







1. 强化学习的基础架构
强化学习是一种人工智能领域的学习方法,它的目标是让智能体(agent)通过与环境交互来最大化累积的奖励(reward)。
在强化学习中,智能体通过不断与环境交互,从中获取反馈信号,以调整自身的行为策略,使得未来获得的奖励最大化。智能体在环境中执行一个动作,环境根据该动作返回一个奖励信号以及下一时刻的状态,智能体根据当前的状态以及奖励信号来选择下一个动作,如此不断地交互下去,直到任务完成。
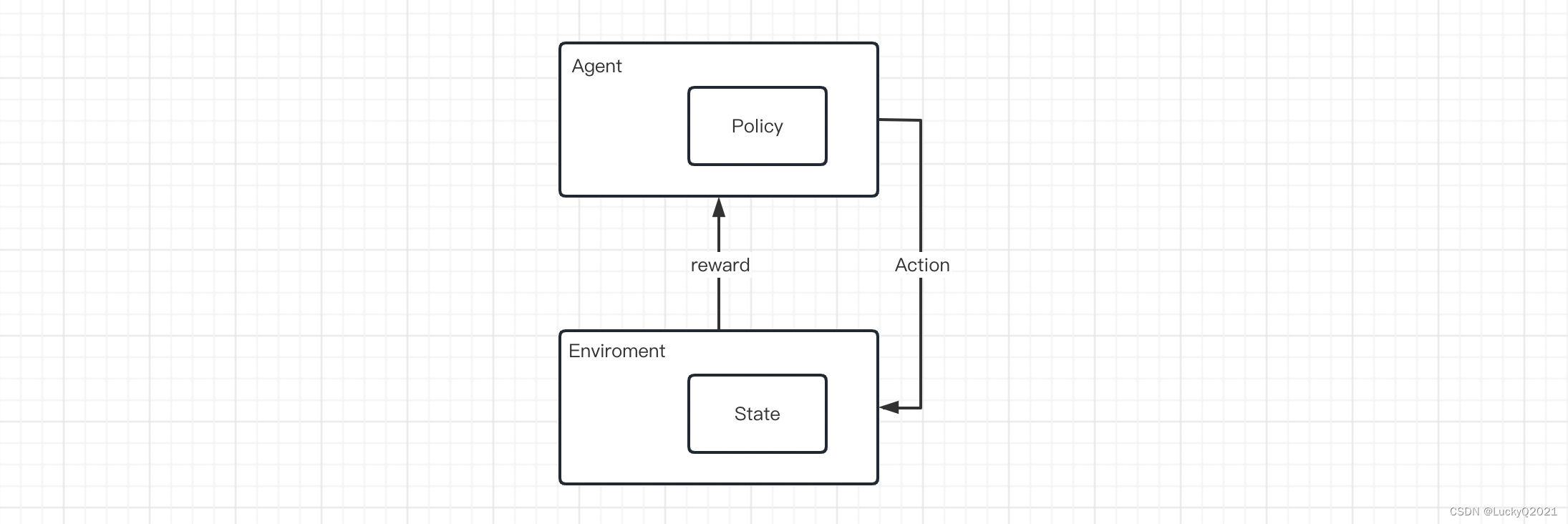
强化学习中的主要元素包括:
- 环境(environment):智能体与之交互的外部世界,它包含了状态、动作和奖励等信息。
- 状态(state):环境的一种表示,描述了环境的某个特定时刻的状态。
- 智能体(agent):决策者,它的目标是从环境中学习一个最优的行为策略,使得未来获得的累积奖励最大化。
- 策略(policy):智能体的行为策略,用于选择下一步要执行的动作,以最大化未来的奖励。
- 动作(action):智能体可以执行的操作,用于改变环境的状态。
- 奖励(reward):智能体根据执行某个动作而获得的反馈信号,通常是一个数值表示执行该动作的好坏。
2. 强化学习的主流方法
2.1 Q-learning
2.1.1 算法介绍
Q-learning是一种基于动作-值函数(Q函数)的强化学习方法,它通过不断更新Q函数来学习最优的行为策略。
所谓Q函数本质上是一个表格,表示在某个状态下执行某个动作所能获得的累积奖励,Q-Learning的核心是不断更新这个Q Table 来完成动作-值的更新。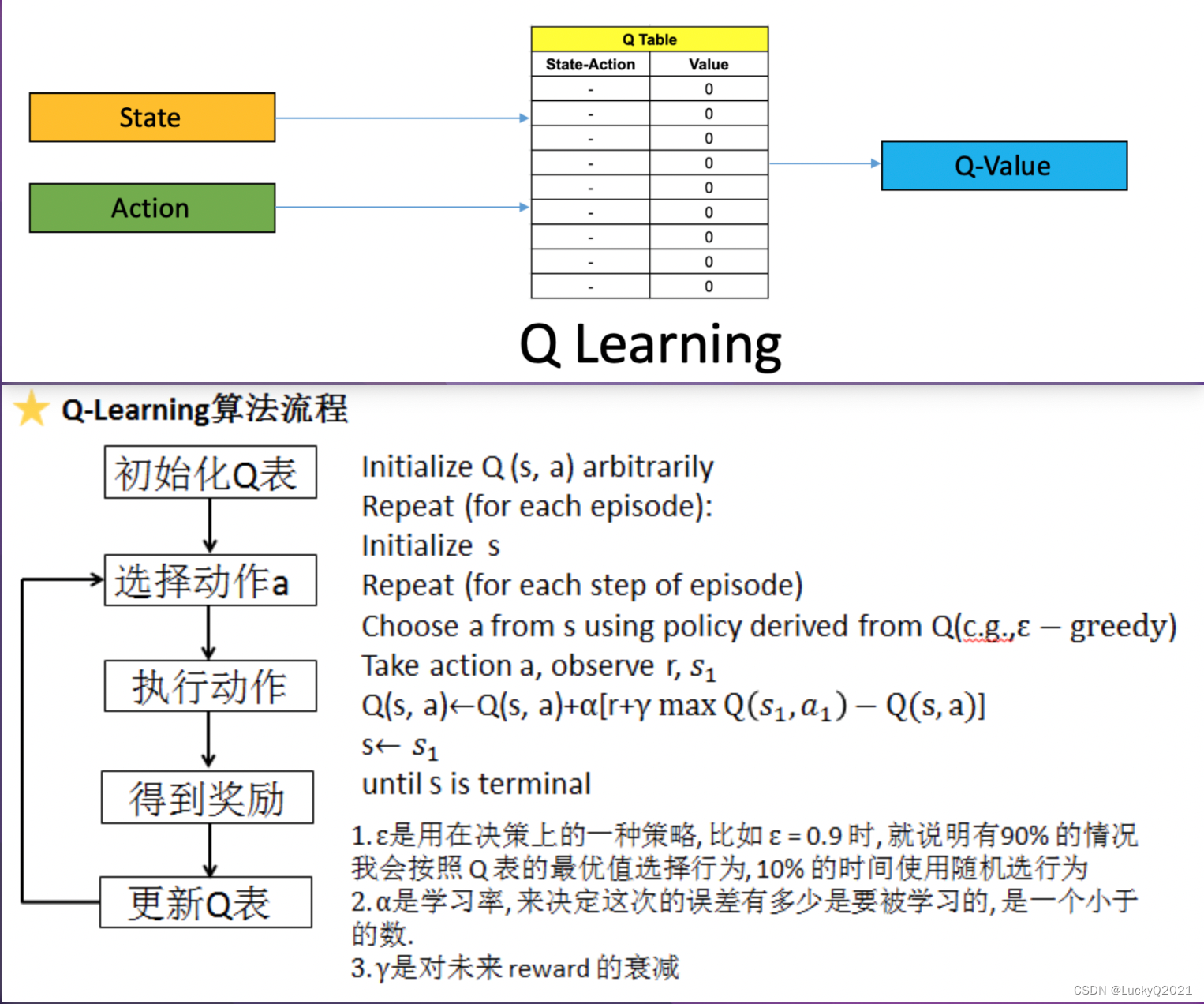
Q-Learning的主要流程如下:
- 初始化Q函数:在开始学习之前,需要初始化Q函数,通常将Q函数的值设为0或者随机值。
- 环境交互:智能体与环境交互,执行一个动作,并且获取环境返回的奖励和下一个状态。
- 更新Q函数:根据当前的状态、动作、奖励和下一个状态,更新Q函数的值。具体的更新公式为:Q(s,a) = Q(s,a) + alpha * (reward + gamma * max[Q(s’,a’)] - Q(s,a))
- 其中,s表示当前状态,a表示当前动作,s’表示下一个状态,a’表示下一个状态下的最优动作,alpha表示学习率(控制每次更新的步长),gamma表示折扣因子(控制未来奖励的重要程度)。
- 选择下一个动作:根据当前状态和Q函数,选择下一个动作,通常采用epsilon-greedy策略,即以一定的概率随机选择动作(探索),以一定的概率选择当前Q值最大的动作(利用)。
循环执行2-4步,直到学习结束。
2.1.2 算法流程举例
假设我们要使用Q-Learning学习一个迷宫游戏:
(1)首先,我们需要定义迷宫的状态空间和动作空间。假设迷宫是一个5x5的网格,智能体可以执行4个动作:上、下、左、右。我们可以用一个5x5的矩阵表示状态空间,0表示空格子,1表示障碍物,2表示终点。例如,下面是一个迷宫的状态空间:
0 0 0 1 0
0 1 0 1 0
0 1 0 1 0
0 1 0 1 0
0 0 0 2 0
(2)接下来,我们需要初始化Q函数。假设我们使用一个5x5x4的数组来表示Q函数,第一维表示状态,第二维表示动作,第三维表示Q值。初始时,我们可以将所有的Q值设为0。
(3)环境交互。智能体从起点开始,不断执行动作,直到到达终点。每次执行一个动作,智能体会得到一个奖励(如果到达了终点,奖励为1,否则奖励为0),并进入下一个状态。例如,智能体可以从(0, 0)出发,先执行向右的动作,然后到达(0, 1)。假设这一步的奖励为0,那么智能体当前的状态就是(0, 1)。
(4)更新Q函数。根据当前状态、执行的动作、奖励和下一个状态,可以使用Q-Learning更新Q函数的值。例如,假设智能体在状态(0, 0)执行了向右的动作,到达了状态(0, 1),奖励为0,下一个最优动作是向下。那么我们可以使用下面的公式来更新Q函数:
Q(0, 0, 1) = Q(0, 0, 1) + alpha * (0 + gamma * max[Q(0, 1, 0), Q(0, 1, 1), Q(0, 1, 2), Q(0, 1, 3)] - Q(0, 0, 1))
其中,最后一维的0,1,2,3分别代表上右下左四个动作
(5)选择下一个动作。根据当前状态和Q函数,可以使用epsilon-greedy策略来选择下一个动作。即以一定的概率随机选择一个动作,以一定的概率选择当前Q值最大的动作。
可以设置一个递减的epsilon值,让随机选择动作的概率随着训练次数的增加而减小。例如,开始时可以将epsilon设置为1,然后每训练一次就将epsilon减小一个小的值,直到最后变成一个很小的值。
2.1.3 简化版代码实现
import numpy as np
# 定义状态空间和动作空间
maze = np.array([
[0, 0, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 0, 0, 2, 0]
])
n_states = 5 * 5
n_actions = 4
# 初始化Q函数
Q = np.zeros((n_states, n_actions))
# 定义超参数
alpha = 0.1
gamma = 0.9
epsilon = 1.0
epsilon_decay = 0.001
# 定义epsilon-greedy策略
def choose_action(state):
if np.random.uniform(0, 1) < epsilon:
action = np.random.choice(n_actions)
else:
action = np.argmax(Q[state])
return action
# 循环训练
n_episodes = 1000
for episode in range(n_episodes):
# 重置状态
state = 0
# 环境交互
while maze.flat[state] != 2:
action = choose_action(state)
next_state = np.clip({
0: state - 5,
1: state + 1,
2: state + 5,
3: state - 1
}[action], 0, 24)
reward = int(maze.flat[next_state] == 2)
# 更新Q函数
Q[state][action] = Q[state][action] + alpha * (reward + gamma * np.max(Q[next_state]) - Q[state][action])
# 转移状态
state = next_state
# 调整epsilon值
epsilon = max(0.1, epsilon - epsilon_decay)
注意,上述代码中没有考虑障碍物对智能体的影响。如果智能体走到了一个障碍物,那么它应该停留在原地,不应该转移到下一个状态。可以根据具体情况对代码进行修改。
2.1.4 算法评价
Q-Learning的优点在于可以学习任何形式的策略,并且具有良好的收敛性质。但是,它也有一些局限性,例如需要离散化状态空间和动作空间、难以处理连续状态空间和动作空间等问题。
2.2 策略梯度(Policy Gradient)
策略梯度(Policy Gradient)是一种基于梯度优化的强化学习算法,它的目标是直接学习策略函数(policy function),而不是学习值函数(value function)。策略函数是一个映射,将当前状态映射到一个动作的概率分布。策略梯度算法的目标是最大化期望累积回报(expected cumulative reward),这个期望是在策略函数下采样得到的。
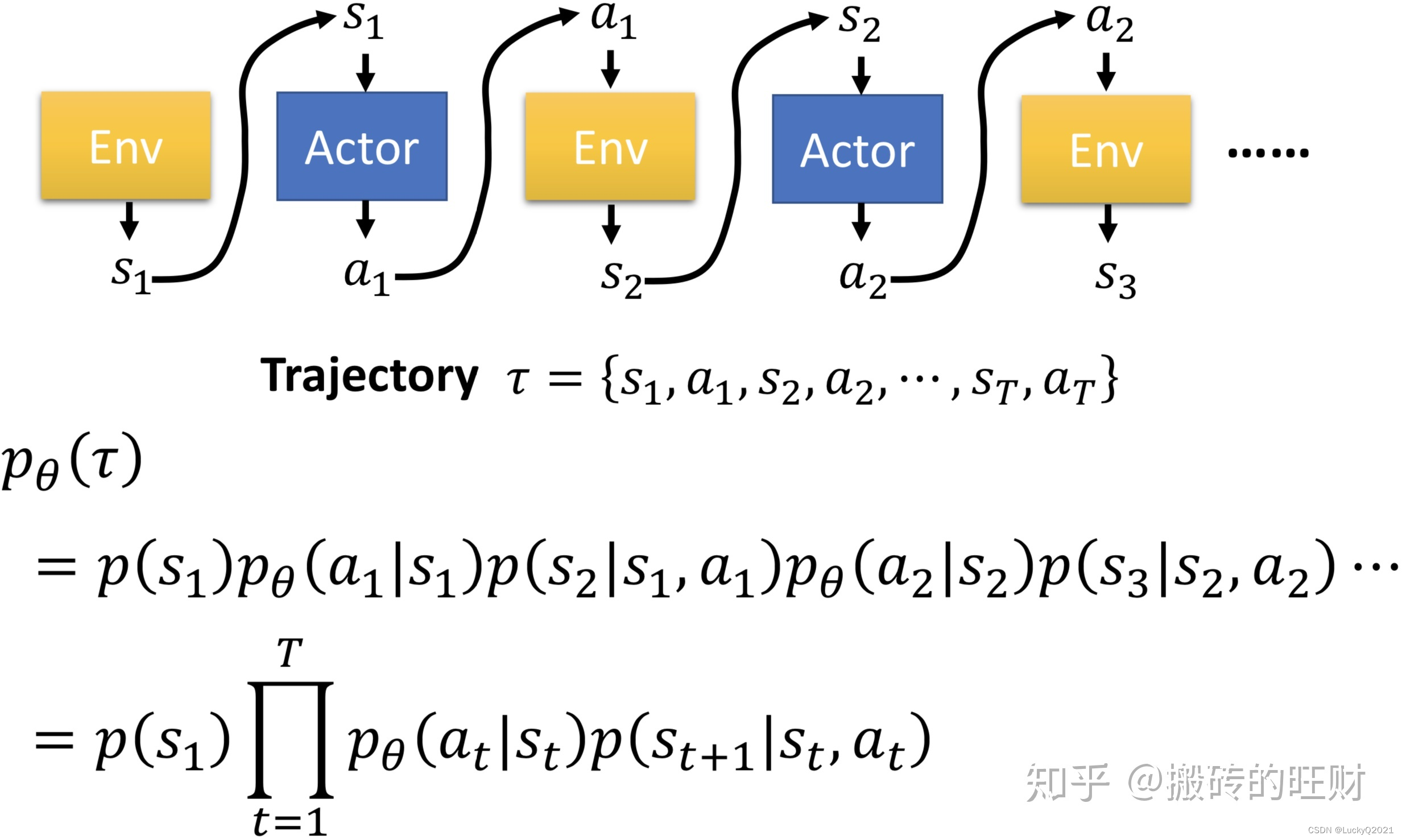
策略梯度的算法框架如下:
- 初始化策略函数的参数。
- 生成一批轨迹,即从起始状态开始,通过执行策略函数生成动作序列,直到到达终止状态,将得到的回报作为这个轨迹的价值。
- 对所有轨迹的回报进行标准化处理,使其均值为0,标准差为1。
- 计算所有轨迹中每个状态-动作对的梯度,并对所有梯度进行加权平均,得到策略梯度的方向。
- 使用梯度上升法更新策略函数的参数,使得策略函数的期望累积回报最大化。
重复步骤2~5,直到策略函数的性能收敛或者达到最大迭代次数。
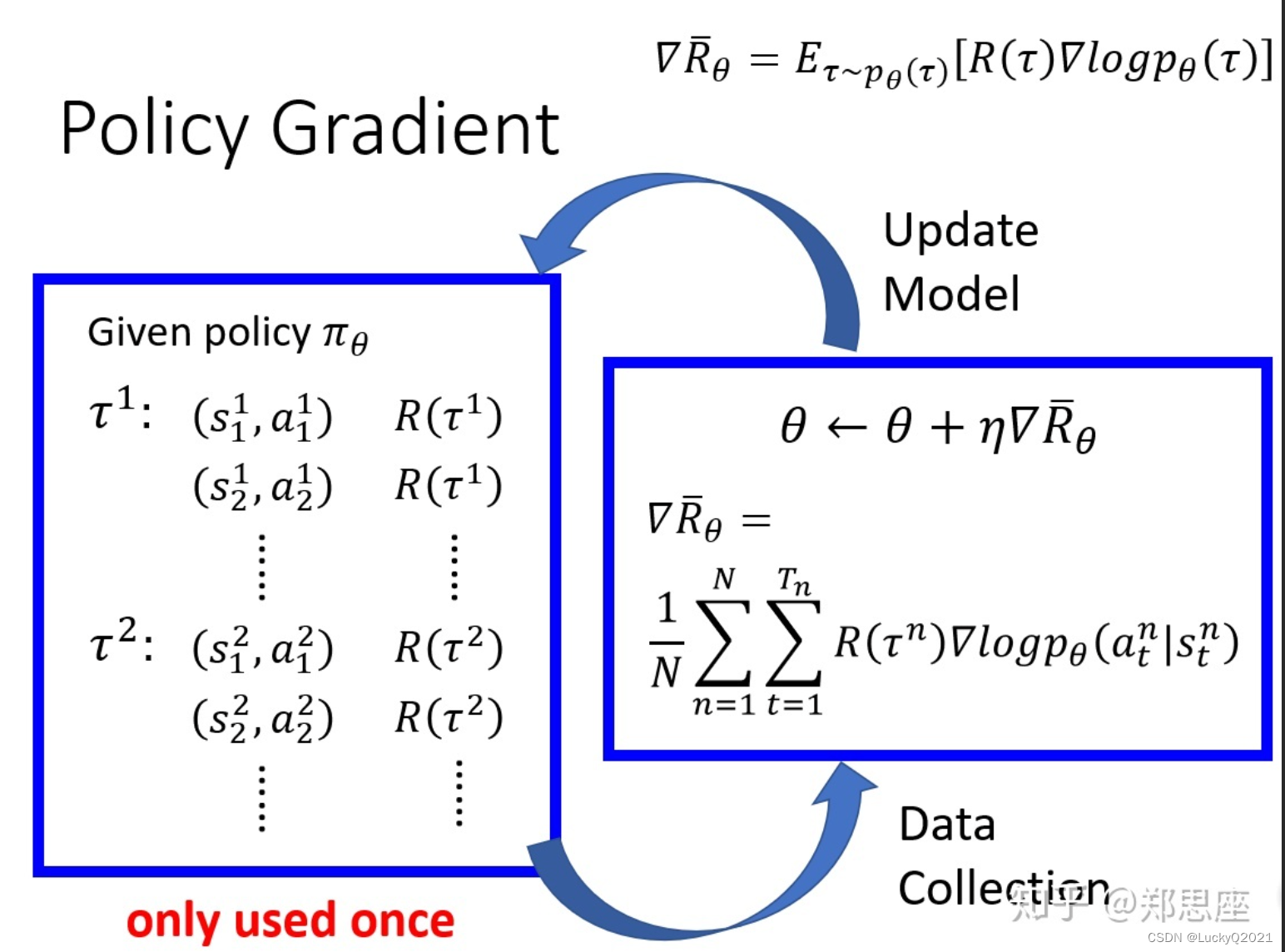
