






2.4.如果没有拷贝成功就将hadoop2和hadoop3的hadoop文件夹删除,然后在拷贝一次
一、配置Hadoop环境
1.查看Hadoop解压位置
pwd

2.配置环境变量
vim /etc/profile

3.编辑环境变量
“/opt/server/hadoop”填自己Hadoop的存放位置。
export HADOOP_HOME=/opt/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin

4.重启环境变量
source /etc/profile

5.查看Hadoop版本,查看成功就表示Hadoop安装成功了
hadoop version

二、修改配置文件
1.检查三台虚拟机:
是否都安装了jdk和hadoop并且配置了环境变量,确保虚拟机之间都能互相ping通以及两两之间能够ssh免密登陆,都完成了网卡、主机名、hosts文件等配置。
| ip地址 | 主机名 | 节点 |
|---|---|---|
| 192.168.147.200 | hadoop | 主节点 |
| 192.168.147.201 | hadoop2 | 子节点 |
| 192.168.147.203 | hadoop3 | 子节点 |
2.切换到配置文件目录
cd /opt/server/hadoop/etc/hadoop

3.修改 hadoop-env.sh 文件
路径改成自己的jdk安装路径(vim命令用不了就用vi)
vim hadoop-env.sh
export JAVA_HOME=/opt/server/jdk


4.修改 core-site.xml 文件
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 用于指定namenode地址在机器master上-->
<value>hdfs://hadoop:8020</value>
</property>
<!-- 用于配置hadoop的数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/server/hadoop/data</value>
</property>
</configuration>

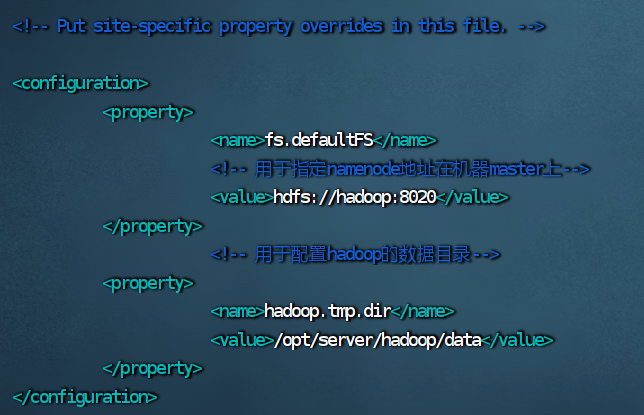
5.修改 mapred-site.xml 文件
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

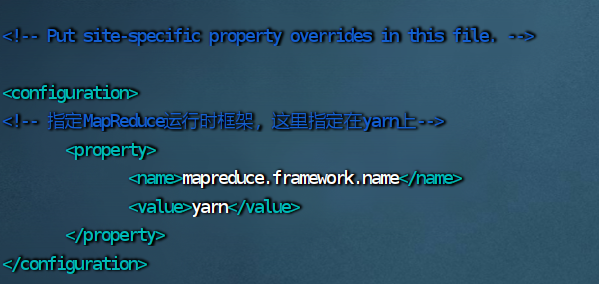
6.修改 hdfs-site.xml 文件
vim hdfs-site.xml
<configuration>
<!--指定HDFS副本的数量,不能超过机器节点数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 为secondary namenode配置所在的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:50090</value>
</property>
</configuration>


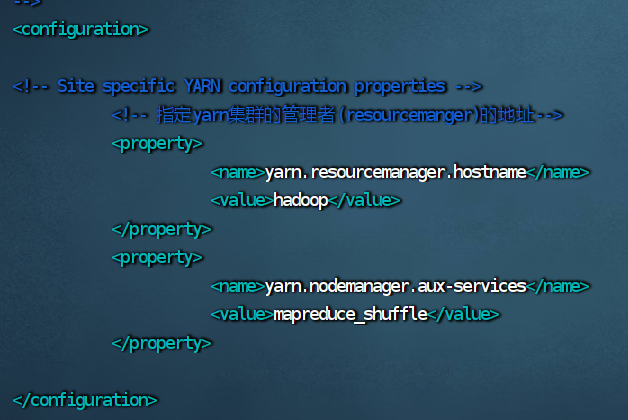
7.修改 yarn-site.xml 文件
vim yarn-site.xml
<configuration>
<!-- 指定yarn集群的管理者(resourcemanger)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

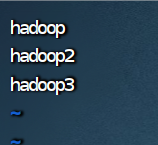
8.修改 workers 文件
vim workers
hadoop
hadoop2
hadoop3

三、给hadoop2、hadoop3分发文件
1.到存放hadoop的文件夹下
cd /opt/server/

2.1.给hadoop2和hadoop3拷贝文件和环境变量
scp -r hadoop-3.2.4/ root@hadoop2:/opt/server/hadoop-3.2.4/
scp /etc/profile root@hadoop2:/etc/profile


2.2.给hadoop2和hadoop3创建软连接
ln -s hadoop-3.2.4/ hadoop

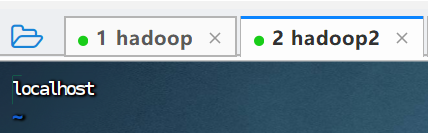
2.3.检查hadoop2和hadoop3是否拷贝成功
hadoop的配置文件拷贝给了hadoop2和hadoop3,在hadoop2打开workers。
vim workers

hadoop2的workers没被修改,说明没拷贝成功。
2.4.如果没有拷贝成功就将hadoop2和hadoop3的hadoop文件夹删除,然后在拷贝一次
rm -rf hadoop-3.2.4

重复2.1的操作
四、修改脚本文件
1.切换到hadoop的sbin目录下
脚本文件都在sbin文件下。
cd /opt/server/hadoop/sbin
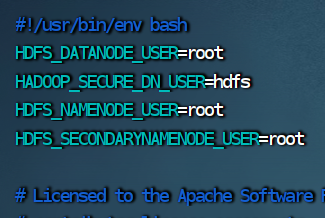
2.修改 start-dfs.sh 脚本文件
vim start-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

3.修改 stop-dfs.sh 脚本文件
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root


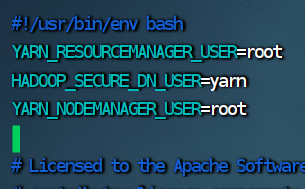
4.修改start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

4.修改 start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root


5.修改 stop-yarn.sh 脚本文件
vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root


五、启动hadoop集群
1.格式化HDFS
hadoop namenode -format


2.启动hadoop
启动hadoop和yarn一定要在sbin目录下。
./start-dfs.sh
为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?















 4844
4844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









