






一、定义
随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。
那什么是有监督学习呢?有监督学习就是把有已知结果的数据集拿去训练,如果训练结果与标准答案的精度足够高就可以使用这个模型去预测或者分类未知结果的数据集。简单来说就是你写很多有标准答案的试卷,当你的准确率足够高的时候你就可以去写没有标准答案的试卷了,因为如果你平时都能考全国前三,那你高考就大概率能考到全国前三。有监督学习主要应用于分类和回归。
无监督学习的数据是没有已知结果的数据,比如清北大学自主招生考试,学校事先不知道学生平时的考试结果,但是有学生奥数经历的介绍,根据以往经验奥数高的一般考的就好,就收了,但是不排除奥数好但是成绩不行的学生存在。无监督学习主要用于聚类和降维。
集成学习故名思义就是“组合学习”,比如本文介绍的随机森林算法就是由很多个决策树组成的算法,在随机森林分类器中会让每个决策树进行投票决定分类结果,而在随机森林回归中则是取每棵决策树的回归结果的平均值作为随机森林回归值。
二、模型理论
传统的决策树模型在训练时经常会出现过拟合的情况,随机森林是有效解决该问题的方法之一。随机森林本质上是很多树的组合,并且每一棵树因为取的样本略有不同所以树与树之间也是有所区别的。
随机森林的思想是每棵树的预测效果可能都相对较好但可能对部分数据过拟合,如果构造足够多的树,并且每棵树都可能有很好的预测结果但是也都会对不同的部分数据过拟合,我们可以通过取平均值来降低过拟合同时保证模型精度,这在数学上是被证明过的。
随机森林的随机性体现在两个方面:
特征随机性和样本随机性:先随机抽取足够的样本,再根据这批样本选择最好的特征,这样每棵树的特征实际上都有可能不完全一样。
因为随机性,森林的偏向可能会略有增加,但是因为取平均,它的方差也会减小,从而生成一个更好的模型。
算法过程如下:
(1)、通过有放回抽样的方法随机抽取n个样本作为决策树模型的样本
(2)、假设这些样本有M个特征,随机选择m个特征作为该决策树的分裂属性
(3)、重复(1)(2)n次就会生成n个决策树,这样就构成了随机森林,这些决策树的回归值的平均值就是随机森林的结果。
三、优缺点
优点:
(1)、可以处理很高维度(特征很多)的数据,并且不用降维,不用做做特征选择
(2)、对数据集的适应能力强,既适用于离散型也适用于连续型数据
(3)、它可以判断特征的重要程度,筛选出重要特征,并且筛选结果也可以用于其他模型,是非常流行的特征筛选方法
(4)、由于采用集成算法,精度往往比单个模型的精度高
(5)、实现简单、精度高,不容易过拟合,可以作为基准模型
缺点:
(1)、随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合
(2)、对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
四、参数介绍
n_estimators :树的数量,默认是10,就是你准备在你的森林里种多少树。这个参数是最重要的,树的数量决定了最后的准确性,但是也会让你的运行速度变的很慢,所以需要不断的测试去决定。
max_features:随机森林允许单个决策树使用特征的最大数量。
Auto/None/sqrt :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。默认是auto
int:是整数
float:百分比选取
log2:所有特征数的log2值
criterion : criterion:分裂节点所用的标准,可选“gini”, “entropy”,默认“gini”。
