







目录
4-1决策树基本流程
决策树模型
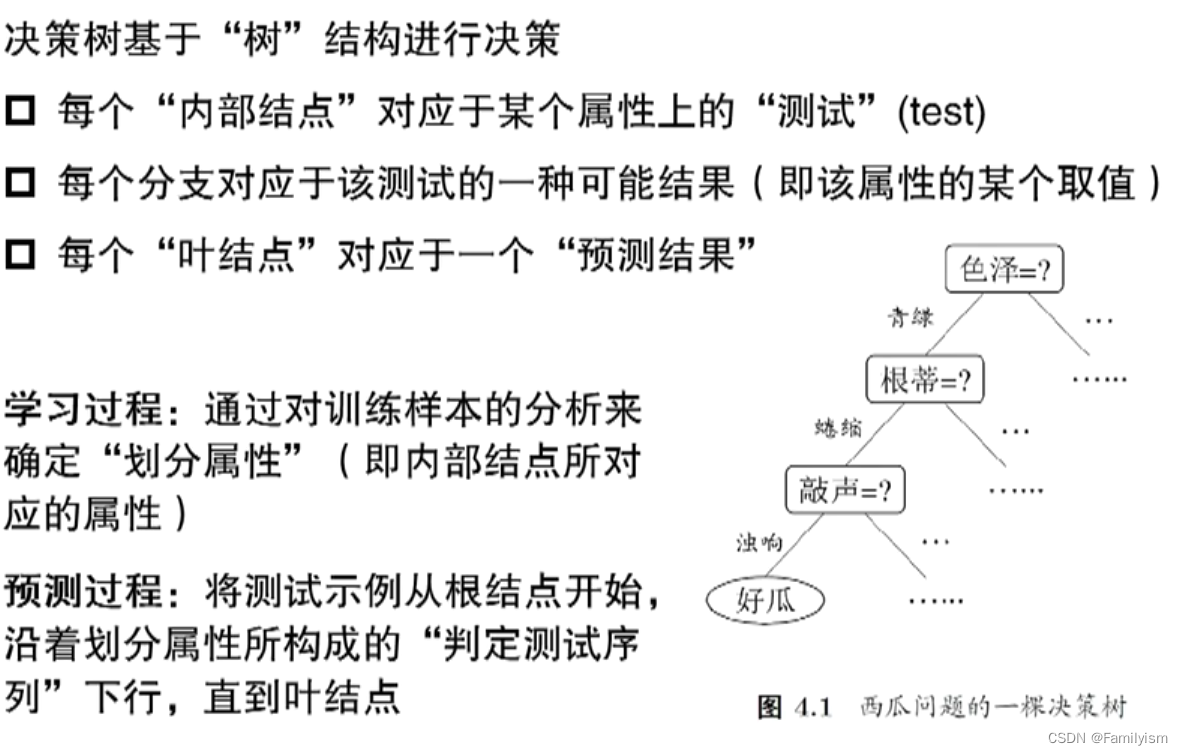
基本流程
一个典型的递归过程,策略:分而治之,自根至叶的递归过程
递归最重要的就是停止条件。
三种停止条件:
1.当前结点包含的样本完全属于同一类别,无需划分
2.当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
3.当前结点包含的样本集合为空,不能划分

基本算法

4-2信息增益划分
决策树的提出在很多程度上受到了信息论的启发,所有很多准则以信息论作为判断。
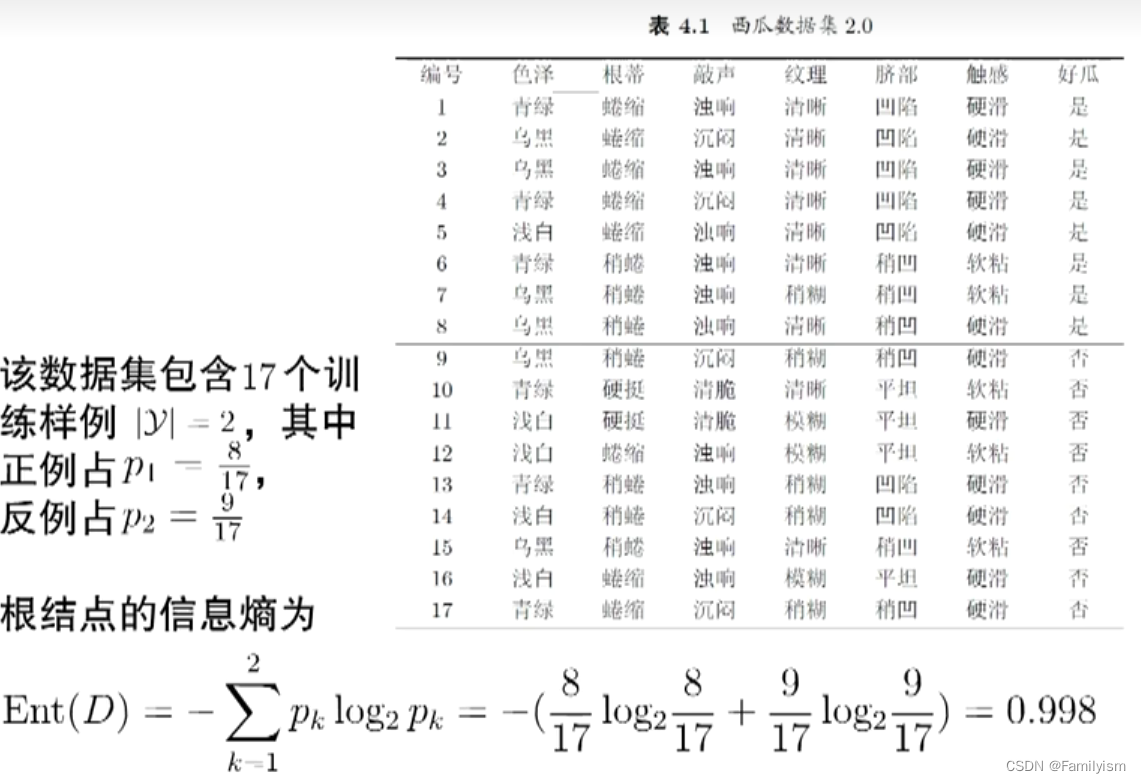
”信息熵“是度量样本集合纯度最常用的一种指标
信息增益
信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化


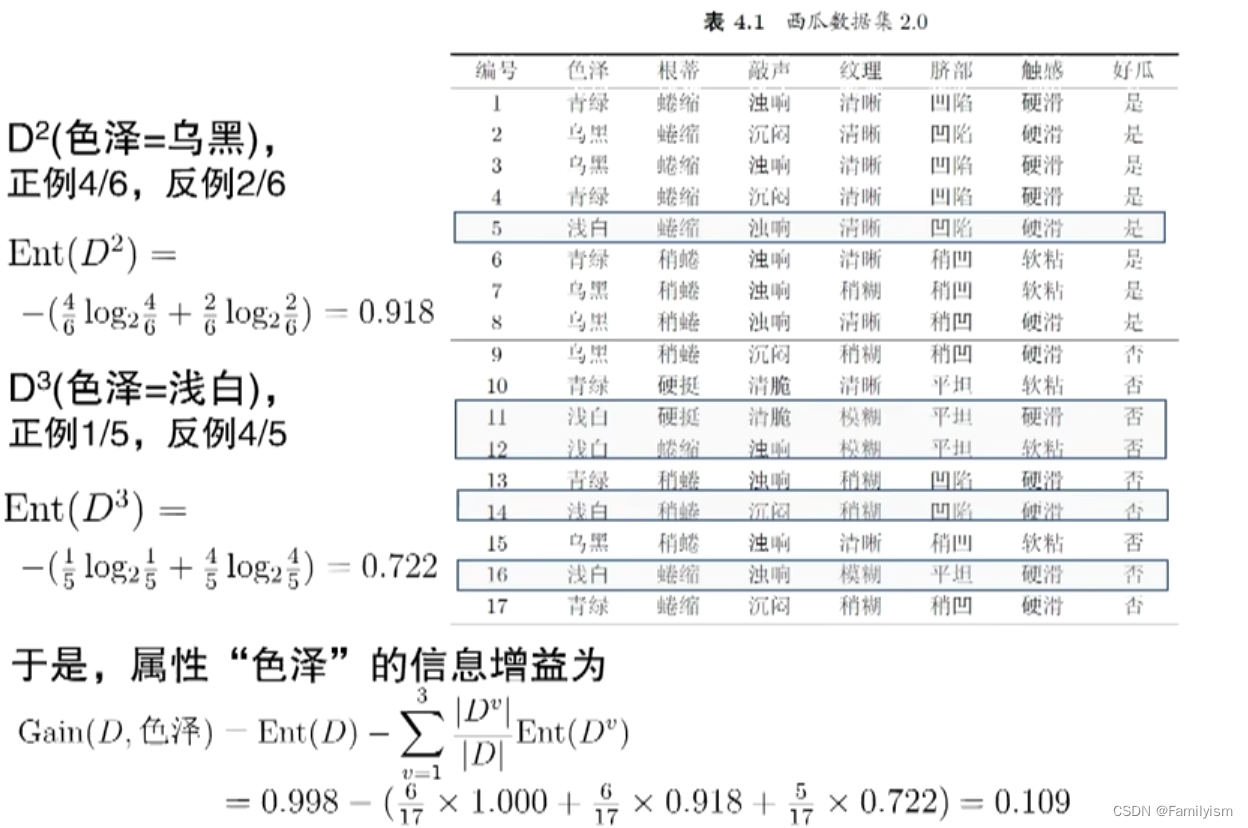
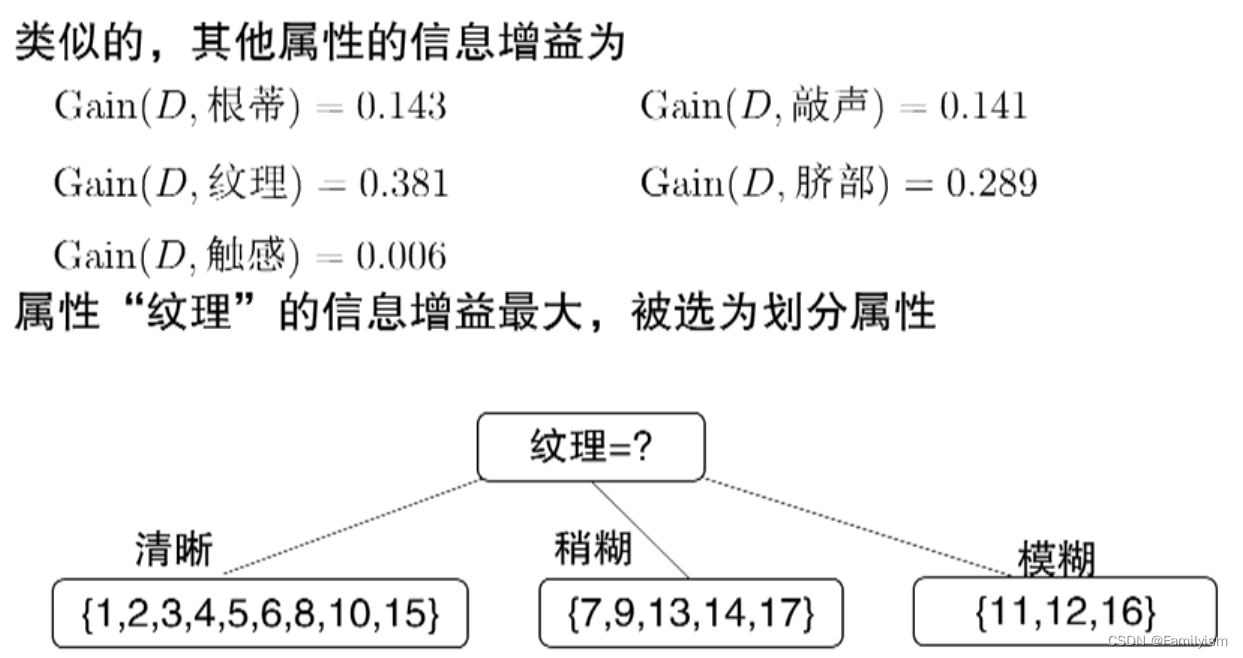
举例说明

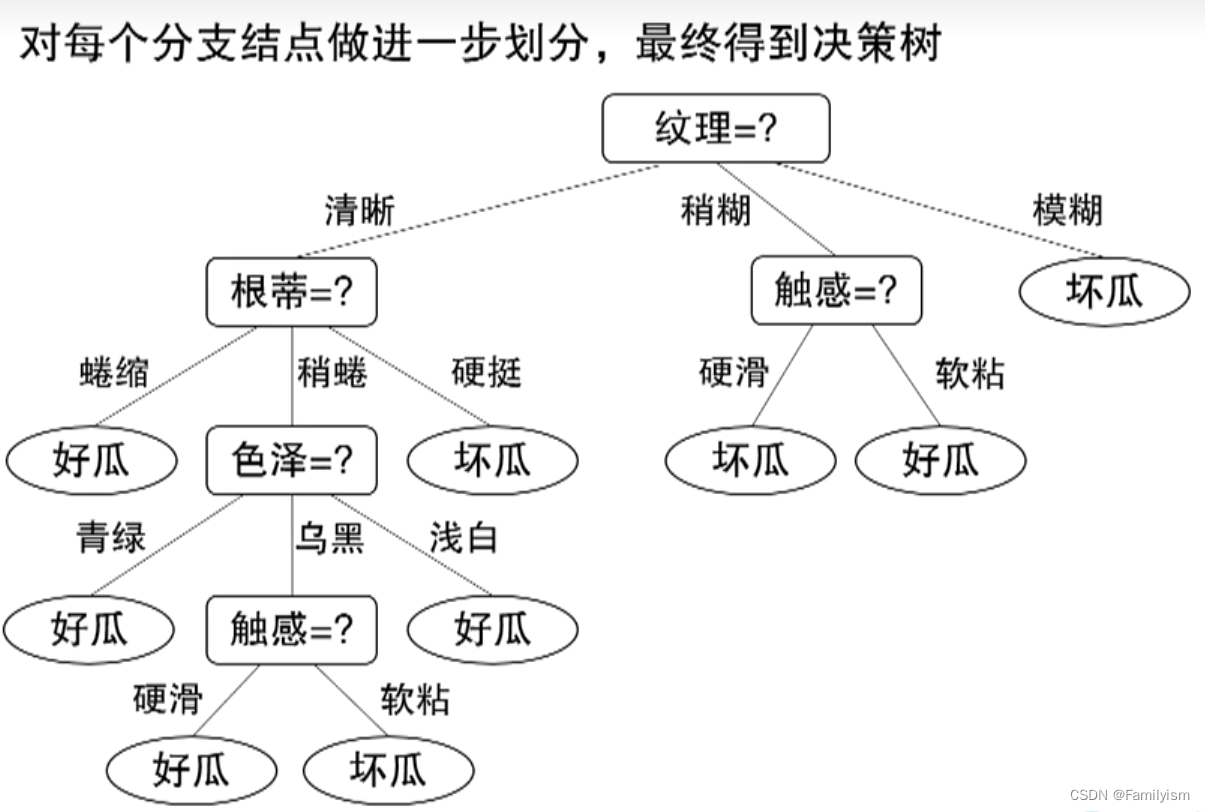
4-3其他属性划分准则
信息增益实际上是偏好于分支数目更多的分类(分类越多,越精确),其实有缺陷。提出了增益率
先找信息增益高的,再找增益率高的。C4.5决策树算法采用增益率来选择划分最优属性。

基尼指数
CART决策树采用“基尼指数”来选择划分属性
直观来说,Gini反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini越小,数据集的纯度越高

研究表明:划分选择的各种准则虽然对决策树的尺寸有较大影响,但对泛化性能的影响很有限
例如信息增益于基尼指数产生的结果,仅在约2%的情况下不同
剪枝方法和程度对决策树泛化性能的影响更为显著
在数据带噪时甚至可能将泛化性能提升25%
4-4决策树剪枝
剪枝是决策树学习算法对付“过拟合”的主要手段。决策树剪枝的基本策略有“预剪枝”和“后剪枝”。
预剪枝:在决策树生产过程中,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化程度的提升,则停止划分
后剪枝:先从训练集生成一颗完整的决策树,然后自底向上的对非叶结点进行考察,若将该结点对应的子树替换成叶结点可以为决策树带来泛化性能的提高,则将该子树替换成叶结点

