










学习DL的过程是“一定”, “务必”, “必须” 要理解关于CUDA的相关知识
就算你不是走专门CUDA平行相关编程技术的, 也必须要能理解其原理
因为所有的产品要落地后要能深得用户喜欢并且赢过其他人的产品, 运行速度非常的重要, 即使快别人一个毫秒就是赢了
那么我把内容将分成几个大类来去说
- 平行运算(Parallel computing)的起源
- CUDA的核心知识
- 简单代码实作
平行运算的起源
为什么我们需要做平行运算?
需要的场景有哪些?
- 计算的复杂度不太高
- 计算的时间长
- 需要快速的反应
- 需要大量输出
从应用的场景来看其实就能简单的总结出结论, 平行运算就好比SOP, 将单一且流程不复杂的动作进行简化来达到提高效率的目的,例如在生产工厂里的生产机台, 将程序设定好之后机台能够依照你设定好的程序快速运行, 那么一间工厂肯定不只有一个生产机台, 要是有个好几部, 那生产的效率将大大的提升, 加快产品出货的速度
拿快速反应场景来举例子, 就好比自动驾驶, 也是深度学习场景中非常热门的项目
如果透过摄像头回传的信息, 检测速度太慢实时帧率太低, 这样是不可能能让产品落地的
我们直接来谈到GPU与深度学习的关联
在2012年中, ImageNet挑战赛首次使用Nvidia GPU后的精准度大幅提高
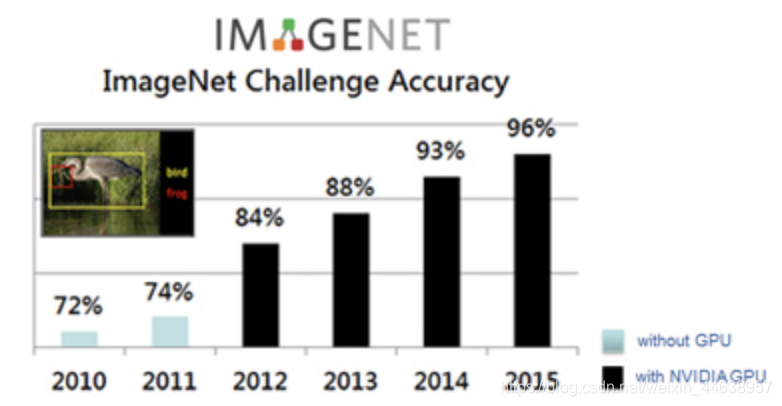
GPU带来的好处使得我们可以投入更多的数据做运算
那么GPU的平行运算架构用的是SIMD(single instrction Multiple Data)有几个以下的特点
- 所有程序单元执行相同的指令
- 多笔资料同时执行相同命令
- 对大量阵列or向量有强大处理能力
Traditional Graphic Pipeline 传统绘图
我们先简单的介绍一下传统绘图(Traditional Graphic Pipeline)的方式对后面会有更深入的理解
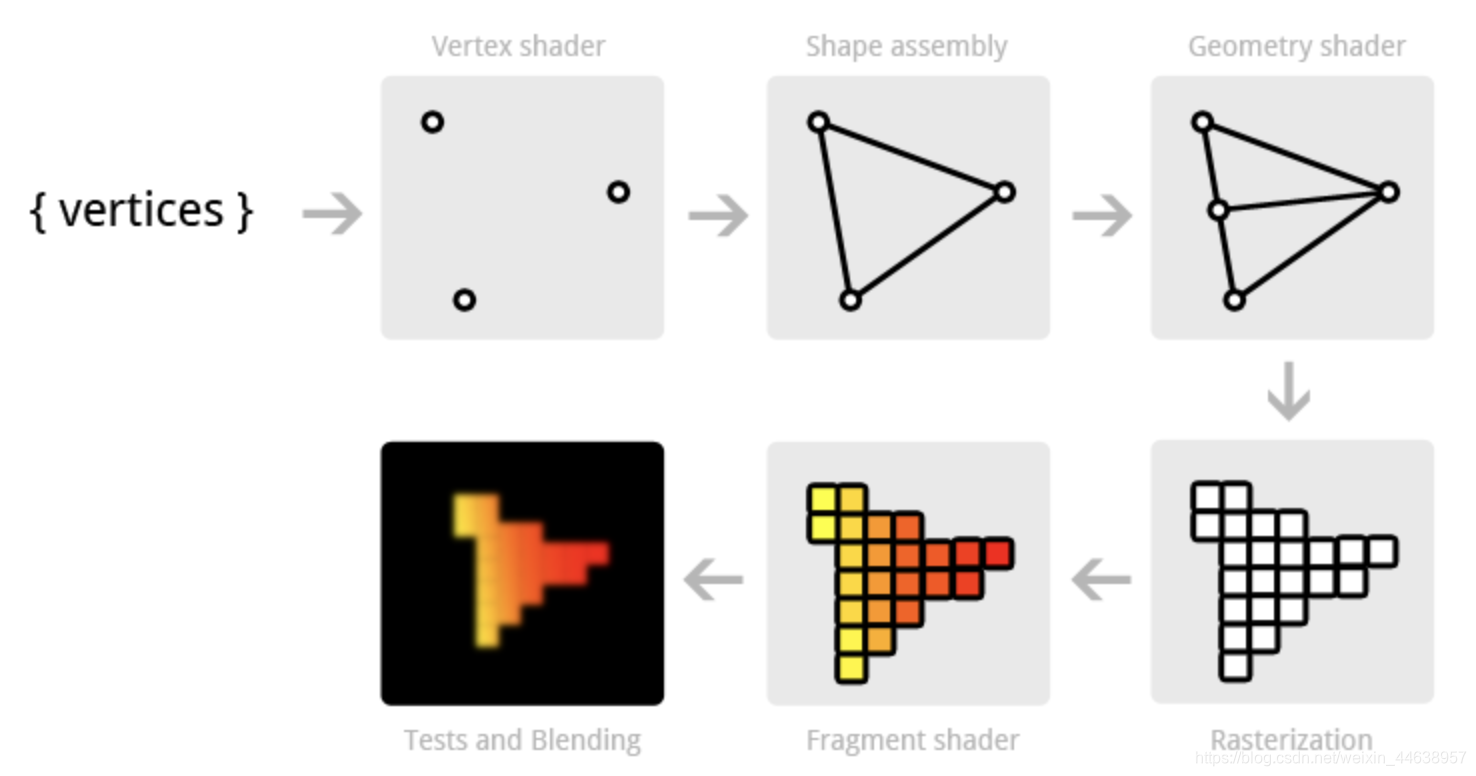
大家肯定有玩过一些3D游戏的经验, 游戏中的模组外形都是用三个点连成三角形, 拼接而成, 用三角形是因为最少的顶点能够变成一个面, 运算量就更少, 这些运算结束就会把结果投射到我们在屏幕上看到的模组, 在经过着色