max_depth:树的最大深度。如果为None,则将节点展开,直到所有叶子都是纯净的(只有一个类),或者直到所有叶子都包含少于min_samples_split个样本。默认是None
min_samples_split:拆分内部节点所需的最少样本数:如果为int,则将min_samples_split视为最小值。如果为float,则min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每个拆分的最小样本数。默认是2
min_samples_leaf:在叶节点处需要的最小样本数。仅在任何深度的分割点在左分支和右分支中的每个分支上至少留下min_samples_leaf个训练样本时,才考虑。这可能具有平滑模型的效果,尤其是在回归中。如果为int,则将min_samples_leaf视为最小值。如果为float,则min_samples_leaf是分数,而ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。默认是1。
最主要的两个参数是n_estimators和max_features,n_estimators理论上是越大越好,但是计算时间也相应增长,所以预测效果最好的值将会出现在合理的树个数;max_features每个决策树在随机选择的特征里找到某个“最佳”特征,使得模型在该特征的某个值上分裂之后得到的收益最大化。max_features越少,方差就会减少,但同时偏差就会增加。如果是回归问题则max_features=n_features,如果是分类问题,则max_features=sqrt(n_features),其中,n_features 是输入特征数。
从下图中我们可以看到参数对Random Forest的影响: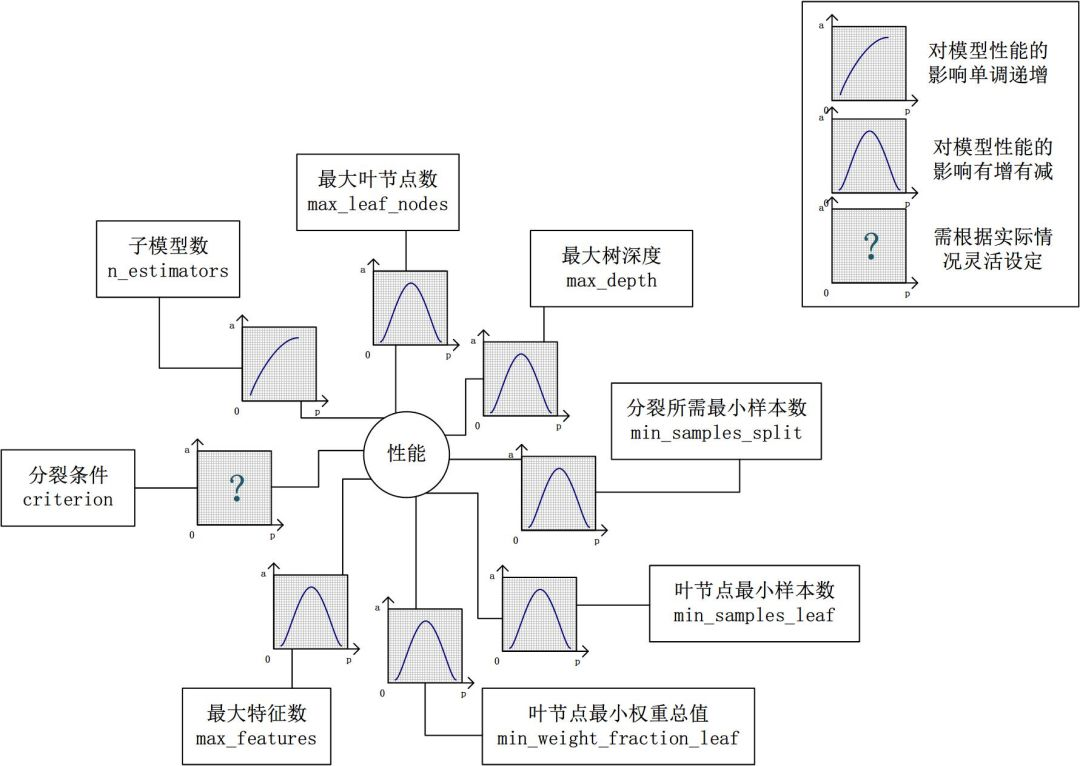
可以看到除了n_estimators外其余参数理论上都不是越大越好,包括 n_estimators实际中也不是越大越好,那如何调节出好的参数呢,一个一个试是不可能的,机器学习库提供了一个暴力调参的函数GridSearchCV(网格搜索),但是这个函数很容易让你的电脑爆炸,因为如果4个参数一起调,每个参数都是100种可能,那就会运行100x100x100x100次模型,显然这是不行的,但是我们可以通过贪心算法,即把最重要的两个参数放到GridSearchCV里找到最优参数,再把次要的参数放进去遍历。总之,不断的尝试就对了。
五、模型步骤
实施随机森林回归通常包括以下步骤:
数据准备:首先需要准备用于训练和测试的数据。数据应该包括特征和目标变量,特征是用于预测的自变量,目标变量是要预测的因变量。数据通常需要进行清洗、处理缺失值、特征选择等预处理步骤。
数据划分:将准备好的数据划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的性能。一般采用随机抽样的方式,将数据按照一定比例划分为训练集和测试集,如70%的数据作为训练集,30%的数据作为测试集。
特征工程:对特征进行进一步处理,包括特征缩放、特征编码、特征构建等。这一步骤有助于提高模型的性能和泛化能力。
模型训练:使用训练集数据,构建随机森林回归模型。通过调整模型的超参数,如树的数量、树的深度、节点分裂的方式等,可以优化模型的性能。
模型评估:使用测试集数据,对训练好的随机森林回归模型进行评估。常用的评估指标包括均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)、决定系数(Coefficient of Determination, R-squared)等。这些指标可以帮助评估模型的预测精度、泛化能力和稳定性。
