







前言
现在Java程序员面试都是因为没有丰富的工作经验和自己过硬的技术,所有都不知道一般互联网应该会问什么技术问题,加上自己可能去面试的时候没有准备的太充分,一面试刚跟面试官扯几个面试题就不知道自己在哪里了,被怼的体无完肤了,最后以灰头土脸的结束,所有针对这类的读者,我把几个群友大厂面试时候的经历和面试题整理出来,再次分享给广大的朋友们去参考,让你们更加的了解一线大厂都是问的什么问题。

蚂蚁金服
一面
算法题,给了长度为N的有重复元素的数组,要求输出第10大的数。
需要在2小时内完成。
二面
自我介绍
目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下
Dubbo踩过哪些坑,怎么解决的?
对线程安全的理解
乐观锁和悲观锁的区别?
这两种锁在Java和MySQL分别是怎么实现的?
事务有哪些特性?
怎么理解原子性?
HashMap为什么不是线程安全的?
怎么让HashMap变得线程安全?
jdk1.8对ConcurrentHashMap做了哪些优化?
redis主从机制了解么?怎么实现的?
有过GC调优的经历么?
有什么想问的
三面
自我介绍
接下来就是全部问的项目,对自己的项目细节逐个盘问,最后问了下如何改进方案
有什么想问我么?
四面
介绍下自己
问项目
说说Spring的生命周期吧
说说GC的过程
强制young gc会有什么问题?
知道G1么?
回收过程是怎么样的?
你提到的Remember Set底层是怎么实现的?
CMS GC有什么问题?
怎么避免产生浮动垃圾?
有什么想问的么?
五面
HRBP面,主要聊了部门在做的事情、职业发展、福利待遇等。阿里面试官有一票否决权,很看重你的价值观是否match。
HR面一定要诚实,不要说谎,只要你说谎HR都会去证实。
最后HR还对我说目前稳定性保障部挺缺人的,希望我尽快回复。
小结
蚂蚁面试比较重视基础,所以Java那些基本功一定要扎实。
拼多多
一面
聊项目
Java中的HashMap、TreeMap解释下?
TreeMap查询写入的时间复杂度多少?
ConcurrentHashMap怎么实现线程安全的?
HashMap多线程有什么问题?怎么解决?
CAS和synchronize有什么区别?都用synchronize不行么?
get需要加锁么,为什么?
volatile的作用是什么?
给我一张纸,画了一个九方格,都填了数字,给一个MN矩阵,从1开始逆时针打印这MN个数,要求时间复杂度尽可能低,可以先说下思路
有什么想问我的?
二面
自我介绍下
手上还有其他offer么?
部门组织结构是怎样的?
系统有哪些模块,每个模块用了哪些技术,数据怎么流转的?给了我一张纸,我在上面简单画了下系统之间的流转情况
链路追踪的信息是怎么传递的?
SpanId怎么保证唯一性?
RpcContext是在什么维度传递的?
Dubbo的远程调用怎么实现的?
Spring的单例是怎么实现的?
为什么要单独实现一个服务治理框架?
谁主导的?内部还在使用么?
逆向有想过怎么做成通用么?
有什么想问的
HR面
主要问了些职业发展、是否有其他offer、以及入职意向等问题,顺便说了下公司的福利待遇等,手上有其他offer或者大厂经历会有一定加分。
字节跳动
一面
自我介绍
聊项目
Redis熟悉么,了解哪些数据结构? zset底层怎么实现的?
红黑树了解么,时间复杂度?
既然两个数据结构时间复杂度都是O(logN),zset为什么不用红黑树
线程池的线程数怎么确定?
如果是IO操作为主怎么确定?
如果计算型操作又怎么确定?
跳表的查询过程是怎么样的,查询和插入的时间复杂度?
说下Dubbo的原理?
CAS了解么?还了解其他同步机制么?