但是这传统的方式会有分配不均的问题, 好比在vertex shader以及 pixel shader的地方, 导致在运算的时候, 没办法平均分配GPU的资源, 在Vertex Shader满载的时候, Pixel Shader的区块就Idle了, 于是会有资源闲置问题, 效率不佳
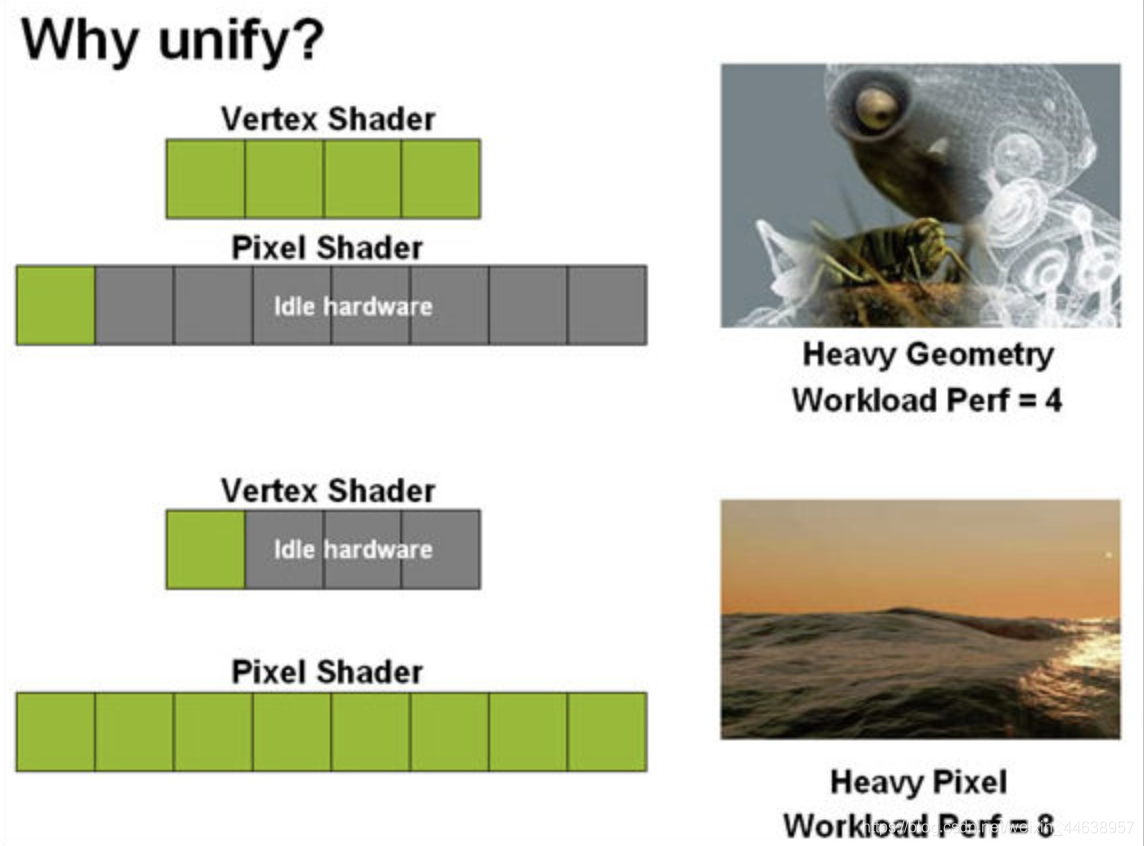
于是约在2007年后就有了新的概念Unified Shader Pipline, 统一化的绘图管线, 能够依照不同比例需求给processors, 避免资源闲置的问题

那么CUDA也是在07年的时候release了CUDA 1的版本, 因为意识到GPU不只能做图像处理, 也能加速运算, 我们要知道的是为什么GPU能比CPU更适合处理这些运算工作(例如矩阵相乘等等), 难道GPU已经可以完全取代CPU了吗?这当然不,请把CPU当做做决策的老大哥, GPU还是个听话做事能力强的小弟来看
CPU与GPU的架构如下图
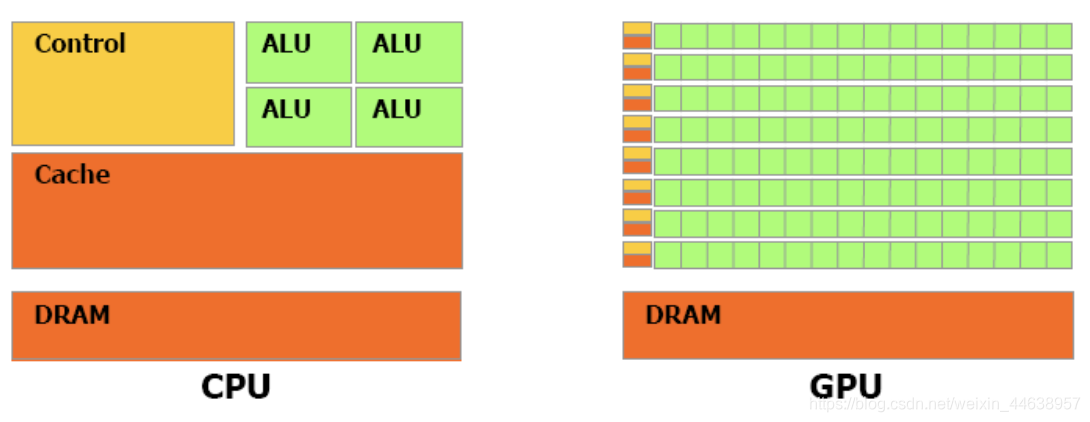
能看见两者之间的结构大不同
CPU比起GPU更适合做复杂的运算(ALU), 逻辑判断, 如我们常用到的if else语句, 另外看结构图就能发现CPU的架构Cache和Control的区块占比大很多, 因为CPU单个核心同时只能运行单线程的指令(所以后来CPU就是朝向多个核心发展), 当CPU等待某些资源的时候需要大量cache过滤内存, 减少访问内存的延迟, 而GPU需要大量简单的运算,架构则多了很多的ALU(绿色方框), 少了很多的Cache和Control, 意味着不需要太多复杂的判断与决策
这边推荐一个最佳回答关于 CPU 和 GPU 的区别是什么?
GPU能取代CPU吗? 不行, 这两者是哥俩好, 互相协同帮忙, 但也许未来CPU以及GPU有可能合并这也说不定, 谁知道未来会怎么样呢?
CUDA(Compute Unified Device Architecture)
什么是CUDA?直接翻译就是统一计算架构,由NVIDIA推出
下面分成硬件以及软件来说说
Hardware的部分
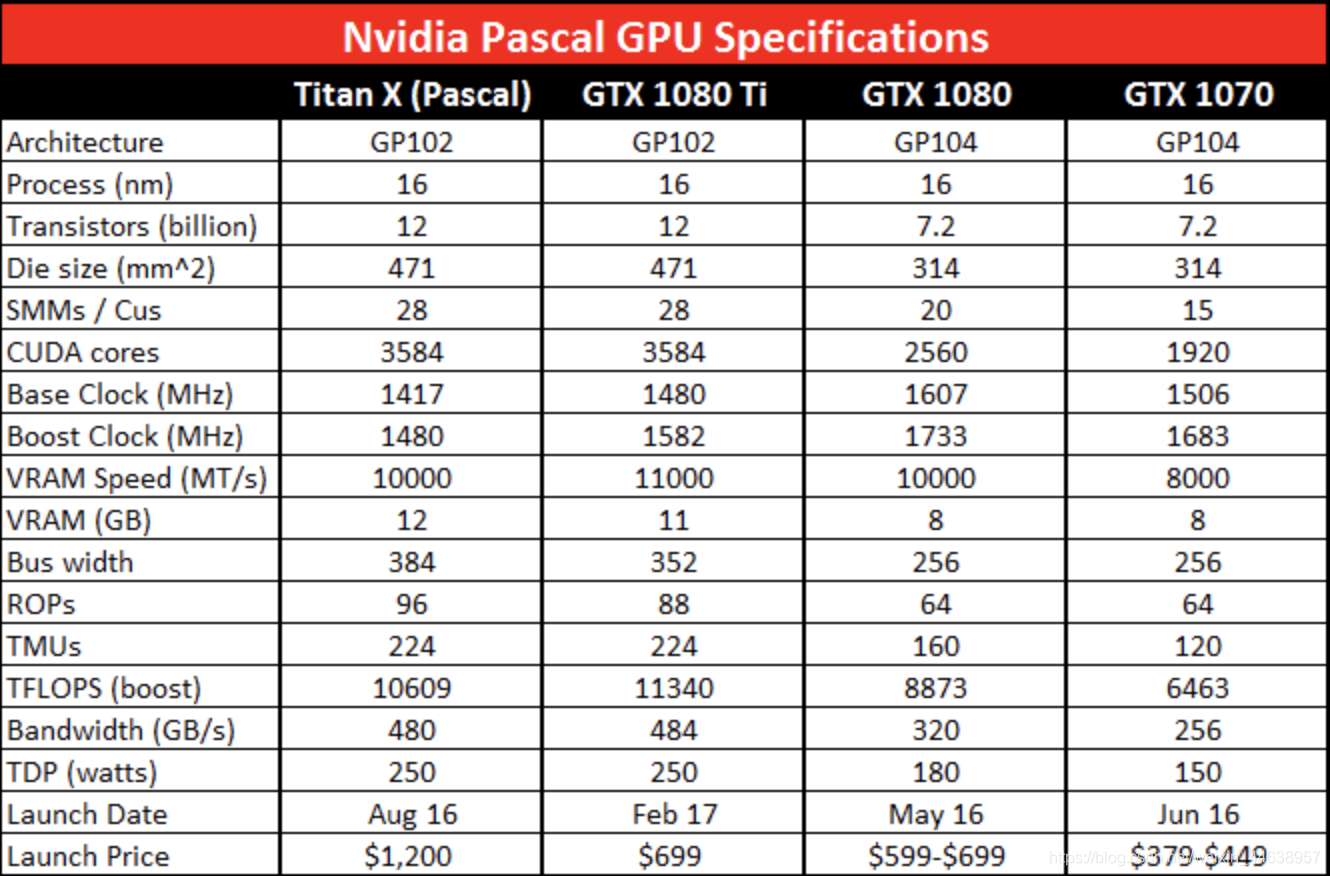
选配深度学习配置的时候,一定会注意这些规格
-
Stream Processors SP 可以说是CUDA cores