模型调优:根据评估结果,可以对模型进行调优,包括调整超参数、增加样本数量、进行特征选择等。通过反复调优,提高模型的性能。
模型预测:在模型训练和调优完成后,可以使用该模型进行实际的预测。将新的特征数据输入模型,模型会根据之前的训练结果生成相应的预测值。
模型解释:随机森林回归模型是一种黑盒模型,难以解释其预测结果。但可以通过特征重要性的排序,了解不同特征对于预测结果的贡献程度,从而解释模型的预测结果。
六、案例建模及具体步骤
读取数据
import pandas as pd
##数据集
model_data=pd.read_excel(r"D:\桌面\M2183\RF模型代码+代码\RF模型代码+代码\GL_HML_Impact Factor_1.0.xlsx",index_col=0)
##用于预测的数据
df_4=pd.read_excel(r"D:\桌面\M2183\RF模型代码+代码\RF模型代码+代码\GL预测数据_4.0.xlsx",index_col=0)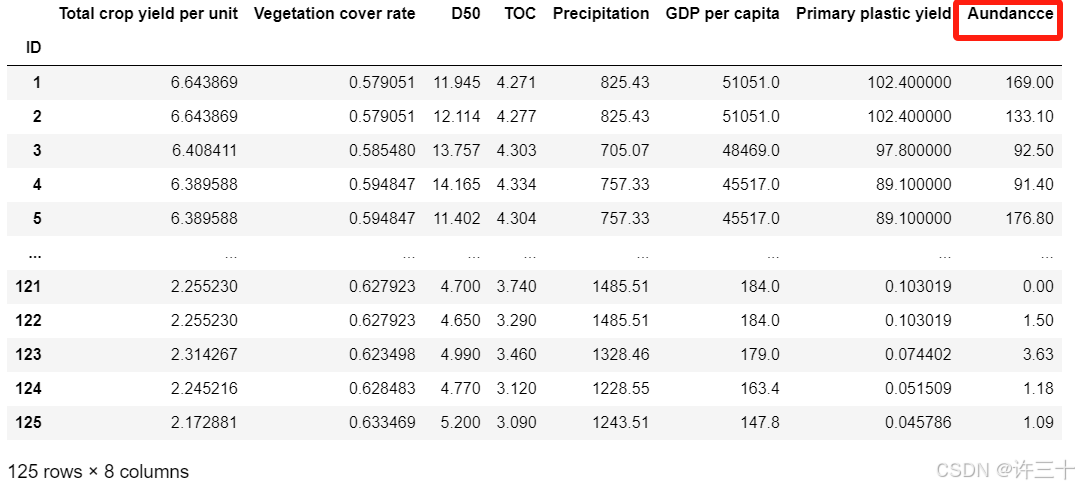
model_data是模型训练使用的数据,共有8个指标,其中Aundance是因变量Y,也就是需要预测的数据,其余7个指标是自变量X,X是7个特征组成的特征集。
df_4是用来预测的数据,相比model_data缺少指标Aundance。读取数据读取数据
导入所需模块&划分训练集和测试集
#随机森林
#导入所需要的包
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report#评估报告
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.model_selection import GridSearchCV #网格搜索
import matplotlib.pyplot as plt#可视化
import seaborn as sns#绘图包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler#归一化,标准化
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
x=model_data.iloc[:,:-1]
y=model_data['Aundancce']
#random_state是随机数种子,相同的随机数种子可以保证抽取相同的样本,如果不设定种子,下一次跑代码的时候用来训练的样本就会和上一次的不一样。
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=90)默认参数下的训练结果
from sklearn.metrics import mean_squared_error, r2_score
model=RandomForestRegressor()#建立默认参数的随机森林回归模型
#利用随机森林进行训练
forest = RandomForestRegressor(
n_estimators=1000,
random_state=1,
n_jobs=-1)
forest.fit(X_train,y_train)
y_pred = forest.predict(X_test)
#评估指标,这里只用了R方和mse
score = forest.score(X_test, y_test)##R方
