







目录
4.1.1 二叉搜索树及查找
什么是二叉搜索树
查找问题分为两类
- 静态查找:固定数据集内查找,只进行find操作
- 动态查找:数据集有添加和删除操作,在此情况下查找
针对动态查找,数据如何组织?
前面提过一种高效的查找方法:二分查找。这种查找方式高效的前提是数据是有序排列的。如果将二分查找的顺序列出来,可以形成名为判定树的结构。
至此,就可以将一个线性的查找过程转换为树的查找过程,而判定树的查找效率就是树的高度。
那么仔细想想,直接将数据放到树结构中而不是数组结构,是否能进一步提升效率?我们经过学习已经知道,树结构要比数组结构动态性强,如果可以提升,那么怎么组织这颗树的数据?
二分查找的顺序组成的查找树中,每个结点左子树的值都小于该结点的值,而右子树大于该结点。依据这种方式构建的查找树就叫做二叉查找树。
定义
二叉搜索树(Binary Search Tree) 也称二叉排序树或二叉查找树
数据特征:
一颗二叉树,可以为空,若非空:
- 非空左子树的所有键值小于其根结点的键值。
- 非空右子树的所有键值大于其根结点的键值。
- 左、右子树都是二叉搜索树。
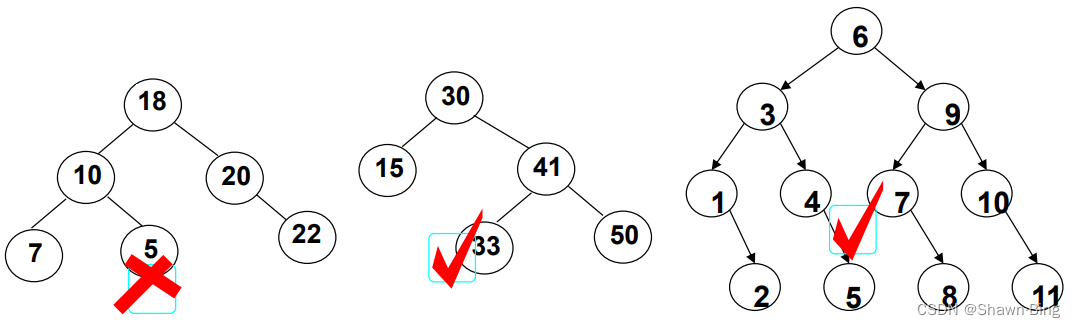
二叉搜索树特殊函数集:
- Position Find( ElementType X, BinTree BST ):从二叉搜索树BST 中查找元素X,返回其所在结点的地址
- Position FindMin( BinTree BST ):从二叉搜索树BST中查找并返回 最小元素所在结点的地址
- Position FindMax( BinTree BST ) :从二叉搜索树BST中查找并返回 最大元素所在结点的地址
- BinTree Insert( ElementType X, BinTree BST )
- BinTree Delete( ElementType X, BinTree BST )
查找操作:Find
算法思想
从根结点开始,如果树为空,返回NULL
若搜索树非空,则根结点关键字和X进行比较,并进行不同处理:
- 若X小于根结点键值,只需在左子树中继续搜索
- 如果X大于根结点的键值,在右子树中进行继续搜索
- 若两者比较结果是相等,搜索完成,返回指向此结点的指针

代码实现
参数表:x是要查找的元素,BST为查找树
Position Find( ElementType X, BinTree BST )
{
if( !BST ) return NULL; /*查找失败*/
if( X > BST->Data )
/*在右子树中继续递归查找*/
return Find( X, BST->Right );
else if( X < BST->Data )
/*在左子树中继续递归查找*/
return Find( X, BST->Left );
/* X == BST->Data */
else
/*查找成功,返回结点的找到结点的地址*/
return BST;
}
上面的函数使用递归实现,但递归效率不高,以下给出用循环实现的方式
Position IterFind( ElementType X, BinTree BST )
{
while( BST ) {
if( X > BST->Data )
BST = BST->Right; /*向右子树中移动,继续查找*/
else if( X < BST->Data )
BST = BST->Left; /*向左子树中移动,继续查找*/
else /* X == BST->Data */
return BST; /*查找成功,返回结点的找到结点的地址*/
}
return NULL; /*查找失败*/
}补:查找最大和最小元素
根据查找树结构,左边结点值小于右边,因此:
- 查找树的最小元素一定在树最左分枝的端结点上
- 最大元素一定是在树的最右分枝的端结点