可以看见1080TI CUDA Cores(single precision), 也就表示CUDA的核心数为3584, 明显比GTX1080 和 1070来的核心数更多, 也意味着处理平行效率更强 -
Stream Multiprocessors (SM)
一个GPU由多个SM组成, 看下图GTX 1080示例 单个SM的结构, SM就是由许多的CUDA cores以及其他像是Warp selector, Shared memory, L1 cache所组成, SM就像是GPU的核心(对比CPU核心)
SP是包含在SM中的, 一组SM包含多少SP, 就是看架构, 这边不细说, 可以自行搜寻Fermi, GF100,GF10X,Kepler等去了解, 那么就能够联想到一张GPU上的SM越多, 也就代表GPU越高阶

硬件先说到这里, 待会讲完软件何在一起说就会很清楚了
Software的部分
CUDA除了是一种平行运算的架构也是CPU与GPU协调工作的一种通用语言
CUDA可分为host和device, host也就是CPU或着当成拥有GPU的电脑, 读写档案配置内存, 或者呼叫GPU资源, device就是GPU, 有独立的计算资源, host要传送数据到device上的内存才能在device中处理, 而在device上执行的程序就是kernel function, 那么就是经由thread来执行这同一个kernel, 如下图橘色部分
下图是CUDA程序的架构
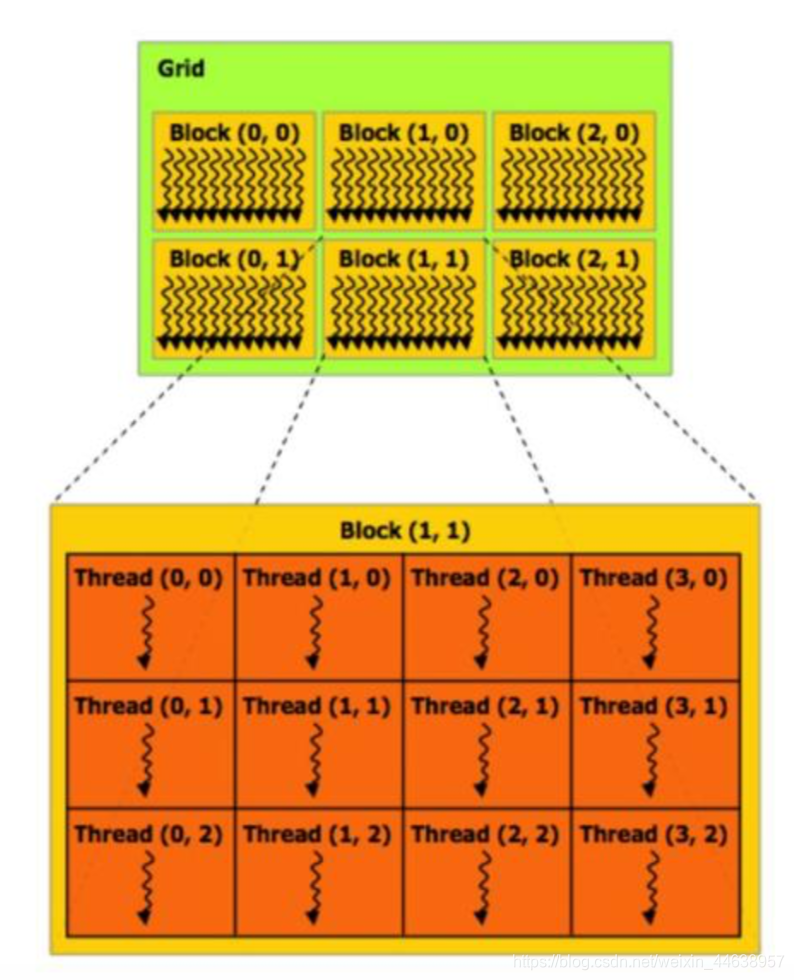
最最最主要分为三个概念所组成, 很重要必须记住
- Thread :最小单元, 中文称作执行绪/线程
- Block :非常多个thread组成一个block
- Grid :多个block组成一个grid
- Warp :每32个thread组成一组warp, 一组warp中所有thread执行相同的指令,
这几个名词是一个比较虚拟的概念, 能够由我们在编写CUDA时自由去分配数量, 依照加速需求的不同去做分配, Thread是包含在Block中, 这个线程就是OS能够运算排程的最小单位,
每一个block中的thread是有上限的, 也许是512, 也许是1024 依照GPU的架构会有所不同
CUDA 程序与GPU的搭配
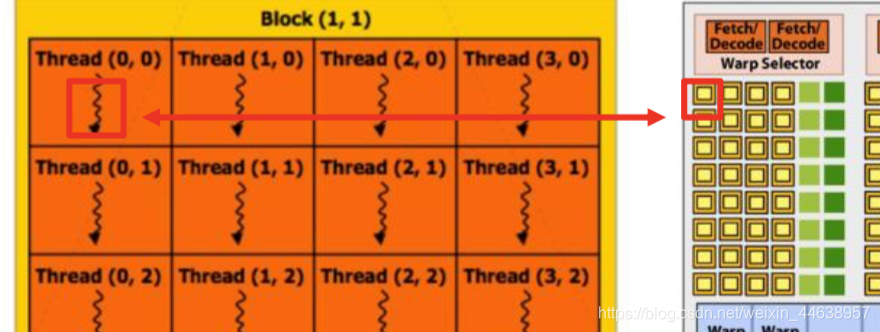
简单的介绍完硬件和软件上的一些基本概念, 那么两者之间该如何搭配?其中的概念又是如何?
