






1. 线性表的定义
线性表:零个或多个数据元素的有限序列。
这里需要强调几个关键的地方。
首先它是一个序列。也就是说,元素之间是有顺序的,若元素存在多个,则第一个元素无前驱,最后一个元素无后继,其他每个元素都有且只有一个前驱和后继。
然后,线性表强调是限有的,元素的个数是有限的。事实上,在计算机中处理的对象都是有限的,那种无限的数列,只存在于数学的概念中。
如果用数学语言来进行定义。可如下:
若将线性表记为(a1,…,ai-1,ai,ai+1,…,an),则表中ai-1领先于ai,ai领先于ai+1,称ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素。当i=1,2,…,n-1时,ai有且仅有一个直接后继,当i=2,3,…,n时,ai有且仅有一个直接前驱。
所以线性表元素的个数n(n≥0)定义为线性表的长度,当n=0时,称为空表。
在非空表中的每个数据元素都有一个确定的位置,如a1是第一个数据元素,an是最后一个数据元素,ai是第i个数据元素,称i为数据元素ai在线性表中的位序。
我现在说一些数据集,大家来判断一下是否是线性表。
先来一个大家最感兴趣的,一年里的星座列表,是不是线性表呢?
 当然是,星座通常都是用白羊座打头,双鱼座收尾,当中的星座都有前驱和后继,而且一共也只有十二个,所以它完全符合线性表的定义。
当然是,星座通常都是用白羊座打头,双鱼座收尾,当中的星座都有前驱和后继,而且一共也只有十二个,所以它完全符合线性表的定义。
公司的组织架构,总经理管理几个总监,每个总监管理几个经理,每个经理都有各自的下属和员工。这样的组织架构是不是线性关系呢?
不是,为什么不是呢?哦,因为每一个元素,都有不只一个后继,所以它不是线性表。那种让一个总经理只管一个总监,一个总监只管一个经理,一个经理只管一个员工的公司,俗称皮包公司,岗位设置等于就是在忽悠外人。
2. 线性表的抽象数据类型
前面我们已经给了线性表的定义,现在我们来分析一下,线性表应该有一些什么样的操作呢?
还是用幼儿园小朋友排队下学的例子,老师为了让小朋友有秩序地出入,所以就考虑给他们排一个队,并且是长期使用的顺序,这个考虑和安排的过程其实就是一个线性表的创建和初始化过程。一开始没经验,把小朋友排好队后,发现有的高有的矮,队伍很难看,于是就让小朋友解散重新排——这是一个线性表重置为空表的操作。
还有什么呢,有时我们想知道,某个小朋友,比如麦兜是否是班里的小朋友,老师会告诉我说,不是,麦兜在春田花花幼儿园里,不在我们幼儿园。这种查找某个元素是否存在的操作很常用。
而后有家长问老师,班里现在到底有多少个小朋友呀,这种获得线性表长度的问题也很普遍。
显然,对于一个幼儿园来说,加入一个新的小朋友到队列中,或因某个小朋友生病,需要移除某个位置,都是很正常的情况。对于一个线性表来说,插入数据和删除数据都是必须的操作。
所以,线性表的抽象数据类型定义如下:

对于不同的应用,线性表的基本操作是不同的,上述操作是最基本的,对于实际问题中涉及的关于线性表的更复杂操作,完全可以用这些基本操作的组合来实现。
比如,要实现两个线性表集合A和B的并集操作。即要使得集合A=A∪B。说白了,就是把存在集合B中但并不存在A中的数据元素插入到A中即可。
仔细分析一下这个操作,发现我们只要循环集合B中的每个元素,判断当前元素是否存在A中,若不存在,则插入到A中即可。思路应该是很容易想到的。
我们假设La表示集合A,Lb表示集合B,则实现的代码如下:
 这里,我们对于union操作,用到了前面线性表基本操作ListLength、GetElem、LocateElem、ListInsert等,可见,对于复杂的个性化的操作,其实就是把基本操作组合起来实现的。
这里,我们对于union操作,用到了前面线性表基本操作ListLength、GetElem、LocateElem、ListInsert等,可见,对于复杂的个性化的操作,其实就是把基本操作组合起来实现的。
3. 线性表的顺序存储结构
3.1 顺序存储定义
说这么多的线性表,我们来看看线性表的两种物理结构的第一种——顺序存储结构。
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。
线性表(a1,a2,……,an)的顺序存储示意图如下:
3.2 顺序存储方式
线性表的顺序存储结构就是在内存中找了块地儿,通过占位的形式,把一定内存空间给占了,然后把相同数据类型的数据元素依次存放在这块空地中.。既然线性表的每个数据元素的类型都相同,所以可以用C语言(其他语言也相同)的一维数组来实现顺序存储结构,即把第一个数据元素存到数组下标为0的位置中,接着把线性表相邻的元素存储在数组中相邻的位置。
描述顺序存储结构需要三个属性:
■ 存储空间的起始位置:数组data,它的存储位置就是存储空间的存储位置。
■ 线性表的最大存储容量:数组长度MaxSize。
■ 线性表的当前长度:length。
3.4 数据长度与线性表长度区别
注意哦,这里有两个概念“数组的长度”和“线性表的长度”需要区分一下。
数组的长度是存放线性表的存储空间的长度,存储分配后这个量是一般是不变的。有个别同学可能会问,数组的大小一定不可以变吗?我怎么看到有书中谈到可以动态分配的一维数组。是的,一般高级语言,比如C、VB、C++都可以用编程手段实现动态分配数组,不过这会带来性能上的损耗。
线性表的长度是线性表中数据元素的个数,随着线性表插入和删除操作的进行,这个量是变化的。
在任意时刻,线性表的长度应该小于等于数组的长度。
3.5 地址计算方法
由于我们数数都是从1开始数的,线性表的定义也不能免俗,起始也是1,可C语言中的数组却是从0开始第一个下标的,于是线性表的第i个元素是要存储在数组下标为i-1的位置,即数据元素的序号和存放它的数组下标之间存在对应关系

用数组存储顺序表意味着要分配固定长度的数组空间,由于线性表中可以进行插入和删除操作,因此分配的数组空间要大于等于当前线性表的长度。
其实,内存中的地址,就和图书馆或电影院里的座位一样,都是有编号的。存储器中的每个存储单元都有自己的编号,这个编号称为地址。当我们占座后,占座的第一个位置确定后,后面的位置都是可以计算的。试想一下,我是班级成绩第五名,我后面的10名同学成绩名次是多少呢?当然是6,7,…、15,因为5+1,5+2,…,5+10。由于每个数据元素,不管它是整型、实型还是字符型,它都是需要占用一定的存储单元空间的。假设占用的是c个存储单元,那么线性表中第i+1个数据元素的存储位置和第i个数据元素的存储位置满足下列关系.
所以对于第i个数据元素ai的存储位置可以由a1推算得出:

也就是如下图所示
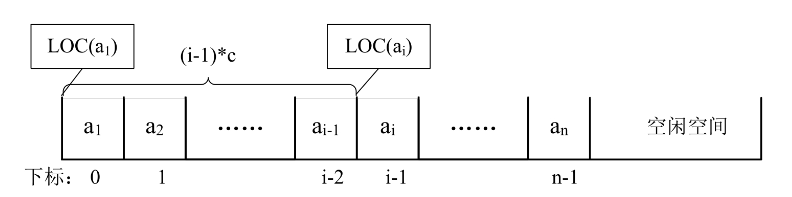
通过这个公式,你可以随时算出线性表中任意位置的地址,不管它是第一个还是最后一个,都是相同的时间。那么我们对每个线性表位置的存入或者取出数据,对于计算机来说都是相等的时间,也就是一个常数,因此用我们算法中学到的时间复杂度的概念来说,它的存取时间性能为O(1)。我们通常把具有这一特点的存储结构称为随机存取结构。
3.6. 线性表顺序存储结构的优缺点

