







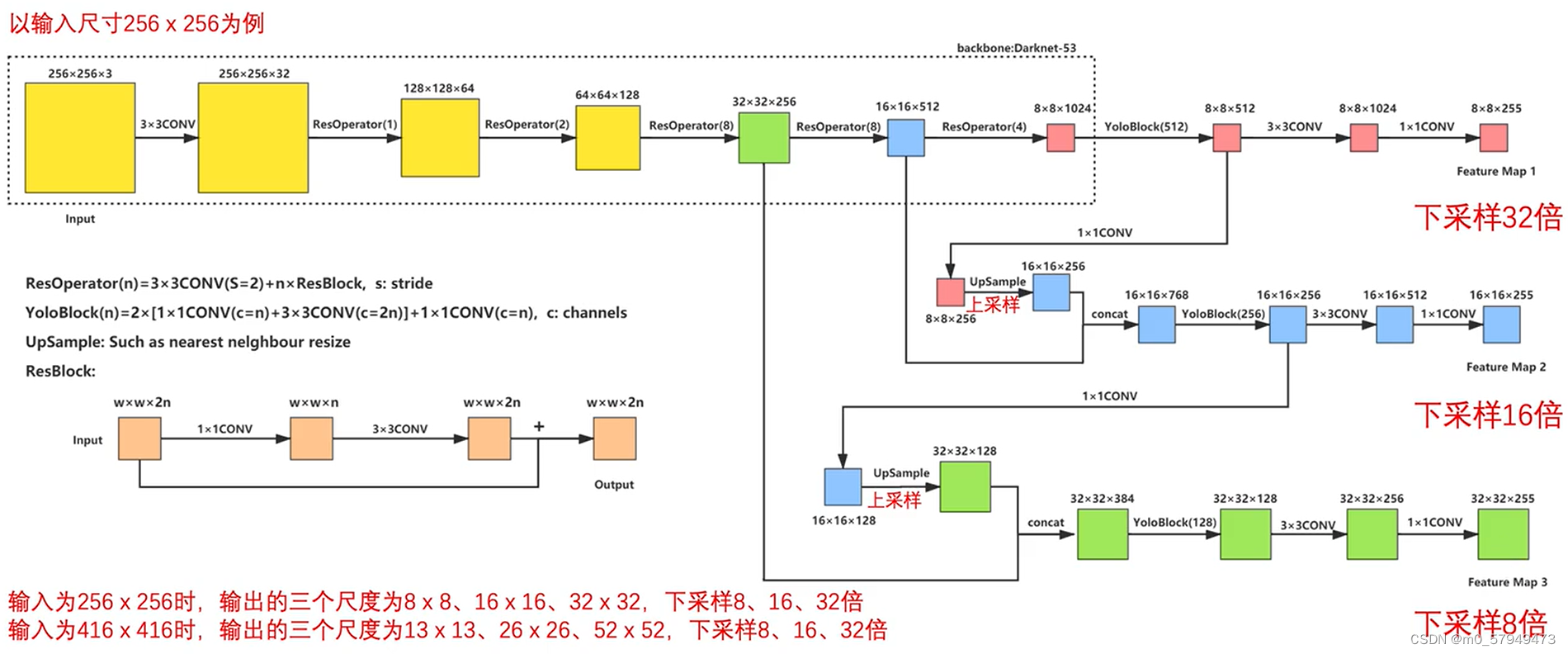
上图为YOLOv3的骨干网络backbone(darknet)很明显采用了多尺度目标检测。255=3*85,其中3代表每个grid cell生成3个anchor,85=5+80,5是每个anchor的位置参数xywhc,80是类别。
c:置信度,可以理解为anchor中有物体的概率 而80是条件类别概率 可以理解为anchor中存在物体后各个类别可能的概率,因此在判断预测框类别的时候需要用c乘条件类别概率。在Yolov1中xywh是直接给出了预测框位置,而对于v2 v3来说预测框是根据anchor偏移得到的,因此得到的是tx ty tw th


关于此网络,416*416图像下采样32倍得到13*13 感受野为32,因此用于检测大目标,同理26与52。既发挥了深层网络的语义抽象的特征,也充分浅层网络的细腻度的像素级别的边缘转角和结构信息的底层特征,因此实现多尺度特征融合和不同尺度物体预测
根据这样多尺度融合和不同尺寸预测的方式,得到的anchor数量相比v1 v2也大大增加,这也是其为什么能检测小目标和密集目标
回顾:
正样本:与ground truth的交并比iou最大的预测框
负样本:与ground truth的交并比iou小于阈值的预测框
(与ground truth的交并比iou大于阈值但不是最大的预测框为不参与)


代码不过多记忆,v1~v3相对都比较老了仅用于学习其思想和优缺点,方便学习后续的v5 v7 v8,后续较新的版本代码做的更好再学习















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