前面在说到的kernel function 也就是device要执行程序时, 会将你所指定的thread 和 block的数量分配到GPU上的SM做运算, 然后经由GPU上的Warp selector (Warp scheduler)来分配资源, GPU能支持上千的线程平行执行, 一个SP能执行一个thread, 那你会问 那假设指定了1024个thread, 所有的thread都会同时丢到SM中执行吗?
前面说过有个叫做warp selector(warp scheduler)的东西在SM上, 并且warp中所有的threads以不同的资料, 平行计算相同的指令, warp是由32个thread组成(在software部分有讲过),假设一个block安排了128个threads时候, 那么交给warp selector时, 就会分成128/32组, 如果block不足32, 也会被当成一个独立的warp, 好比一个block中有120个thread, 120/32 余数为24, 也就是说最后一个warp就浪费了32-24个thread的计算能力, 所以在设定thread数量时最好以32倍数为基础, 不要浪费了资源
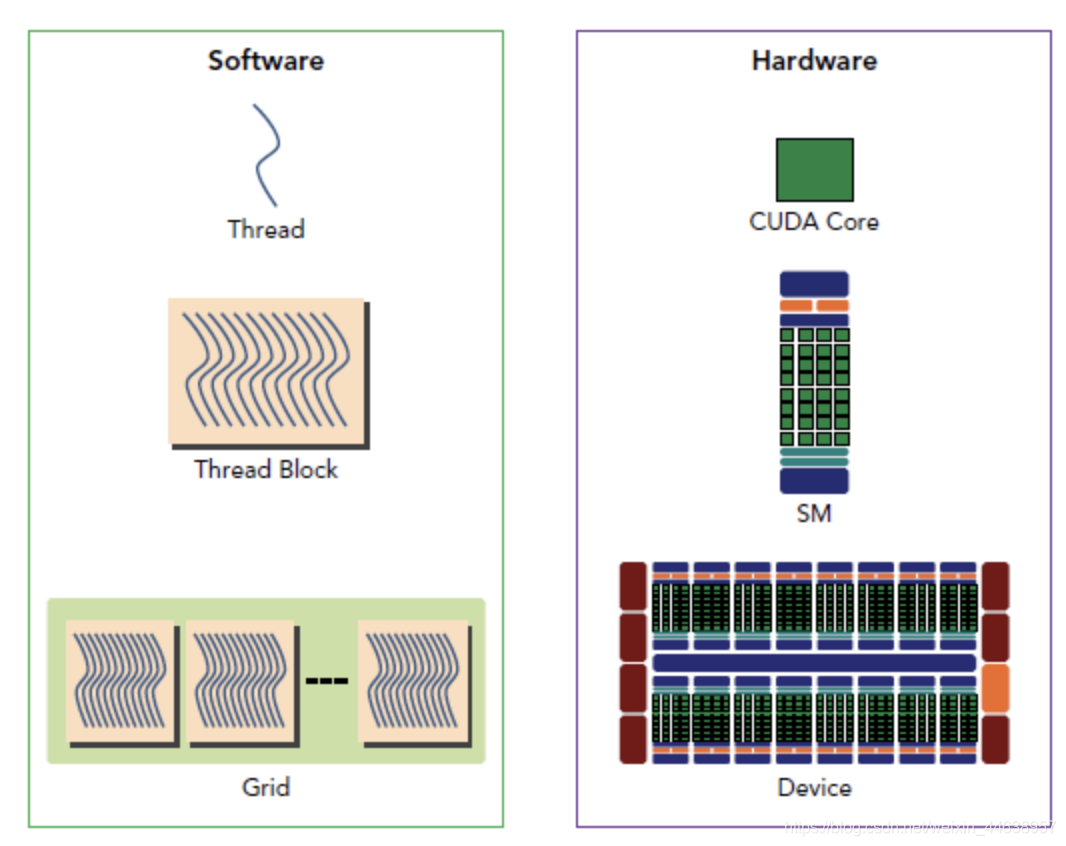
可以将软件以及硬件放在一起对比
概念在厘清一下, thread在就好比CUDA Core也就是SP(一个SP执行一个thread)
那么我们定义好的thread以及block的数量然后丢到SM中执行, 交给SM中的warp selector分配排程
可以看到一个Device(GPU)有多个SM
cuDNN
NVIDIA提供了哪些
cuDNN 是一个基于深度网路神经设计的GPU加速函数库(library), 这些函数经常用于DNN的应用
例如我们熟知的
- Convolution 卷积
- pooling 池化
- Softmax
- 激活函数(Sigmoid, ReLU …etc)
都是在DL中最常用到的数学运算, 我们不必自己写CUDA, 因为cuDNN已经写好了
cuBLAS 则是一个处理矩阵运算的函数库
能够支援多种精度(单精度, 双精度,…etc)的运算
其他还有像是支持稀疏矩阵运算的cuSPARSE 等等
我们平时使用的Framwork已经将cuDNN函数库很完美的兼容了,
nvcc