策略梯度算法的核心是计算梯度方向,即如何更新策略函数的参数以优化预期的回报。梯度方向的计算通常使用策略梯度定理(Policy Gradient Theorem),其公式如下:
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 0 T ∇ θ log π θ ( a t ( i ) ∣ s t ( i ) ) R ( i ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^N \sum_{t=0}^T \nabla_{\theta} \log \pi_{\theta}(a_t^{(i)}|s_t^{(i)}) R^{(i)} ∇θJ(θ)≈N1i=1∑Nt=0∑T∇θlogπθ(at(i)∣st(i))R(i)
其中, ∇ θ J ( θ ) \nabla_{\theta} J(\theta) ∇θJ(θ) 表示要更新的参数的梯度方向, J ( θ ) J(\theta) J(θ) 表示预期的回报, π θ ( a t ( i ) ∣ s t ( i ) ) \pi_{\theta}(a_t^{(i)}|s_t^{(i)}) πθ(at(i)∣st(i)) 表示在状态 s t ( i ) s_t^{(i)} st(i) 下,根据策略函数 π θ \pi_{\theta} πθ 采取动作 a t ( i ) a_t^{(i)} at(i) 的概率, R ( i ) R^{(i)} R(i) 表示第 i i i 条采样轨迹的总回报。
上式中, log π θ ( a t ( i ) ∣ s t ( i ) ) \log \pi_{\theta}(a_t^{(i)}|s_t^{(i)}) logπθ(at(i)∣st(i)) 表示采取动作 a t ( i ) a_t^{(i)} at(i) 的概率的对数,而 ∇ θ log π θ ( a t ( i ) ∣ s t ( i ) ) \nabla_{\theta} \log \pi_{\theta}(a_t^{(i)}|s_t^{(i)}) ∇θlogπθ(at(i)∣st(i)) 表示对应的梯度向量。这个梯度向量可以使用自动微分或符号微分方法进行计算。
需要注意的是,上述公式是使用蒙特卡洛采样的策略梯度算法(也称为REINFORCE算法)的公式,它的更新方向具有较大的方差,不太稳定。在实际中,为了增加计算的效率和更新的稳定性,可以采用基于价值函数或基于策略梯度定理的Actor-Critic等策略梯度算法的改进版本,以获取更好的训练效果。
2.2.1 简化代码实现
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
class Policy(nn.Module):
def __init__(self, n_states, n_actions):
super(Policy, self).__init__()
self.fc1 = nn.Linear(n_states, 10)
self.fc2 = nn.Linear(10, n_actions)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.softmax(self.fc2(x), dim=0)
return x
class PolicyGradientAgent:
def __init__(self, env, learning_rate=0.01, reward_decay=0.95):
self.env = env
self.n_actions = env.action_space.n
self.n_states = env.observation_space.shape[0]
self.lr = learning_rate
self.gamma = reward_decay
# 创建策略网络
self.policy_network = Policy(self.n_states, self.n_actions)
self.optimizer = optim.Adam(self.policy_network.parameters(), lr=self.lr)
def choose_action(self, state):
# 根据当前状态选择一个动作
state = torch.from_numpy(state).float().unsqueeze(0)
action_probs = self.policy_network(state)[0]
action = np.random.choice(range(self.n_actions), p=action_probs.detach().numpy())
return action
def store_transition(self, state, action, reward):
# 存储每一步的状态、动作和回报
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
def learn(self):
# 计算折扣回报
discounted_rewards = self.discount_and_norm_rewards()
# 将状态、动作、回报转换为tensor
states = torch.tensor(self.states)
actions = torch.tensor(self.actions)
rewards = torch.tensor(discounted_rewards)
# 计算损失
log_probs = self.policy_network(states).gather(1, actions.view(-1, 1))
loss = -torch.mean(log_probs * rewards)
# 梯度下降更新策略网络
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 清空经验池
self.states, self.actions, self.rewards = [], [], []
def discount_and_norm_rewards(self):
# 计算折扣回报
discounted_rewards = np.zeros_like(self.rewards)
running_add = 0
for t in reversed(range(len(self.rewards))):
running_add = running_add * self.gamma + self.rewards[t]
discounted_rewards[t] = running_add
# 归一化处理
discounted_rewards -= np.mean(discounted_rewards)
discounted_rewards /= np.std(discounted_rewards)
return discounted_rewards
def train(env, agent, max_episodes, max_episode_steps):
scores = []
for i in range(max_episodes):
state = env.reset()
score = 0
for j in range(max_episode_steps):
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
agent.store_transition(state, action, reward)
state = next_state
score += reward
if done or j == max_episode_steps - 1:
agent.learn()
scores.append(score)
print('Episode: {} | Score: {:.2f}'.format(i, score))
break
return scores
2.3 Actor-Critic
Actor-Critic是一种结合了策略梯度和值函数的强化学习方法,它既能学习最优的行为策略,又能学习价值函数,从而更加稳定和高效地学习。
Actor-Critic算法中的“Actor”指的是策略网络,它类似于策略梯度算法中的神经网络,负责选择动作。而“Critic”指的是值函数网络,用来估计当前状态的价值,并提供一个基准来指导策略的更新。
