






3种使用方法,分别对应开始处理123。方法一和方法二需先自己对pdf进行一些处理,但是速度快,多次重复归档也方便,基本上一千多页只要一两分钟。最推荐方法二。
方法三操作最少,pdf扫描件直接就可以处理了,但是这个会调用paddleocr,每页都得弄一二十秒,重复归档的话,每次得重新识别。这个确实是操作最少的。其实用多线程识别的话,速度会快一些,但有时会出错,就没用多线程。
下面是方法3的使用过程。
程序很粗犷,解压要10分钟,耐心等待。
资源
通过网盘分享的文件:归档程序1.2.zip
链接: https://pan.baidu.com/s/1KnEgEXb7qLNNgavHCvn-Sw?pwd=1111 提取码: 1111
效果
查看自己指定的归档的文件夹,文件都重命名在里面的,可以自动拆页的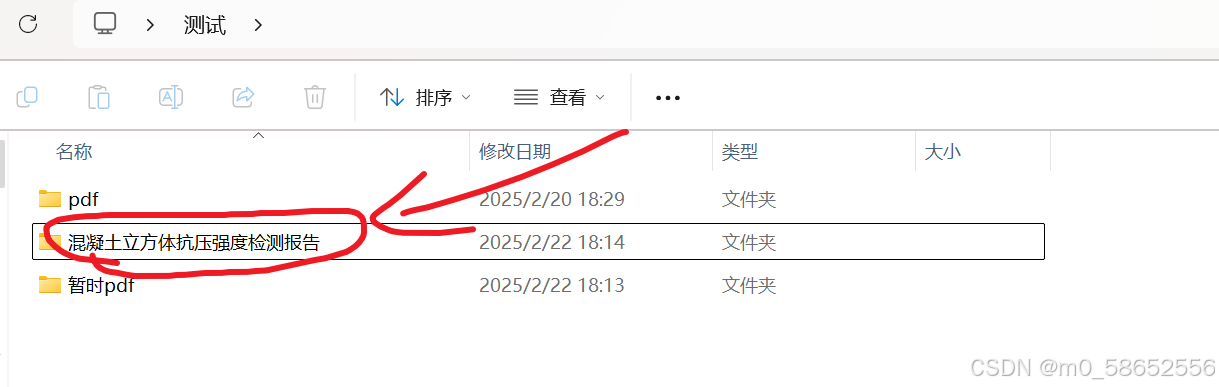
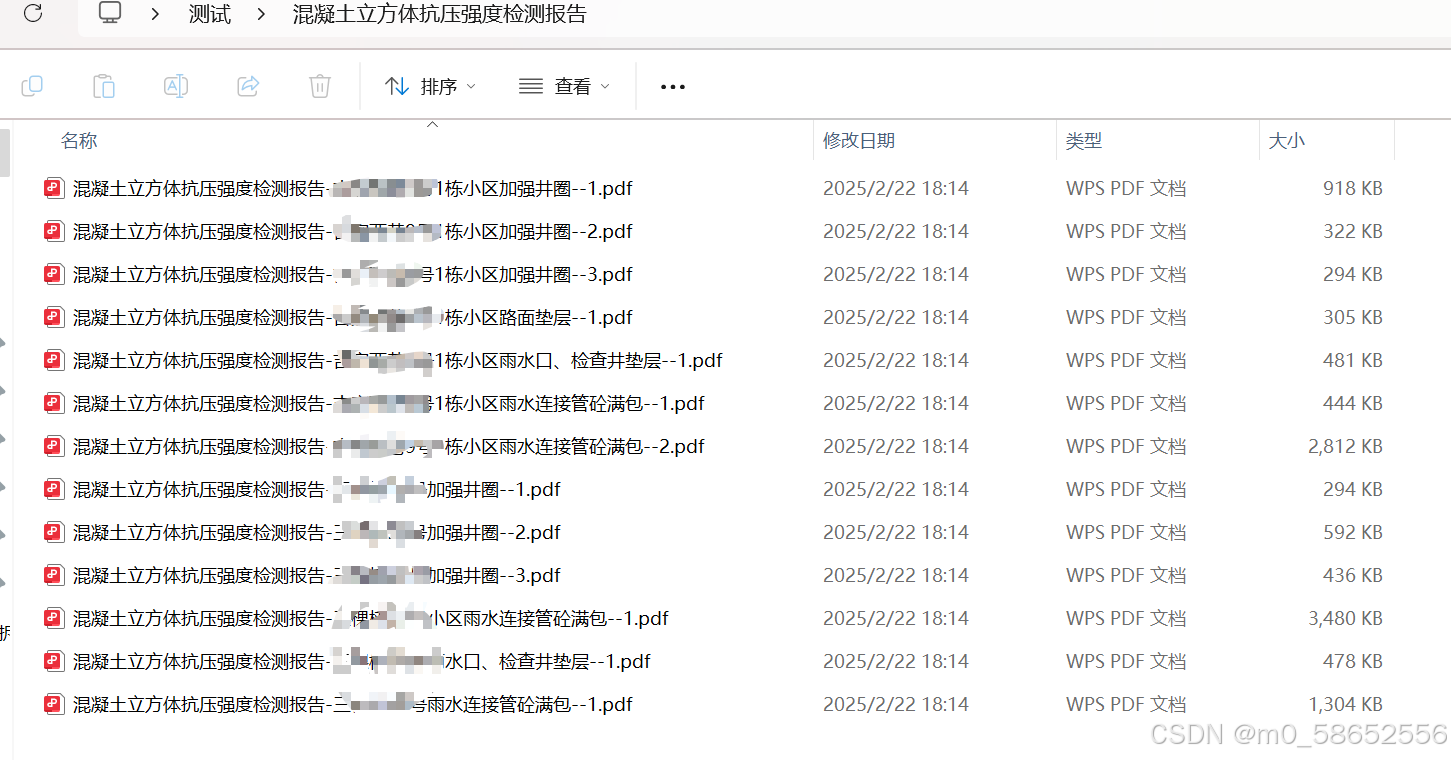
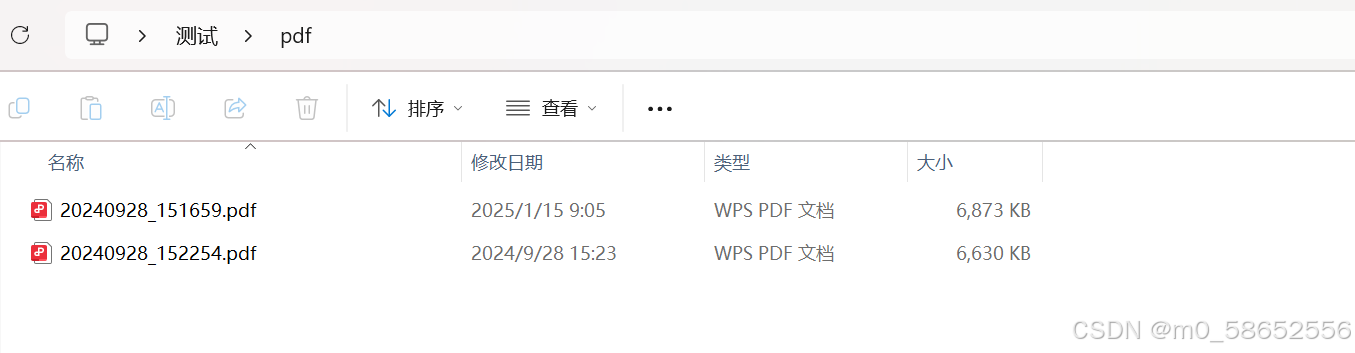
再看一眼源文件,是这样的
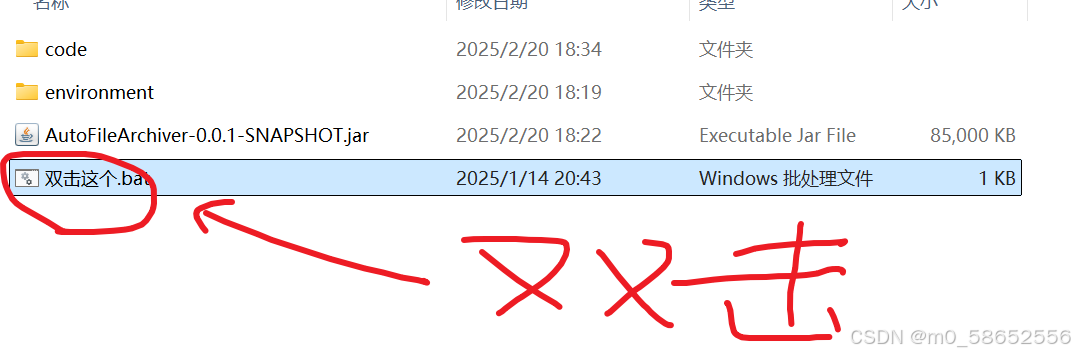
开始使用
解压完双击即可。
