






1. RNN:循环神经网络
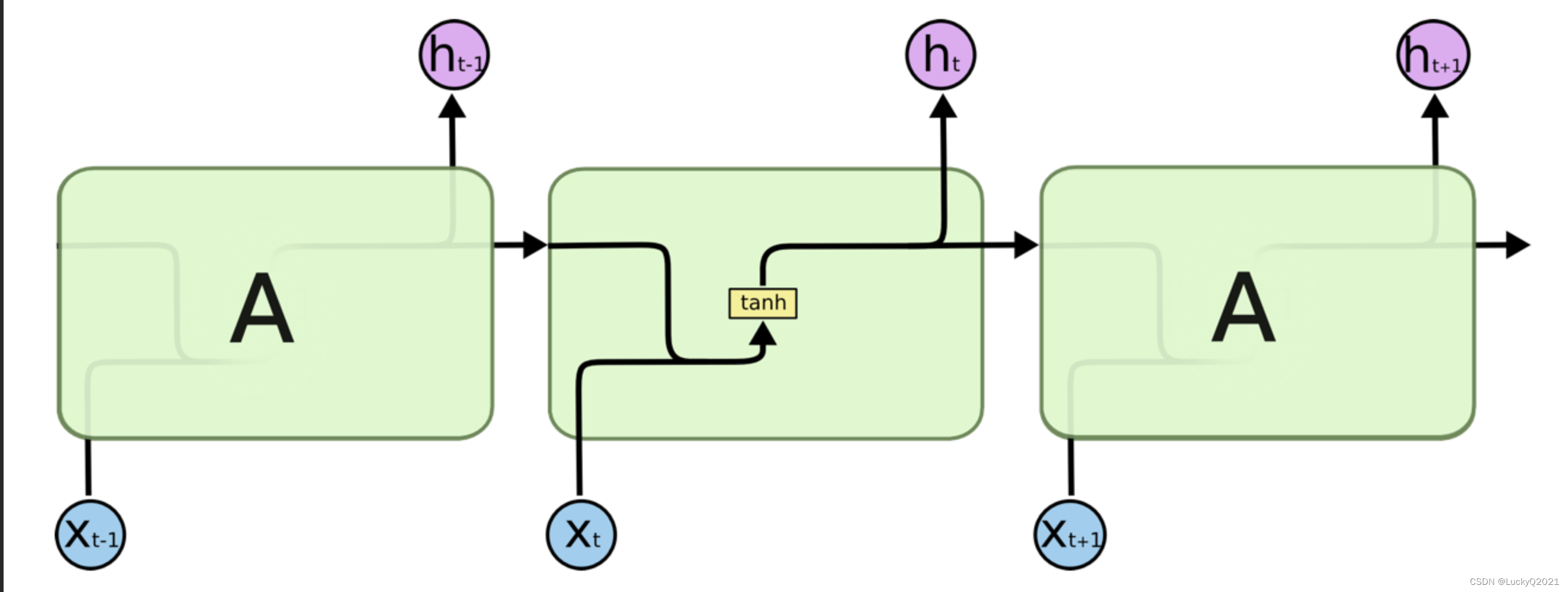
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def init_hidden(self):
return torch.zeros(1, self.hidden_size)
2. GRU:门控神经网络
门控循环单元(Gated Recurrent Unit,GRU)是一种循环神经网络(Recurrent Neural Network,RNN)的变种,由 Cho et al. (2014) 提出。与标准的 RNN 相比,GRU 引入了门控机制,以便网络能够更好地处理长序列。
GRU 中的门控单元有两个,分别是重置门(Reset Gate)和更新门(Update Gate)。这两个门控单元的作用是控制信息的流动,其中重置门负责控制过去的信息如何被组合,而更新门则负责控制新信息如何被整合到网络状态中。
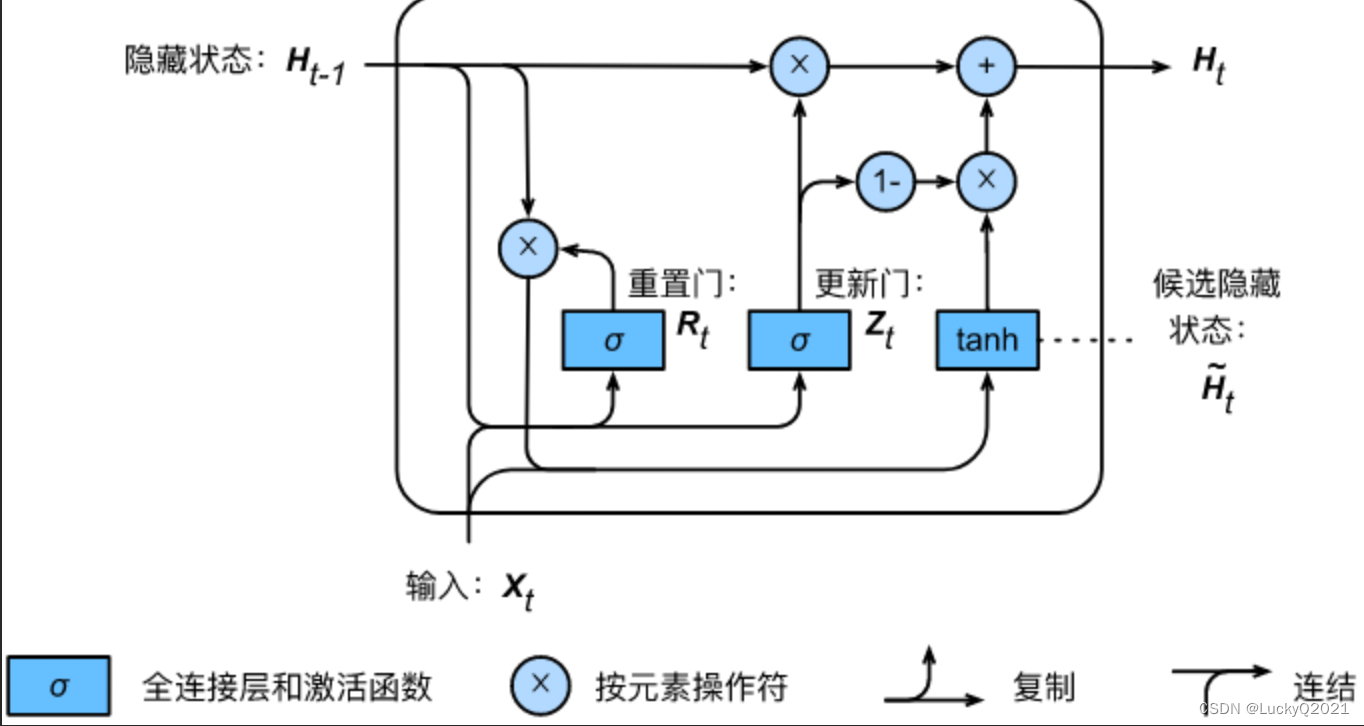
import torch
import torch.nn as nn
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(GRUCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.reset_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.update_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.out_gate = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
r = torch.sigmoid(self.reset_gate(combined))
z = torch.sigmoid(self.update_gate(combined))
h_hat = torch.tanh(self.out_gate(torch.cat((input, r * hidden), 1)))
h = (1 - z) * hidden + z * h_hat
return h
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1):
super(GRU, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru_cells = nn.ModuleList()
for i in range(num_layers):
if i == 0:
self.gru_cells.append(GRUCell(input_size, hidden_size))
else:
self.gru_cells.append(GRUCell(hidden_size, hidden_size))