做题:数组A,2*n个元素,n个奇数、n个偶数,设计一个算法,使得数组奇数下标位置放置的都是奇数,偶数下标位置放置的都是偶数。先说下你的思路
你有什么想问我的?
二面
自我介绍
问项目
分布式追踪的上下文是怎么存储和传递的?
SpringMVC不同用户登录的信息怎么保证线程安全的?
我们聊聊mysql吧,说下索引结构,为什么使用B+树?
Dubbo的RpcContext是怎么传递的?主线程的ThreadLocal怎么传递到线程池?你说的内存泄漏具体是怎么产生的?
线程池的线程是不是必须手动remove才可以回收value?那你说的内存泄漏是指主线程还是线程池?
什么是索引覆盖?
Java为什么要设计双亲委派模型?
什么时候需要自定义类加载器?
做题:手写一个对象池
有什么想问我的
小结
头条的面试确实很专业,而且面试官最后给我了一点建议,就是研究技术的时候一定要结合技术的背景。
面试官都有一个特点,会抓住一个值得深入的点或者你没说清楚的点深入下去直到你把这个点讲清楚,不然面试官会觉得你并没有真正理解。
最后的内容
在开头跟大家分享的时候我就说,面试我是没有做好准备的,全靠平时的积累,确实有点临时抱佛脚了,以至于我自己还是挺懊恼的。(准备好了或许可以拿个40k,没做准备只有30k+,你们懂那种感觉吗)
如何准备面试?
1、前期铺垫(技术沉积)
