







在更新完ELMO、Bert之后,还有一个家族成员——GPT需要记录。其实也一直想写啦,只不过最近都在玩。那什么是GPT呢?GPT就是Generative Pre-Training 的简称,实际上就是transformer的decoder。那GPT在做一个怎样的工作呢?就是输入一个句子中的上一个词,我们希望GPT模型可以得到句子中的下一个词,就仅此而已。当然,由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。

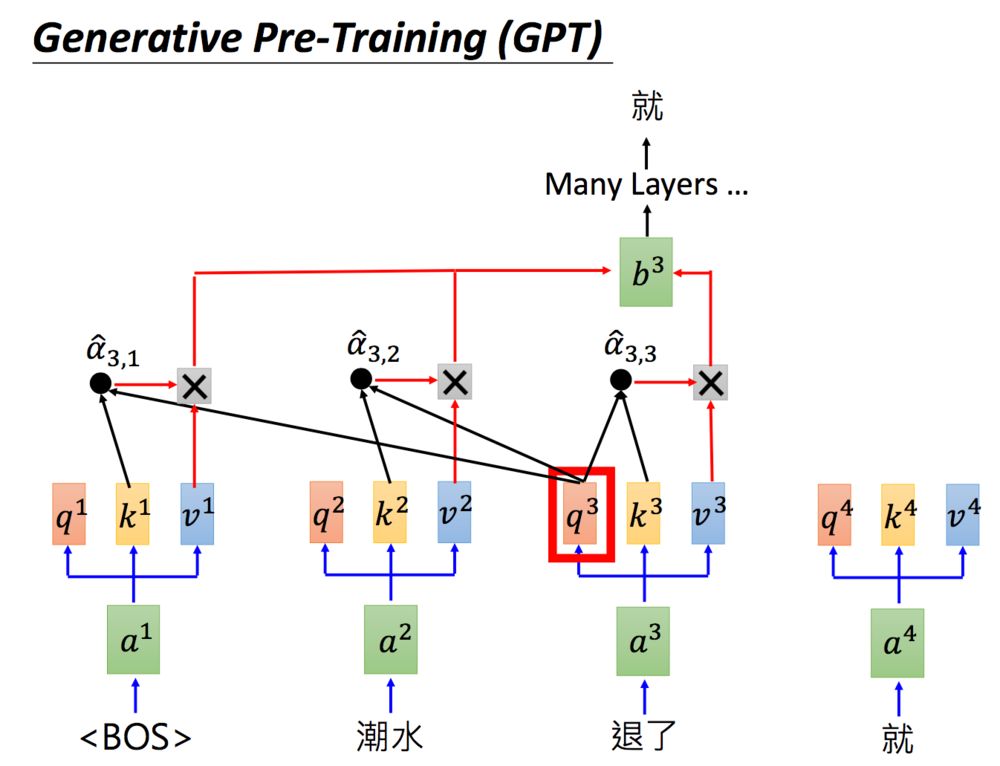
那GPT是怎么运作的呢?上面有提到说GPT要做的事情就是给它一个词汇,能够预测下一个词汇。举例来说,你给它beginning of sentence(BOS)这个token,再输入“潮水”这个词汇,希望GTPmodel可以output“退了”这个词汇。那要怎样output“退了”这个词汇呢?同样,GPT也会做self-attention:如下图,把“潮水”input进去,产生query,key跟value,也就是图中的,然后做self-attention,那具体怎么做,在之前的transformer系列都有提到过,这里就不再叙述了。
在预测完“退了”之后呢就把“退了”拿下来, 然后再问GPT说“退了”后面该接哪个词汇。那“退了”这个词汇也会产生query,key跟value,也就是图中的,然后将
呢跟已经产生的词汇包括自己做self-attention,得到的embedding通过很多层,就预测到了“就”这个词汇。那这个process呢就这样反复进行下去,就是GTPmodel要做的事情。
GPT跟GPT-2做的事情一样,就是训练一个language model ,只不过这个language model非常非常的巨大。那GPT与Bert有什么差一点呢?
1.语言模型:Bert和GPT-2虽然都采用transformer,但是Bert使用的是transformer的encoder,即:Self Attention,是双向的语言模型;而GPT-2用的是transformer中去掉中间Encoder-Decoder Attention层的decoder,即:Masked Self Attention,是单向语言模型。
2.结构:Bert是pre-training + fine-tuning的结构;而GPT-2只有pre-training。
3.输入向量:GPT-2是token embedding + position embedding;Bert是 token embedding + position embedding + segment embedding。
4.参数量:Bert是3亿参数量;而GPT-2是15亿参数量。
5.Bert引入Masked LM和Next Sentence Prediction;而GPT-2只是单纯的用单向语言模型进行训练,没引入这两个。
6.Bert不能做生成式任务,而GPT-2可以。参考NLP——Bert与GPT-2的纠葛 - 知乎 (zhihu.com)














 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