def forward(self, input, hidden=None):
if hidden is None:
hidden = torch.zeros(self.num_layers, input.size(0), self.hidden_size)
outputs = []
for i in range(self.num_layers):
hidden[i] = self.gru_cells[i](input, hidden[i])
input = hidden[i]
outputs.append(input)
return outputs, hidden
3. LSTM:长短期记忆神经网络
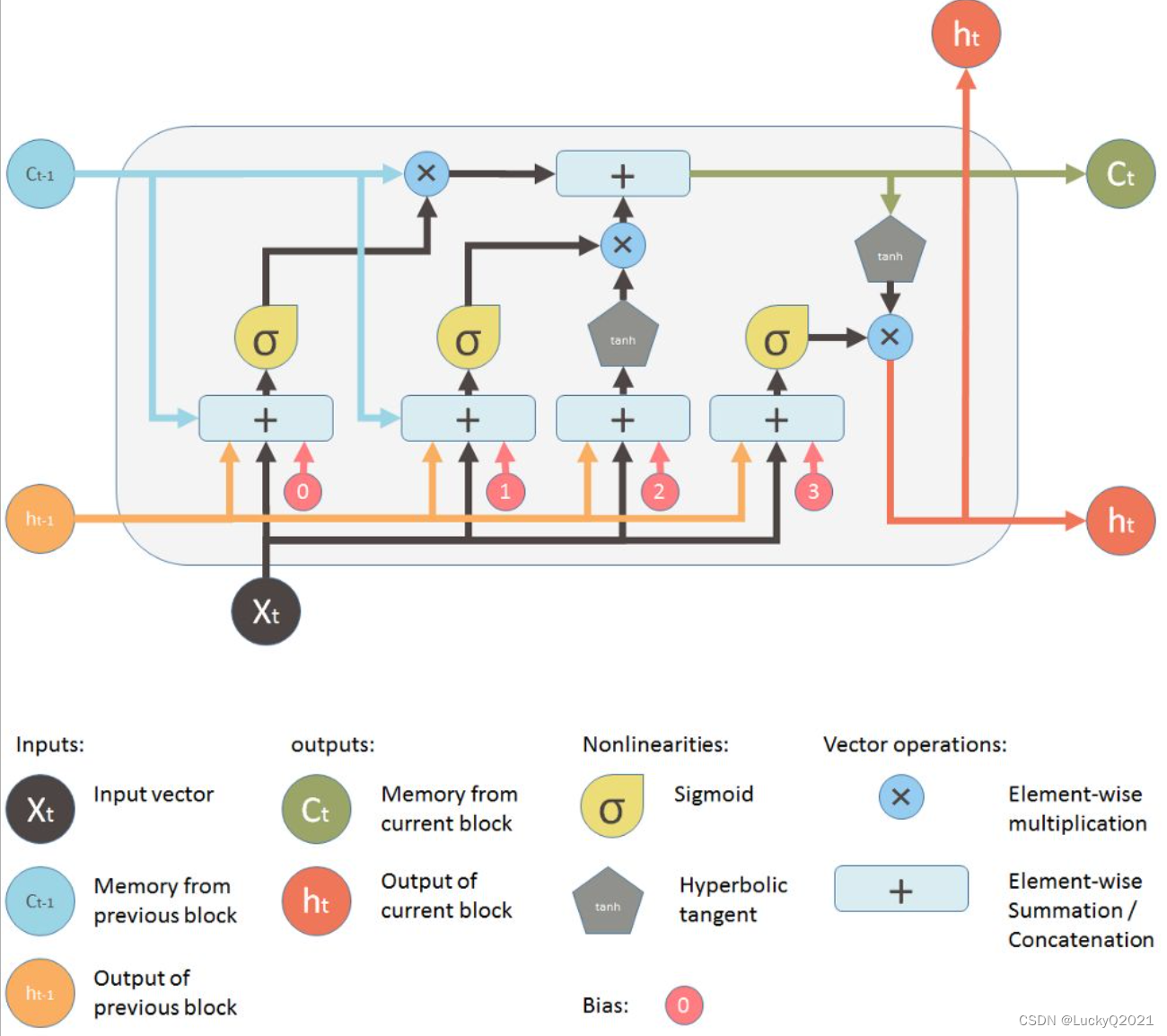
import torch
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.W_ih = nn.Parameter(torch.Tensor(input_size, 4 * hidden_size))
self.W_hh = nn.Parameter(torch.Tensor(hidden_size, 4 * hidden_size))
self.bias = nn.Parameter(torch.Tensor(4 * hidden_size))
self.reset_parameters()
def reset_parameters(self):
std = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
weight.data.uniform_(-std, std)
def forward(self, input, hx):
h, c = hx
gates = (torch.mm(input, self.W_ih) + torch.mm(h, self.W_hh) + self.bias)
i_gate, f_gate, o_gate, g_gate = torch.split(gates, self.hidden_size, dim=1)
i_gate = torch.sigmoid(i_gate)
f_gate = torch.sigmoid(f_gate)
o_gate = torch.sigmoid(o_gate)
g_gate = torch.tanh(g_gate)
c_next = f_gate * c + i_gate * g_gate
h_next = o_gate * torch.tanh(c_next)
return h_next, c_next
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.ModuleList()
self.lstm.append(nn.LSTMCell(input_size, hidden_size))
for i in range(1, num_layers):
