






浅析A星算法
A星算法主要用于求起始点到目标点的最短路径问题(此问题的前提是两点之间一定有障碍物),最短路径问题在网络通信的路由选择及导航等中有着广泛的应用。
文章目录
前言
A*算法,别称“启发式搜索”,要了解A星算法,我们应该先搞清楚欧几里得距离和曼哈顿距离。A*算法可以说是两种算法的优势和(Dijkstra with a Heurist),所以接着我们继续探究其组成——BFS算法和Dijkstra算法,这有利于我们对A*算法的理解。
一、欧几里得距离和曼哈顿距离
a.欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点(起始点到目标点)之间的真实距离,或者向量的自然长度(即该点到原点的距离)。. 在二维和三维空间中的欧氏距离就是两点之间的实际距离,可以理解为向量的模。
b.出租车几何或曼哈顿距离(Manhattan Distance)是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。
为什么叫出租车几何呢?这是因为街道纵横交错,从起始点到目标点不可能走直线到达,而是通过道路到达,这个路程值就称为曼哈顿距离(x值与y值的绝对值之和)。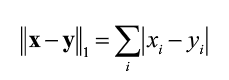
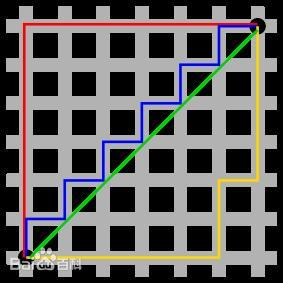
该图中绿线为欧式距离,红线为曼哈顿距离,黄蓝线为等价曼哈顿距离
曼哈顿距离是|x|值和|y|值的和,无论走什么路线,最后的计算值都是不变的,曼哈顿距离不是距离不变量,当坐标轴变动时,点间的距离就会不同,由于这只涉及加减计算,可以节约宝贵的算力,而欧几里得距离进行浮点计算,对算力的需求较大。在距离计算中,我们一般将每个方格的边长设为10,对角线的长度为14(约等于10x1.41),这样方便计算,且误差较小。

黄线:欧几里得距离
绿线:曼哈顿距离
二、算法
在讨论算法之前,我们先建立open-closed表,即一个open-list和closed-list。将open-list理解为一个容器(例如队列或是链表),这里面的每一个项都是待检查的;closed-list同理,不过这里面的每一项都是检查过的,在下一步检察中这些项都不会被检查。
2.1 Dijkstra算法
| Pros | 搜索的完整性和最佳性 |
| Cons | 只能看到到目前为止积累的成本(即统一成本),从而在每一个"方向"上探索下一个状态 ;没有关于目标位置的信息 |
Dijkstra算法从物体所在的初始点开始,访问图中的结点。它迭代检查待检查结点集中的结点,并把和该结点最靠近的尚未检查的结点加入待检查结点集(open-list)。从初始结点向四面八方扩展搜索(in all directions),直到到达目标结点。Dijsktra算法保证能找到一条从初始点到目标点的最短路径,只要所有的边都有一个非负的代价值。(上文说过方格边长一般取10)

2.2 BFS算法
最佳优先搜索(BFS)算法按照类似的流程运行,它能够评估任意点到目标点的代价,在搜索中,它会选择离目标点较近的点,也就说,如果目标点在南方向,它会倾向于导向南方的路径。
但是,由于其仅考虑到达目标点的代价,而忽略了以及花费代价,所以在某些情况下(如有障碍物)尽管路径变得很长,它仍然继续走下去。与其相似的还有DFS(深度优先算法),这里不做探讨,感兴趣的读者可以百度查询。


