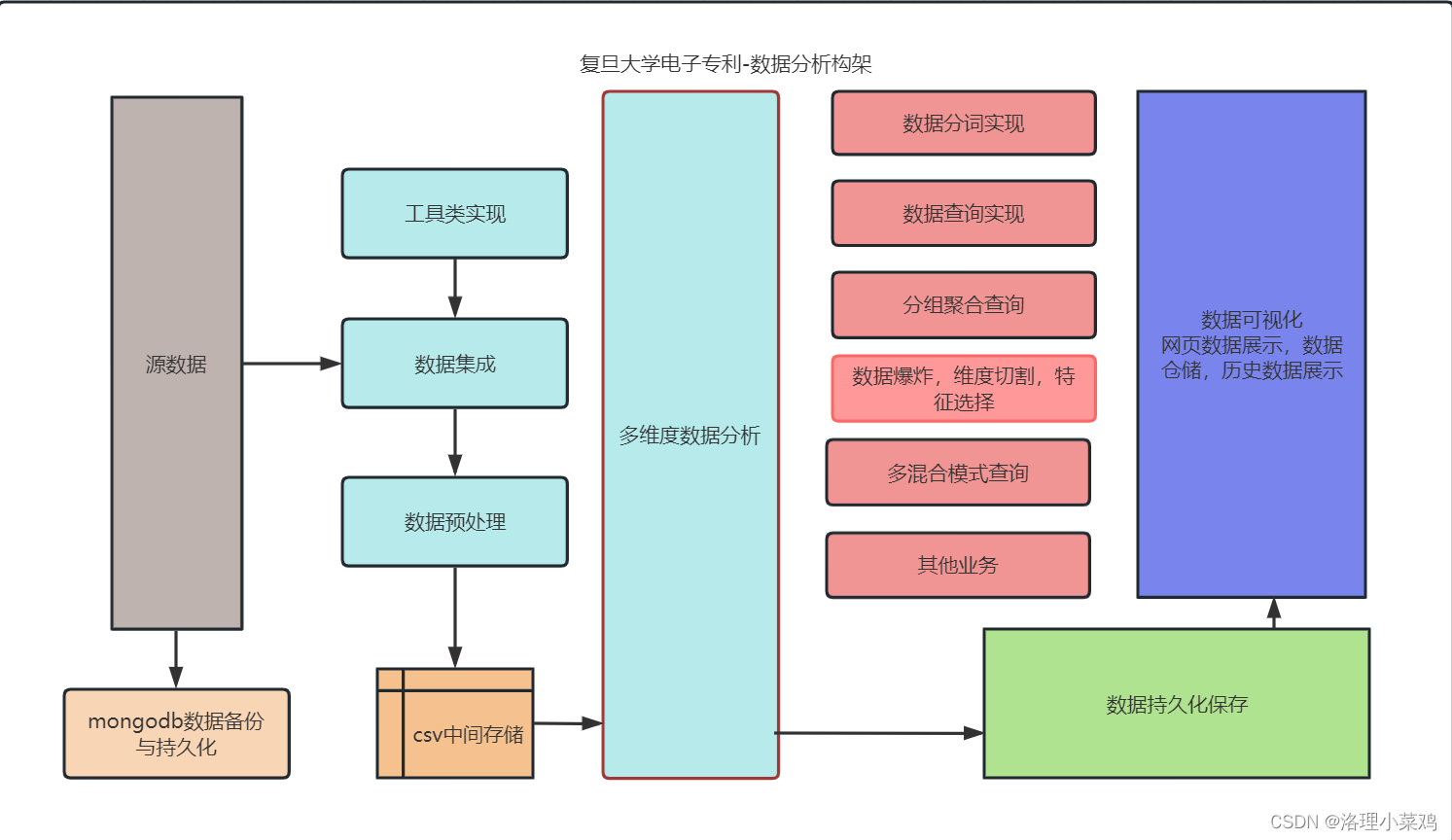
数据集成
1.数据集使用spark集成的问题
实验目的:数据传递到hdfs上,并使用spark on hive 将数据存入hive
问题描述1:os的函数listdir()返回的列表将数据集成变得很容易,但是对于spark来书,处理的开销很大
问题解决1:spark.read.csv()能够集成文件夹的所有文件
问题描述2:每个文件编码不一致,source-01的编码是utf-8但是source-03的编码是gbk