self.lstm.append(nn.LSTMCell(hidden_size, hidden_size))
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
h, c = [], []
for i in range(self.num_layers):
h.append(torch.zeros(input.size(0), self.hidden_size))
c.append(torch.zeros(input.size(0), self.hidden_size))
for i in range(input.size(1)):
x = input[:, i, :]
for j in range(self.num_layers):
h[j], c[j] = self.lstm[j](x, (h[j], c[j]))
x = h[j]
output = self.fc(h[-1])
output = self.softmax(output)
return output, (h, c)
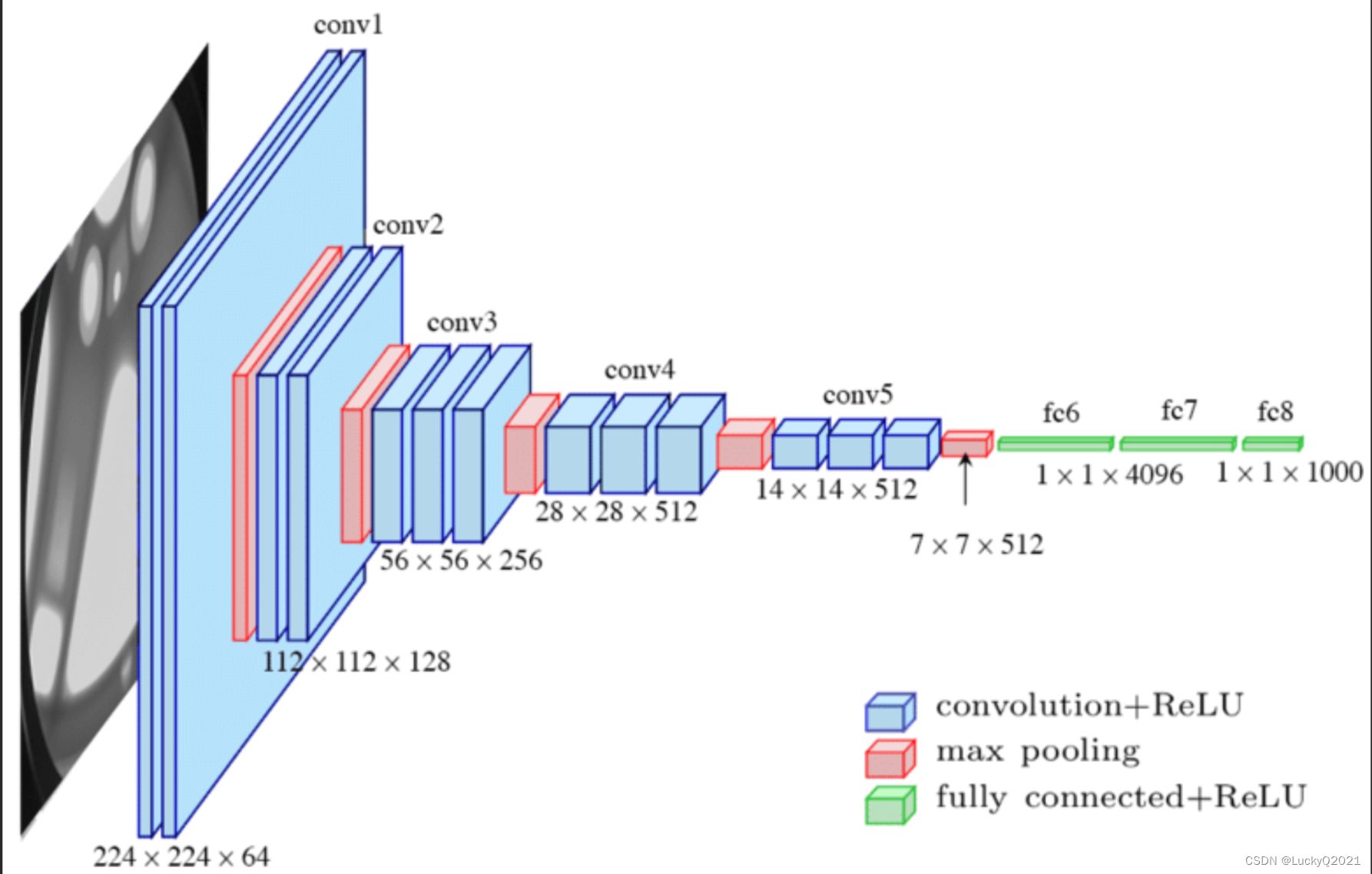
4. CNN(Convolutional Neural Network):卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种经典的深度学习模型,主要用于图像和语音等信号数据的处理和识别。CNN 最早用于图像分类任务,但现在已经被广泛应用于各种领域,如自然语言处理、视频分析、游戏AI等。
CNN的主要特点是通过卷积操作提取输入数据中的局部特征,并通过池化操作对这些特征进行降维和抽象。CNN 由多个卷积层、池化层和全连接层组成。卷积层的作用是提取输入数据的特征,每个卷积层由多个卷积核组成,卷积核通过对输入数据进行卷积操作,提取出与特定模式或特征相关的信息。池化层则将特征图中的信息进行降维和抽象,以减少模型参数和计算量。全连接层则将最终的特征向量映射到输出空间,用于分类或回归任务。
CNN 在处理图像、语音等信号数据时,相比于传统的机器学习模型,具有许多优点。首先,CNN 能够自动学习输入数据的特征表示,无需手工设计特征。其次,CNN 具有局部连接和共享权重的特性,能够大大减少模型参数和计算量。此外,CNN 还具有平移不变性的特性,即无论图像在图像平面内如何平移,CNN 都能识别出相同的物体。
在实践中,CNN 的性能取决于网络结构的设计、损失函数的选择和训练策略的优化等方面。常用的 CNN 网络结构包括 LeNet、AlexNet、VGG、GoogLeNet、ResNet 等,这些网络结构在深度、层数、卷积核的大小等方面都有所不同,针对不同的任务,需要选择不同的网络结构和训练策略。
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
上述代码定义了一个名为 SimpleCNN 的类,继承自 nn.Module。在 init 方法中,定义了 2 个卷积层,一个最大池化层,两个全连接层。在 forward 方法中,实现了前向传播的过程。具体的网络结构如下:
- conv1:输入为 3 × 32 × 32 3\times32\times32 3×32×32 的图像,经过 3 × 3 3\times3 3×3 的卷积核,得到 32 × 32 × 32 32\times32\times32 32×32×32 的特征图,再经过 ReLU 激活函数;
- pool:最大池化层,窗口大小为 2 × 2 2\times2 2×2,步长为 2,得到 32 × 16 × 16 32\times16\times16 32×16×16 的特征图;
- conv2:输入为 32 × 16 × 16 32\times16\times16 32×16×16 的特征图,经过 3 × 3 3\times3 3×3 的卷积核,得到 64 × 16 × 16 64\times16\times16 64×16×16 的特征图,再经过 ReLU 激活函数;
- pool:最大池化层,窗口大小为 2 × 2 2\times2 2×2,步长为 2,得到 64 × 8 × 8 64\times8\times8 64×8×8 的特征图;
- fc1:将特征图展开为向量,输入到全连接层,输出大小为 128,再经过 ReLU 激活函数;
- fc2:输入大小为 128,输出大小为 10,表示 10 类图像标签。
这是一个简单的 CNN 模型,可以根据需要进行更改和优化。
5. ResNet: 残差连接网络
ResNet(Residual Network)是深度残差网络,由微软亚洲研究院提出,其主要特点是利用残差块(Residual Block)来解决深度神经网络中的梯度消失和梯度爆炸问题,使得网络层数可以进一步加深,从而获得更好的性能。
在传统的深度神经网络中,网络层数增加时,模型的表达能力也会增强,但是网络的训练难度也会增加。一方面,随着网络层数的增加,梯度会经过越来越多的非线性层,导致梯度消失的问题;另一方面,对于梯度较大的情况,梯度反向传播时可能会出现梯度爆炸的问题。
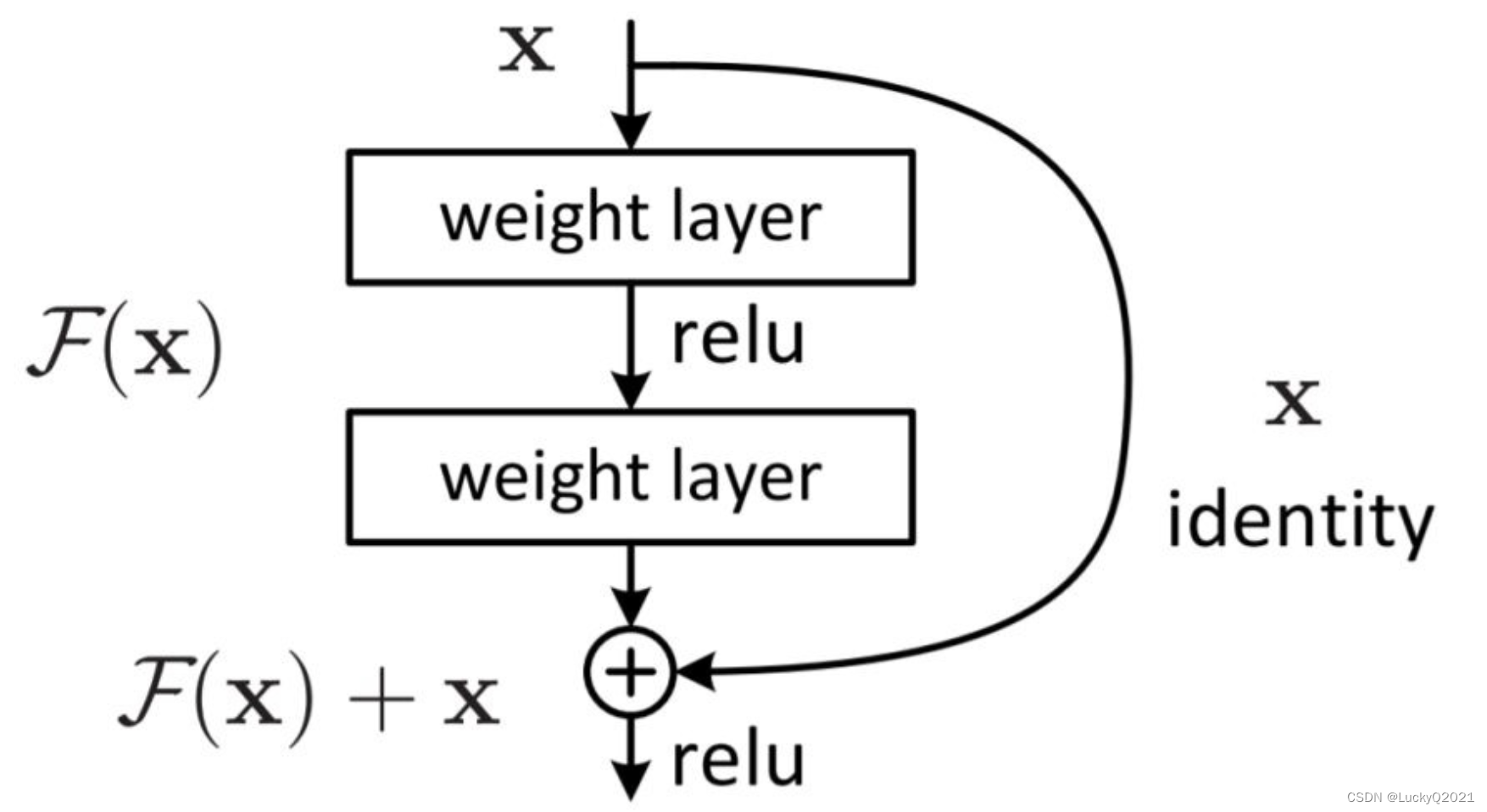
为了解决这些问题,ResNet 提出了残差块的概念,它的输入和输出可以通过一个跨层连接相加的方式,使得网络层数可以增加而不会导致梯度消失或梯度爆炸问题。残差块的具体实现包含了如下的步骤:
对于输入
x
x
x,通过两个卷积层和激活函数得到
F
(
x
)
F(x)
F(x);
将
F
(
x
)
F(x)
F(x) 和输入
x
x
x 相加得到输出
y
y
y。
同时,为了进一步加深网络层数,ResNet 还引入了残差连接(Residual Connection),即将某一层的输出直接加到后面的多层输出中,进一步加强网络的表达能力。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(residual)
out = self.relu(out)
return out
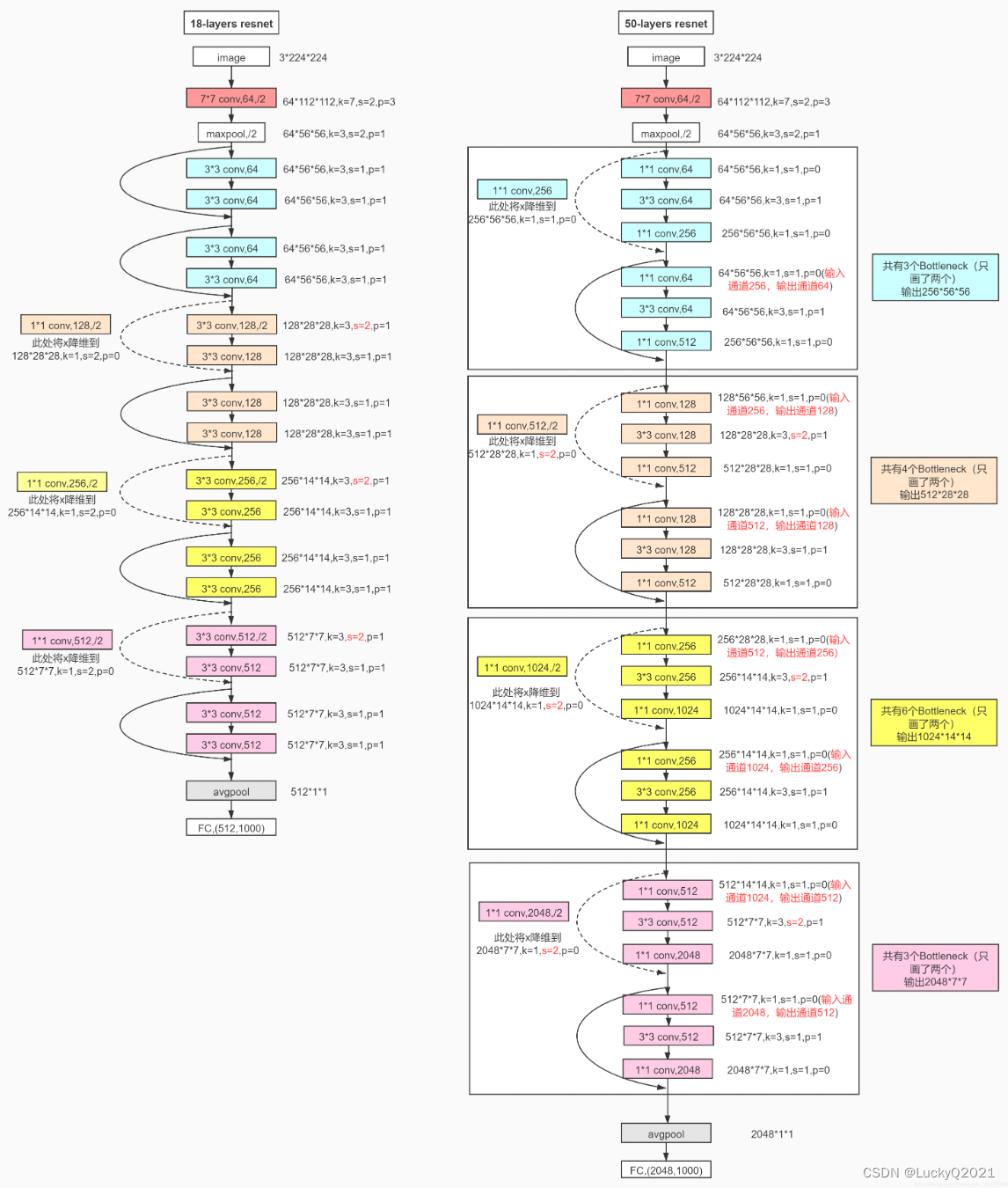