程序员面试其实是对于技术的一次摸底考试,你的技术牛逼,那你就是大爷。大厂对于技术的要求主要体现在:基础,原理,深入研究源码,广度,实战五个方面,也只有将原理理论结合实战才能把技术点吃透。
下面是我会看的一些资料笔记,希望能帮助大家由浅入深,由点到面的学习Java,应对大厂面试官的灵魂追问,有需要的话就戳这里:蓝色传送门打包带走吧。
这部分内容过多,小编只贴出部分内容展示给大家了,见谅见谅!
- Java程序员必看《Java开发核心笔记(华山版)》

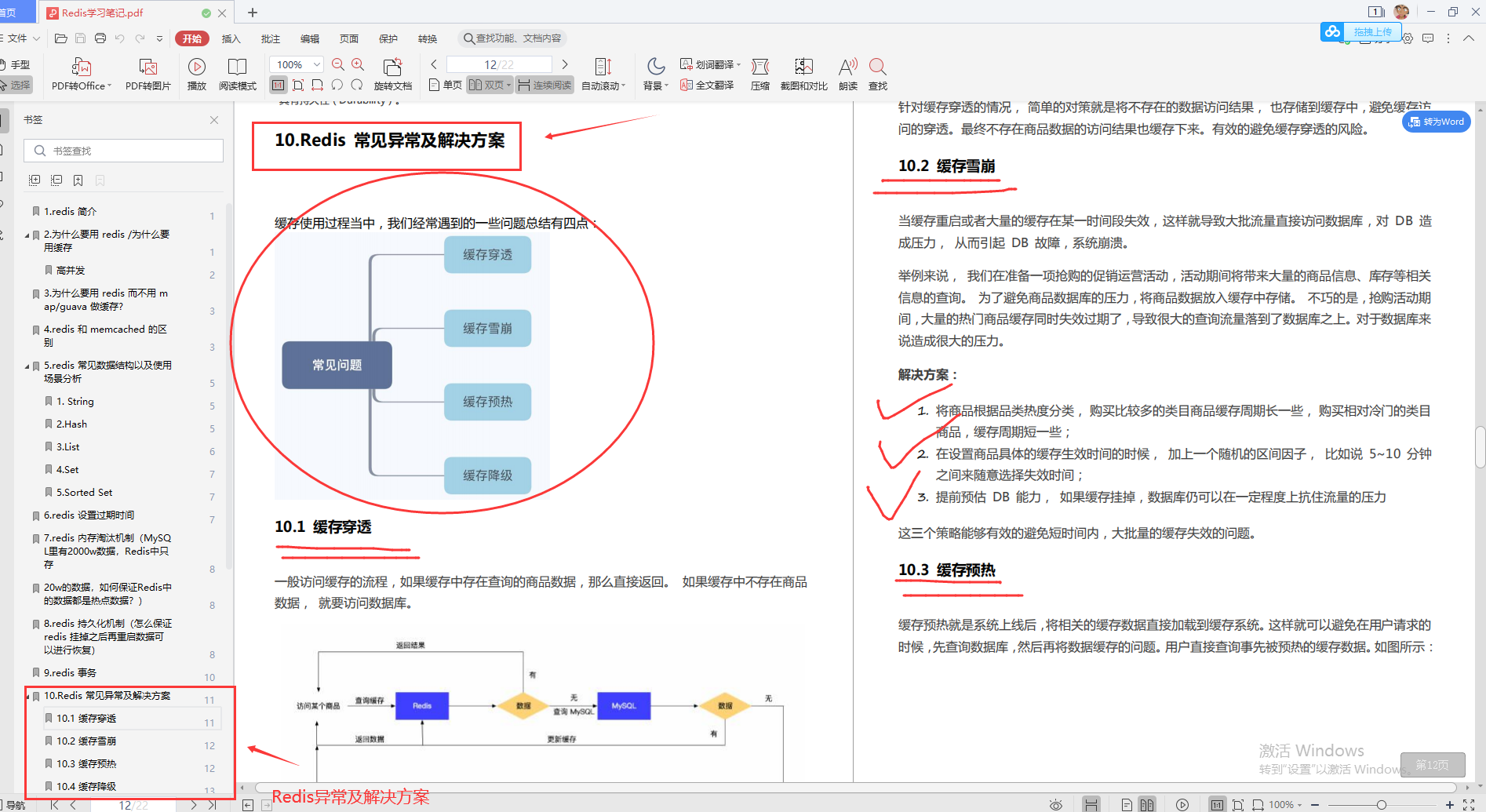
- Redis学习笔记
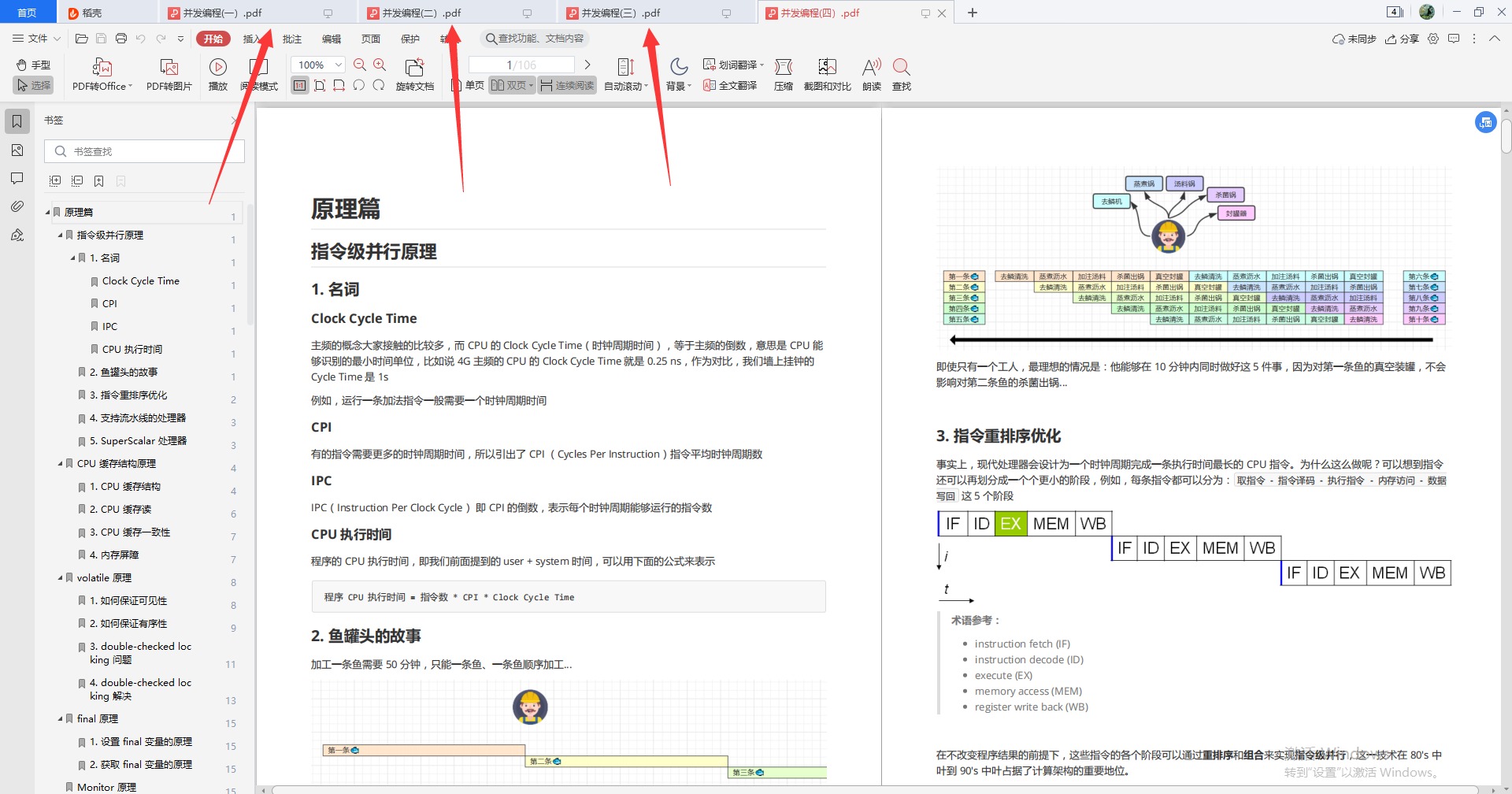
- Java并发编程学习笔记
四部分,详细拆分并发编程——并发编程+模式篇+应用篇+原理篇