NVCC就是NVIDIA CUDA的编译器, 可以编译编写好的CUDA程序, 了解到这边就可以了
简单实践
实践之前必须有安装以下
- CUDA
- NVCC
最后还是到了编辑CUDA程序的时间, 主要用的还是以C语言为主, 毕竟用C才能有效的分配内存资源, 我个人认为C能写的好的人真的niu
所以这个部分如果要实作的话还是要有一点点C的先修知识会比较清楚, 另外特别强调一点是我会依照NVIDIA的一些官方课程最基础架构来去说, 但官方的课程是需要付费的, 一定有版权的问题, 所以我不会全部照搬内容, 这样不妥当, 重点放在能快速理解CUDA的核心知识以及编程的方式就行了
代码开始写之前先介绍一些CUDA的函数
CUDA文件的扩展名都是cu
__global__: 放在函数前面, 表示在GPU上执行的意思
GPUfunction<<<Block, thread>>>() : <<<>>>称为Execution configuration, 可自行定义要执行的Block的数量, thread就是每一个block上的thread数, 注意不是thread总数,
cudaDeviceSynchronize() :该函数将使得CPU的function等Device(GPU)上的function结束后才执行, 避免mismatch
最简单的例子
#include <stdio.h>
void CPUFunction()
{
printf("This function is defined to run on the CPU.\n");
}
__global__ void GPUFunction() //注意该function前面加上了__global__, 表示在GPU下执行
{
printf("This function is defined to run on the GPU.\n");
}
int main()
{
CPUFunction();
GPUFunction<<<1, 5>>>();//block为5, thread为5, 表示设置为 1 * 5 = 执行5次
cudaDeviceSynchronize();//在GPU function 结束后记得同步
}
nvcc进行编译
利用NVCC即可输入刚刚编写好的CUDA程序, 假设刚刚的档名为hellogpu.cu
-o 表示编译好的档名, 如果没指定就是自动生成a.out档名
