






在深度学习中,随机数种子是用来初始化随机数生成器的值。有了随机数种子,可以更好的重复试验以及控制模型训练的随机性。
设置相同的随机数种子能够使得随机数生成器生成的随机序列变得可重复。这对于实验的可重复性非常重要,因为在相同的随机初始化下,模型的训练过程、性能评估等都能够在不同运行中得到相同的结果。这有助于调试和验证模型,确保实验结果的一致性。同时,深度学习中的一些步骤,比如权重初始化、数据集划分、数据增强等,通常涉及到随机性。通过设置相同的种子,可以确保这些步骤在不同运行中产生相同的随机结果,从而更好地理解和控制模型的行为。

但是,不同的随机数种子可以导致模型的初始化、数据集划分、权重更新等过程中产生不同的随机性,从而对模型的训练和性能产生影响。
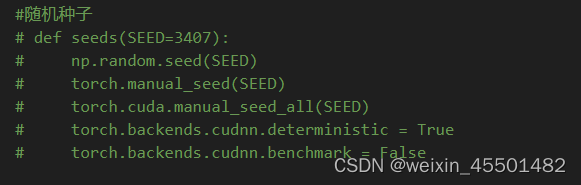
而随机数的选取又毫无规律,很难找到一个适合于自己模型的随机数种子。在网上查阅很久后看到了一篇文章推荐了一个随机数种子,文章题目为“torch.manual seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision”,这个随机数种子是作者多次试验后得出的,在文中作者也提出了实验的缺陷,但这个随机数种子大家还是可以借鉴一下。原文是英文,如果不想看英文,可以看看这篇公众号文章“微信公众平台 (qq.com)”。

















 2616
2616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