class ResNet18(nn.Module):
def __init__(self, num_classes=10):
super(ResNet18, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1)
self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2)
self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2)
self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
6. GNN:图神经网络
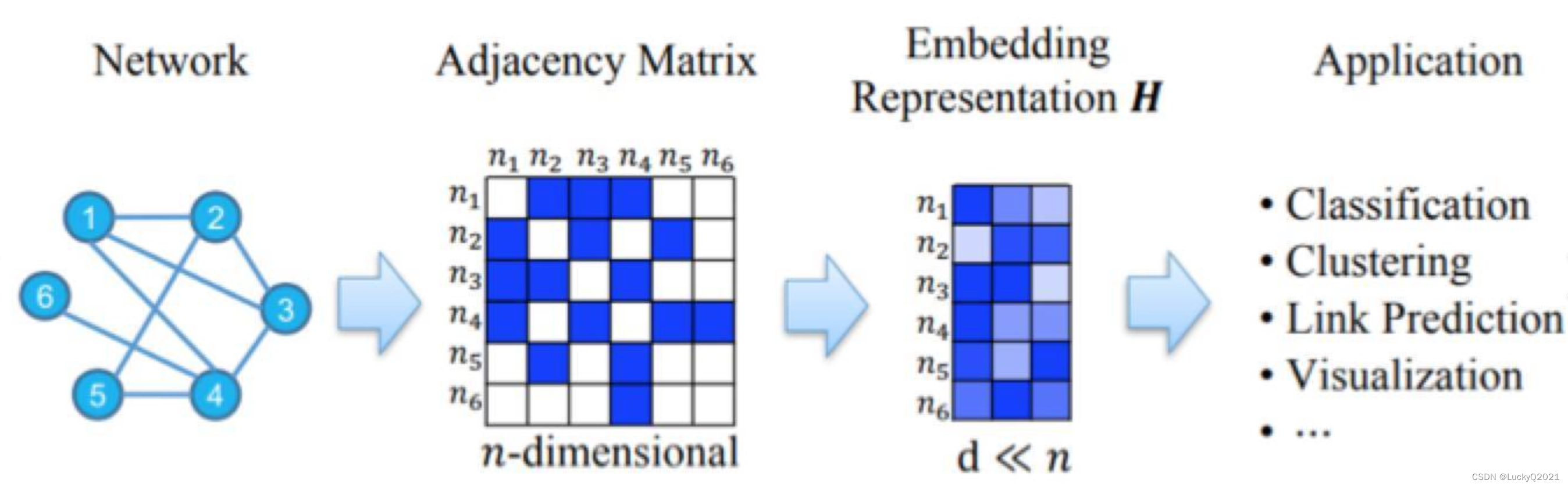
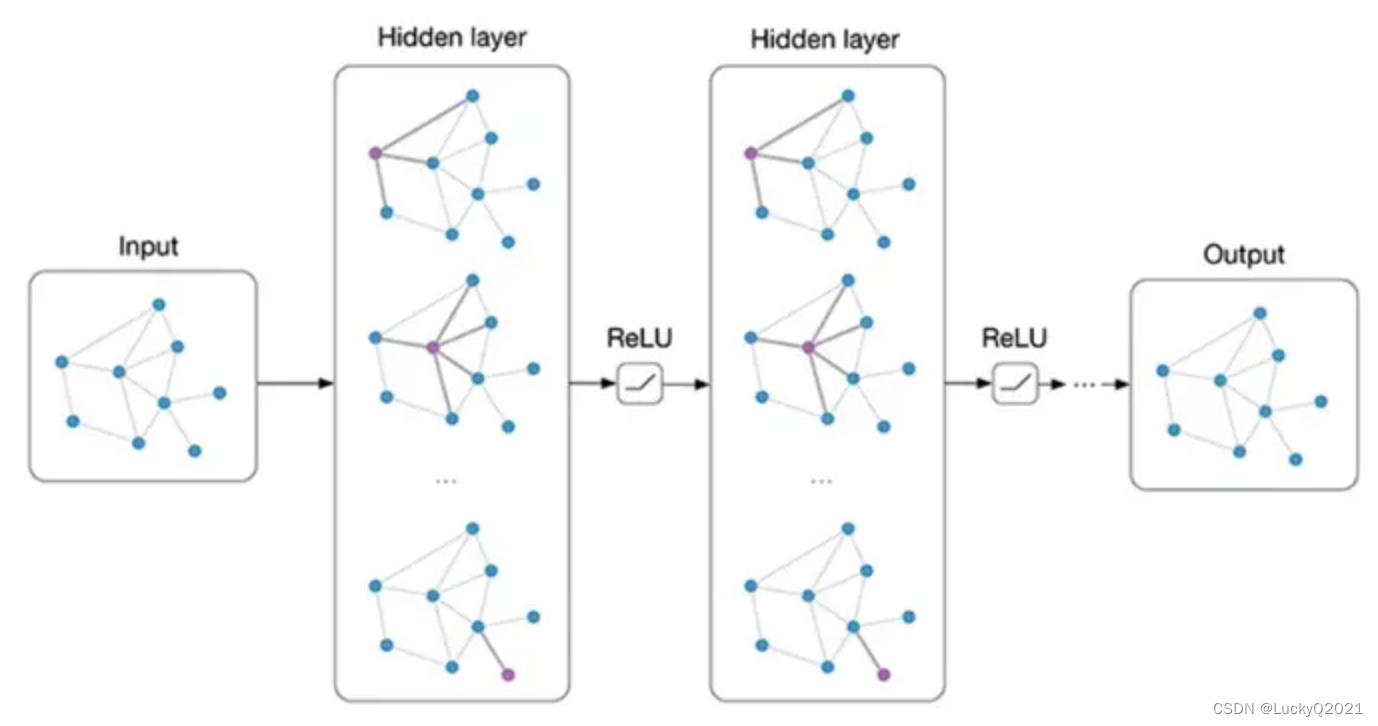
图神经网络(Graph Neural Network,GNN)是一种广泛应用于图数据分析的深度学习模型。它的目标是对图中的节点和边进行分类、回归和聚类等任务。在过去的几年中,图神经网络已经成为了人工智能领域的热门话题之一,被广泛应用于社交网络分析、推荐系统、生物信息学和化学分子分析等领域。
与传统神经网络不同,图神经网络的输入是一个图,其中每个节点代表一个实体,每条边代表实体之间的关系。GNN的主要目标是对每个节点进行编码,以捕获节点与其相邻节点之间的关系。在训练过程中,GNN会通过反向传播算法学习节点之间的相互作用,以提高模型的准确性。
图神经网络的结构通常包含几层,每层都会计算节点的嵌入表示。嵌入表示是一种将节点映射到向量空间的技术,它可以使相似节点在向量空间中更接近,从而提高模型的性能。在每一层中,GNN会计算节点的邻居节点的聚合信息,并将其与当前节点的特征向量进行组合,以获得节点的新嵌入表示。这种聚合方式可以通过不同的机制来实现,包括邻居节点的平均值、加权平均值或最大池化等。
import torch
import torch.nn as nn
import torch.nn.functional as F
class GCNLayer(nn.Module):
def __init__(self, in_features, out_features):
super(GCNLayer, self).__init__()
self.weight = nn.Parameter(torch.Tensor(in_features, out_features))
self.bias = nn.Parameter(torch.Tensor(out_features))
self.reset_parameters()
def reset_parameters(self):
torch.nn.init.xavier_uniform_(self.weight)
torch.nn.init.zeros_(self.bias)
def forward(self, x, adj):
x = torch.matmul(adj, x)
