






1 语法介绍:
tf.keras.utils.image_dataset_from_directory()
从目录中读取数据并进行预处理
tf.keras.utils.image_dataset_from_directory(
directory, #数据存放目录
labels='inferred', #标签由目录结构推断
label_mode='int', #标签编码方式:int、categorical、binary;分别为标签编码为整数、类别向量、二分类编码为0或1
class_names=None, #用于labels='inferred'时,类名的显式列表(必须匹配子目录的名称)。用于控制类的顺序(否则使用字母数字顺序)。
color_mode='rgb', #“grayscale”、“rgb,默认值:“rgb”,将图像转为 1、3、4通道
batch_size=32, #一次处理图像的数量
image_size=(256, 256), #指定读取图像后,调整图像大小
shuffle=True, #是否打乱原数据的顺序
seed=None, #随机种子
validation_split=None, #验证集分割比例
subset=None, #要返回的数据的子集为training或者validation或者both(训练集和验证集组成的元组)
interpolation='bilinear',#调整图像大小时用的插值方法,默认bilinear,
follow_links=False, #是否访问符号链接指向的子目录
crop_to_aspect_ratio=False, #调整图像大小时是否保留纵横比
**kwargs
)
tf.data.Dataset.take()
从该数据集中创建最多包含count个元素的数据集。
tf.data.Dataset.take(
count, #子集最多包含的数量
name=None, #源数据名称
)
2 tf.keras.utils.image_dataset_from_directory()数据预处理
import tensorflow as tf
import os
import matplotlib.pyplot as plt
train_dir="E:/machine learning data/rps_data/rps_train/" #训练集
test_dir="E:/machine learning data/rps_data/rps_test/"
train_data=tf.keras.utils.image_dataset_from_directory(
train_dir,
labels='inferred',
label_mode='int',#标签编码
validation_split=0.2,#验证集比例为20%
subset='training',#处理后得到的数据为训练集
seed=123,
#class_names=
shuffle=True,
color_mode='rgb',
batch_size=32,
image_size=(64,64)
)
validation_data=tf.keras.utils.image_dataset_from_directory(
train_dir,
labels='inferred',
label_mode='int',#标签编码
validation_split=0.2,
subset='validation',#处理后得到的数据为验证集
seed=123,
#class_names=
shuffle=True,
color_mode='rgb',
batch_size=32,
image_size=(64,64)
)
test_data=tf.keras.utils.image_dataset_from_directory(
test_dir,
labels='inferred',#自己推断标签,根据目录结构
label_mode='int',
shuffle=True,
color_mode='rgb',
batch_size=32,
image_size=(64,64)
)结果:

3 tf.data.Dataset.take()显示训练数据前几张图像
#查看训练集的前9张图片
class_names=train_data.class_names
print(class_names)
plt.figure(figsize=(10,10))
for image,label in train_data.take(1): #BatchDataset类型数据返回最多一个批次为包含图像数组和标签的元组,图像数组shape=(32,64,64,3),标签(32,1)
#print(image,label)
for i in range(9):
ax=plt.subplot(3,3,i+1)
plt.imshow(image[i].numpy().astype("uint8"))#转换为numpy形式的数组
plt.axis('off')
plt.title(class_names[label[i]])结果:

4 模型构建和训练
#构建模型
model=tf.keras.Sequential([
tf.keras.layers.Rescaling(1/255),
tf.keras.layers.Conv2D(64,(3,3),padding='same',activation='relu',input_shape=(64,64,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128,(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(3,activation='softmax')
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
metrics=['acc'])
model.build(input_shape=(2016,64,64,3))
model.summary()
#模型开始训练
import datetime
start_time=datetime.datetime.now()
epochs=10
history=model.fit(train_data,validation_data=validation_data,epochs=epochs,verbose=1)
#模型结束训练
end_time=datetime.datetime.now()
cost_time=end_time-start_time
print('模型训练时长:',cost_time)
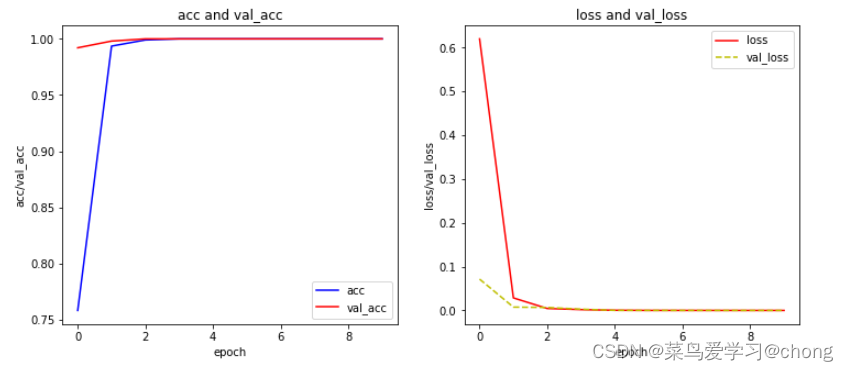
5 查看训练精度和损失以及验证集精度和损失
#查看精度和损失
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
x=range(len(acc))
fig,ax=plt.subplots(1,2,figsize=(12,5))
ax1=ax[0]
ax2=ax[1]
ax1.plot(x,acc,'b',label='acc')
ax1.plot(x,val_acc,'r',label='val_acc')
ax1.set_xlabel('epoch')
ax1.set_ylabel('acc/val_acc')
ax1.set_title('acc and val_acc')
ax1.legend()
ax2.plot(x,loss,'r',label='loss')
ax2.plot(x,val_loss,'y',linestyle='--',label='val_loss')
ax2.set_xlabel('loss')
ax2.set_ylabel('val_loss')
ax2.set_title('loss and val_loss')
ax2.legend()
plt.show()
结果:
















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