Actor-Critic算法有很多变体,如N步Actor-Critic算法、异步Actor-Critic算法、连续动作空间的Actor-Critic算法等等。其中最基本的版本称为“单步Actor-Critic算法”,它的具体实现如下:
- 初始化策略网络和值函数网络;
- 对于每个回合,执行以下操作:
- 初始化环境和状态;
- 在当前策略下选择一个动作;
- 执行动作并观察下一个状态和奖励;
- 计算当前状态的价值,即使用值函数网络估计当前状态的状态值或动作值;
- 计算当前状态的优势函数,即当前状态的价值减去基准价值;
- 使用当前状态、动作、优势函数和奖励来计算损失函数;
- 使用损失函数对策略网络和值函数网络进行反向传播更新参数;
- 重复执行步骤2,直到训练结束。
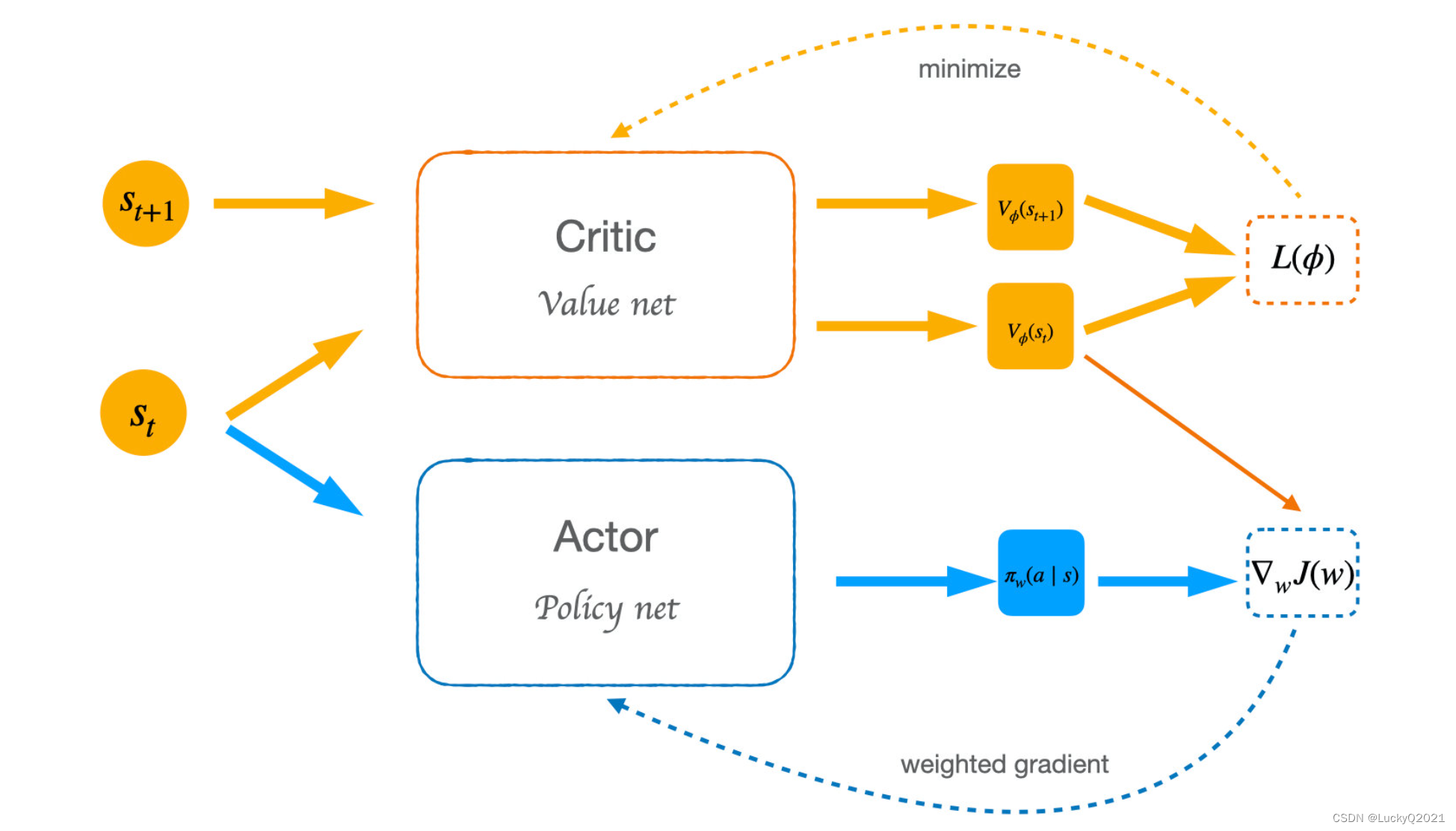
Actor-Critic算法的数学原理可以用下面的公式描述:
Δ θ = α ∇ θ log π θ ( s , a ) ( Q π ( s , a ) − V π ( s ) ) \Delta\theta=\alpha\nabla_{\theta}\log\pi_{\theta}(s,a)(Q^{\pi}(s,a)-V^{\pi}(s)) Δθ=α∇θlogπθ(s,a)(Qπ(s,a)−Vπ(s))
其中, Δ θ \Delta\theta Δθ表示策略的改进量, α \alpha α表示学习率, ∇ θ log π θ ( s , a ) \nabla_{\theta}\log\pi_{\theta}(s,a) ∇θlogπθ(s,a)表示策略在状态 s s s下采取行动 a a a的概率的梯度, Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)表示在状态 s s s下采取行动 a a a的回报期望, V π ( s ) V^{\pi}(s) Vπ(s)表示在状态 s s s下采取最优行动的回报期望。公式的意思是:Actor根据当前状态 s s s和采取的行动 a a a,计算出策略的梯度,并根据Critic评估的 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)和 V π ( s ) V^{\pi}(s) Vπ(s),更新策略的参数 θ \theta θ,从而使得Actor的策略更加接近于最优策略。
2.3.1 简化版代码实现
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
class ActorCritic(nn.Module):
def __init__(self, input_size, output_size, hidden_size=128):
super(ActorCritic, self).__init__()
self.actor = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size),
nn.Softmax(dim=-1)
)
self.critic = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
def forward(self, x):
return self.actor(x), self.critic(x)
def train(env, ac, gamma=0.99, num_episodes=1000, lr=0.001):
optimizer = optim.Adam(ac.parameters(), lr=lr)
criterion = nn.SmoothL1Loss()
for episode in range(num_episodes):
obs = env.reset()
done = False
ep_reward = 0
while not done:
action_prob, value = ac(torch.from_numpy(obs).float())
action = np.random.choice(len(action_prob), p=action_prob.detach().numpy())
next_obs, reward, done, _ = env.step(action)
ep_reward += reward
_, next_value = ac(torch.from_numpy(next_obs).float())
if done:
target = torch.Tensor([reward])
else:
target = reward + gamma * next_value.detach()
td_error = target - value
actor_loss = -torch.log(action_prob[action]) * td_error.detach()
critic_loss = criterion(value, target)
loss = actor_loss + critic_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
obs = next_obs
print("Episode {}: Reward = {}".format(episode+1, ep_reward))
在训练期间,我们还需要维护一个经验回放缓冲区。每个时间步,我们将当前状态、动作、奖励和下一个状态存储在回放缓冲区中。当我们训练策略和值函数网络时,我们可以从回放缓冲区中随机采样一批数据,并使用它们来更新网络。
2.4 深度强化学习(Deep Reinforcement Learning)
将深度学习方法应用到强化学习中的一种方法,通过使用深度神经网络来表示策略函数或值函数,从而更好地处理高维状态空间和连续动作空间的问题。
2.4.1 DQN(Deep Q-Networks)
深度强化学习中最经典的算法之一,其核心思想是使用深度神经网络来近似Q值函数,通过策略改进的方式不断提高策略的性能。
DQN(Deep Q-Networks)是一种深度强化学习算法,是利用神经网络近似Q-learning的一种方法。DQN主要解决了Q-learning算法在高维状态空间下无法有效应用的问题。
DQN算法的主要思路是使用一个神经网络来逼近Q函数,将状态作为神经网络的输入,输出为每个动作的Q值。在训练时,使用经验回放机制和目标网络来提高训练效果。
具体来说,DQN算法使用一个神经网络来近似Q函数,将状态作为输入,输出每个动作的Q值。神经网络的训练目标是最小化Q值与目标Q值之间的均方误差,其中目标Q值由当前状态和下一状态的最大Q值计算得出。为了提高训练效率和稳定性,DQN算法使用了两个技术:经验回放和目标网络。
经验回放是一种存储和重用过去的经验的方法。在训练时,DQN算法将智能体与环境的交互过程中的经验存储在一个经验回放池中,并从中随机选择一批经验进行训练。这样做的好处是可以使数据更充分地利用,并且减少数据之间的相关性。
目标网络是另外一个神经网络,它的参数与主网络参数相同,但是在训练过程中不会被更新,而是定期从主网络复制一份参数。这样做的好处是可以使目标Q值更加稳定,减少训练过程中的波动。
总之,DQN算法通过使用深度神经网络逼近Q函数,使用经验回放和目标网络来提高训练效率和稳定性,能够有效地解决高维状态空间下的强化学习问题。它是深度强化学习中一种非常有效的算法,在许多复杂任务上取得了成功。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
class DQN(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=64):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, state):
return self.net(state)
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))
return np.array(state), np.array(action), np.array(reward), np.array(next_state), np.array(done)
def __len__(self):
return len(self.buffer)
class DQNAgent:
def __init__(self, state_dim, action_dim, lr=0.001, gamma=0.99, epsilon=1.0, epsilon_decay=0.995, epsilon_min=0.01, target_update=10, batch_size=64, memory_capacity=10000):