x = torch.matmul(x, self.weight)
x = x + self.bias
return F.relu(x)
class GCN(nn.Module):
def __init__(self, n_feat, n_hid, n_class):
super(GCN, self).__init__()
self.layer1 = GCNLayer(n_feat, n_hid)
self.layer2 = GCNLayer(n_hid, n_class)
def forward(self, x, adj):
x = self.layer1(x, adj)
x = self.layer2(x, adj)
return x
7. GCN(Graph Convolutional Network): 图卷积网络
图卷积网络(Graph Convolutional Network,GCN)是一种用于处理图数据的深度学习模型,它是对传统的卷积神经网络(Convolutional Neural Network,CNN)在图数据上的推广和扩展。GCN 可以对节点和边进行特征提取和表征学习,并用于图的分类、节点分类、链接预测、社区发现等任务。
在 GCN 中,每个节点和它的邻居节点都被视为一个局部的子图,然后通过卷积操作来融合它们的特征信息。GCN 的卷积操作与传统的卷积操作不同,它是基于图上的邻接矩阵进行的。GCN 通过在局部子图上进行卷积操作,将节点的特征信息与它的邻居节点的特征信息进行交互,从而得到更丰富、更具有表征性的节点特征表征。
GCN 的基本原理可以用下面的公式表示:
H ( l + 1 ) = σ ( D ^ − 1 2 A ^ D ^ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma (\hat{D}^{-\frac{1}{2}} \hat{A} \hat{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}) H(l+1)=σ(D^−21A^D^−21H(l)W(l))
其中, H ( l ) H^{(l)} H(l) 表示第 l l l 层的节点特征矩阵, A ^ = A + I \hat{A} = A + I A^=A+I 表示邻接矩阵 A A A 加上自连接矩阵 I I I, D ^ \hat{D} D^ 表示 A ^ \hat{A} A^ 的度矩阵, W ( l ) W^{(l)} W(l) 表示第 l l l 层的权重矩阵, σ \sigma σ 表示激活函数。
GCN 的基本操作可以分为三步:
输入:输入图的邻接矩阵 A A A 和特征矩阵 X X X。
卷积:对 A A A 和 X X X 进行卷积操作,得到新的特征矩阵 H H H。
输出:对 H H H 进行池化、激活、线性变换等操作,得到最终的输出。
值得注意的是,GCN 可以通过堆叠多个卷积层来获得更高层次的特征表征,并且可以通过添加正则化、优化器等操作来提高模型的泛化性能和训练效果。
