






关于爬虫
对于生物信息来说,爬虫并没有太大的用处,只是偶尔用得到(比如爬KEGG,自动化查询NCBI等等);对于数据分析来说,爬虫重要性增加了很多,毕竟很多数据来源很复杂。
简单讲点python爬虫吧,实用为主。
检查robots.txt
Robots协议也称作爬虫协议(网络爬虫排除标准,Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取。robots.txt文件一般放在网站的根目录下。
User-agent: *
Disallow: /
Allow: /public/看看就明白哪些允许爬了,如果网站没有,那就随便吧。看这个的目的就是防止法律风险,当然也有打擦边球的。。。
爬虫学习路径
总结一下学习路径:
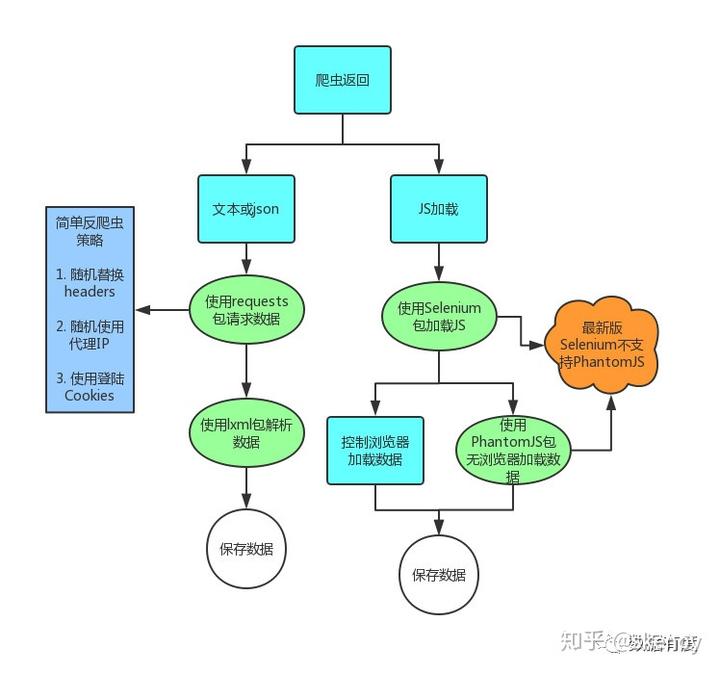
- 据说pyppeteer可以替代Selenium+PhantomJS组合。
- 左侧路径有框架
Scrapy,不过基本请求和解析方法没有变化,百万级爬虫请使用框架吧,但对于生物信息分析来说基本用不到,数据分析大多数情况也很难用到。 - 我找了一些header仅供参考,详见github下instance/spider/header.txt
- 代理IP,这个网站不错: https://www.xicidaili.com/nn
- 反爬虫策略使用方法:
# F12检查浏览器中的cookie内容
header = {
'user-agent': 'XXX',
'cookie': 'XXX'}
}
requests.get("https://name", headers=header, proxies={'http': 'XXX:OOO'})还有什么没考虑到
再详细点就是requests的post和session等等,另外就是多线程和异步处理加速运行;目的不同,学习程度也不同,只要一段时间内适合自己即可。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