问题解决2:创建gbk和utf-8两个文件目录,并使用union连接
问题描述3: windows终端的文件到hdfs和spark on hive集群,数据应该如何集成
问题解决3:我们使用scala作为本地数据集成工具将数据传到hdfs,python将hdfs数据载入hive。
一是scala是以java为底层核心的语言,具有jdbc良好配置,可以将数据存入mysql中作为备份数据与持久化数据。
使用python作为数据挖掘和可视化语言,pyecharts,matplotlib,sklearn,pytorch多种类和库使数据多种多样。
使用spark on hive,尽可能在分析的时候使用HQL语句进行数据分析
问题描述4:hive不能自动映射中文字段(create table *** like *** 失效)
问题解决: hive建表数据填充
数据集最大问题:数据混乱(文本字段中含有大量的转义字符)
2.使用pandas对数据集成
2.1 数据编码修改

如上所示,使用记事本打开我们会在记事本尾部看到编码格式,如上,上面显示的是UTF-8格式。
2.2 时间段选择
2.3 数据异常剔除
2.4 数据合并并存储至中间表
工具类实现
1. 数据可视化基础工具类
2.文本语义分析库jieba工具类
3.mongodb存储工具类
4.redis 存储工具类
5. 其他工具类
数据分析流程
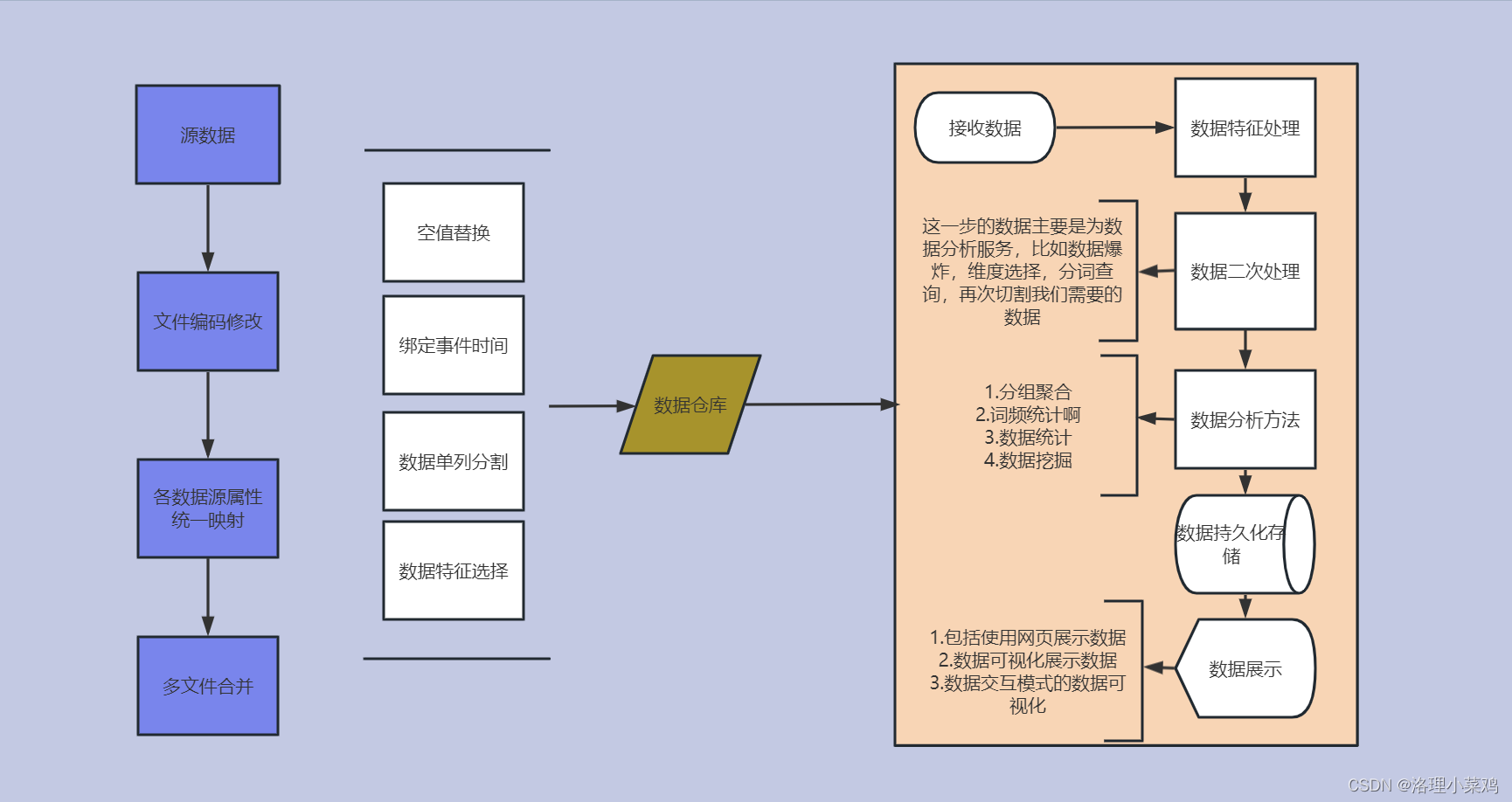
数据分析
1. 分组分析(pandas 数据分组查询)