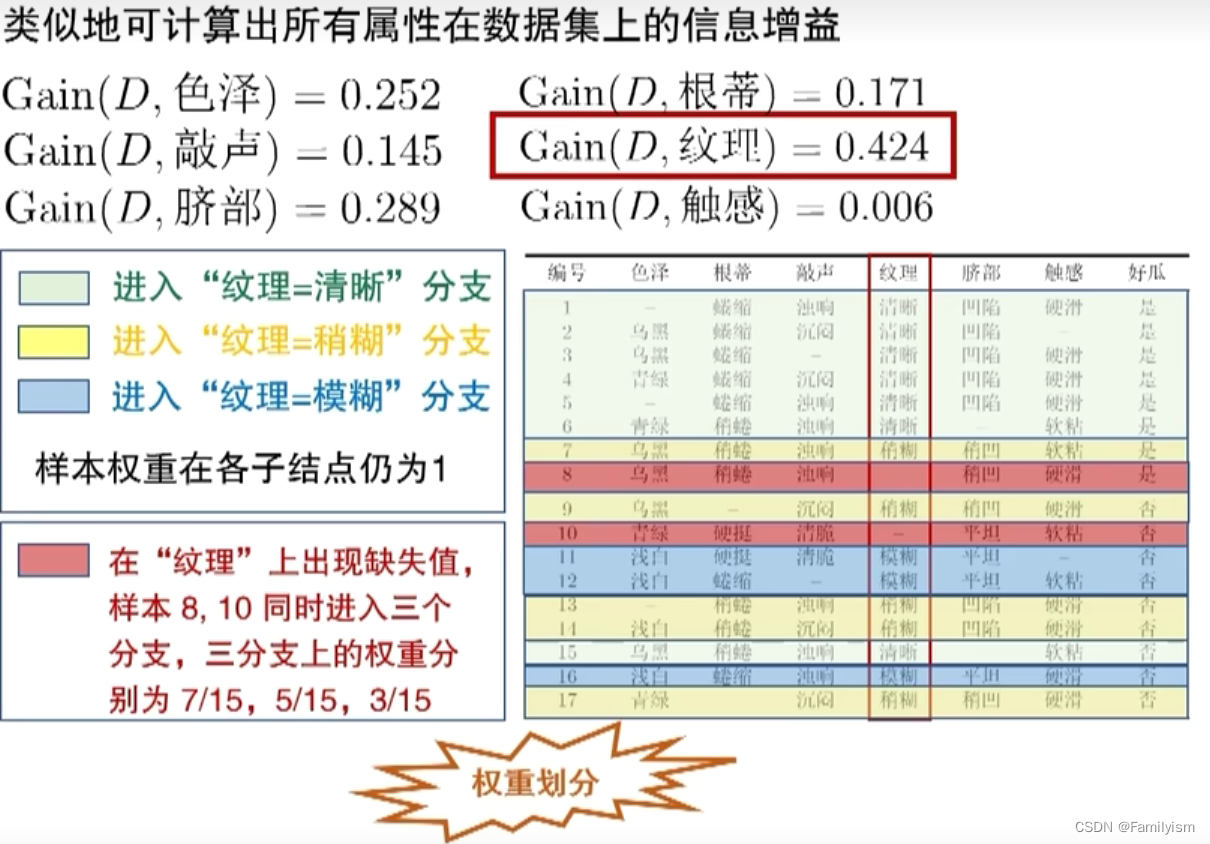
4-5缺失值处理
现实世界,经常会遇见不完整的样本

基本思路:“样本赋权,权重划分”
举例说明:


4-6代码实战
数据集

代码实战
导包
import numpy as np
import pandas as pd
import sklearn.tree as st
import math
import matplotlib
import os
import matplotlib.pyplot as plt
data = pd.read_csv('xigua.csv',header=None)
data熵
def calcEntropy(dataSet):
mD = len(dataSet)
dataLabelList = [x[-1] for x in dataSet]
dataLabelSet = set(dataLabelList)
ent = 0
for label in dataLabelSet:
mDv = dataLabelList.count(label)
prop = float(mDv) / mD
ent = ent - prop * np.math.log(prop, 2)
return ent拆分数据集
# index - 要拆分的特征的下标
# feature - 要拆分的特征
# 返回值 - dataSet中index所在特征为feature,且去掉index一列的集合
def splitDataSet(dataSet, index, feature):
splitedDataSet = []
mD = len(dataSet)
for data in dataSet:
if(data[index] == feature):
sliceTmp = data[:index]
sliceTmp.extend(data[index + 1:])
splitedDataSet.append(sliceTmp)
return splitedDataSet
选择最优特征
# 返回值 - 最好的特征的下标
def chooseBestFeature(dataSet):
entD = calcEntropy(dataSet)
mD = len(dataSet)
featureNumber = len(dataSet[0]) - 1
maxGain = -100
maxIndex = -1