-run 表示编译好之后直接运行(一样会先产生执行档)
输入以下进行编译
nvcc -o test_hello hellogpu.cu -run
输出如下
This function is defined to run on the CPU
This function is defined to run on the GPU
This function is defined to run on the GPU
This function is defined to run on the GPU
This function is defined to run on the GPU
This function is defined to run on the GPU
thread 和 block 的位置indices
CUDA的kernel function能够获取thread以及block的位置, 也就是说我们能够利用这个特性增加使用方法, 例如在for loop中有很大的帮助
threadIdx.x:表示thread线程的位置blockIdx.x:表示block的位置blockDim.x: 表示block的维度, 也就是block中有多少thread
有了这些index信息就能推算出当前thread的位置, 注意每一个thread都有自己独有的位置, 运用如下公式
threadIdx.x + blockIdx.x * blockDim.x
下图是一个gpufunction<<<2, 4>>>的图形化样子, 也就是2个block, 每个block有4个thread
上面的数字就表示位置, 比如下图红色的thread位置就是
blockIdx.x = 1, threadIdx.x = 2
blockDim.x = 4 带入上述公式就是
2 + 1 * 4 = 6
得出当前的位置在6, 从左边数过来确实属于index 6的位置(从0开始算)
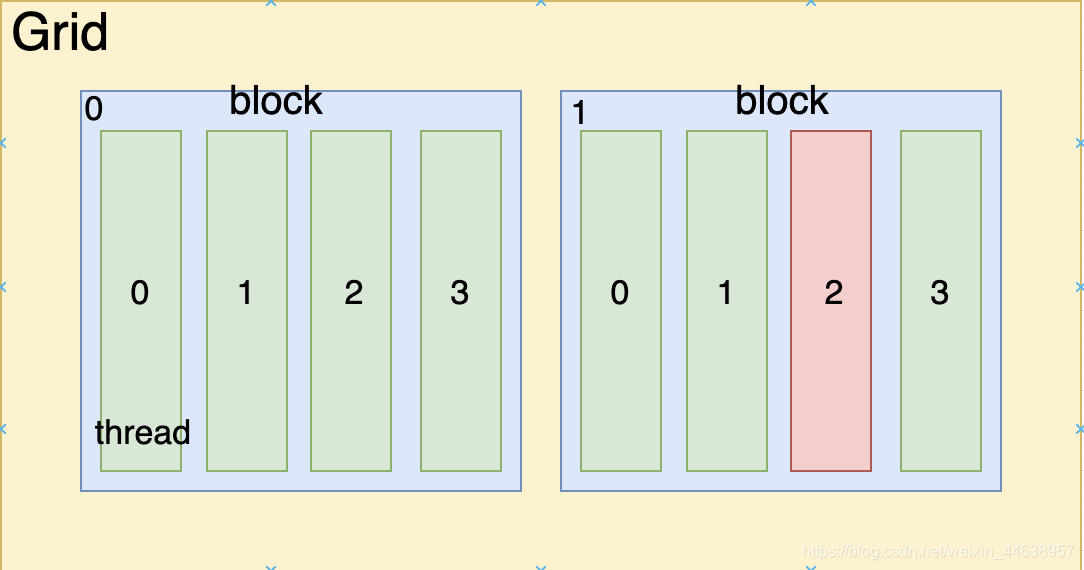
图片是自己画的, 有需要使用可以告知一下
来看个例子
#include <stdio.h>
__global__ void loop()
int dataidx = threadIdx.x + blockIdx.x * blockDim.x;
//获取每个线程的位置, 然后打印出
printf("This is iteration number %d\n",dataidx);