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_decay = epsilon_decay
self.epsilon_min = epsilon_min
self.target_update = target_update
self.batch_size = batch_size
self.memory = ReplayBuffer(memory_capacity)
self.q_net = DQN(state_dim, action_dim)
self.target_net = DQN(state_dim, action_dim)
self.target_net.load_state_dict(self.q_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.q_net.parameters(), lr=lr)
self.loss_fn = nn.MSELoss()
self.total_reward = 0
def get_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(self.action_dim)
with torch.no_grad():
q_values = self.q_net(torch.tensor(state, dtype=torch.float))
return q_values.argmax().item()
def train(self):
if len(self.memory) < self.batch_size:
return
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
self.total_rewards += rewards
with torch.no_grad():
max_q_values = self.target_net(torch.tensor(next_states, dtype=torch.float)).max(dim=1)[0]
target_q_values = rewards + self.gamma * max_q_values * (1 - dones)
q_values = self.q_net(torch.tensor(states, dtype=torch.float)).gather(1, torch.tensor(actions, dtype=torch.long).unsqueeze(1)).squeeze()
loss = self.loss_fn(q_values, target_q_values)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
if self.target_update > 0 and self.memory.__len__() % self.target_update == 0:
self.target_net.load_state_dict(self.q_net.state_dict())
return self.total_rewards
def store_transition(self, state, action, reward, next_state, done):
self.memory.push(state, action, reward, next_state, done)
def main():
env = gym.make('CartPole-v0')
batch_size = 32
gamma = 0.99
dqn_agent = DQNAgent(state_dim=env.observation_space.shape[0], action_dim=env.action_space.n, lr=1e-3, gamma=gamme, batch_size=batch_size)
num_episodes = 1000
for episode in range(num_episodes):
episode_reward = dqn_agent.train()
print("Episode:", episode, "Reward:", episode_reward)
env.close()
在DQN算法中,我们使用两个神经网络来估计 Q 值函数:一个是当前估计的 Q 网络,另一个是目标 Q 网络。这是为了解决 Q 学习算法中使用同一个 Q 网络估计目标值和估计值时的不稳定性问题。
Q 网络的参数
θ
\theta
θ 更新使用的是以下公式:
θ
t
+
1
=
θ
t
+
α
(
r
+
γ
Q
θ
t
(
s
′
,
a
′
)
−
Q
θ
t
(
s
,
a
)
)
∇
θ
Q
θ
t
(
s
,
a
)
\theta_{t+1} = \theta_{t} + \alpha(r+ \gamma Q_{\theta{t}}(s', a') - Q_{\theta{t}}(s, a))\nabla_{\theta}Q_{\theta{t}}(s, a)
θt+1=θt+α(r+γQθt(s′,a′)−Qθt(s,a))∇θQθt(s,a)
其中,
α
\alpha
α 是学习率,
r
r
r 是当前状态下的奖励值,
γ
\gamma
γ 是折扣因子,表示对于未来奖励的考虑程度,
s
s
s 是当前状态,
a
a
a 是在
s
s
s 状态下的动作,
s
′
s'
s′ 是执行动作
a
a
a 后的下一个状态,
max
a
′
Q
θ
t
(
s
′
,
a
′
)
\max_{a'} Q_{\theta_t}(s',a')
maxa′Qθt(s′,a′) 表示下一个状态
s
′
s'
s′ 下所有可能的动作
a
′
a'
a′ 的 Q 值中的最大值,
Q
θ
t
(
s
,
a
)
Q_{\theta_t}(s,a)
Qθt(s,a) 表示当前状态和动作的 Q 值。
目标 Q 网络的参数
θ
′
\theta'
θ′ 的更新使用的是以下公式:
θ
t
′
=
τ
θ
t
+
(
1
−
τ
)
θ
t
′
\theta_{t}^{'} = \tau\theta_{t} + (1-\tau)\theta_{t}^{'}
θt′=τθt+(1−τ)θt′
其中,
τ
\tau
τ 是一个小于 1 的参数,用于平滑地更新目标网络的参数,通常取 0.01 或更小的值。
可以将目标 Q 网络理解为固定不变的“银行家”,它给出一个“稳妥”的估计,而 Q 网络则充当“投资人”,不断调整自己的估计。在训练过程中,Q 网络的参数会不断地被更新,而目标 Q 网络的参数只是慢慢地向 Q 网络的参数靠近,这样可以避免过度的拟合和震荡,提高训练的稳定性。
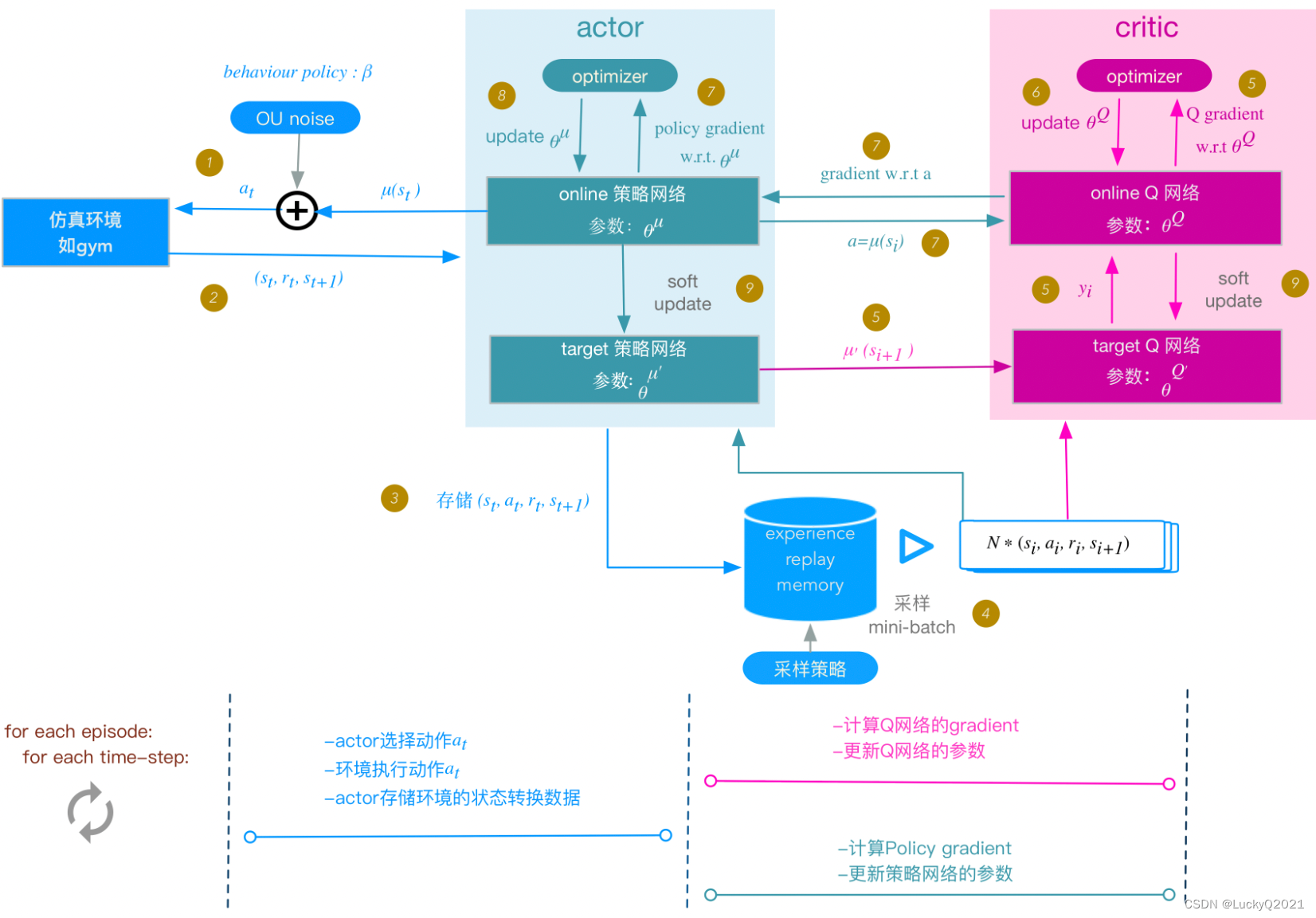
2.4.2 DDPG(Deep Deterministic Policy Gradient)
主要解决连续动作空间问题,使用Actor-Critic结构,将连续的动作空间转化为连续的动作值,并通过反馈更新Actor和Critic的权重参数。
DDPG算法使用一个Actor网络和一个Critic网络,其中Actor网络是一个策略函数,它接收状态作为输入,输出对应动作的概率分布;Critic网络是一个价值函数,它接收状态和动作作为输入,输出对应的Q值。这两个网络都是深度神经网络,因此可以处理高维、复杂的状态空间和动作空间。
DDPG算法中,Actor网络的目标是最大化Q值,即最大化期望回报。为了实现这一点,Actor网络采用了一种叫做确定性策略梯度(Deterministic Policy Gradient,DPG)的方法,它直接输出最优动作,而不是动作的概率分布。Critic网络的目标是学习Q值函数,用于评估Actor网络输出的动作。
DDPG算法使用经验回放机制,这样可以使样本更加独立和随机,从而更好地训练神经网络。DDPG算法还引入了一个Target网络,用于计算目标Q值。Target网络是Critic网络的一个副本,但是它的参数是通过软更新方式得到的,即定期将Critic网络的参数赋值给Target网络。
在每一步中,DDPG算法使用Actor网络选择动作,然后执行动作并观察环境的反馈,将反馈(奖励和下一个状态)存储在经验回放缓冲区中。在训练过程中,DDPG算法从经验回放缓冲区中随机采样一批经验,然后使用它们来更新Actor和Critic网络的参数。
