







图形处理单元 (GPU)
要了解CUDA,我们需要具备图形处理单元(GPU)的工作知识。GPU是一种擅长处理专业计算的处理器。
这与中央处理器(CPU)形成鲜明对比,中央处理器是一种擅长处理一般计算的处理器。CPU是为我们电子设备上大多数典型计算提供动力的处理器。
GPU的计算速度比CPU快得多。但是,情况并非总是如此。GPU 相对于 CPU 的速度取决于所执行的计算类型。最适合 GPU 的计算类型是可以并行完成的计算。
并行计算
并行计算是一种计算类型,其中通过特定计算被分解为可以同时执行的独立较小计算。然后,将生成的计算重新组合或同步,以形成原始较大计算的结果。

大型任务可以分解的任务数取决于特定硬件上包含的内核数。内核是在给定处理器内实际执行计算的单元,CPU 通常具有四个、八个或十六个内核,而 GPU 可能具有数千个内核。
还有其他重要的技术规范,但这种描述旨在推动总体思路。
有了这些工作知识,我们可以得出结论,并行计算是使用GPU完成的,我们也可以得出结论,最适合使用GPU解决的任务是可以并行完成的任务。如果计算可以并行完成,我们可以使用并行编程方法和GPU加速计算。
现在让我们把注意力转向神经网络,看看为什么GPU在深度学习中被如此频繁地使用。我们刚刚看到GPU非常适合并行计算,而关于GPU的这个事实就是深度学习使用它们的原因。
在并行计算中,并行任务是几乎不需要花费或不需要任何精力将整个任务分成一组要并行计算的较小任务。
令人尴尬地并行的任务是很容易看出一组较小的任务彼此独立。
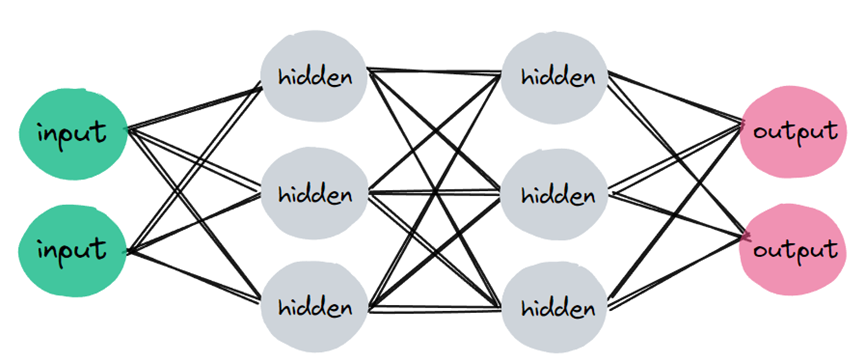
由于这个原因,神经网络是尴尬的并行。我们使用神经网络进行的许多计算可以很容易地分解成较小的计算,使得较小的计算集不相互依赖。一个这样的例子是卷积。
卷积示例
让我们看一个例子,卷积运算:

此动画展示了没有数字的卷积过程。我们在底部有一个蓝色的输入通道。底部阴影的卷积滤波器在输入通道上滑动,以及绿色输出通道:
-
蓝色(底部)- 输入通道
-
阴影(蓝色顶部) - 3 x 3卷积核
-
绿色(顶部)- 输出通道
对于蓝色输入通道上的每个位置,一个3 x 3卷积核执行计算,将蓝色输入通道的阴影部分映射到绿色输出通道的相应阴影部分。
在动画中,这些计算依次发生。但是,每个计算都独立于其他计算,这意味着任何计算都不依赖于任何其他计算的结果。
因此,所有这些独立计算都可以在GPU上并行进行,并且可以产生整个输出通道。
这使我们能够看到,通过使用并行编程方法和GPU可以加速卷积操作。
Nvidia硬件 (GPU) 和软件 (CUDA)
Nvidia是一家设计GPU的技术公司,他们将CUDA创建为一个软件平台,与他们的GPU硬件配对,使开发人员更容易构建使用Nvidia GPU的并行处理能力加速计算的软件。
![]()
Nvidia GPU是支持并行计算的硬件,而CUDA是为开发人员提供API的软件层。
因此,您可能已经猜到使用CUDA需要Nvidia GPU,并且CUDA可以从Nvidia的网站免费下载和安装。
开发人员通过下载 CUDA 工具包来使用 CUDA。随着工具包而来的是专门的库,如cuDNN,CUDA深度神经网络库。

