







本笔记参考自b站up主:丸一口
论文参考自Adaptive Federated Learning in Resource Constrained Edge Computing Systems
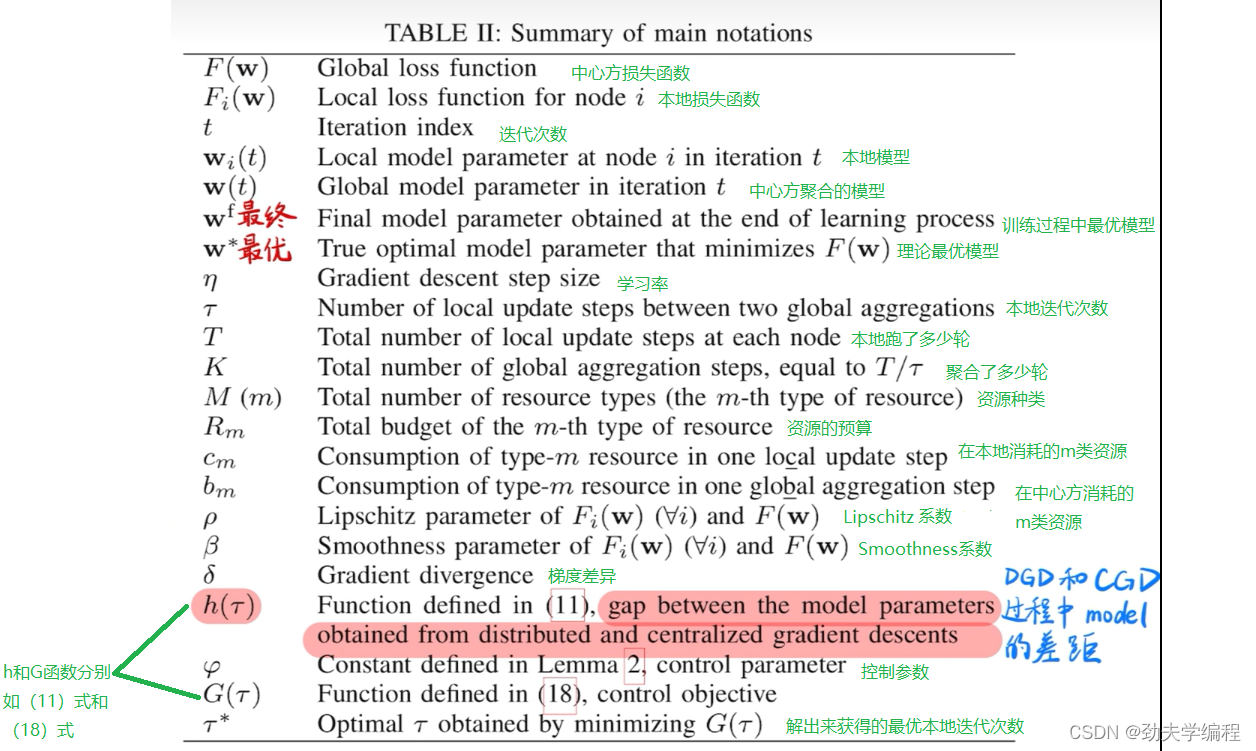
一、符号
原文的符号解释如下图绿色字体所注
二、应用场景

就是在资源小于资源预算的情况下,同时又要满足资源受限的条件下,找一个损失函数最小的最终模型wf。
三、与FedAvg算法区别

在第k个客户端上做更新:做E轮循环,把数据集Pk用B的大小进行切分,切分成batches个,对于每一个batches里面的数据做梯度下降,然后整个数据集做完E轮训练得到新模型返回给中心方。
服务器端:初始化一个模型,做T轮循环,直到准确率达到要求,然后在众多客户端中随机选C*K个做梯度下降(C表示比例,K表示客户端总量),然后服务器在做梯度下降的同时,客户端也在并行的做迭代。做完上述操作后,做一个加权平均得到新模型。
FedAvg算法详解见笔者上一篇文章:文章链接
本篇文章探讨的算法如下:


ps:Lipschitz就是利普西斯连续,可以理解成它是一个连续的函数图像。
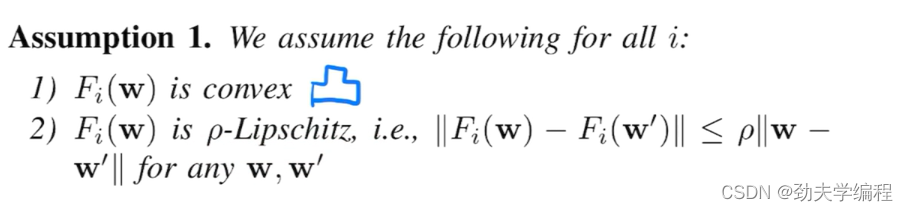
比如这里的p就可以理解成Fi(W)函数的一个斜率,p是可以通过公式算出来的。
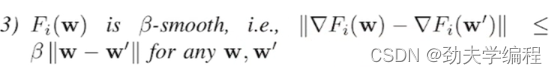

可以理解为f(x)这个函数是smooth的,那么它的梯度就是利普西斯的,就相当于是β是导数斜率
客户端算法流程:

中心方算法流程:

















 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