class GCN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(GCN, self).__init__()
# GCN layer
self.gc1 = nn.Linear(input_dim, hidden_dim)
self.gc2 = nn.Linear(hidden_dim, output_dim)
# ReLU activation function
self.relu = nn.ReLU()
# Softmax classifier
self.softmax = nn.Softmax(dim=1)
def forward(self, adj, features):
# GCN layer
x = self.gc1(features)
x = torch.matmul(adj, x)
x = self.relu(x)
x = self.gc2(x)
# Softmax classifier
output = self.softmax(x)
return output
堆叠多个卷积层的GCN实现
import torch
import torch.nn as nn
class GCN(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim):
super(GCN, self).__init__()
# Define the GCN layers
self.layers = nn.ModuleList([
GCNLayer(in_dim, hidden_dim),
GCNLayer(hidden_dim, out_dim)
])
def forward(self, adj, features):
# Perform multiple GCN layers
for layer in self.layers:
features = layer(adj, features)
return features
class GCNLayer(nn.Module):
def __init__(self, in_dim, out_dim):
super(GCNLayer, self).__init__()
# Define the weight matrix
self.weight = nn.Parameter(torch.FloatTensor(in_dim, out_dim))
# Initialize the weight matrix
nn.init.xavier_uniform_(self.weight)
def forward(self, adj, features):
# Normalize the adjacency matrix
adj = adj + torch.eye(adj.size(0))
rowsum = adj.sum(1)
d_inv_sqrt = torch.pow(rowsum, -0.5)
d_inv_sqrt[torch.isinf(d_inv_sqrt)] = 0.