PyTorch 附带 CUDA
使用PyTorch或任何其他神经网络API的好处之一是,并行性融入了API中。这意味着作为神经网络程序员,我们可以更多地关注构建神经网络,而不是性能问题。
有了PyTorch,CUDA从一开始就融入了。无需其他下载。我们所需要的只是有一个受支持的Nvidia GPU,我们可以使用PyTorch利用CUDA。我们不需要知道如何直接使用 CUDA API。
现在,如果我们想编写PyTorch扩展,那么知道如何直接使用CUDA可能会很有用。
毕竟,PyTorch是用所有这些编写的:
-
Python
-
C++
-
CUDA
将 CUDA 与 PyTorch 结合使用
在PyTorch中利用CUDA非常容易。如果我们想在GPU上执行特定的计算,我们可以通过在我们的数据结构(张量)上调用cuda()来指示PyTorch这样做。
假设我们有以下代码:
> t = torch.tensor([1,2,3])
> t
tensor([1, 2, 3])
默认情况下,以这种方式创建的张量对象位于 CPU 上。因此,我们使用此张量对象执行的任何操作都将在 CPU 上执行。
现在,要将张量移动到GPU上,我们只需编写:
> t = t.cuda()
> t
tensor([1, 2, 3], device='cuda:0')
这种能力使PyTorch非常通用,因为计算可以在CPU或GPU上有选择地执行。
GPU 可能比 CPU 慢
我们说过,我们可以有选择地在GPU或CPU上运行计算,但为什么不直接在GPU上运行每个计算呢?
GPU不是比CPU快吗?
答案是,GPU仅针对特定任务更快。我们可能遇到的一个问题是降低性能的瓶颈。例如,将数据从 CPU移动到 GPU 的成本很高,因此在这种情况下,如果计算任务很简单,则整体性能可能会降低。

将相对较小的计算任务转移到GPU不会让我们加快速度,并且确实会减慢我们的速度。请记住,GPU适用于可以分解为许多较小任务的任务,如果计算任务已经很小,那么通过将任务移动到GPU,我们将没有太多收获。
出于这个原因,在刚开始时简单地使用CPU通常是可以接受的,并且随着我们处理更大更复杂的问题,开始更多地使用GPU。
GPGPU 计算
最初,使用GPU加速的主要任务是计算机图形学。因此得名图形处理单元,但近年来,出现了更多种类的并行任务。正如我们所看到的,其中一项任务是深度学习。
深度学习以及许多其他使用并行编程技术的科学计算任务正在导致一种称为GPGPU或通用GPU计算的新型编程模型。
GPGPU计算通常只是称为GPU计算或加速计算,因为在GPU上预制各种任务变得越来越普遍。
Nvidia一直是这一领域的先驱。Nvidia将通用GPU计算简称为GPU计算。Nvidia首席执行官黄仁勋(Jensen Huang)很早就设想了GPU计算,这就是为什么CUDA是在近10年前创建的。
尽管CUDA已经存在了很长时间,但它现在才刚刚开始真正起飞,而Nvidia迄今为止在CUDA上的工作就是为什么Nvidia在深度学习的GPU计算方面处于领先地位。
当我们听到Jensen谈论GPU计算堆栈时,他指的是GPU作为底部的硬件,CUDA作为GPU顶部的软件架构,最后是CUDA顶部的cuDNN等库。
这个GPU计算堆栈是支持在一个原本非常专业的芯片上的通用计算能力。我们经常在计算机科学中看到这样的堆栈,因为技术是分层构建的,就像神经网络一样。
坐在CUDA和cuDNN之上的是PyTorch,这是我们将要工作的框架,最终支持顶部的应用程序。
本文深入探讨了GPU计算和CUDA,但它比我们需要的要深入得多。我们将在这里使用PyTorch在堆栈顶部附近工作。
注:以上内容翻译自https://deeplizard.com/learn/video/6stDhEA0wFQ















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