2.文本分析(调用jieba分词库)
3.数据可视化(困难一点的我们使用pyecharts做静态网页)
数据存储
1.mongodb 数据存储(需要先安装mongodb)
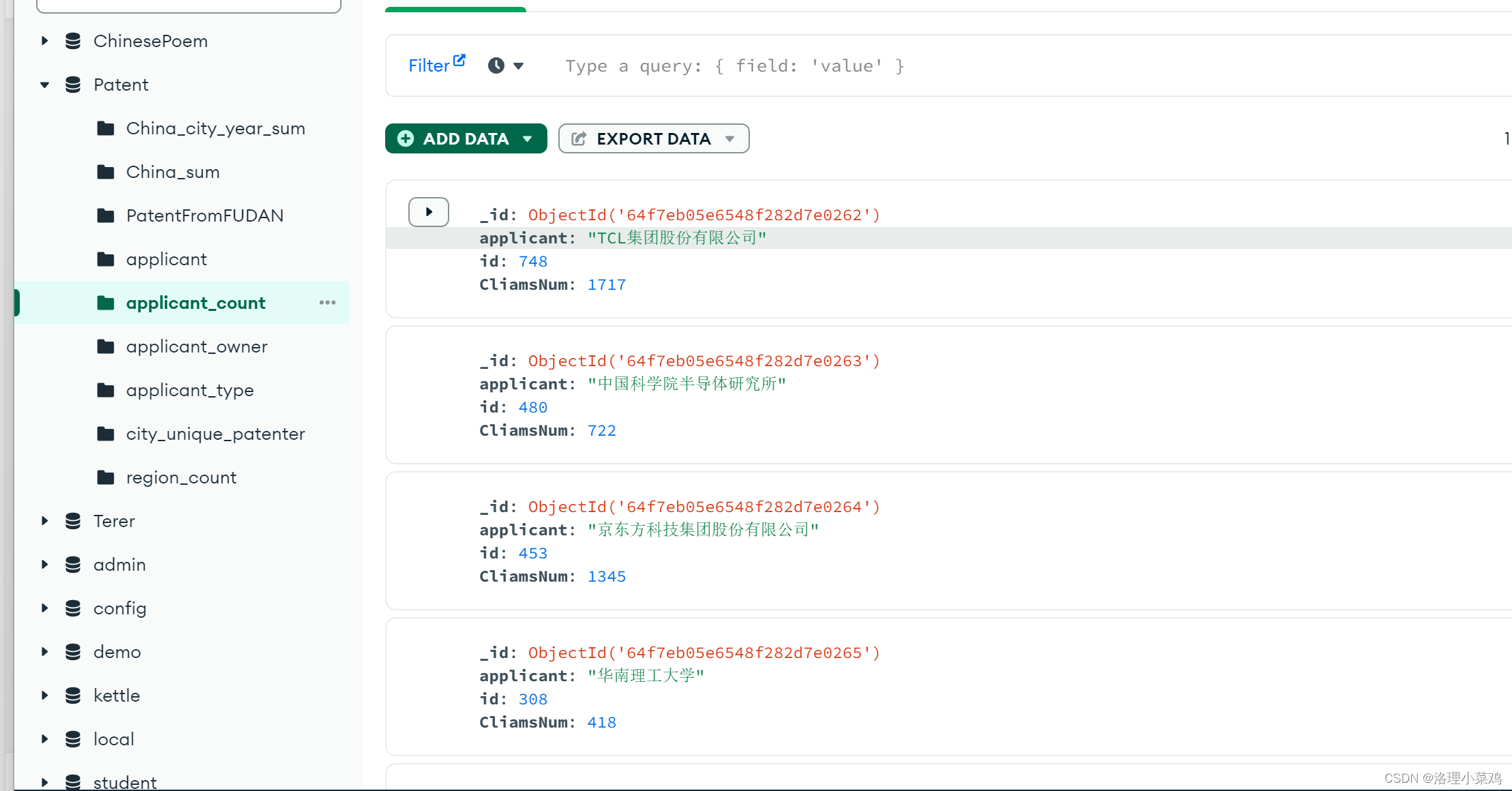
对数据分析和数据集成的结果使用mongodb进行存储
2.redis 数据缓存(需要下载redis)

由上可以看到,存储路径信息的是集合的数据结构,因为集合不允许重复项。
