







 本文介绍了一位非计算机专业的作者如何利用Python和SARIMA模型预测季节性时间序列——气温数据。首先从Berkeley Earth获取数据,进行预处理,包括数据读取、设置索引、转换数值类型和删除缺失值。接着,通过seasonal_decompose进行趋势、季节性和随机效应的分解,然后进行ADF检验和差分处理,确保数据平稳。最后,通过网格搜索确定SARIMAX模型参数并进行预测,预测结果显示气温趋势逐渐上升,但也存在一定的波动。作者认为单一模型的预测效果有限,表示未来会继续学习和优化模型。
本文介绍了一位非计算机专业的作者如何利用Python和SARIMA模型预测季节性时间序列——气温数据。首先从Berkeley Earth获取数据,进行预处理,包括数据读取、设置索引、转换数值类型和删除缺失值。接着,通过seasonal_decompose进行趋势、季节性和随机效应的分解,然后进行ADF检验和差分处理,确保数据平稳。最后,通过网格搜索确定SARIMAX模型参数并进行预测,预测结果显示气温趋势逐渐上升,但也存在一定的波动。作者认为单一模型的预测效果有限,表示未来会继续学习和优化模型。
本人非计算机专业,只是沾边而已。所有算法和模型都是从网上学到的,平常上课、复习什么的没有太多精力学原理,只是到会用的程度。你纠错就是你对,大家相互交流。
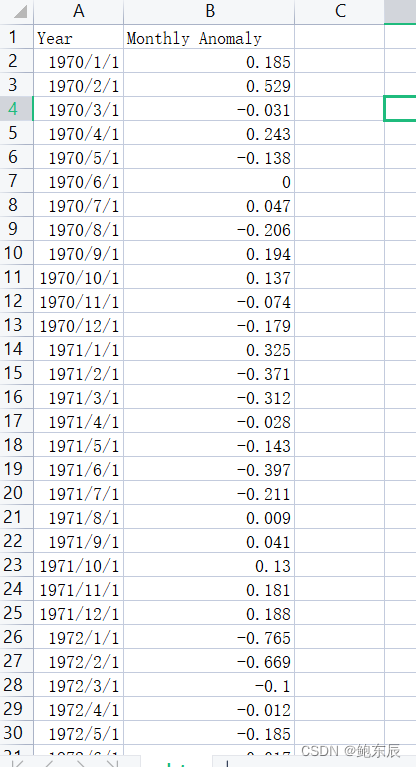
首先数据集是从Berkeley Earth下载,长这个样子,有一千五百多条数据。这是每年的气温相对于1850-1900年平均气温的相对值(我记得好像是这个解释)
第一步导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 28, 18
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
import itertools
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签之后进行数据预处理,注释的可以不看。首先读取数据;把Year设置为索引;如果文件中数值格式为字符串类型,需要用to_numeric函数转换为数值型;之后删除缺失值,作图。