for i in range(featureNumber):
entDCopy = entD
featureI = [x[i] for x in dataSet]
featureSet = set(featureI)
for feature in featureSet:
splitedDataSet = splitDataSet(dataSet, i, feature) # 拆分数据集
mDv = len(splitedDataSet)
entDCopy = entDCopy - float(mDv) / mD * calcEntropy(splitedDataSet)
if(maxIndex == -1):
maxGain = entDCopy
maxIndex = i
elif(maxGain < entDCopy):
maxGain = entDCopy
maxIndex = i
return maxIndex
寻找最多作为标签
# 返回值 - 标签
def mainLabel(labelList):
labelRec = labelList[0]
maxLabelCount = -1
labelSet = set(labelList)
for label in labelSet:
if(labelList.count(label) > maxLabelCount):
maxLabelCount = labelList.count(label)
labelRec = label
return labelRec
生成树
def createFullDecisionTree(dataSet, featureNames, featureNamesSet, labelListParent):
labelList = [x[-1] for x in dataSet]
if(len(dataSet) == 0):
return mainLabel(labelListParent)
elif(len(dataSet[0]) == 1): #没有可划分的属性了
return mainLabel(labelList) #选出最多的label作为该数据集的标签
elif(labelList.count(labelList[0]) == len(labelList)): # 全部都属于同一个Label
return labelList[0]
bestFeatureIndex = chooseBestFeature(dataSet)
