






1、定义
爬虫是一种自动化程序,可以模拟人类的行为,从互联网上抓取大量的数据。它可以在一定时间内抓取数百万个网页,并将这些数据存储在本地或云端数据库中,以便后续处理和分析。
简单来说就是:通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
2、爬虫的工作原理
爬虫的工作原理是通过HTTP请求来获取网页的源代码,然后解析HTML文档,提取出需要的数据。爬虫可以通过正则表达式、XPath或CSS选择器来获取数据。获取数据后,爬虫可以将数据存储在本地或云端数据库中,以便后续处理和分析。
3、爬虫的分类
根据爬虫的使用场景和目的,可以将爬虫分为以下几类:
(1)通用爬虫:通过用于搜索引擎,可以抓取互联网上的所有网页。
(2)聚焦爬虫:用于特定领域的数据抓取,例如:新闻、论坛、电商等。
(3)增量爬虫:用于定期更新已有数据,例如:新闻、股票等。
(4)深度爬虫:用于获取网页中的所有链接和数据,例如:社交网站、论坛等。
4、爬虫的应用
爬虫的应用很广泛,涉及各个领域,例如:
(1)搜索引擎:搜索引擎通过爬虫抓取互联网上的网页,并将这些网页存储在自己的数据库。
(2)数据挖掘:爬虫可以从电商网站、社交网络等平台上获取用户数据、商品信息等。
(3)舆情分析:爬虫可以从新闻网站、微博、论坛等平台上获取用户评论、舆情信息等。
(4)金融分析:爬虫可以从股票交易平台、财经网站等平台上获取股票、财经数据等。
5、反爬机制
门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取
6、反反爬策略
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站的
7、爬虫注意事项
使用爬虫时需要注意以下事项:
(1)尊重网站的Robots.txt协议:Robots.txt协议是网站所有者用来告诉爬虫哪些页面可以被爬虫爬取的协议。规定了网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取。
查看方法:
例如查看豆瓣网的robots协议,在网站域名后面加/robots.txt:
https://www.douban.com/robots.txt

(2)尊守法律法规:在爬取数据时,需要遵守相关的法律法规,不得侵犯他人的合法权益。
(3)控制抓取速度:过快的抓取速度可能会对网站造成负担,甚至会被网站封禁。
(4)数据处理和存储:在获取数据后,需要对数据进行处理和存储,以后后续的分析和使用。
8、http&https协议
(1)概念:就是服务器和客户端进行数据交互的一种形式。
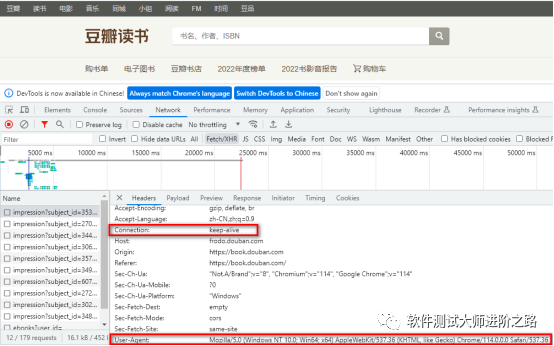
(2)常用请求信息:重点关注如下参数信息
User-Agent:请求载体的身份标识
Connection:请求完毕后,是断开连接还是保持连接
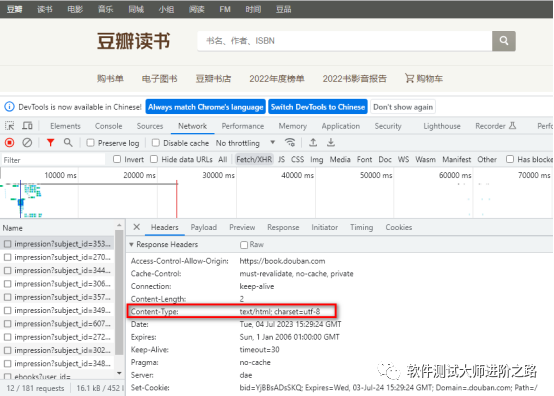
(3)常用响应信息:
Content-Type:服务器响应回客户端的数据类型
(4)https协议:安全的超文本传输协议
(5)加密方式:常见的3种加密方式
1)对称秘钥加密
2)非对称秘钥加密
3)证书秘钥加密(例如:https)
本章总结
爬虫是一种强大的工具,可以帮助我们从互联网上获取大量的数据。但在使用爬虫时,需要遵守相关的法律法规和网站的Robots.txt协议,以控制抓取速度,并对数据进行处理和存储分析。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