- Java程序员必看书籍《深入理解 ava虚拟机第3版》(pdf版)

- 大厂面试必问——数据结构与算法汇集笔记
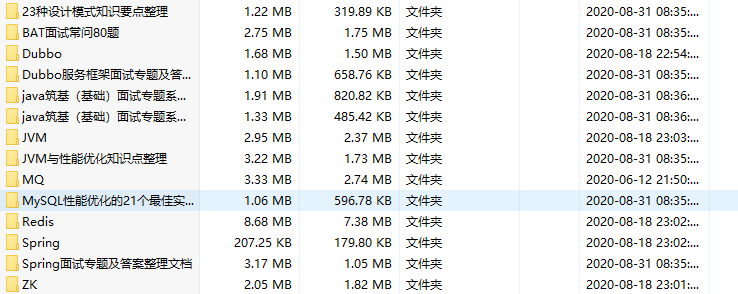
其他像Spring,SpringBoot,SpringCloud,SpringCloudAlibaba,Dubbo,Zookeeper,Kafka,RocketMQ,RabbitMQ,Netty,MySQL,Docker,K8s等等我都整理好,这里就不一一展示了。
2、狂刷面试题
技术主要是体现在平时的积累实用,面试前准备两个月的时间再好好复习一遍,紧接着就可以刷面试题了,下面这些面试题都是小编精心整理的,贴给大家看看。
