






安装
(1)Pytorch安装 (自行官网安装对应cuda版本)
(2)下载最新yolov8_obb代码:
GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
pip安装和gitclone均可
(3)安装依赖
官方给出:
也可尝试:pip install -e .
DOTA数据集的训练、测试、推理
(1)快速入门(测试环境)
使用dota8数据集用于测试:创建新py文件,复制下面代码运行(代码会自动帮你安装pt文件和dota8数据集,如果下载太慢导致失败,可根据失败信息自行下载)
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-obb.pt') # load a pretrained model (recommended for training)
# Train the model
results = model.train(data='dota8.yaml', epochs=100, imgsz=640)参考:DOTA8 -Ultralytics YOLOv8 文档
通过快速入门,可以了解项目的文件结构和数据集构架
(2)数据集处理
①将DOTA数据集转换为yolov8可训练的格式
原数据集格式如下:

v8使用的数据集格式:

关于数据集转换,官方已经写好了代码:
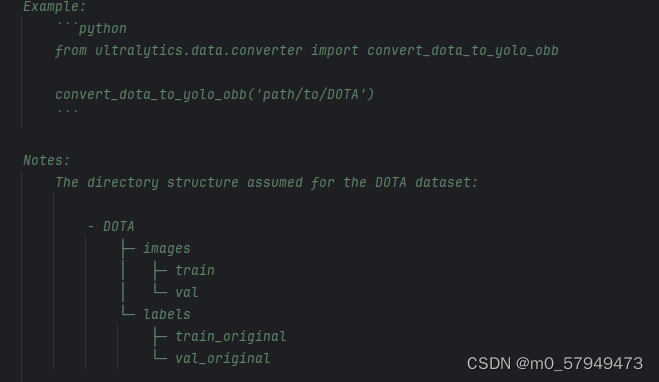
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb('path/to/DOTA')新建一个py文件,可以把路径改为指向DOTA文件夹的绝对路径,文件夹目录结构如下:
②数据集图像裁剪
方法一:使用已经裁剪好的DOTA数据集然后使用①转化格式,或者使用DOTA数据集提供的toolkit
方法二:利用ultralytics\ultralytics\data\split_dota.py,该Py文件提供了分割函数,使用如下:
from ultralytics.data.split_dota import split_trainval
split_trainval(data_root=r'datasets\DOTA',save_dir=r'datasets\DOTA_split')备注 :尝试了方法二,发现裁剪后的图片数量和标签数量对应不上,各位看官可自行尝试
(3)开始训练
①下载预训练权重
②确定数据集
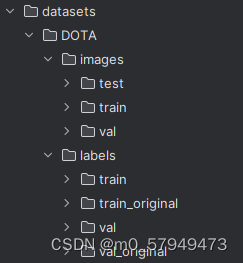
③在cfg/datasets中创建DOTAv1-obb.yaml,修改路径和类别(如果使用项目自带的跳过该步骤)
④修改并使用cfg/models/v8/yolov8-obb.yaml
根据自己的DOTAv1-obb.yaml修改nc
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 Oriented Bounding Boxes (OBB) model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 15 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, OBB, [nc, 1]] # OBB(P3, P4, P5)⑤新建train.py ,复制如下代码:
from ultralytics import YOLO
model = YOLO('yolov8n-obb.yaml').load('yolov8n-obb.pt')
model.train(data='DOTAv1.yaml', epochs=100, imgsz=1024, batch=4, workers=4)命令运行:CUDA_VISIBLE_DEVICES=gpu_ids python train.py
(4)验证
from ultralytics import YOLO
def main():
model = YOLO(r'runs/obb/train/weights/best.pt')
model.val(data='dotav1.yaml', imgsz=1024, batch=4, workers=4)
if __name__ == '__main__':
main()(5)推理
from ultralytics import YOLO
model = YOLO('runs/obb/train/weights/best.pt')
results = model('datasets/DOTA/images/val/P0003__1__0___0.png', save=True)训练HRSC2016数据集
关于HRSC数据集解读:HRSC数据集解读,DOTA数据集转YOLO旋转框格式,HRSC数据集转YOLO旋转框格式_dota数据集 yolo格式-CSDN博客
HRSC数据集转YOLO旋转框代码地址:GitHub - yrpyyds/HRSC2DOTA2YOLO: HRSC数据集转DOTA转YOLO v8,以及对应的显示标注框的简易UI
注:代码简单可以自行阅读,帮作者写个readme:先使用HRSC_to_DOTA->DOTA_to_YOLO,每个阶段均可使用drawed.py验证转化是否成功
问题:HRSC数据集经过整理后,Train文件夹下有效标注的数据集为617张(其中train=436,val=181),Test文件夹下有效标注集为438张(6张背景图)。
数据集分为三个层级,0级为船,1级是航母、军舰、商船、潜艇,2级为各种航母,军舰细分。
由于船舰类型丰富、每个类型数据量较小、类别区分没有明确界限,因此大部分处理方式(上述代码链接)均将HRSC三级类别归到二级类别且将一级类别的ship删去。但这种删去同样带来了一些问题,它将很多分类结果为ship的图片变成了背景图。例如,一张图片它只有一个框 其注释为ship=1,现在我们删除ship导致其注释txt文件变成了空文件,图片并没有删除,而且变成了背景图;那么我们能不能直接删掉这种图片呢?答案是否定的,因为如果一张图片中既有我们要的类别也有ship的话,删除整张图片也会删除我们想要的。
解决方式可以自行决定
后续训练过程同DOTA数据集训练过程,只需要修改dataset.yaml,以及修改Yolov8obb.yaml中的nc即可

更换yolo的backbone和neck
待更新














 8164
8164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