具体地说,更新Critic网络的参数时,DDPG算法使用类似于DQN中的Bellman方程的更新公式,其中目标Q值使用Target网络计算。更新Actor网络的参数时,DDPG算法使用策略梯度算法,其中梯度使用Critic网络计算。此外,为了防止过拟合和提高训练效果,DDPG算法还使用了噪声策略,使得Actor网络的输出更具随机性,从而更好地探索动作空间。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import random
# 经验回放定义
class ReplayBuffer:
def __init__(self, buffer_size, state_dim, action_dim):
self.buffer_size = buffer_size
self.state_dim = state_dim
self.action_dim = action_dim
self.buffer = np.empty((buffer_size, state_dim * 2 + action_dim + 2)) # state, action, reward, next_state, done
self.position = 0
def add(self, state, action, reward, next_state, done):
data = np.hstack((state, action, [reward], next_state, [done]))
self.buffer[self.position % self.buffer_size] = data
self.position += 1
def sample(self, batch_size):
if self.position < batch_size:
raise Exception("not enough data")
idx = np.random.choice(min(self.position, self.buffer_size), batch_size, replace=False)
batch = self.buffer[idx]
state = torch.tensor(batch[:, :self.state_dim], dtype=torch.float)
action = torch.tensor(batch[:, self.state_dim:self.state_dim+self.action_dim], dtype=torch.float)
reward = torch.tensor(batch[:, -3], dtype=torch.float)
next_state = torch.tensor(batch[:, -2-self.state_dim:-2], dtype=torch.float)
done = torch.tensor(batch[:, -1], dtype=torch.float)
return state, action, reward, next_state, done
# 噪声生成
class OrnsteinUhlenbeckProcess:
def __init__(self, size, theta=0.15, sigma=0.2, mu=0.):
self.size = size
self.theta = theta
self.sigma = sigma
self.mu = mu
self.reset()
def reset(self):
self.state = np.ones(self.size) * self.mu
def sample(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(len(x))
self.state = x + dx
return self.state
# 神经网络定义
class ActorNet(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim):
super(ActorNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, action_dim)
self.dropout = nn.Dropout(p=0.1)
def forward(self, state):
x = F.relu(self.fc1(state))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = torch.tanh(self.fc3(x))
return x
class CriticNet(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim):
super(CriticNet, self).__init__()
self.fc1 = nn.Linear(state_dim+action_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
self.dropout = nn.Dropout(p=0.1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
class DDPG:
def __init__(self, state_dim, action_dim, gamma, tau, buffer_size, batch_size, actor_lr, critic_lr):
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma
self.tau = tau
self.buffer_size = buffer_size
self.batch_size = batch_size
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.actor = Actor(self.state_dim, self.action_dim).to(device)
self.actor_target = Actor(self.state_dim, self.action_dim).to(device)
self.critic = Critic(self.state_dim, self.action_dim).to(device)
self.critic_target = Critic(self.state_dim, self.action_dim).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=self.actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=self.critic_lr)
self.memory = ReplayBuffer(self.buffer_size)
def act(self, state):
state = torch.FloatTensor(state).unsqueeze(0).to(device)
with torch.no_grad():
action = self.actor(state).cpu().data.numpy().flatten()
return action
def update(self):
if len(self.memory) < self.batch_size:
return
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
states = torch.FloatTensor(states).to(device)
actions = torch.FloatTensor(actions).to(device)
rewards = torch.FloatTensor(rewards).unsqueeze(1).to(device)
next_states = torch.FloatTensor(next_states).to(device)
dones = torch.FloatTensor(dones).unsqueeze(1).to(device)
# Update critic
next_actions = self.actor_target(next_states)
q_targets_next = self.critic_target(next_states, next_actions)