int main()
loop<<<2, 5>>>();//设定block = 2, thread = 5, 2*5 = 10, 所以会执行10次
cudaDeviceSynchronize();
}
编译后, output
This is iteration number 0
This is iteration number 1
This is iteration number 2
This is iteration number 3
This is iteration number 4
This is iteration number 5
This is iteration number 6
This is iteration number 7
This is iteration number 8
This is iteration number 9
解说一下, block设定为2, thread为5, 带入公式后并且赋值给dataidx
因为config设定<<<2, 5>>> 所以这个loop function将执行10次, 每一个thread在block中都会分配位置, 10次就就是0~9
分配内存的CUDA函数
下面两个函数是一定会用到的
cudaMallocManaged(src, size) : 能够为src分配size大小的内存, src为变量
cudaFree() : 释放内存
无法精准设置 execution configuration 的thread数量的情况
一种情况是任务有1000, 而thread是32的倍数为最佳(前面有说到), 1000/32 无法整除的情况, execution configuration 上无法确切的设置
解决方法有
- 编写Execution configuration,让創建的Thread数超过執行分配工作所需的Thread数
- 将值作為参数传递到Kernel function (N) 中,以表示要處理的数据总大小或完成工作所需的总Thread數。
- 计算Grid內的Thread Index, 檢查該Index是否超過任务1000,只在不超過的情況下執行與Kernel function相關的工作。
现在给个例子
假设现在的任务有1000个平行任务要执行, 一个block中的thread为256为佳且无法修正的情况下,block应该如何设置?