bestFeatureName = featureNames.pop(bestFeatureIndex)
myTree = {bestFeatureName: {}}
featureList = featureNamesSet.pop(bestFeatureIndex)
featureSet = set(featureList)
for feature in featureSet:
featureNamesNext = featureNames[:]
featureNamesSetNext = featureNamesSet[:][:]
splitedDataSet = splitDataSet(dataSet, bestFeatureIndex, feature)
myTree[bestFeatureName][feature] = createFullDecisionTree(splitedDataSet, featureNamesNext, featureNamesSetNext, labelList)
return myTree
初始化
# 返回值
# dataSet 数据集
# featureNames 标签
# featureNamesSet 列标签
def readWatermelonDataSet():
dataSet = data.values.tolist()
featureNames =['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
#获取featureNamesSet
featureNamesSet = []
for i in range(len(dataSet[0]) - 1):
col = [x[i] for x in dataSet]
colSet = set(col)
featureNamesSet.append(list(colSet))
return dataSet, featureNames, featureNamesSet
画图
# 能够显示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.serif'] = ['SimHei']
# 分叉节点,也就是决策节点
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
# 叶子节点
leafNode = dict(boxstyle="round4", fc="0.8")
# 箭头样式
arrow_args = dict(arrowstyle="<-")
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
"""
绘制一个节点
:param nodeTxt: 描述该节点的文本信息
:param centerPt: 文本的坐标
:param parentPt: 点的坐标,这里也是指父节点的坐标
:param nodeType: 节点类型,分为叶子节点和决策节点
:return:
"""
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def getNumLeafs(myTree):
"""
获取叶节点的数目
:param myTree:
:return:
"""
# 统计叶子节点的总数
numLeafs = 0
# 得到当前第一个key,也就是根节点
firstStr = list(myTree.keys())[0]
# 得到第一个key对应的内容
secondDict = myTree[firstStr]
# 递归遍历叶子节点
for key in secondDict.keys():
# 如果key对应的是一个字典,就递归调用
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
# 不是的话,说明此时是一个叶子节点
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
"""
得到数的深度层数
:param myTree:
:return:
"""
# 用来保存最大层数
maxDepth = 0
# 得到根节点
firstStr = list(myTree.keys())[0]
# 得到key对应的内容
secondDic = myTree[firstStr]
# 遍历所有子节点
for key in secondDic.keys():
# 如果该节点是字典,就递归调用
if type(secondDic[key]).__name__ == 'dict':
# 子节点的深度加1
thisDepth = 1 + getTreeDepth(secondDic[key])
# 说明此时是叶子节点
else:
thisDepth = 1
# 替换最大层数
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotMidText(cntrPt, parentPt, txtString):