①大厂高频45道笔试题(智商题)

②BAT大厂面试总结(部分内容截图)
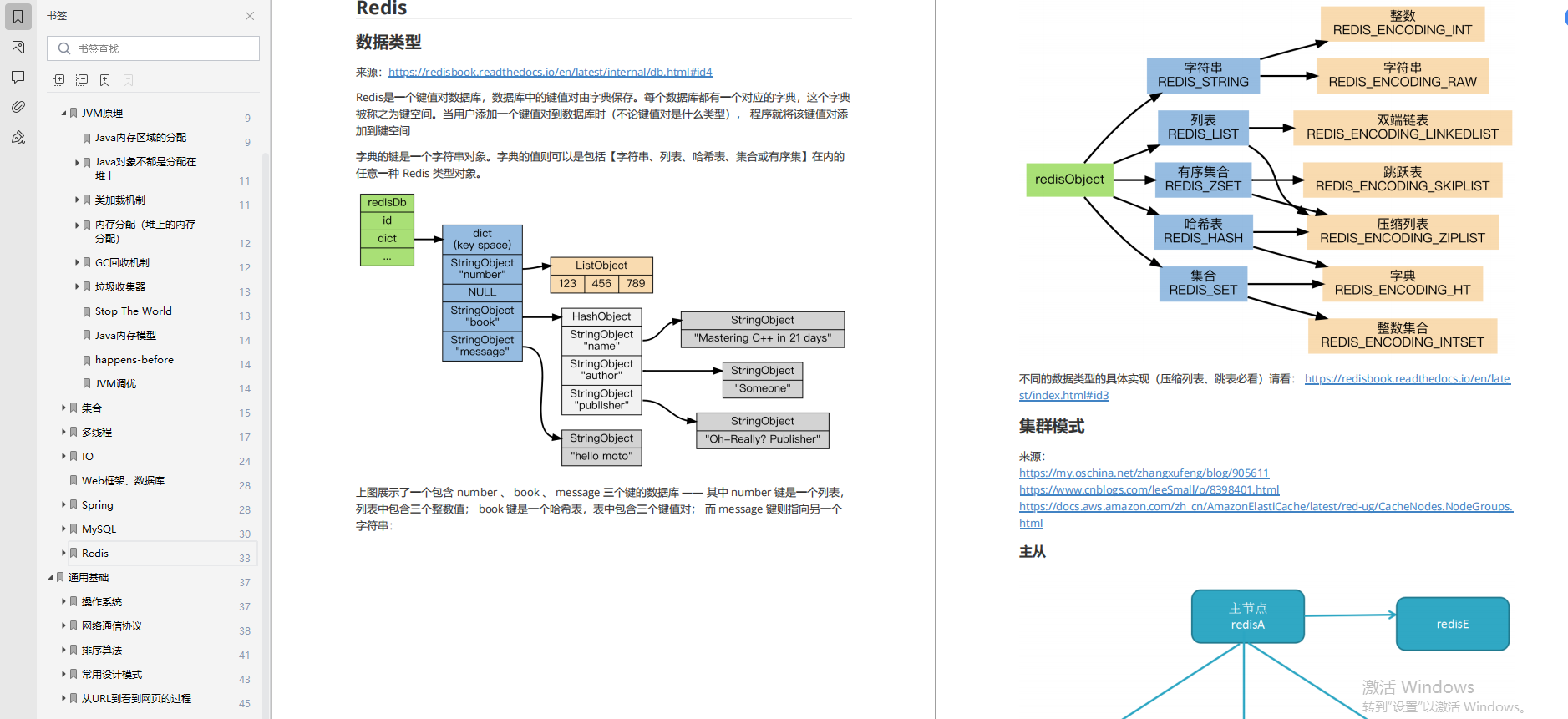
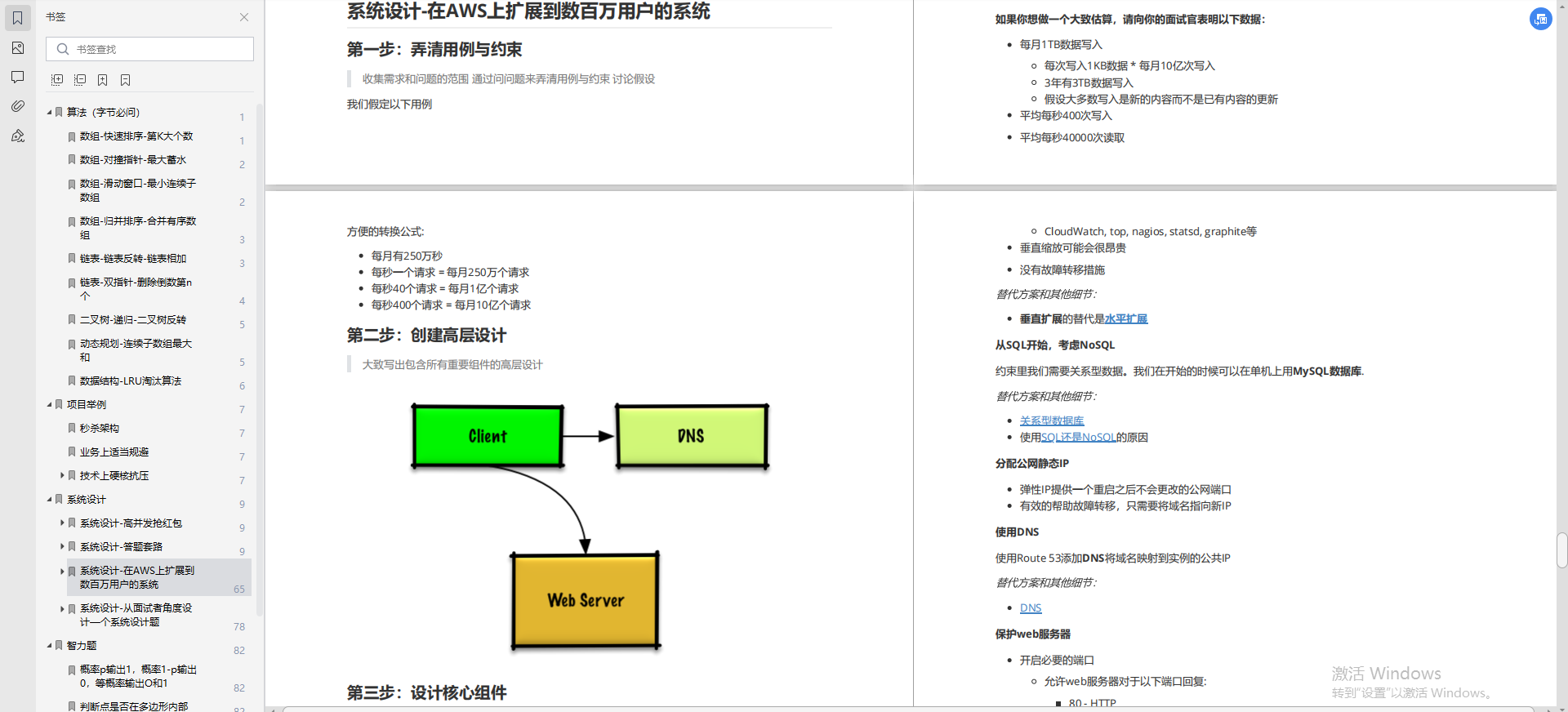
③面试总结
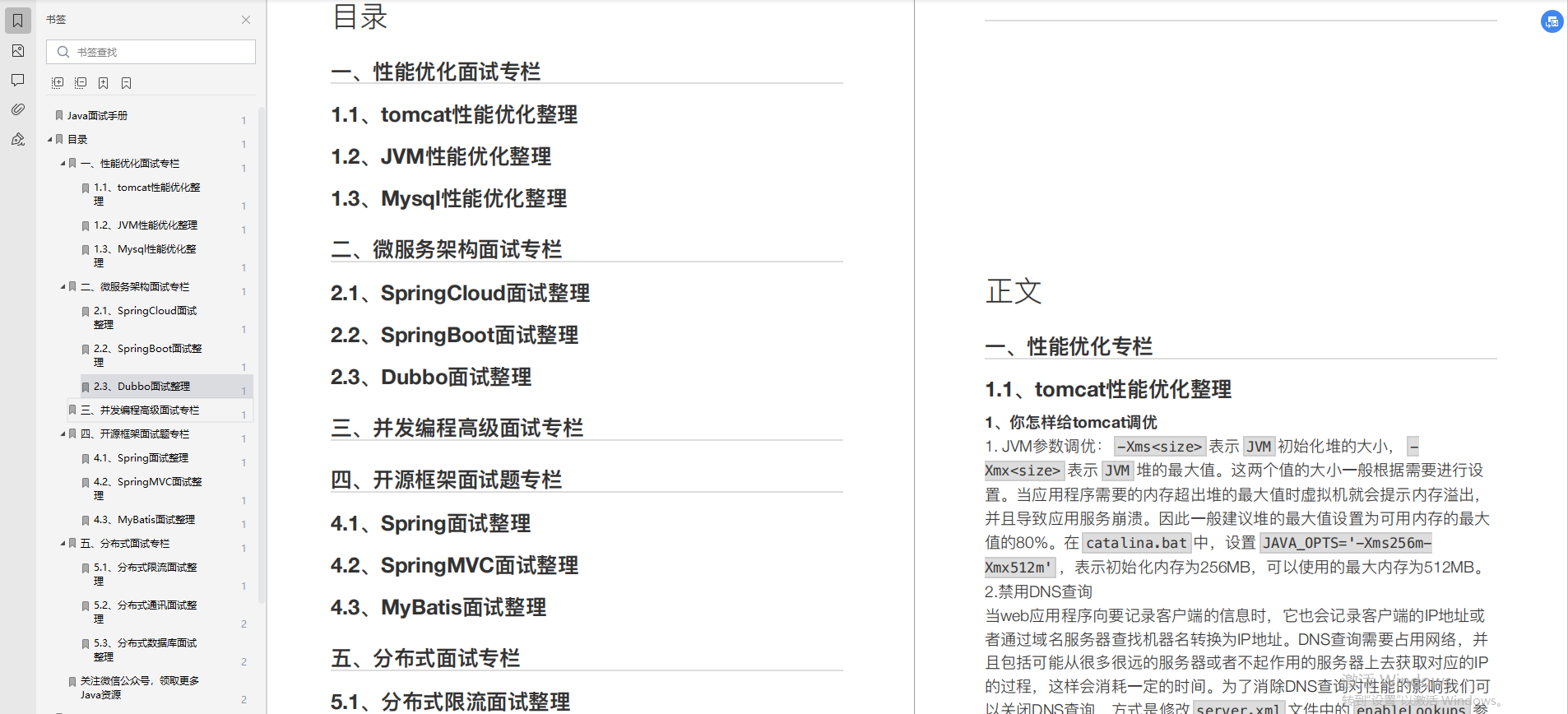
3、结合实际,修改简历
程序员的简历一定要多下一些功夫,尤其是对一些字眼要再三斟酌,如“精通、熟悉、了解”这三者的区别一定要区分清楚,否则就是在给自己挖坑了。当然不会包装,我可以将我的简历给你参考参考,如果还不够,那下面这些简历模板任你挑选:
以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
给自己挖坑了。当然不会包装,我可以将我的简历给你参考参考,如果还不够,那下面这些简历模板任你挑选:
[外链图片转存中…(img-pb133ETu-1620572118720)]
以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
以上文章中,提及到的所有的笔记内容、面试题等资料,均可以免费分享给大家学习,有需要的话就戳这里打包带走吧。















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