q_targets = rewards + (self.gamma * q_targets_next * (1 - dones))
q_expected = self.critic(states, actions)
critic_loss = F.mse_loss(q_expected, q_targets)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Update actor
actions_pred = self.actor(states)
actor_loss = -self.critic(states, actions_pred).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update target networks
self.soft_update(self.critic, self.critic_target)
self.soft_update(self.actor, self.actor_target)
def soft_update(self, local_model, target_model):
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(self.tau*local_param.data + (1.0-self.tau)*target_param.data)
def add_to_buffer(self, state, action, reward, next_state, done):
self.memory.add(state, action, reward, next_state, done)
def train(env, agent, n_episodes=2000, max_t=1000, print_every=100, save_every=500):
scores_deque = deque(maxlen=print_every)
scores = []
for i_episode in range(1, n_episodes+1):
state = env.reset()
agent.reset()
score = 0
noise = OrnsteinUhlenbeckProcess(env.action_space.shape[0])
for t in range(max_t):
action = agent.act(state, noise.sample())
next_state, reward, done, _ = env.step(action)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
scores_deque.append(score)
scores.append(score)
avg_score = np.mean(scores_deque)
if i_episode % print_every == 0:
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, avg_score))
if i_episode % save_every == 0:
torch.save(agent.actor_local.state_dict(), 'checkpoint_actor.pth')
torch.save(agent.critic_local.state_dict(), 'checkpoint_critic.pth')
if avg_score >= 30.0:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode-100, avg_score))
torch.save(agent.actor_local.state_dict(), 'checkpoint_actor.pth')
torch.save(agent.critic_local.state_dict(), 'checkpoint_critic.pth')
break
return scores
2.4.3 SAC(Soft Actor-Critic)
对DDPG进行改进,引入最大熵理论,使得策略在探索和利用之间保持平衡,避免过度依赖奖励函数。
SAC (Soft Actor-Critic) 是一种基于最大熵理论的深度强化学习算法,是 Actor-Critic 算法的一种扩展。SAC 在优化策略和值函数的同时,优化策略的熵,使得策略的探索更加充分。相比于 DDPG 等算法,SAC 有更好的表现,并且更加稳定。
SAC算法与其他基于策略梯度的算法不同,它将熵(Entropy)作为一个额外的目标加入到优化中,从而鼓励策略的探索性和多样性,防止策略陷入局部最优解。因此,SAC算法通常被认为是一个强大、高效且稳定的深度强化学习算法。
SAC算法的目标函数包括三个部分:状态值函数(Value function)的均方误差(Mean Squared Error,MSE)项、策略的期望回报(Expected Return)项和策略熵(Policy Entropy)的负值。具体来说,目标函数可以写成以下形式:
J ( θ ) = E s t ∼ ρ ( s ) , a t ∼ π θ ( a ∣ s t ) [ 1 2 ( V ϕ ( s t ) − Q θ ( s t , a t ) ) 2 − α log π θ ( a t ∣ s t ) + α ⋅ H ( π θ ( ⋅ ∣ s t ) ) ] J(\theta)=\mathbb{E}{s_t\sim\rho(s),a_t\sim\pi{\theta}(a|s_t)}[\frac{1}{2}(V_{\phi}(s_t)-Q_{\theta}(s_t,a_t))^2-\alpha\log\pi_{\theta}(a_t|s_t)+\alpha\cdot H(\pi_{\theta}(\cdot|s_t))] J(θ)=Est∼ρ(s),at∼πθ(a∣st)[21(Vϕ(st)−Qθ(st,at))2−αlogπθ(at∣st)+α⋅H(πθ(⋅∣st))]
其中, s t s_t st和 a t a_t at分别表示时间步 t t t时的状态和动作, π θ ( a t ∣ s t ) \pi_{\theta}(a_t|s_t) πθ(at∣st)表示在状态 s t s_t st下选择动作 a t a_t at的概率, V ϕ ( s t ) V_{\phi}(s_t) Vϕ(st)表示状态 s t s_t st的值函数, Q θ ( s t , a t ) Q_{\theta}(s_t,a_t) Qθ(st,at)表示在状态 s t s_t st下选择动作 a t a_t at的Q值, α \alpha α是一个超参数, H ( π θ ( ⋅ ∣ s t ) ) H(\pi_{\theta}(\cdot|s_t)) H(πθ(⋅∣st))表示策略 π θ \pi_{\theta} πθ在状态 s t s_t st下的熵, ρ ( s ) \rho(s) ρ(s)是状态 s s s的分布。
SAC算法的核心思想是,通过最大化目标函数 J ( θ ) J(\theta) J(θ)来更新策略和状态值函数。具体来说,算法使用随机梯度下降(Stochastic Gradient Descent,SGD)来最小化目标函数的负数,从而更新参数 θ \theta θ和 ϕ \phi ϕ:
∇ θ L ( θ ) = E s t ∼ ρ ( s ) , a t ∼ π θ ( a ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ( α log π θ ( a t ∣ s t ) − Q θ ( s t , a t ) + V ϕ ( s t ) ) ] \nabla_{\theta}\mathcal{L}(\theta)=\mathbb{E}{s_t\sim\rho(s),a_t\sim\pi{\theta}(a|s_t)}[\nabla_{\theta}\log\pi_{\theta}(a_t|s_t)(\alpha\log\pi_{\theta}(a_t|s_t)-Q_{\theta}(s_t,a_t)+V_{\phi}(s_t))] ∇θL(θ)=Est∼ρ(s),at∼πθ(a∣st)[∇θlogπθ(at∣st)(αlogπθ(at∣st)−Qθ(st,at)+Vϕ(st))]