代码实现:
最小:(递归)
Position FindMin( BinTree BST )
{
if( !BST )
return NULL; /*空的二叉搜索树,返回NULL*/
else if( !BST->Left )
return BST; /*找到最左叶结点并返回*/
else
return FindMin( BST->Left ); /*沿左分支继续查找*/
}
最大:(循环迭代)
Position FindMax( BinTree BST )
{
if(BST )
while( BST->Right )
BST = BST->Right;/*沿右分支继续查找,直到最右叶结点*/
return BST;
}
4.1.2 二叉搜索树的插入
插入操作:Insert
分析:插入操作的关键在于需要找到插入位置。需要保证插入操作以后仍然是一颗二叉搜索树——左子树小于根结点,右子树大于根结点
算法思想
将要插入的元素与根结点进行比较,
- 若小于根结点就与根结点左子树(递归)进行比较
- 若大于根结点就与根结点右子树(递归)进行比较
- 若为空,则创建一个结点并插入此位置,将该位置(指针)赋给根结点的right或left
代码实现
参数表:要插入的元素x,二叉搜索树BST
BinTree Insert( ElementType X, BinTree BST )
{
/*若原树为空,生成并返回一个结点的二叉搜索树*/
if( !BST ){
BST = malloc(sizeof(struct TreeNode));
BST->Data = X;
BST->Left = BST->Right = NULL;
}else{
/*开始找要插入元素的位置*/
if( X < BST->Data )
BST->Left = Insert( X, BST->Left);/*递归插入左子树*/
else if( X > BST->Data )
BST->Right = Insert( X, BST->Right);/*递归插入右子树*/
}
/*若元素X已经存在,什么都不做 */
return BST;
}
例题
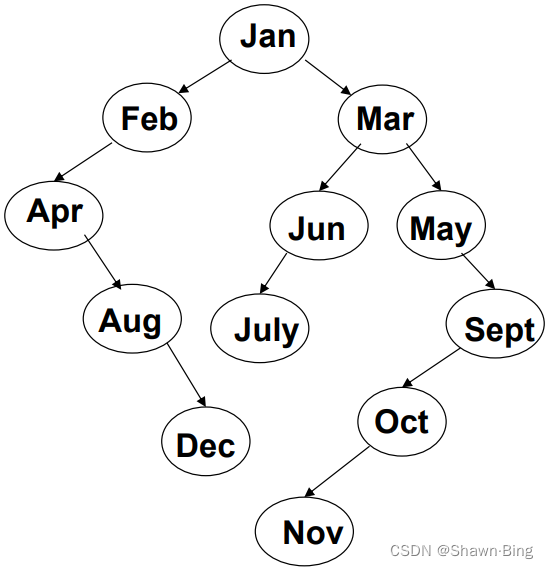
以一年十二个月的英文缩写为键值,按从一月到十二月顺序输入,即输入序列为(Jan, Feb, Mar, Apr, May, Jun, July, Aug, Sep, Oct, Nov, Dec),按首字母大小为判据,构建其搜索二叉树
- 根结点为Jan
- F<J,Feb为Jan左子树
- M>J,Mar为Jan右子树
- ...
4.1.3 二叉搜索树的删除
删除操作:delete
算法思想
首先找到结点,然后分三种情况讨论
情况1:删除叶节点
直接删除,并将其父结点left/right赋NULL
情况2:删除有一个孩子的子结点
将其父结点的指针指向被删除结点的子结点(让父结点指向孙子结点),再删除该结点
情况3:删除有两个孩子的子结点
这个问题比较复杂,所以可以采取简化的原则,怎么简化?删除有两个孩子的子结点,那么这个位置谁来坐?找一个替罪羊来!找一个结点来替代它!简单来说,我们一般找左子树的最大或者右子树的最小。还记得搜索二叉树的特性吗?最大值一定在最右边、最小值在最左边,这意味着什么?这就意味着左最大和右最小最多只有一个子结点,这不就把一个删除有两个孩子的子结点问题变成了查找并替换最多只有一个孩子的子结点问题了吗?
代码实现
BinTree Delete( ElementType X, BinTree BST )
{
Position Tmp;
//树为空
if( !BST ) printf("要删除的元素未找到");
else if( X < BST->Data )
BST->Left = Delete( X, BST->Left); /* 左子树递归删除,返回新(左)根结点位置 */
else if( X > BST->Data )
BST->Right = Delete( X, BST->Right); /* 右子树递归删除 */
/*找到了要删除的结点 */
else{
/*被删除结点有左右两个子结点 */
if( BST->Left && BST->Right ) {
/*在右子树中找最小的元素填充删除结点*/
Tmp = FindMin( BST->Right );
BST->Data = Tmp->Data;
/*在删除结点的右子树中删除最小元素*/
BST->Right = Delete( BST->Data, BST->Right);
}else{ /*被删除结点有一个或无子结点*/
Tmp = BST;
if( !BST->Left ) /* 有右孩子或无子结点*/
{BST = BST->Right; }
else if( !BST->Right ) /*有左孩子或无子结点*/
{BST = BST->Left; }
free( Tmp );
}
}
return BST;
}













 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