2.3 A*算法
A*算法(又称“启发式搜索”)于1968年发明,它是将BFS(贪心算法)和Dijsktra算法结合在一起的算法。
在正式讨论之前,我们先确定三个函数式:f(n),g(n)和h(n);得以下公式:
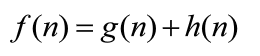
f(n)是评估函数,G值是从起始点到现在所在点m(current node)的移动代价,这是一个叠加的值,也就是说下一个节点的G值是其前继G值加上前继到该点的移动代价值;H值是从现在的方格m移动到终点 的估算成本。H值我们一般使用曼哈顿距离进行测算。这里我们要注意,G值和H值的衡量单位要保持一致,否则你可能无法得到正确的路径,而且算法也会运行的更加慢!
下面是关于三种算法的一个说明(H值与G值的关系):
- 1.如果H值=0,那么只有G值是有用的,这时A*算法也就是Dijkstra算法,它能保证可以找到一条最优路径。
- 2.如果H值总是小于(或等于)从现在节点走到目标结点的步数,那么A*算法一定可以找到最优路径. H值越小,A*扩展的结点就越多,这会导致A*算法变得越慢。
- 3.如果H值恰好等于从现在节点走到目标结点的步数,A*算法扩展的所有结点都在最优路径上,它不会扩展任何其他无关结点,此时A*算法的速度是非常快的.尽管你无法总是做到这一点,但在某 些情况下你可以使他这么运行。
- 4.如果H值所给出的信息有时大于从结点n走到目标结点的步数,那么A*算法将无法确保能够找到最优路径,但它会运行得更快。
- 5.在极端的情况下,如果H值十分接近G值,那么只有H值起作用,此时A*算法实际上变成BFS。
第一.
现确定搜索的区域,假设起始点(start node)是A点,目标点(target node)是B点,中间是一堵墙(障碍,obstacles),它们分别用绿,红,蓝色表示。障碍的意思就是该方格无法通行,黑色的方格是可通行的。路径就是方格中心点移动产生的轨迹线。

第二.
1. 从起点 A 开始,并把它就加入到一个由方格组成的 open list中。现在 open list 里只有一项,它就是起点 A ,后面会慢慢加入更多的项。 Open list 里的格子是路径可能会是沿途经过的,也有可能不经过的。
2. 查看与起点 A 相邻的方格 ( 忽略障碍所处的方格,若周围方格无障碍,则有8个相邻方格) ,把其中可走的 (walkable) 方格也加入到 open list 中。把起点 A 设置为这些方格的父节点 (parent node) 。当我们在追踪路径时,这些父节点的内容是很重要的。
3. 把 A 从 open list 中移除,加入到 close list中, close list 中的每个方格都是现在不需要再关注的,上文已经说过。
如下图所示,深绿色的方格为起点,它的外框是亮蓝色,表示该方格被加入到了 close list 。与它相邻的黑色方格是需要被检查的,他们的外框是亮绿色。每个黑方格都有一个灰色的指针指向他们的父节点,这里是起点 A 。

下一步,我们需要从 open list 中选一个与起点 A 相邻的方格,按下面描述的一样或多或少的重复前面的步骤,被选中的方格应该具有最小的F值,通过计算子节点的F,G,H,值我们得到下图:
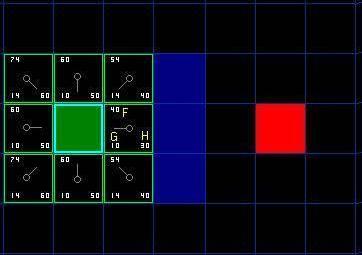
显然,正右方的方格具有最小的F值,以该点为例,我们来计算一次其三个值。该点中心到目标点的距离是3,由曼哈顿法得,|x|=30.|y|=0,则H值(曼哈顿距离)为30;G值为起始点到该点的实际距离为10,右下方的方格G值为对角线的长度14,H值相应的算出为40(有多种移动方法,但结果是一样的)。
第三.
接下来,,我们从 open list 中选择 F 值最小的 ( 方格 ) 节点,然后对所选择的方格作如下操作:
1.把它从 open list 里取出,放到 close list 中,表明它已经被检查了。
2.检查它相邻的所有方格,忽略在 close list 中或是障碍方格 ,若周围方格不在open lsit 中,将它们加入到 open list 中。同时把我们选定的F值最小的新方格(current node)设置为这些新加入的方格的父节点。
3. 如果某相邻的方格m已经在 open list 中,检查从起始点经过当前方格到达那个m方格是否具有更小的 G 值。如果有,则把那个方格m的父亲设为当前方格 (current node ) ,然后重新计算那个方格m的 F 值,G 值和H值。相反,不做任何操作。 接下来,我们以下图为例进行一个示范:

详细示范!!! 示范了一个完整的步骤:


这次,当我们检查相邻的方格时,我们发现它右边的方格是墙,忽略墙在的方格,我们把墙下面的一格也忽略掉。因若不穿越墙角的话,你无法直接从当前方格移动到那个方格。你需要先往下走,然后再移动到那个方格以来绕过墙角。 ( 注意:穿越墙角的规则是可选的,这里我们设定其不可穿过 )
这样还剩下 5 个相邻的方格。current code下面的 2 个方格还没有加入 open list ,所以把它们加入,同时把当前方格设为他们的父节点。在剩下的3 个方格中,有 2 个已经在 close list 中 ( 一个是起点,一个是当前方格上面的方格,外框被加亮的 ) ,我们忽略它们。最后一个方格,也就是当前方格左边的方格,我们检查经由当前方格到达那里是否具有更小的 G 值,没有,因此我们准备从 open list 中选择下一个待处理的方格。
不断重复这个过程,直到把终点也加入到了 open list 中,此时如下图所示:

注意观察各个图中方格的父节点和指针指向,这里我们要利用这些得出最短路径图,从终点开始,按着指针向父节点移动,当你被带回到起点时所产生的轨迹就是你的路径。如下图所示:

注:这里我们要注意父节点的问题,观察上图可知起始点下方两方格的父节点和指针指向发生了变化,原来的G是28,变化后是20,这是在获得新路径时发生的,因为G值变得不同了,所以其父节点,F和G值都要重新测定,这是一个重要的细节!
下面是A*算法的伪代码:

4.小小的改进
尽管A*算法综合了两种算法的优势,但是仍然性能较低,低性能的一个原因来自于启发函数的约束或者说不足(原文是ties)。当某些路径具有相同的f值的时候,它们都会被搜索(explored),尽管我们只需要搜索其中的一条,与Dijkstra算法相比这仍然需要大量的算力,尤其是地图较大的时候:

解决这个问题,我们可以为启发函数添加一个附加值(small tie breaker)。附加值对于结点必须是确定性的,也就是说,它不能是随机的数,而且它必须让f值体现区别。因为A*对f值排序,f值差异意味着只有一个等效的f值会被检测。下图是改进后的图像:

总结
我们总结一下A*算法的步骤:
1. 将起点加入 open list 中。
2. 重复以下过程:
a. 查看 open list ,查找 F 值最小的节点,并把它作为当前将处理的节点(current code)。
b. 把这个节点加入到 close list 中。
c. 对当前方格的 8 个相邻方格的处理:
如果它是障碍(obstacles)或者它在 close list 中,忽略它。否则,做如下操作。: 如果它不在 open list 中,把它加入 open list ,并且把当前方格设置为它的父亲,测算该方格的 F , G 和 H 值; 如果它已经在 open list 中,检查这条路径 ( 即从起始点经过当前方格到达它那里 ) 是否更好,用 G 值作参考。更小的 G 值表示这是更好的路径。如果是这样,把它的父节点设置为当前方格,同时重新计算它的 G 和 F 值。
d. 暂停,当你出现以下情况时:终点被加入到了 open list 中,此时已经找到了路径; 查找终点失败,并且 open list 是空的,此时不存在路径。
3. 保存路径。从终点开始,每个方格中心点沿着父节点(指针方向)移动直至起始点,形成的轨迹就是我们要寻找的路径。
注释:
1.图片来源于CSDN社区的主流A*算法博客,原作者是Patrick Lester,点击链接阅读原文:http://www.gamedev.net/reference/articles/article2003.asp
2.参考博客来源:
a.https://blog.csdn.net/coutamg/article/details/53923717 这是一篇译文 原作链接:http://theory.stanford.edu/~amitp/GameProgramming/ (作者Amit),讲解的很详细,读者想了解更多可以阅读他们的文章。
b.https://eveture.blog.csdn.net/article/details/89382502 这篇博客是翻译Patrick Lester的文章,笔者认为这篇翻译的相对好一些。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









