







内容:设计并实现一个简单的用于分类的SVI M,主要用于iris 分类。将iris数据集分为训综集和测试集,使用训练集训练得到SVM 分类模型,并使用模型预测测试集的类别归属。
实现思路及步骤如下。
(1)读取数据集,区分标签和数据。(2)标准化数据集。
(3)将数据集划分为训练集和测试集。(4)构建SVM模型。
(5)输出预测测试集结果,评价分类模型性食能,输出测试报告。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 加载数据集
iris = load_iris()
# 区分标签和数据
X = iris.data
y = iris.target
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建SVM模型
svm = SVC(kernel='linear')
svm.fit(X_train, y_train)
# 预测测试集结果
y_pred = svm.predict(X_test)
# 输出测试结果和分类报告
print('测试集预测结果:\n', y_pred)
print('分类模型性能评估报告:\n', classification_report(y_test, y_pred))
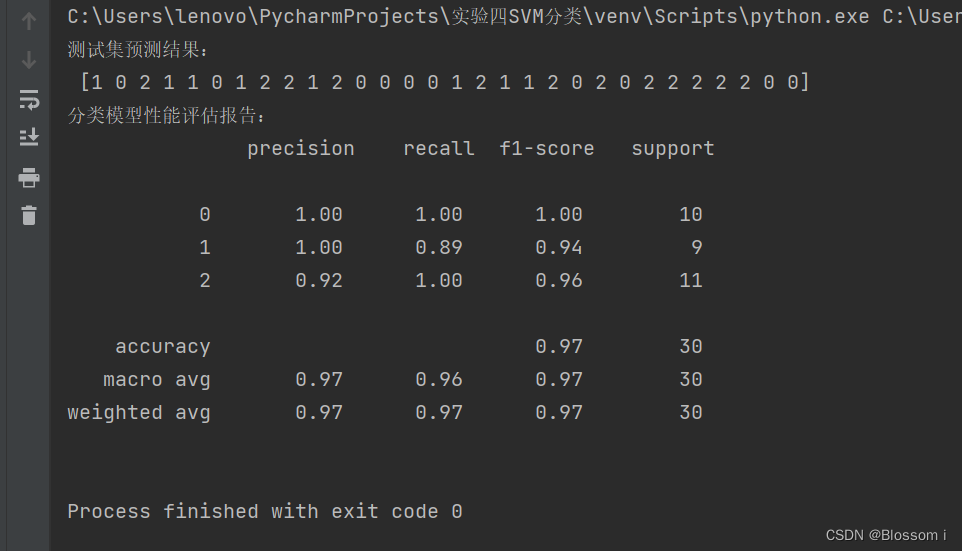
在上述代码中,首先通过load_iris函数加载iris数据集,然后将数据集分为特征和标签两部分。使用StandardScaler类对特征数据进行标准化处理,以便提高模型的收敛效率和预测精度。使用train_test_split函数划分原始数据集为训练集和测试集。
接着,利用SVC类构建线性核支持向量机模型,并使用训练集对其进行拟合。用训练好的SVM模型对测试集进行预测,得到预测结果。最后,使用classification_report函数输出模型的分类性能评估报告,包括精确度、召回率、F1值等指标。
通过这些步骤,我们就可以构建一个简单的基于iris数据集的SVM分类模型,并用于分类预测。















 5605
5605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