Springboot2 + vue + mongodb +redis + axios 数据交互式的前后端后台
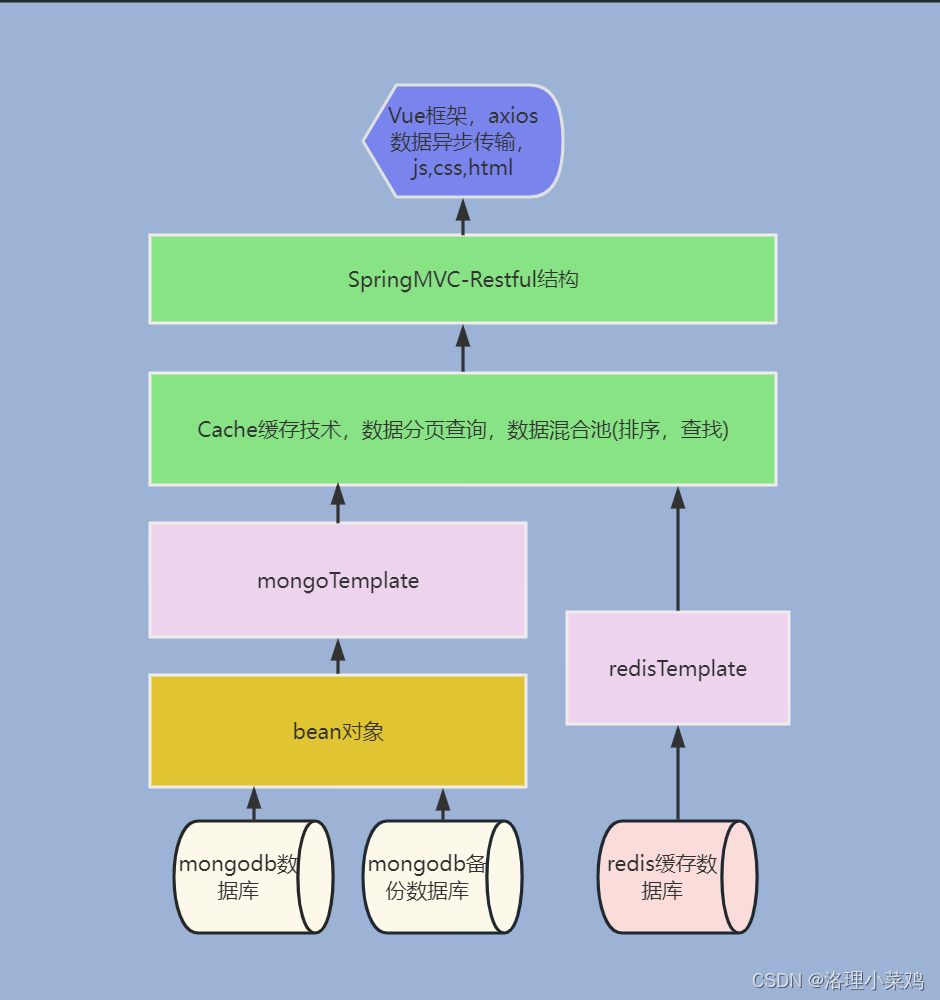
如上显示了springboot和其他数据库,前端的使用
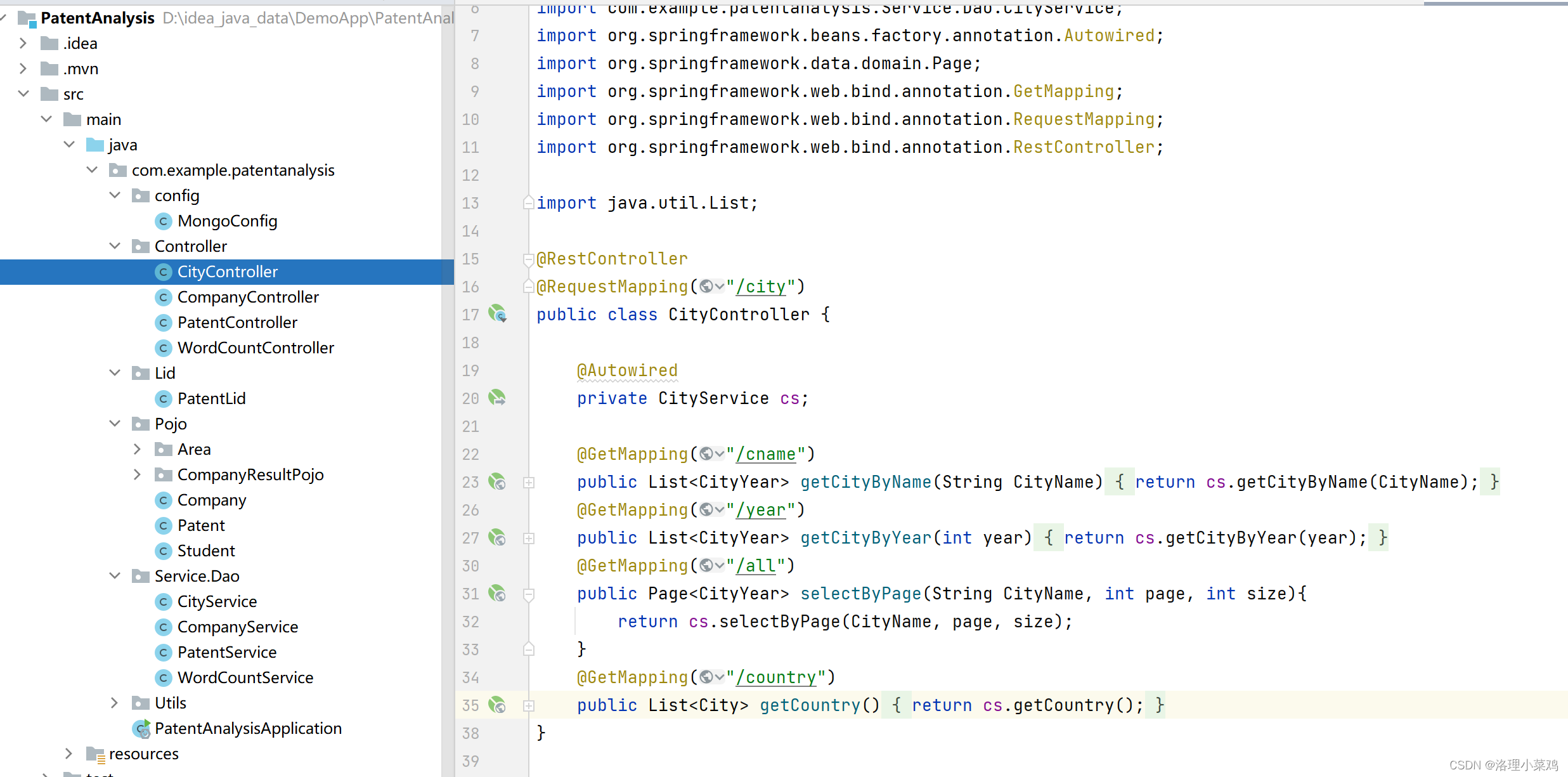
以上是个截图,展示了各个功能模块
网页展示


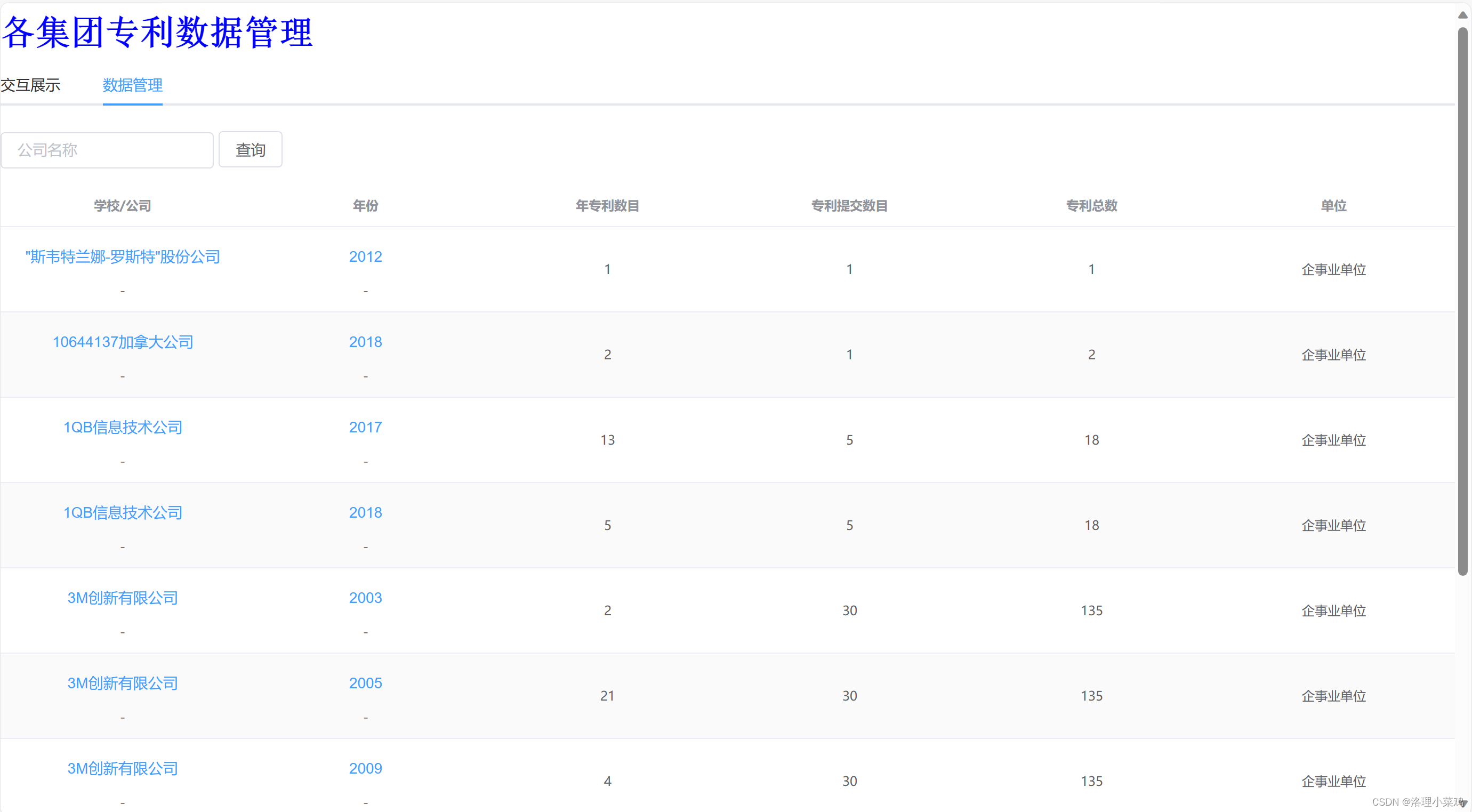
