






目录
什么是随机种子&设置随机种子的作用 (2023/04/11)
关于随机种子
什么是随机种子&设置随机种子的作用 (2023/04/11)
我的理解:
- 简略版:随机种子就是一个数,固定这个数值可以让随机数生成器产生的初始化随机数是相同的。
- 复杂版:我们在训练网络时,网络里面定义的权重参数会先初始化为一个随机数,然后再经过训练不断更新。一个很大的问题是,权重参数的初始值会在一定程度上影响模型最后的收敛结果,因此使用不同的初始化参数,最后得到的结果差别可能会较大。但固定权重参数的初始值可以很大程度上使实验结果可以复现,而设置随机种子的目的就是让权重参数能初始化为同一个数。
注:这里使用“很大程度”是因为固定权重参数初始值并不能保证实验结果就一定可以复现。其他因素,如:服务器的不同,也可能导致结果不同。(但以我目前少许的经验来看,固定权重参数的初始值可以解决我大部分的实验结果可复现性问题)
官方版:
坑
1.不设置随机种子
不设置随机种子对很多模型来讲实验结果是真的无法复现。我最开始接触深度学习的时候根本不知道随机种子,当时的模型比较稳健,随机数对结果的影响较小,每次跑出的结果差别不大,所以我很长时间没有意识到这个问题。直到我遇到了不那么稳健的模型(我自己搭的)……
2.设置随机种子的方式不对
当我意识到随机种子的必要性时,我就在自己的模型中设置了随机种子。以下是相关代码
# packages need to be imported
import random
import numpy as np
import torch
# define setting function
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
# set random seed
setup_seed(3407) # the number 3407 can be any other value you like以上的代码应该可以涵盖到所有需要生成随机数的地方。但是,把放它错位置仍然会导致你模型中的初始化随机数没有固定。
踩坑场景再现:把setup_seed()放在训练文件的主函数开头
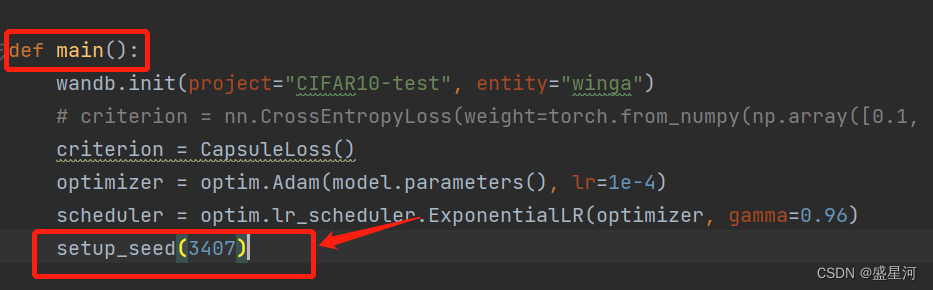
分析:setup_seed()的作用域在添加这个函数的后面,而我的网络模型是在开头import packages时就已经引入了,因此setup_seed()函数根本作用不到我的模型,即我的模型中的初始化随机数并没有被固定。
解决方式:直接将函数放在导入模型(准确来说是涉及到生成随机数的代码)前面。我的操作方式如下图
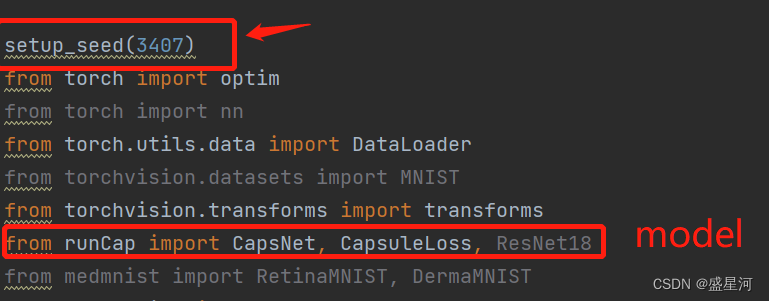
若有不妥之处,望不吝赐教:D

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