"""
计算出父节点和子节点的中间位置,填充信息
:param cntrPt: 子节点坐标
:param parentPt: 父节点坐标
:param txtString: 填充的文本信息
:return:
"""
# 计算x轴的中间位置
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
# 计算y轴的中间位置
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
# 进行绘制
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt):
"""
绘制出树的所有节点,递归绘制
:param myTree: 树
:param parentPt: 父节点的坐标
:param nodeTxt: 节点的文本信息
:return:
"""
# 计算叶子节点数
numLeafs = getNumLeafs(myTree=myTree)
# 计算树的深度
depth = getTreeDepth(myTree=myTree)
# 得到根节点的信息内容
firstStr = list(myTree.keys())[0]
# 计算出当前根节点在所有子节点的中间坐标,也就是当前x轴的偏移量加上计算出来的根节点的中心位置作为x轴(比如说第一次:初始的x偏移量为:-1/2W,计算出来的根节点中心位置为:(1+W)/2W,相加得到:1/2),当前y轴偏移量作为y轴
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
# 绘制该节点与父节点的联系
plotMidText(cntrPt, parentPt, nodeTxt)
# 绘制该节点
plotNode(firstStr, cntrPt, parentPt, decisionNode)
# 得到当前根节点对应的子树
secondDict = myTree[firstStr]
# 计算出新的y轴偏移量,向下移动1/D,也就是下一层的绘制y轴
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
# 循环遍历所有的key
for key in secondDict.keys():