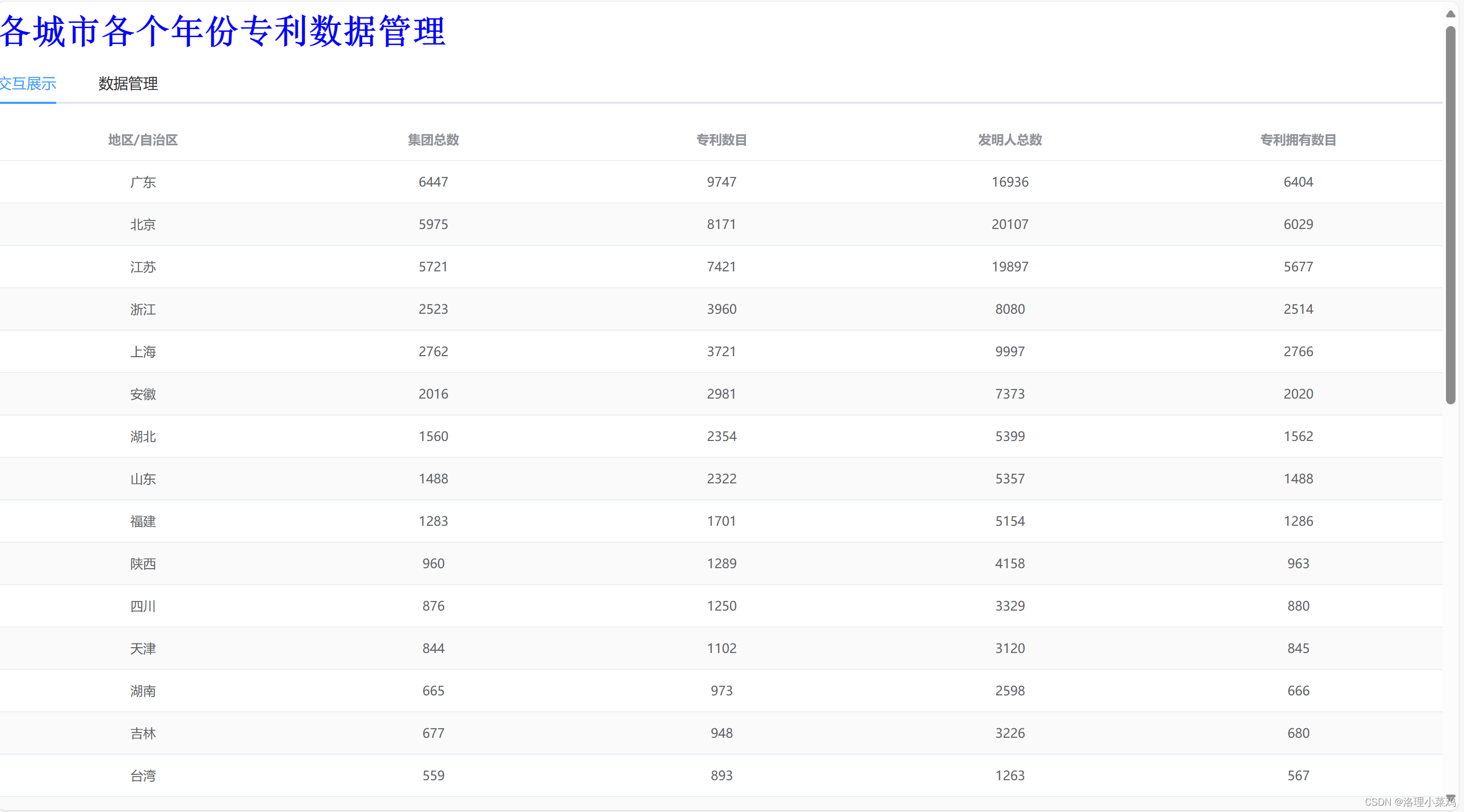


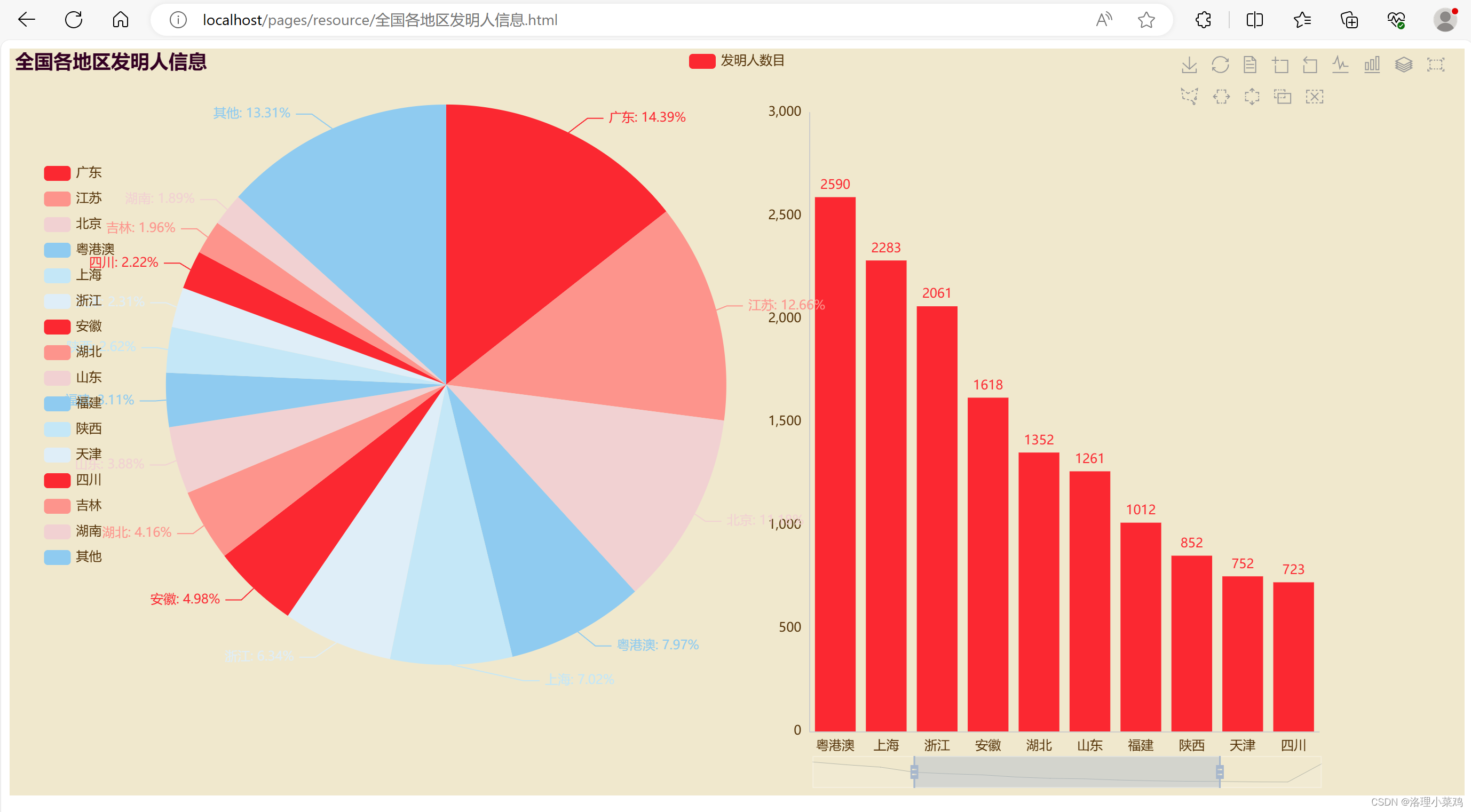

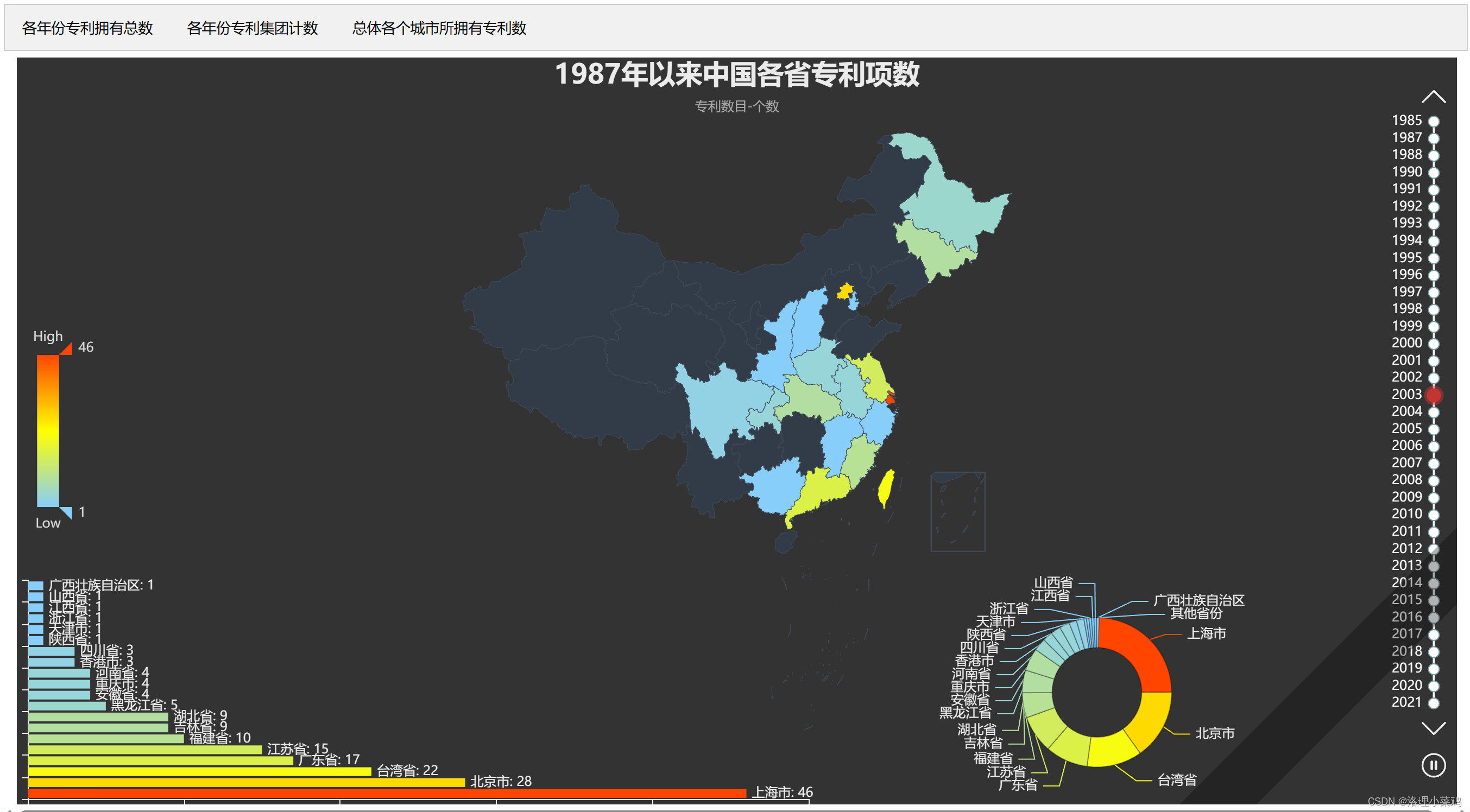
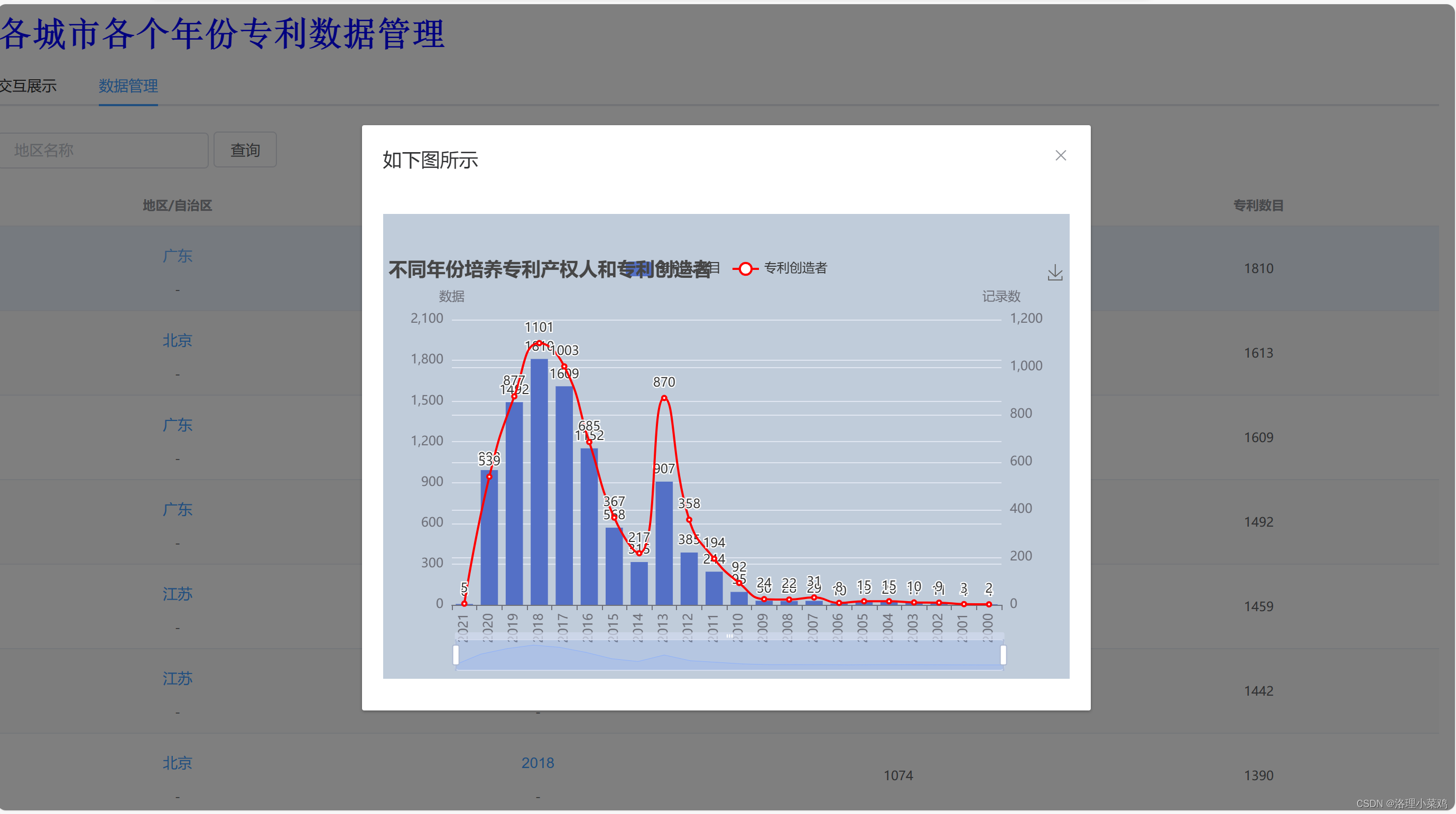
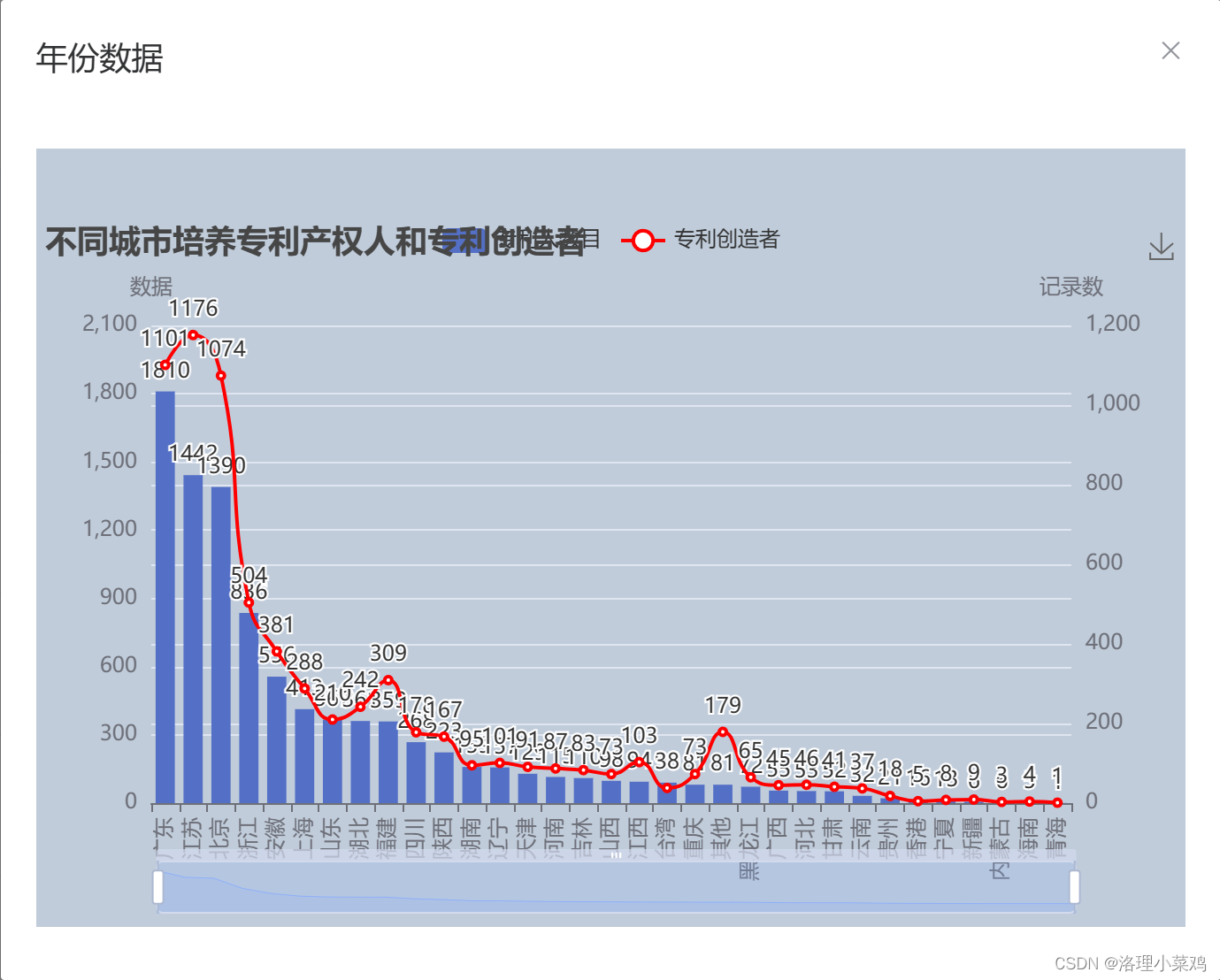
数据集网盘地址:链接:https://pan.baidu.com/s/1jg9169hva0_GogGF4awdjQ?pwd=0225 提取码:0225
Python 后台:
链接:https://pan.baidu.com/s/1480TP0WQ2fSWa01tg-dfjg?pwd=0225
提取码:0225
Springboot程序:暂时不能无偿















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