d_mat_inv_sqrt = torch.diag(d_inv_sqrt)
adj = torch.matmul(torch.matmul(d_mat_inv_sqrt, adj), d_mat_inv_sqrt)
# Perform the GCN operation
features = torch.matmul(adj, torch.matmul(features, self.weight))
# Apply ReLU activation
features = nn.functional.relu(features)
return features
PointNet: 指针网络
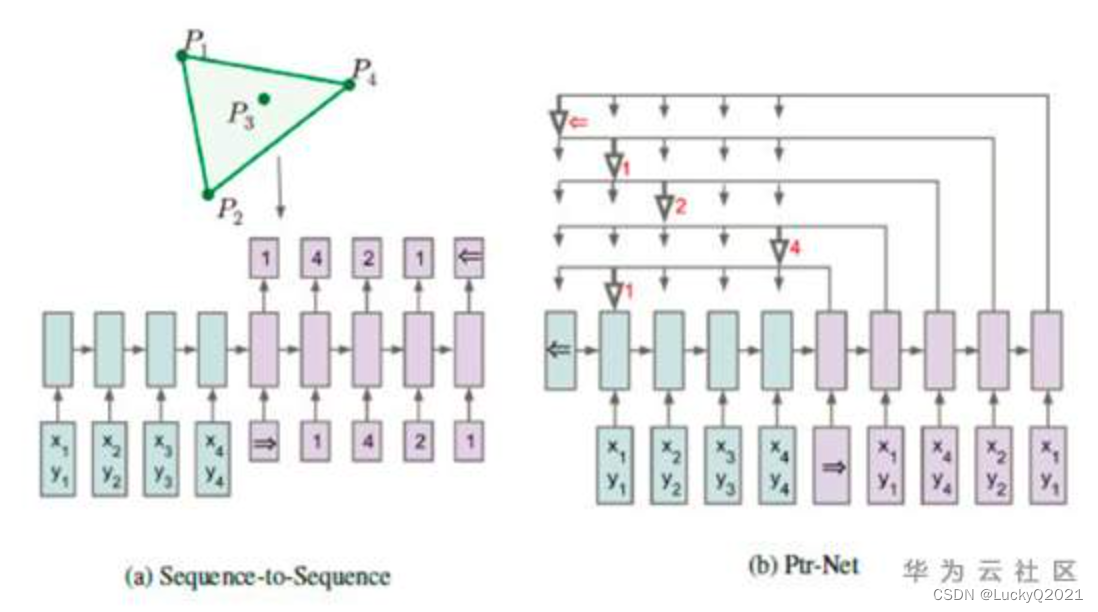
指针网络(Pointer Network)是一种神经网络结构,用于解决序列到序列(Sequence-to-Sequence)的问题,它在许多自然语言处理任务中都表现出色。相比于传统的序列到序列模型,指针网络具有更好的泛化能力和更高的效率。
指针网络最初由 Google 在 2015 年提出,其主要思想是在解码器中使用指针,而不是像传统的序列到序列模型一样使用 softmax 函数来对词表中的每个单词进行打分。在指针网络中,每个时间步都会输出一个指针,指向输入序列中的一个位置。这个指针可以被看作是一个选择器,它决定了哪个输入位置是当前最佳的输出。
指针网络通常用于处理诸如文本摘要、自然语言推理、问答等任务,其中输入和输出序列的长度可以变化。指针网络的优点在于它可以有效地处理变长的输入和输出序列,并且它的输出可以是一个序列中的任意位置,而不仅仅是词表中的某个词。
指针网络的主要优点包括:
- 可以处理变长的输入和输出序列。
- 可以输出任意位置的结果,而不仅仅是词表中的某个词。
- 可以直接使用输入序列中的信息,而不需要将其转换为向量。
指针网络的主要缺点包括:
- 训练过程中可能出现指针漂移的问题,即指针会偏向输入序列中的某些位置而不是正确的位置。
- 训练过程中需要大量的数据和计算资源。
在实践中,指针网络通常与其他模型结构一起使用,例如注意力机制、卷积神经网络和循环神经网络。指针网络的许多变体已经被提出,例如双向指针网络和多层指针网络,这些变体可以进一步提高模型的性能和泛化能力。
import torch
import torch.nn as nn
import torch.nn.functional as F
class PointerNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(PointerNetwork, self).__init__()
self.encoder = nn.LSTM(input_dim, hidden_dim, batch_first=True, bidirectional=True)
self.decoder = nn.LSTM(input_dim, hidden_dim*2, batch_first=True)
self.linear = nn.Linear(hidden_dim*2, 1)
self.hidden_dim = hidden_dim
def forward(self, inputs):
batch_size, seq_len, input_dim = inputs.size()
encoder_outputs, (h, c) = self.encoder(inputs)
decoder_input = torch.zeros(batch_size, input_dim).to(inputs.device)
decoder_hidden = (h[-2:].transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_dim),
c[-2:].transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_dim))
scores = []
pointers = []
for i in range(seq_len):
decoder_output, decoder_hidden = self.decoder(decoder_input.unsqueeze(1), decoder_hidden)
energy = self.linear(decoder_output.squeeze(1))
score = F.softmax(energy, dim=1)
pointer = torch.bmm(score.unsqueeze(1), encoder_outputs).squeeze(1)
scores.append(score)
pointers.append(pointer)
decoder_input = pointer
return torch.stack(scores, dim=1), torch.stack(pointers, dim=1)















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