mse = mean_squared_error(y_test, y_pred)
print(score)
print(mse)
##可视化
plt.figure()
plt.plot(np.arange(len(y_test)), y_test[:], "go-", label="True value")
plt.plot(np.arange(len(y_pred)), y_pred[:], "ro-", label="Predict value")
plt.title(f"RandomForest---score:{score}")
plt.legend(loc="best")
plt.show()结果如下:
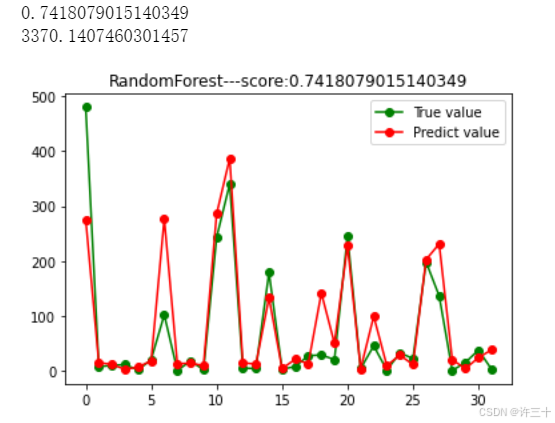
就可视化的结果来看,预测值和实际值的趋势基本一致,但是mse的值较大,整个模型的误差偏大,下面进行调参,每个参数挨个调整的方法看下面这篇文章,此处直接用网格搜索法寻找最优参数组合。
网格搜索法调参
# 设置随机森林回归模型的参数
param_grid = {
'n_estimators': [10, 50, 100, 200, 400,600,800,1000],
'max_depth': [None, 10, 20, 30, 50],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['log2', 'sqrt']
}
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
# 网格搜索法确定最佳参数
rf = RandomForestRegressor(random_state=42)
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error', verbose=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print(grid_search.best_params_)
得到上述最优参数组合后,进行训练:
from sklearn.metrics import mean_squared_error, r2_score
# 使用sklearn调用衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
from sklearn.metrics import mean_absolute_error
model=RandomForestRegressor()#建立默认参数的模型
#利用随机森林进行训练
forest = RandomForestRegressor(
n_estimators=50,
max_features='log2',
min_samples_leaf=2,
min_samples_split=5,
max_depth=10,
random_state=1,
n_jobs=-1)
forest.fit(X_train,y_train)
y_pred = forest.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
score = forest.score(X_test, y_test)##R方
r2=r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse=sqrt(mse)
print("mae:",mae)