∇ ϕ L ( ϕ ) = E s t ∼ ρ ( s ) , a t ∼ π θ ( a ∣ s t ) , s t + 1 ∼ P ( s t + 1 ∣ s t , a t ) [ ( V ϕ ( s t ) − Q θ ( s t , a t ) ) 2 ] \nabla_{\phi}\mathcal{L}(\phi)=\mathbb{E}{s_t\sim\rho(s),a_t\sim\pi{\theta}(a|s_t),s_{t+1}\sim P(s_{t+1}|s_t,a_t)}[(V_{\phi}(s_t)-Q_{\theta}(s_t,a_t))^2] ∇ϕL(ϕ)=Est∼ρ(s),at∼πθ(a∣st),st+1∼P(st+1∣st,at)[(Vϕ(st)−Qθ(st,at))2]
import torch
import torch.nn.functional as F
import numpy as np
import random
from collections import deque
import gym
# Define the neural network model for the Q-function
class QNetwork(torch.nn.Module):
def __init__(self, state_dim, action_dim, hidden_size):
super(QNetwork, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_size)
self.fc2 = torch.nn.Linear(hidden_size, hidden_size)
self.fc3 = torch.nn.Linear(hidden_size, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Define the neural network model for the policy function
class PolicyNetwork(torch.nn.Module):
def __init__(self, state_dim, action_dim, hidden_size, log_std_min=-20, log_std_max=2):
super(PolicyNetwork, self).__init__()
self.log_std_min = log_std_min
self.log_std_max = log_std_max
self.fc1 = torch.nn.Linear(state_dim, hidden_size)
self.fc2 = torch.nn.Linear(hidden_size, hidden_size)
self.mean_fc = torch.nn.Linear(hidden_size, action_dim)
self.log_std_fc = torch.nn.Linear(hidden_size, action_dim)
def forward(self, state):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
mean = self.mean_fc(x)
log_std = self.log_std_fc(x)
log_std = torch.clamp(log_std, self.log_std_min, self.log_std_max)
return mean, log_std
def sample(self, state, epsilon=1e-6):
mean, log_std = self.forward(state)
std = log_std.exp()
normal = torch.distributions.Normal(mean, std)
z = normal.rsample()
action = torch.tanh(z)
log_prob = normal.log_prob(z) - torch.log(1 - action.pow(2) + epsilon)
log_prob = log_prob.sum(-1, keepdim=True)
return action, log_prob
def get_log_prob(self, state, action, epsilon=1e-6):
mean, log_std = self.forward(state)
std = log_std.exp()
normal = torch.distributions.Normal(mean, std)
z = torch.atanh(action)
log_prob = normal.log_prob(z) - torch.log(1 - action.pow(2) + epsilon)
log_prob = log_prob.sum(-1, keepdim=True)
return log_prob
# Define the replay buffer
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
state_batch, action_batch, reward_batch, next_state_batch, done_batch = zip(*random.sample(self.buffer, batch_size))
return np.array(state_batch), np.array(action_batch), np.array(reward_batch, dtype=np.float32), np.array(next_state_batch), np.array(done_batch, dtype=np.uint8)
def __len__(self):
return len(self.buffer)
class SAC:
def __init__(self, state_dim, action_dim, max_action, device):
self.device = device
self.actor = PolicyNetwork(state_dim, action_dim, max_action).to(self.device)
self.critic1 = QNetwork(state_dim, action_dim).to(self.device)
self.critic2 = QNetwork(state_dim, action_dim).to(self.device)
self.target_critic1 = QNetwork(state_dim, action_dim).to(self.device)
self.target_critic2 = QNetwork(state_dim, action_dim).to(self.device)
hard_update(self.target_critic1, self.critic1)
hard_update(self.target_critic2, self.critic2)
self.actor_optim = torch.optim.Adam(self.actor.parameters(), lr=3e-4)
self.critic_optim = torch.optim.Adam(list(self.critic1.parameters()) + list(self.critic2.parameters()), lr=3e-4)
def train(self, replay_buffer, batch_size=256, discount=0.99, tau=0.005, alpha=0.2):
# Sample replay buffer
state, action, next_state, reward, not_done = replay_buffer.sample(batch_size)
state = torch.FloatTensor(state).to(self.device)
action = torch.FloatTensor(action).to(self.device)
next_state = torch.FloatTensor(next_state).to(self.device)
reward = torch.FloatTensor(reward).to(self.device).unsqueeze(1)
