







【摘要】刚接触机器学习,记录并总结自己所学习到的知识,若有错误之处,还望指正。
模型及算法
机器学习的算法有:
(1)有监督学习∶朴素贝叶斯、线性回归、决策树、神经网络、逻辑回归、支持向量机、集成算法等。
(2)无监督学习:聚类分析、关联规则、序列模式
【注】在学习模型过程中要抓住核心所在,毕竟它是不变的。
一、朴素贝叶斯
它是应用最广泛的分类算法之一;传统贝叶斯算法是类别型的。
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 | 应用的场景 |
| 朴素贝叶斯 | 用于预测离散变量的监督学习算法 | 基于训练数据中的特征和标签之间的概率关系,通过计算后验概率来进行分类预测 | 简单易懂,易于实现和解释,适用于大多数数据集 | 对非独立特征和连续变量的处理能力较差,对异常值和噪声敏感 | 文本分类、多类别分类(处理多个离散类别及标签)、相关性特征若的分类等。 |
在此公式中,P(B|A)是A发生的情况下,B发生的概率;P(B)是B的先验概率。
二、线性回归
线性回归模型的核心是找到一条最优的直线,使得预测值与实际值之间的误差最小。
【注】不能把毫无关系的两种现象进行随意的回归分析。
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 |
| 线性回归 | 用于预测连续变量的监督学习算法 | 通过对变量之间的线性关系进行建模,来预测目标变量的值。 | 简单易懂,易于实现和解释,适用于大多数数据集 | 对非线性关系的建模能力较弱,对异常值和噪声敏感 |
(误差)似然函数:求具体的位置范围,而不是一个值。
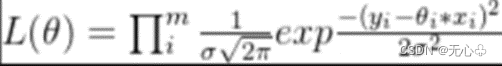
【注】在做回归分析是必须处理离群值和错误值等。否则,异常值会对方程中的系数产生较大的影响。
三、决策树
决策树模型的核心是找到一组最优的特征和阈值,使得每个子集的纯度最高。
决策树由结点和有向边组成,树中包含三种结点:(1)根结点:包含样本全集。(2)内部结点:对应于属性测试条件,恰有⼀条⼊边,两条或多条出边;(3)叶结点:对应于决策结果,恰有⼀条⼊边,但没有出边。
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 |
| 决策树 | 用于预测离散或连续变量的监督学习算法 | 数据集分成多个子集,并进行递归划分,构建树形结构 | 易于理解和解释,能够处理非线性关系和缺失值 | 容易过拟合和欠拟合,对异常值和噪声敏感 |
【注】训练数据中存在噪音或者训练数据太少,就会出现过度拟合现象。
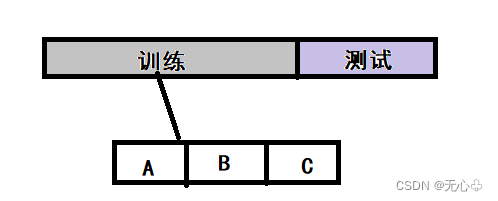
以上图为例:对训练集进行划分后,A+B--->C(用C测试)、A+C--->B、B+C--->A,显而易见最终结果为3。
ID3(处理分类问题)
ID3使用信息增益作为属性选择方法;熵是衡量一个节点不纯度的指标,熵值越大,节点所蕴涵的不确定信息就越大,节点越不纯。
【注】在数据进行中,若哪个字段带来的信息熵益最大,它就是首要选择。
C5.0
采用信息增益率来加以改进,避免了ID3算法过度配适的问题。
CART树
该算法构建二元分类回归树,即:决策树在每次分叉的时候,只能分出两支。
【注】C5.0通过计算预测错误率来剪枝、CART通过验证数据集来剪枝。
四、神经网络
BP神经网络模型将神经元分为三个层次:
输入层:负责接收外界的刺激,即外部的数据。
隐藏层:也被称为可多层,负责增加计算能力,以解决困难问题。
输出层:也被称为决策层,负责进行决策。
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 |
| 神经网络 | 用于预测离散或连续变量的监督学习算法 | 通过模拟生物神经元之间的相互作用,来构建多层神经网络,并使用反向传播算法来训练模型 | 能够处理非线性关系和高维数据,具有较高的准确性和鲁棒性 | 模型复杂度较高,需要较长的训练时间和较大的存储空间 |
##*************神经网络部分*****************##
##MLPClassifier--做分类
from sklearn.neural_network import MLPClassifier
##hidden_layer_sizes=(100) 100---隐藏层的结点数 后面不加默认为一层
##hidden_layer_sizes=(100,2)----2层
##logistic---把所有数值压缩在0~1之间 // max_iter---最大迭代次数
mlp=MLPClassifier(hidden_layer_sizes=(100,2),activation='logistic',max_iter=1000)
mlp.fit(x_train,y_train)
ypred=mlp.predict(x_test)
print(ypred)例:当遇到二分类问题时,单一节点输出。
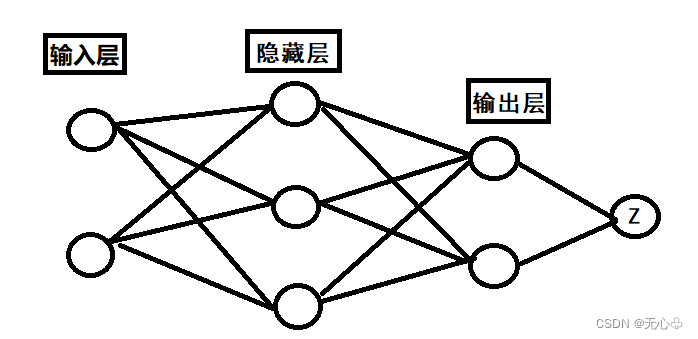
【注】总结点(Z)输出后,总结果会与实际结果有一定的误差。
当输入层和隐藏层之间随机生成a、b时,y=ax+b(a为权重值)。

【注】有几列数据设几个结点,而回归问题只有一个结点;它对数值型数据进行0和1操作,对于类别型的数据进行摊平处理。
【解读】当输出结果时,会把转化的结果(0/1)又转换回来。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