# print("forest求得的r2:",score)
print("r2:",r2)
print("mse:",mse)
print("rmse:",rmse)
plt.figure()
plt.plot(np.arange(len(y_test)), y_test[:], "go-", label="True value")
plt.plot(np.arange(len(y_pred)), y_pred[:], "ro-", label="Predict value")
plt.title(f"RandomForest---score:{score}")
plt.legend(loc="best")
plt.show()
得到如下结果:
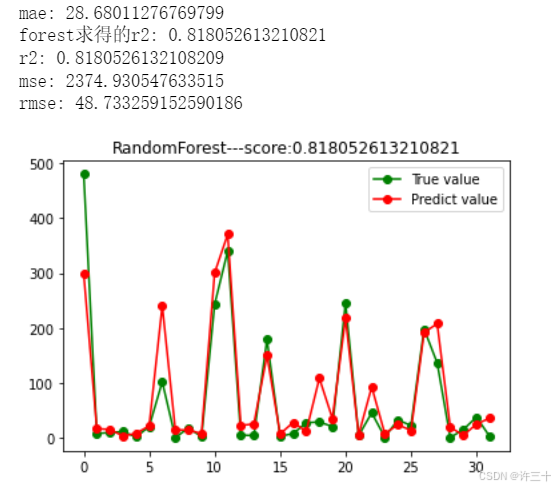
虽然mse的值还是偏大,但是相较默认参数的结果误差有了明显的下降。
拓展:网格搜索法的过程展示:
from matplotlib import pyplot as plt
# 可视化处理
results = pd.DataFrame(grid_search.cv_results_)
# print(results)
from sklearn.metrics import mean_squared_error, r2_score
# 输出最佳模型的MSE和R^2
best_rf = grid_search.best_estimator_
predictions = best_rf.predict(X_test)
best_mse = mean_squared_error(y_test, predictions)
best_r2 = r2_score(y_test, predictions)
print('MSE of the best model: ', best_mse)
print('R^2 of the best model: ', best_r2)
mse = abs(results['mean_test_score'])
plt.figure(figsize=(10, 8))
plt.title("Random Forest Grid Search MSEs", fontsize=16)
plt.xlabel("Parameter Set", fontsize=16)
plt.ylabel("MSE Score", fontsize=16)
plt.plot(range(1, len(mse) + 1), mse, color='#d7191c', linestyle='--', label='MSE')
plt.grid(False)
plt.legend(loc='best', fontsize=14)
plt.show()
plt.clf()网格搜索的过程集合在grid_search.cv_results_ 中,这里的可视化是mse的值变化图。

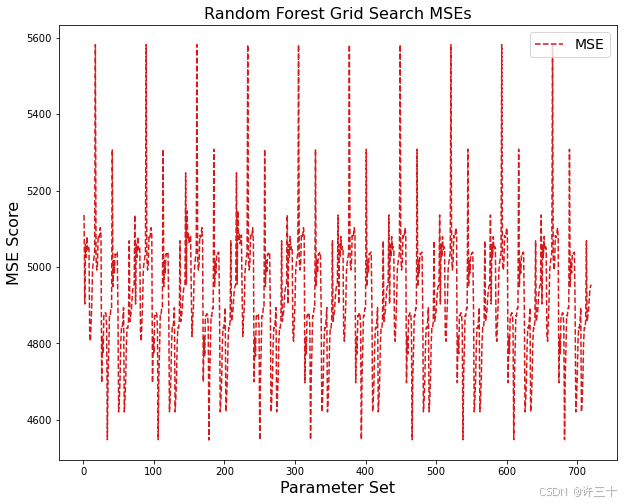
模型预测
将没有用于预测的数据df_4直接带入模型即可得到预测值。
##带入预测数据
df_4['Aundancce']=forest.predict(df_4.iloc[:,1:])
df_4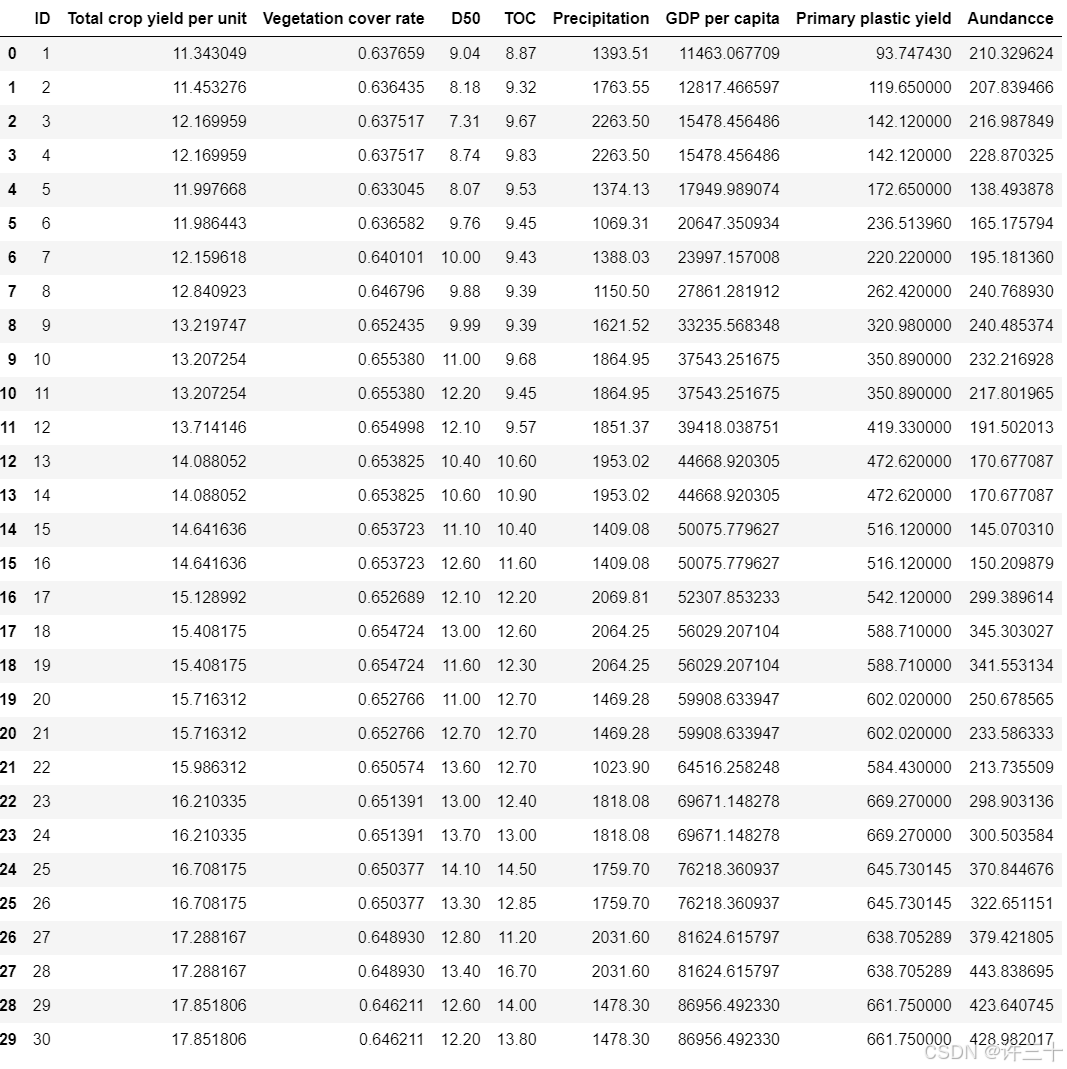
完整代码自取:
#随机森林
#导入所需要的包
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report#评估报告