第一要确保所有任务都能使用上GPU,因此我们要计算出Grid中的thread index, 在thread index不超过1000的情况下执行kernel function, 另外在设定execution configuration的地方, blocks可以这样设定
(N + threads_per_block - 1) / threads_per_block;, 这样主要是为了确保至少有N个thread在grid中, 并且超出的thread数量也不会超过一个block
#include <stdio.h>
__global__ void initializeElementsTo(int initialValue, int *a, int N)
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < N) //确保index不超过数据范围才执行
{
a[i] = initialValue;
}
}
int main()
{
int N = 1000;
int *a;
int initialValue = 6;
size_t size = N * sizeof(int); ///sizeof计算int型大小
cudaMallocManaged(&a, size);
size_t threads_per_block = 256;
size_t blocks_num = (N + threads_per_block - 1) / threads_per_block;
///确保至少有N个thread在grid中, 并且超出的thread数量也不会超过一个block
initializeElementsTo<<<blocks_num, threads_num>>>(initialValue, a, N);
cudaDeviceSynchronize();
for (int i = 0; i < N; ++i) ///检查a的每个元素都有被赋值成功
{
if(a[i] != initialValue)
{
printf("FAILURE: target value: %d\t a[%d]: %d\n", initialValue, i, a[i]);
exit(1);
}
}
printf("SUCCESS!\n");
cudaFree(a); //释放内存
}
output为
SUCCESS!
线程不够用怎么办?
grid中的thread數量小於任務總數的情況, 假設任務需求為1000, 但是thread总数只有250, 则表示thread必须重用4次, 这时候需要grid-stride-loop 技巧,也就是需要计算每一次跨步的距离, 这个距离就是一次grid中thread的总数(就是250), 举例thread[0] 会去计算任务成员0, 250, 500, 750, 1000,那thread[1]就计算1, 251, 501, 751, 1001超过1000则不计算
也就是说, 每个线程负责的不只有一个任务, 透过这样的方式可以让thread线程重复利用
计算grid中thread的总数公式 = gridDim.x * blockDim.x
gridDim.x : grid中有多少个block
blockDim.x : block中有多少个thread
带入例子来说明, 重点都已经标注在代码旁边
任务为将 a 的每个元素都 double, 但情况为grid的总数少于thread(线程不够用的情况), 因为需要使用gird-stride-loop的方法
#include <stdio.h>
void init(int *a, int N)///初始化 int a
{
int i;
for (i = 0; i < N; ++i) ///每个元素值初始化跟自己的index值一样, 这不是重点
{
a[i] = i;
}
}
__global__
void doubleElements(int *a, int N) //function主要double a阵列中每个元素
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; //计算每个thread自己的位置
int stride = gridDim.x * blockDim.x;
//计算步长, 原理就是block数 * thread数 就是thread总数
for (int i = idx; i < N; i += stride)// i+=stride, 确保每一次的thread的步长都是自身thread总数的大小
{
a[i] *= 2; //执行元素double
}
}
bool checkElementsAreDoubled(int *a, int N) //该函数确认是否值都被double了
{
int i;
for (i = 0; i < N; ++i)
{
if (a[i] != i*2) return false;
}
return true;
}
int main()
{
int N = 10000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
init(a, N);
size_t threads_per_block = 256;
size_t number_of_blocks = 32;
///256 * 32 = 8192 少于10000, 所以需要是grid-stride-loop技巧
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N);
cudaDeviceSynchronize();
bool areDoubled = checkElementsAreDoubled(a, N);
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
cudaFree(a);
}
output 为
TRUE
最后看一下caffe源码中的ReLU怎么用CUDA实现的
首先看到宏定义CUDA_KERNEL_LOOP, 可以看见熟悉的公式计算每个线程自己的位置
#define CUDA_KERNEL_LOOP(i, n)
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < (n);i += blockDim.x * gridDim.x)
//步长一样是thread总数, 避免线程数不够
namespace caffe {
template <typename Dtype>
__global__ void ReLUForward(const int n, const Dtype* in, Dtype* out,
Dtype negative_slope) {
CUDA_KERNEL_LOOP(index, n) {
out[index] = in[index] > 0 ? in[index] : in[index] * negative_slope;
//逻辑运算"?", in[index] 大于0 = True 则 in[index] 否则 in[index] * negative_slope
}
}
相当于把每个元素都交给了thread带入ReLU的函数
CUDA最简入门就到这, 下一次CUDA相关的就写一下更深入的, 毕竟这次有关速度, nvprof都没写到 篇幅已经太长了
虽然CUDA不是什么特别牛的高阶语言, 很多主打AI的培训班也没有类似的课程, 但应用的邻域确实很广泛, 也不能保证未来你都没机会用到的对吧?
如果想了解更多CUDA应用的领域可以看这个官方链接NVIDIA CUDA 应用领域
reference
http://davidespataro.it/pages/Dspataro-accelleratingSCIARAfv3.html
https://graphicscardhub.com/graphics-card-technical-terms/
https://graphicscardhub.com/cuda-cores-vs-stream-processors/
https://stackoverflow.com/questions/11888772/when-to-call-cudadevicesynchronize
https://devblogs.nvidia.com/how-access-global-memory-efficiently-cuda-c-kernels/
https://blog.imalan.cn/archives/446/

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









