







SVM
- SVM算法简介
- SVM算法的API介绍
- SVM算法原理
- SVM的损失函数
- SVM的核方法
- SVM回归
SVM算法简介
SvM: SVM全称是supported vector machine (支持向量机),即寻找到一个超平面使样本分成两类,并且间隔最大。

超平面最大间隔:寻找一个平面,使得这个平面最大地原理最近的训练实例。如右图:
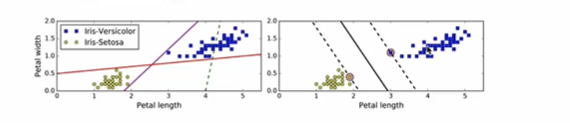
硬间隔分类:指严格地让所有实例都不在最大间隔之间,并且位于正确的一边。
存在的问题:
- 它只在数据是线性可分离的时候才有效;
- 它对异常值非常敏感。
软间隔分类:使得目标尽可能在保持最大间隔宽阔和限制间隔违例(即位于最大间隔之上,甚至在错误的一边的实例)之间找到良好的平衡
 在Scikit-Learn的SVM类中,可以通过超参数C来控制这个平衡:C值越⼩,则间隔越宽,但是间隔违例也会越多。上图
在Scikit-Learn的SVM类中,可以通过超参数C来控制这个平衡:C值越⼩,则间隔越宽,但是间隔违例也会越多。上图
显示了在⼀个⾮线性可分离数据集上,两个软间隔SVM分类器各⾃的决策边界和间隔。
左边使⽤了⾼C值,分类器的错误样本(间隔违例)较少,但是间隔也较⼩。
右边使⽤了低C值,间隔⼤了很多,但是位于间隔上的实例也更多。看起来第⼆个分类器的泛化效果更好,因为⼤多数
间隔违例实际上都位于决策边界正确的⼀边,所以即便是在该训练集上,它做出的错误预测也会更少。
SVM算法的API介绍
from sklearn import svm
x = [[0,0],[1,1]]
y = [0,1]
ss = svm.SVC()
ss.fit(x,y)
print(ss.predict([[2, 2]]))
SVM算法原理

朗格朗⽇乘⼦法
拉格朗⽇乘⼦法 (Lagrange multipliers)是⼀种寻找多元函数在⼀组约束下的极值的⽅法. 通过引⼊拉格朗⽇乘⼦,可将有 d 个变量与 k 个约束条件的最优化问题转化为具有 d + k 个变量的⽆约束优化问题求解。

对偶问题:



总结:
1)⾸先是求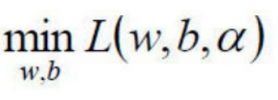
的极⼤值
2)计算上⾯式⼦的极值求出α∗;
3)将α∗代⼊,计算w,b
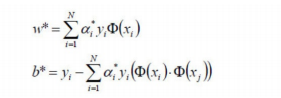
4)求得超平⾯:
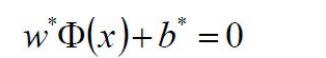
5)求得分类决策函数
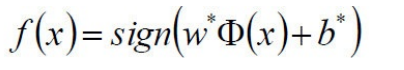
SVM的损失函数

0/1损失
当正例的点落在y=0这个超平⾯的下边,说明是分类正确,⽆论距离超平⾯所远多近,误差都是0.
当这个正例的样本点落在y=0的上⽅的时候,说明分类错误,⽆论距离多远多近,误差都为1.
SVM Hinge损失函数
当⼀个正例的点落在y=1的直线上,距离超平⾯⻓度1,那么1-ξ=1,ξ=0,也就是说误差为0;
当它落在距离超平⾯0.5的地⽅,1-ξ=0.5,ξ=0.5,也就是说误差为0.5;
当它落在y=0上的时候,距离为0,1-ξ=0,ξ=1,误差为1;
当这个点落在了y=0的上⽅,被误分到了负例中,距离算出来应该是负的,⽐如-0.5,那么1-ξ=-0.5,ξ=-1.5.误 差为1.5.
Logistic损失函数
损失函数的公式为:ln(1 + e−yi)
当yi = 0时,损失等于ln2,这样真丑,所以我们给这个损失函数除以ln2. 这样到yi = 0时,损失为1,即损失函数过(0,1)点 即上图中的红⾊线。
SVM的核方法
核函数,是将原始输⼊空间映射到新的特征空间,从⽽,使得原本线性不可分的样本可能在核空间可分。


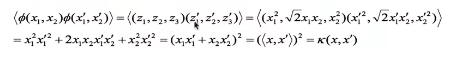
核函数的作⽤就是⼀个从低维空间到⾼维空间的映射,⽽这个映射可以把低维空间中线性不可分的两类点变成线性 可分的。

SVM回归

SVM算法案例实践


总结
SVM的优点:
- 在⾼维空间中⾮常⾼效;
- 即使在数据维度⽐样本数量⼤的情况下仍然有效;
- 在决策函数(称为⽀持向量)中使⽤训练集的⼦集,因此它也是⾼效利⽤内存的
- 通⽤性:不同的核函数与特定的决策函数⼀⼀对应
SVM的缺点:
- 如果特征数量⽐样本数量⼤得多,在选择核函数时要避免过拟合;
- 对缺失数据敏感; 对于核函数的⾼维映射解释⼒不强
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
train = pd.read_csv("train.csv")
# print(train.head())
# print(train.shape)
#确定目标值和特征值
train_image = train.ix[:,1:]
train_label = train.ix[:,0]
#查看具体图像
num = train_image.ix[0,].values.reshape(28,28)
plt.imshow(num)
plt.axis("off")
plt.show()
#查看形状
# def to_plot(n):
# num = train_image.ix[n,].values.reshape(28, 28)
# plt.imshow(num)
# plt.axis("off")
# plt.show()
#数据基本处理
#特征值归一化
train_image = train_image.values /255
train_label = train_label.values
#数据集分割
x_train,x_test,y_train,y_test = train_test_split(train_image,train_label,train_size= 0.8,random_state=0)
#特征降维和模型训练
#多次使用pca,确定最后的最优模型
def n_components_analysis(n,x_train,y_train,x_test,y_test):
#记录开始时间
start = time.time()
#pca降维实现
pca = PCA(n_components=n)
print("特征降维,传递的参数为:{}".format(n))
pca.fit(x_train)
#在训练集和测试集进行降维
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
#利用svc进行训练
print("开始使用svc进行训练")
ss = svm.SVC()
ss.fit(x_train_pca,y_train)
#获取accuracy结果
accuracy = ss.score(x_test_pca,y_test)
#记录结束时间
end = time.time()
print("准确率是:{},消耗时间是:{}s".format(accuracy,int(end-start)))
return accuracy
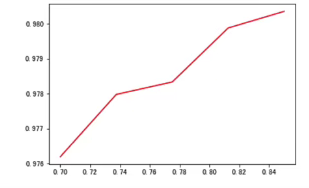
#传递多个n_components,寻找合理的n_components:
n_s= np.linspace(0.70,0.85,num=5)
accuracy = []
for n in n_s:
tmp = n_components_analysis(n,x_train,y_train,x_test,y_test)
accuracy.append(tmp)
#准确率可视化
plt.plot(n_s,np.array(accuracy),"r")
plt.show()
#经过图形展示,选择合理的n_components,最后考虑确定的结果为0.80
#确定最优模型
pca = PCA(n_components=0.80)
pca.fit(x_train)
pca.n_components_
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
#训练比较有的模型
ssl = svm.SVC()
ssl.fit(x_train_pca,y_test)
ssl.score(x_test_pca,y_test)















 2757
2757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