4. 线性表的链式存储结构
前面我们讲的线性表的顺序存储结构。它是有缺点的,最大的缺点就是插入和删除时需要移动大量元素,这显然就需要耗费时间。能不能想办法解决呢?
要解决这个问题,我们就得考虑一下导致这个问题的原因。
为什么当插入和删除时,就要移动大量元素,仔细分析后,发现原因就在于相邻两元素的存储位置也具有邻居关系。它们编号是1,2,3,…,n,它们在内存中的位置也是挨着的,中间没有空隙,当然就无法快速介入,而删除后,当中就会留出空隙,自然需要弥补。问题就出在这里。
同学思路:让当中每个元素之间都留有一个空位置,这样要插入时,就不至于移动。可一个空位置如何解决多个相同位置插入数据的问题呢?所以这个想法显然不行。
B同学思路:那就让当中每个元素之间都留足够多的位置,根据实际情况制定空隙大小,比如10个,这样插入时,就不需要移动了。万一10个空位用完了,再考虑移动使得每个位置之间都有10个空位置。如果删除,就直接删掉,把位置留空即可。这样似乎暂时解决了插入和删除的移动数据问题。可这对于超过10个同位置数据的插入,效率上还是存在问题。对于数据的遍历,也会因为空位置太多而造成判断时间上的浪费。而且显然这里空间复杂度还增加了,因为每个元素之间都有若干个空位置。
C同学思路:我们反正也是要让相邻元素间留有足够余地,那干脆所有的元素都不要考虑相邻位置了,哪有空位就到哪里,而只是让每个元素知道它下一个元素的位置在哪里,这样,我们可以在第一个元素时,就知道第二个元素的位置(内存地址),而找到它;在第二个元素时,再找到第三个元素的位置(内存地址)。这样所有的元素我们就都可以通过遍历而找到。
好!太棒了,这个想法非常好!C同学,你可惜生晚了几十年,不然,你的想法对于数据结构来讲就是划时代的意义。我们要的就是这个思路。
4.1 线性表链式存储结构定义
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置

以前在顺序结构中,每个数据元素只需要存数据元素信息就可以了。现在链式结构中,除了要存数据元素信息外,还要存储它的后继元素的存储地址。
因此,为了表示每个数据元素ai与其直接后继数据元素ai+1之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
n个结点(ai的存储映像)链结成一个链表,即为线性表(a1,a2,…,an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起,如下图所示。
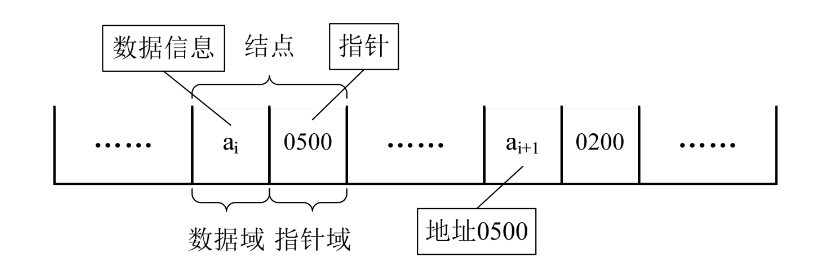
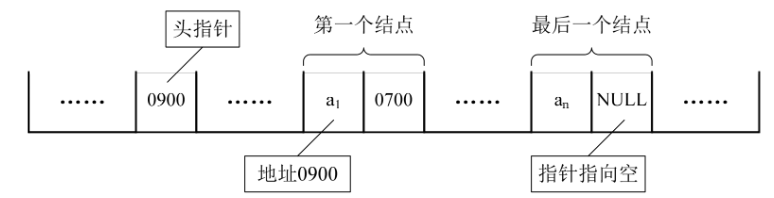
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中第一个结点的存储位置叫做头指针,那么整个链表的存取就必须是从头指针开始进行了。之后的每一个结点,其实就是上一个的后继指针指向的位置。想象一下,最后一个结点,它的指针指向哪里?
最后一个,当然就意味着直接后继不存在了,所以我们规定,线性链表的最后一个结点指针为“空”(通常用NULL或“^”符号表示,如下图所示)。
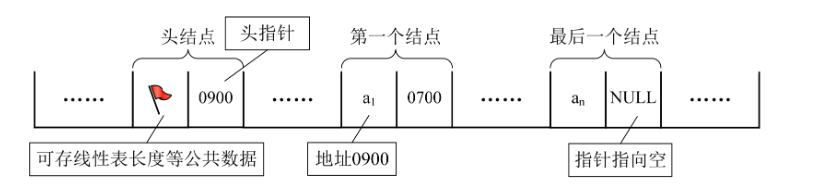
有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的数据域可以不存储任何信息,谁叫它是第一个呢,有这个特权。也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针,如下图所示。
4.2 头指针与头结点的异同
4.3 线性表链式存储结构代码描述

带有头结点的单链表

空链表

单链表中,我们在C语言中可用结构指针来描述。

从这个结构定义中,我们也就知道,结点由存放数据元素的数据域存放后继结点地址的指针域组成。
假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next的值是一个指针。p->next指向谁呢?当然是指向第i+1个元素,即指向ai+1的指针。也就是说,如果p->data=ai,那么p->next->data=ai+1