not_done = torch.FloatTensor(not_done).to(self.device).unsqueeze(1)
# Update Q-function
with torch.no_grad():
# Select action according to policy and add clipped noise
next_action, next_log_pi = self.actor.sample(next_state)
noise = torch.randn_like(next_action) * alpha
noise = noise.clamp(-0.5, 0.5)
next_action = (next_action + noise).clamp(-1, 1)
# Compute the target Q value
target_Q1 = self.target_critic1(next_state, next_action)
target_Q2 = self.target_critic2(next_state, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + not_done * discount * (target_Q - alpha * next_log_pi)
current_Q1 = self.critic1(state, action)
current_Q2 = self.critic2(state, action)
critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
self.critic_optim.zero_grad()
critic_loss.backward()
self.critic_optim.step()
# Update policy
sampled_actions, log_prob = self.actor.sample(state)
min_Q = torch.min(
self.critic1(state, sampled_actions),
self.critic2(state, sampled_actions)
)
actor_loss = (alpha * log_prob - min_Q).mean()
self.actor_optim.zero_grad()
actor_loss.backward()
self.actor_optim.step()
# Update target networks
soft_update(self.target_critic1, self.critic1, tau)
soft_update(self.target_critic2, self.critic2, tau)
在SAC算法中,PolicyNetwork和QNetwork是通过最小化Q值和策略的KL散度来联合训练的。具体来说,在每次更新中,需要先更新Q网络,然后再更新策略网络。
更新Q网络时,需要计算目标Q值,目标Q值可以用来计算Q值的损失函数。在SAC算法中,目标Q值是由SAC算法中的三个Q网络中的最小值来计算的,即 Q ( s t , a t ) = min i = 1 , 2 , 3 Q i ( s t , a t ) Q(s_t, a_t) = \min_{i=1,2,3} Q_i(s_t, a_t) Q(st,at)=mini=1,2,3Qi(st,at),其中 Q i Q_i Qi 是第 i i i 个Q网络。
在更新策略网络时,需要计算策略梯度。由于策略网络的优化目标是最大化期望累积回报,而累积回报是随机变量,因此需要使用重要性采样来估计梯度。具体来说,对于每个时间步 t t t,可以计算出在状态 s t s_t st 时采取动作 a t a_t at 的概率 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st),并根据重要性采样公式计算策略梯度。SAC算法中的策略梯度可以写成以下形式:
∇ θ J = E s t ∼ D , ϵ t ∼ N [ ∇ θ log π θ ( a t ∣ s t ) Q min ( s t , a t ) − α log π θ ( a t ∣ s t ) ] \nabla_\theta J = \mathbb{E}{s_t\sim D, \epsilon_t\sim \mathcal{N}}[\nabla\theta \log \pi_\theta(a_t|s_t) Q_{\text{min}}(s_t, a_t) - \alpha \log \pi_\theta(a_t|s_t)] ∇θJ=Est∼D,ϵt∼N[∇θlogπθ(at∣st)Qmin(st,at)−αlogπθ(at∣st)]
其中 D D D 是经验回放缓冲区, ϵ t \epsilon_t ϵt 是高斯噪声。上式中的第一项是重要性采样的梯度,表示策略网络对应动作的Q值的梯度乘以策略的对数概率,第二项是熵的梯度,用于鼓励策略探索更多的动作。
在具体实现中,可以先计算Q值损失,然后使用Q网络计算策略梯度,并更新策略网络和目标熵值 α \alpha α。策略梯度和目标熵值 α \alpha α 的计算可以使用PyTorch的自动微分功能进行。更新Q网络和策略网络时,可以使用Adam优化器来更新网络的权重参数。
重要性采样(Importance Sampling)
一种用于估计期望值的方法,常用于强化学习中的策略评估问题。在策略评估中,我们需要计算某个策略下的状态值函数或状态-动作值函数,但是由于需要计算期望,我们通常无法直接得到准确的值,而需要使用采样的方法来近似计算。
在某些情况下,我们已经有了一个分布p(x),并且我们想要计算某个函数f(x)在这个分布上的期望值,即 E[f(x)]。但是计算这个期望值可能很困难,因为我们不一定知道分布p(x)的具体形式。重要性采样就是一种通过从另一个分布q(x)中抽样来估计E[f(x)]的方法,其中q(x)是我们已知的一个分布。具体来说,我们可以使用以下公式来估计E[f(x)]:
E
[
f
(
x
)
]
≈
Σ
[
f
(
x
)
∗
w
(
x
)
]
/
Σ
[
w
(
x
)
]
E[f(x)] \approx \Sigma [f(x) * w(x)] / \Sigma[w(x)]
E[f(x)]≈Σ[f(x)∗w(x)]/Σ[w(x)]
其中,w(x)是重要性采样权重,定义为:
w
(
x
)
=
p
(
x
)
/
q
(
x
)
w(x) = p(x) / q(x)
w(x)=p(x)/q(x)
这个权重表示我们从分布q(x)中采样的样本在分布p(x)中的“重要性”,也就是这个样本对期望值的估计贡献。如果q(x)和p(x)的形式很接近,那么估计的准确性就会比较高,反之则可能会有较大的误差。
在强化学习中,重要性采样通常用于在策略评估过程中估计状态值函数或状态-动作值函数。具体来说,当我们想要评估某个策略的值函数时,我们可以使用另一个策略来采样,然后使用重要性采样来估计目标策略的值函数。具体来说,我们可以从另一个策略(例如均匀随机策略)中采样一批状态或状态-动作对,然后根据重要性采样公式来计算目标策略下的状态值函数或状态-动作值函数的估计值。重要性采样可以大大增加我们用来估计目标策略值函数的数据,从而提高估计的准确性。
2.4.4 PPO(Proximal Policy Optimization)
基于Policy Gradient方法,通过限制每次更新的策略参数变化量,提高训练的稳定性,避免过拟合和振荡。
2.4.5 A3C(Asynchronous Advantage Actor-Critic)
A3C算法使用Actor-Critic结构,通过神经网络分别学习策略和价值函数。此外,为了提高训练效率,A3C算法使用异步训练的方式,即在多个并发的Agent中进行训练,每个Agent拥有独立的副本,通过交互式学习来共同优化全局的模型参数。这种方式可以利用多核CPU或多个GPU,加速模型的训练过程,同时也可以增加模型的稳定性,减少模型陷入局部最优解的风险。
2.5 强化学习中的探索(Exploration in Reinforcement Learning)
探索是强化学习中非常重要的一个问题,它涉及到如何在学习过程中充分探索环境,以获取更多的信息和奖励。常见的探索方法包括epsilon-greedy、softmax策略、UCB等。















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









