






AEmain函数
import torch
from torch.utils.data import DataLoader #自定义自己读取数据的方法,集成类,封装到dataloader
from torchvision import transforms, datasets
#transforms 常用的图片变换,裁剪旋转
#datasets 构建计算机视觉模型,加载数据的函数以及常用的数据集接口
from ae import AE
from torch import nn, optim
#optim优化器,优化算法封装成的包,把优化的参数以及使用到的学习率传入函数中
#反向传播前利用优化器对参数梯度进行清零,反向传播结束后利用优化器对参数更新
#对神经网络参数的操作可以直接在优化器上进行
import matplotlib.pyplot as plt
#可视化工具,绘图
plt.style.use("ggplot")
#设置plt风格
def main(epoch_num):
# 下载mnist数据集
mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([
transforms.ToTensor()]), download=True)
'''
‘root’
True, 下载训练集 trainin.pt; 如果是False,下载测试集 test.pt; 默认是True
transforms.Compose()类。这个类的主要作用是串联多个图片变换的操作。
transform:一系列作用在PIL图片上的转换操作,返回一个转换后的版本
transforms.ToTensor()将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
download:是否下载到 root指定的位置,如果指定的root位置已经存在该数据集,则不再下载
'''
mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([transforms.ToTensor()]), download=True)
#查看每一个batch图片的规模
x, label = iter(mnist_train).__next__()
# 取出第一批(batch)训练所用的数据集
print(' img : ', x.shape)
# img : torch.Size([32, 1, 28, 28]), 每次迭代获取32张图片,每张图大小为(1,28,28)
# 准备工作 : 搭建计算流程
device = torch.device('cuda')
#torch.device代表将torch.Tensor分配到的设备的对象
#cuda设备类型,gpu,设备序号没有就是当前设备
model = AE().to(device)
# 生成AE模型,并转移到GPU上去
print('The structure of our model is shown below: \n')
print(model)
loss_function = nn.MSELoss()
'''
生成损失函数,度量预测值和真实值的差异,损失函数越小,模型鲁棒性越好
前向传播输出预测值,损失函数计算出预测值和真实值之间的差异值,就是损失值
得到损失值,模型通过反向传播更新参数,降低真实值和预测值之间的损失
MSELoss均方损失函数就是均方差
'''
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 生成优化器,需要优化的是model的参数,学习率为0.001
'''
optimizer优化器对象保存当前的状态,并能根据计算得到的梯度更新参数
model.base.parameters()将使用1e-3的学习率
optim有SGD、adam、adagrad等优化器,参数传进去并进行优化
'''
# 开始迭代
loss_epoch = []
for epoch in range(epoch_num):
# 每一代都要遍历所有的批次
for batch_index, (x, _) in enumerate(mnist_train):
# [b, 1, 28, 28]
x = x.to(device)
# 前向传播
x_hat = model(x) # 模型的输出,在这里会自动调用model中的forward函数
loss = loss_function(x_hat, x) # 计算损失值,即目标函数
# 后向传播
optimizer.zero_grad() # 梯度清零,否则上一步的梯度仍会存在
loss.backward() # 后向传播计算梯度,这些梯度会保存在model.parameters里面
optimizer.step() # 更新梯度,这一步与上一步主要是根据model.parameters联系起来了
loss_epoch.append(loss.item())
if epoch % (epoch_num // 10) == 0:
print('Epoch [{}/{}] : '.format(epoch, epoch_num), 'loss = ', loss.item()) # loss是Tensor类型
# x, _ = iter(mnist_test).__next__() # 在测试集中取出一部分数据
# with torch.no_grad():
# x_hat = model(x)
return loss_epoch
if __name__ == '__main__':
epoch_num = 100
loss_epoch = main(epoch_num=epoch_num)
# 绘制迭代结果
plt.plot(loss_epoch)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
ae.py
from torch import nn
class AE(nn.Module):
def __init__(self):
# 调用父类方法初始化模块的state,后面的是类的构造方法
super(AE, self).__init__()
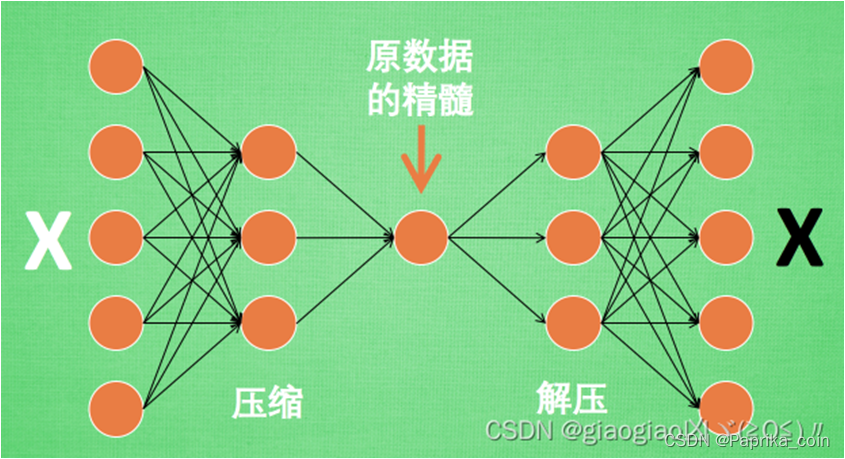
# 编码器 : [b, 784] => [b, 20]
self.encoder = nn.Sequential(
#可以允许整个容器视为单个模块,多个模块封装成一个模块,定义自己的网络层
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 20),
nn.ReLU()
#输入784神经元,输出到隐藏层256个神经元
#激活函数relu
#输入256个神经元,输出到输出层20个神经元
)
# 解码器 : [b, 20] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(20, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
# 图片数值取值为[0,1],不宜用ReLU
)
def forward(self, x):
"""
向前传播部分, 在model_name(inputs)时自动调用
:param x: the input of our training model
:return: the result of our training model
"""
batch_size = x.shape[0] # 每一批含有的样本的个数
# flatten
# tensor.view()方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,
# 返回的新tensor与原tensor共享内存,即更改一个,另一个也随之改变。
x = x.view(batch_size, 784) # 一行代表一个样本
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batch_size, 1, 28, 28)
return x
参考文献:
Python实战——VAE的理论详解及Pytorch实现_vae模型 pytorch_三只佩奇不结义的博客-CSDN博客

















 4561
4561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