4.4 单链表的读取
在线性表的顺序存储结构中,我们要计算任意一个元素的存储位置是很容易的。但在单链表中,由于第i个元素到底在哪?没办法一开始就知道,必须得从头开始找。因此,对于单链表实现获取第i个元素的数据的操作GetElem,在算法上,相对要麻烦一些。
获得链表第i个数据的算法思路:
1.声明一个结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,返回结点p的数据。
实现代码算法如下:

说白了,就是从头开始找,直到第i个元素为止。由于这个算法的时间复杂度取决于i的位置,当i=1时,则不需遍历,第一个就取出数据了,而当i=n时则遍历n-1次才可以。因此最坏情况的时间复杂度是O(n)。
由于单链表的结构中没有定义表长,所以不能事先知道要循环多少次,因此也就不方便使用for来控制循环。其主要核心思想就是“工作指针后移”,这其实也是很多算法的常用技术。此时就有人说,这么麻烦,这数据结构有什么意思!还不如顺序存储结构呢。
哈,世间万物总是两面的,有好自然有不足,有差自然就有优势。下面我们来看一下在单链表中的如何实现“插入”和“删除”。
4.5 单链表的插入与删除
a 单链表的插入
先来看单链表的插入。假设存储元素e的结点为s,要实现结点p、p->next和s之间逻辑关系的变化,只需将结点s插入到结点p和p->next之间即可。可如何插入呢?

根本用不着惊动其他结点,只需要让s->next和p->next的指针做一点改变即可。
![]()
解读这两句代码,也就是说让p的后继结点改成s的后继结点,再把结点s变成p的后继结点.
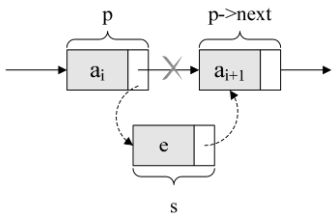
考虑一下,这两句的顺序可不可以交换?
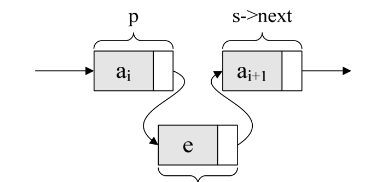
如果先p->next=s;再s->next=p->next;会怎么样?哈哈,因为此时第一句会使得将p->next给覆盖成s的地址了。那么s->next=p->next,其实就等于s->next=s,这样真正的拥有ai+1数据元素的结点就没了上级。这样的插入操作就是失败的,造成了临场掉链子的尴尬局面。所以这两句是无论如何不能反的,这点初学者一定要注意。
插入结点s后,链表如下图所示。
对于单链表的表头和表尾的特殊情况,操作是相同的,如下图所示。

单链表第i个数据插入结点的算法思路:
1.声明一结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,在系统中生成一个空结点s;
5.将数据元素e赋值给s->data;
6.单链表的插入标准语句s->next=p->next; p->next=s;
7.返回成功。

在这段算法代码中,我们用到了C语言的malloc标准函数,它的作用就是生成一个新的结点,其类型与Node是一样的,其实质就是在内存中找了一小块空地,准备用来存放e数据s结点。
b 单链表的删除
现在我们再来看单链表的删除。设存储元素ai的结点为q,要实现将结点q删除单链表的操作,其实就是将它的前继结点的指针绕过,指向它的后继结点即可,如下图所示。
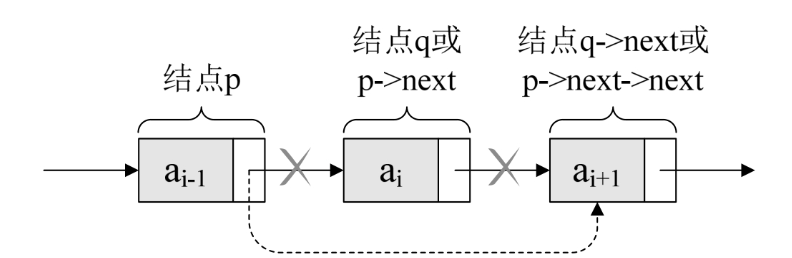
我们所要做的,实际上就是一步,p->next=p->next->next,用q来取代p->next,即是
![]()
单链表第i个数据删除结点的算法思路:
1.声明一结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,将欲删除的结点p->next赋值给q;
5.单链表的删除标准语句p->next=q->next;
6.将q结点中的数据赋值给e,作为返回;
7.释放q结点;8.返回成功。
实现代码算法如下:

这段算法代码里,我们又用到了另一个C语言的标准函数free。它的作用就是让系统回收一个Node结点,释放内存。
分析一下刚才我们讲解的单链表插入和删除算法,我们发现,它们其实都是由两部分组成:第一部分就是遍历查找第i个元素;第二部分就是插入和删除元素。
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(n)。如果在我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。但如果,我们希望从第i个位置,插入10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个元素,每次都是O(n)。而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显。
5. 单链表的整表创建
回顾一下,顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而单链表和顺序存储结构就不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始状态起,依次建立各元素结点,并逐个插入链表。
单链表整表创建的算法思路:
1.声明一结点p和计数器变量i;
2.初始化一空链表L;
3.让L的头结点的指针指向NULL,即建立一个带头结点的单链表;
4.循环:◆ 生成一新结点赋值给p;◆ 随机生成一数字赋值给p的数据域p->data;◆ 将p插入到头结点与前一新结点之间。
实现代码算法如下:

这段算法代码里,我们其实用的是插队的办法,就是始终让新结点在第一的位置。我也可以把这种算法简称为头插法,如下图所示。
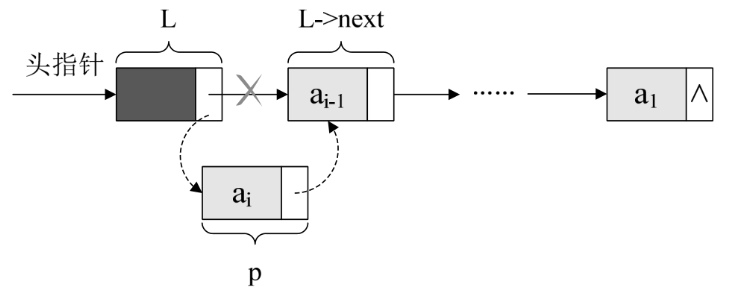
可事实上,我们还是可以不这样干,为什么不把新结点都放到最后呢,这才是排队时的正常思维,所谓的先来后到。我们把每次新结点都插在终端结点的后面,这种算法称之为尾插法。
实现代码算法如下:
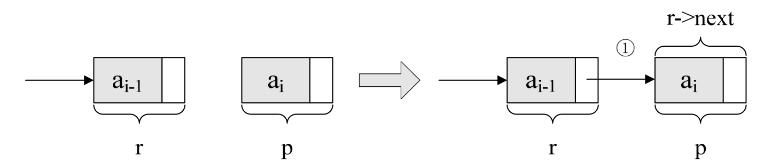
 注意L与r的关系,L是指整个单链表,而r是指向尾结点的变量,r会随着循环不断地变化结点,而L则是随着循环增长为一个多结点的链表。
注意L与r的关系,L是指整个单链表,而r是指向尾结点的变量,r会随着循环不断地变化结点,而L则是随着循环增长为一个多结点的链表。
6. 单链表的整表删除
当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将它释放掉,以便于留出空间给其他程序或软件使用。
单链表整表删除的算法思路如下:
1.声明一结点p和q;
2.将第一个结点赋值给p;
3.循环:◆ 将下一结点赋值给q;◆ 释放p;◆ 将q赋值给p。
实现代码算法如下:

这段算法代码里,常见的错误就是有同学会觉得q变量没有存在的必要。在循环体内直接写free(p);p=p->next;即可。可这样会带来什么问题?
要知道p是一个结点,它除了有数据域,还有指针域。你在做free(p);时,其实是在对它整个结点进行删除和内存释放的工作。这就好比皇帝快要病死了,却还没有册封太子,他儿子五六个,你说要是你脚一蹬倒是解脱了,这国家咋办,你那几个儿子咋办?这要是为了皇位,什么亲兄弟血肉情都成了浮云,一定会打起来。所以不行,皇帝不能马上死,得先把遗嘱写好,说清楚,哪个儿子做太子才行。而这个遗嘱就是变量q的作用,它使得下一个结点是谁得到了记录,以便于等当前结点释放后,把下一结点拿回来补充。明白了吗?
好了,说了这么多,我们可以来简单总结一下。
7. 单链表结构与顺序存储结构优缺点
简单地对单链表结构和顺序存储结构做对比:

通过上面的对比,我们可以得出一些经验性的结论:
■ 若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。若需要频繁插入和删除时,宜采用单链表结构。比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
■ 当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间的大小问题。而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。总之,线性表的顺序存储结构和单链表结构各有其优缺点,不能简单的说哪个好,哪个不好,需要根据实际情况,来综合平衡采用哪种数据结构更能满足和达到需求和性能。















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