# 如果当前的key是字典的话,代表还有子树,则递归遍历
if isinstance(secondDict[key], dict):
plotTree(secondDict[key], cntrPt, str(key))
else:
# 计算新的x轴偏移量,也就是下个叶子绘制的x轴坐标向右移动了1/W
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
# 打开注释可以观察叶子节点的坐标变化
# print((plotTree.xOff, plotTree.yOff), secondDict[key])
# 绘制叶子节点
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
# 绘制叶子节点和父节点的中间连线内容
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
# 返回递归之前,需要将y轴的偏移量增加,向上移动1/D,也就是返回去绘制上一层的y轴
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree):
"""
需要绘制的决策树
:param inTree: 决策树字典
:return:
"""
# 创建一个图像
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
# 计算出决策树的总宽度
plotTree.totalW = float(getNumLeafs(inTree))
# 计算出决策树的总深度
plotTree.totalD = float(getTreeDepth(inTree))
# 初始的x轴偏移量,也就是-1/2W,每次向右移动1/W,也就是第一个叶子节点绘制的x坐标为:1/2W,第二个:3/2W,第三个:5/2W,最后一个:(W-1)/2W
plotTree.xOff = -0.5/plotTree.totalW
# 初始的y轴偏移量,每次向下或者向上移动1/D
plotTree.yOff = 1.0
# 调用函数进行绘制节点图像
plotTree(inTree, (0.5, 1.0), '')
# 绘制
plt.show()
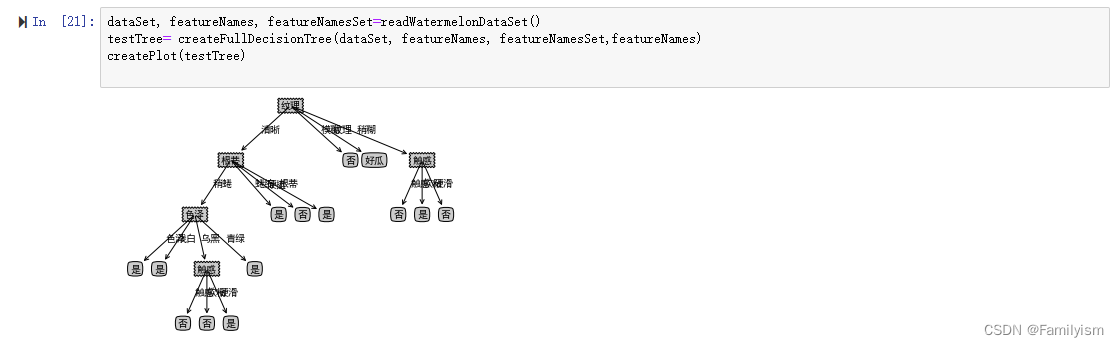
结果















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