df = pd.read_csv("data.csv") #读取CSV数据
# df.head(15) #查看数据集前十五条数据
# df.info() #查看数据变量属性
# dateparse = lambda x: pd.to_datetime(x, format='%Y%m', errors = 'coerce')
df = pd.read_csv("data.csv", parse_dates=['Year'], index_col='Year')
# ts = df[pd.Series(pd.to_datetime(df.index, errors='coerce')).notnull().values]
# ts.info()
df['Monthly Anomaly'] = pd.to_numeric(df['Monthly Anomaly'], errors='coerce')
df.dropna(inplace = True) #删除缺失值
# ts.info()
tem = df['Monthly Anomaly']
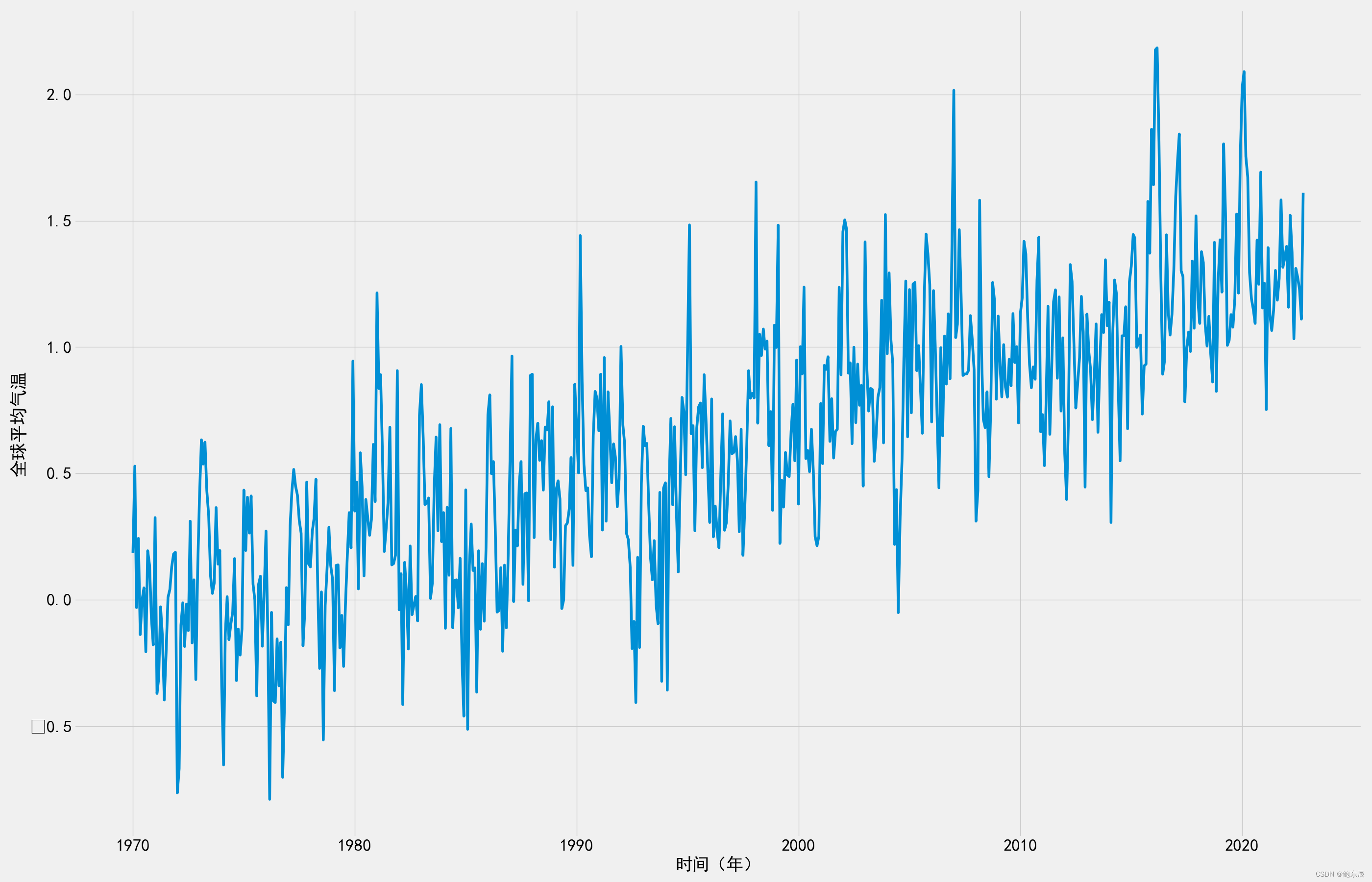
plt.plot(tem)
plt.xticks(fontsize = 25)
plt.yticks(fontsize = 25)
plt.xlabel(u'时间(年)', fontsize = 25)
plt.ylabel(u'全球平均气温', fontsize = 26)
plt.show()数据可视化结果如下:
之后进行SARIMA的重要一步,通过Python中的seasonal_decompose函数可以提取序列的趋势、季节和随机效应。对于非平稳的时间序列,可以通过对趋势和季节性进行建模并将它们从模型中剔除&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2471
2471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