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.model_selection import GridSearchCV #网格搜索
import matplotlib.pyplot as plt#可视化
import seaborn as sns#绘图包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler#归一化,标准化
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
训练数据
model_data=pd.read_excel(r"D:\桌面\M2183\RF模型代码+代码\RF模型代码+代码\GL预测数据_1.0.xlsx")
#预测数据
df_4=pd.read_excel(r"D:\桌面\M2183\RF模型代码+代码\RF模型代码+代码\GL预测数据_4.0.xlsx")
x=model_data.iloc[:,:-1]
y=model_data['Aundancce']
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=90)
from sklearn.metrics import mean_squared_error, r2_score
# 使用sklearn调用衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
from sklearn.metrics import mean_absolute_error
#利用随机森林进行训练
forest = RandomForestRegressor(
n_estimators=50,
max_features='log2',
min_samples_leaf=2,
min_samples_split=5,
max_depth=10,
random_state=1,
n_jobs=-1)
forest.fit(X_train,y_train)
y_pred = forest.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
score = forest.score(X_test, y_test)##R方
r2=r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse=sqrt(mse)
print("mae:",mae)
# print("forest求得的r2:",score)
print("r2:",r2)
print("mse:",mse)
print("rmse:",rmse)
plt.figure()
plt.plot(np.arange(len(y_test)), y_test[:], "go-", label="True value")
plt.plot(np.arange(len(y_pred)), y_pred[:], "ro-", label="Predict value")
plt.title(f"RandomForest---score:{score}")
plt.legend(loc="best")
plt.show()
##带入预测数据
df_4['Aundancce']=forest.predict(df_4.iloc[:,1:])相关阅读:
分类算法-随机森林实战案例_随机森林案例-CSDN博客 随机森林特征重要性排序参考这篇文章末尾处


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