 出现两个黑窗口,不要关闭,ctrl+c复制弹出的网址,粘贴到浏览器enter就行了
出现两个黑窗口,不要关闭,ctrl+c复制弹出的网址,粘贴到浏览器enter就行了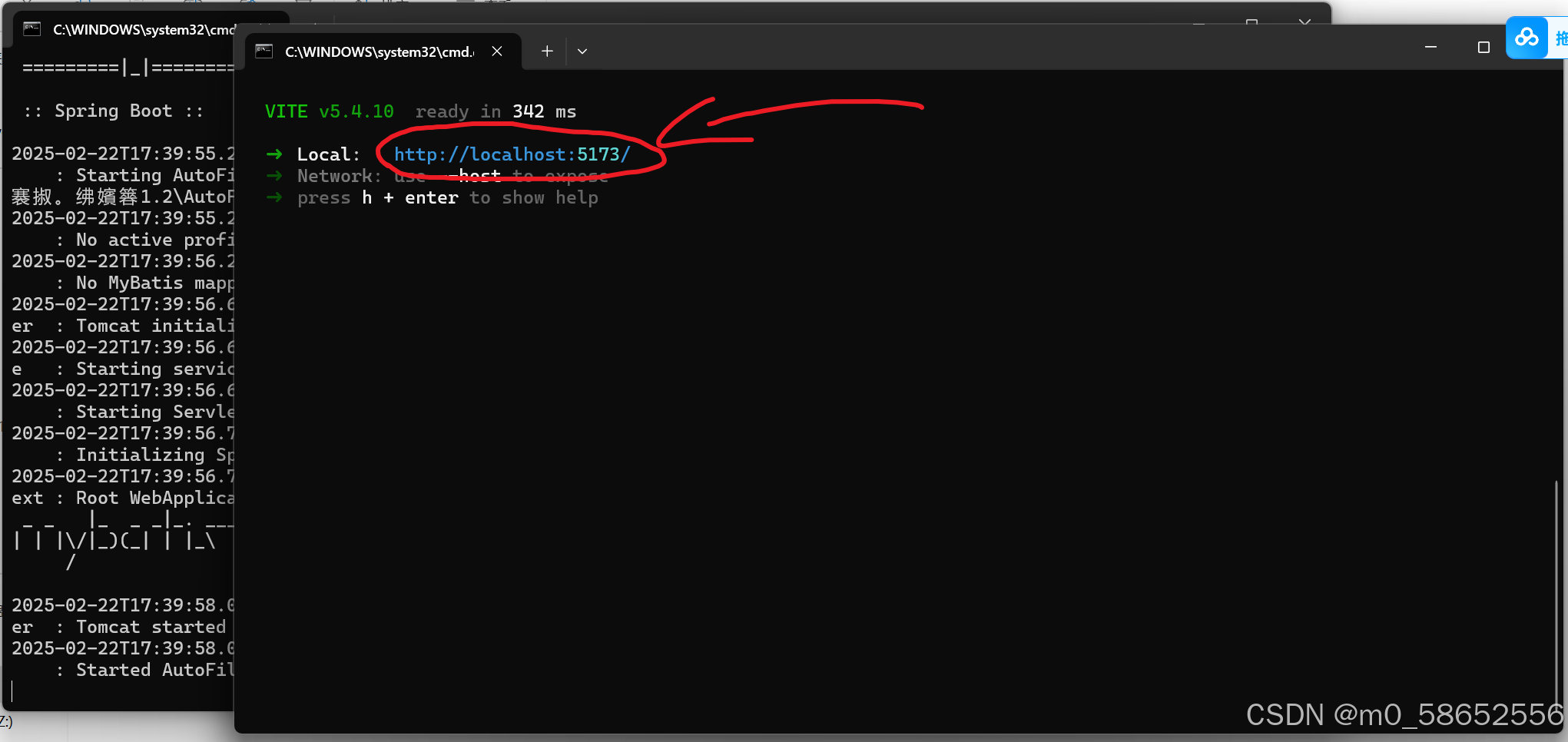
浏览器出现这个页面,按标记填
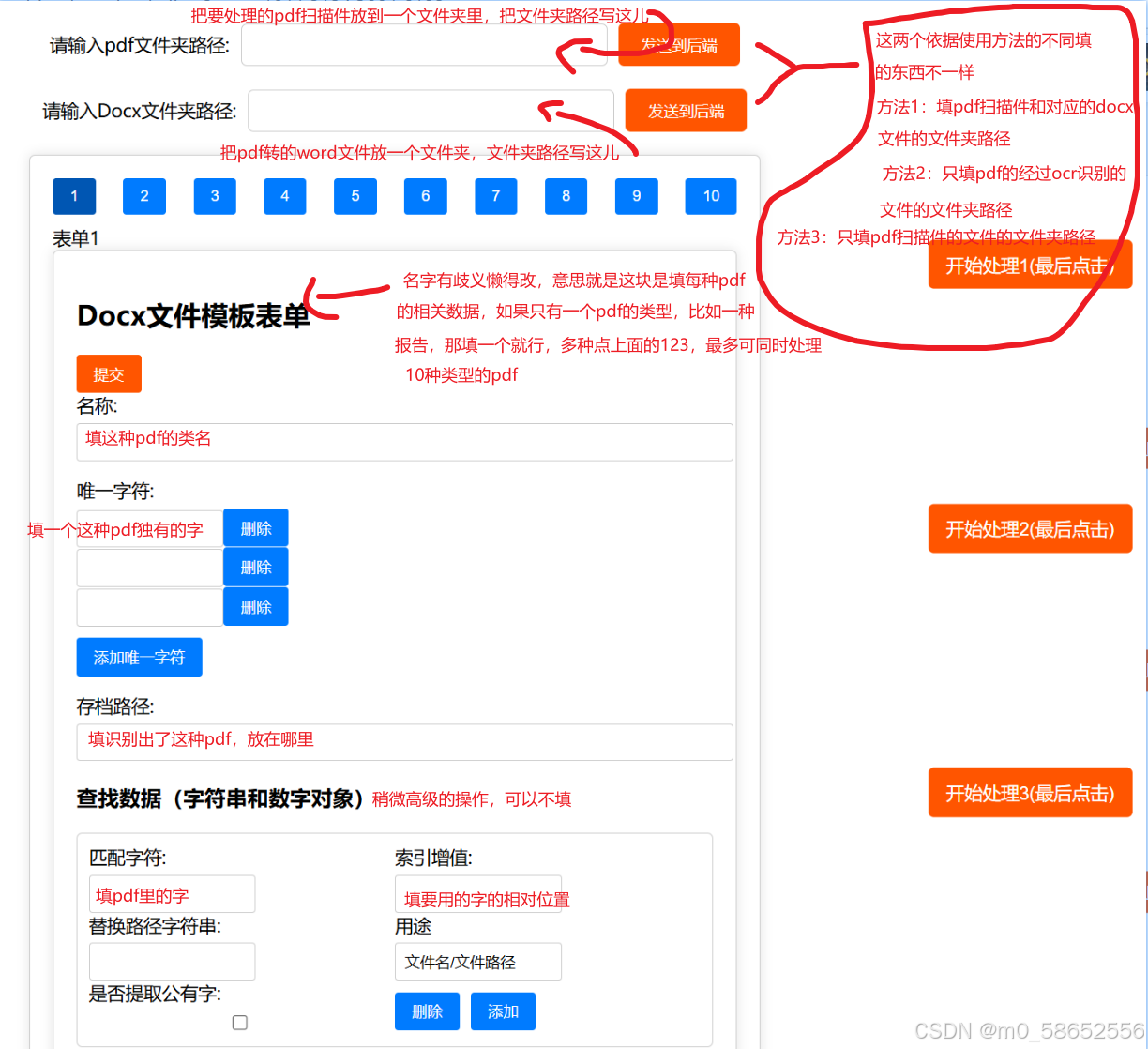
示例
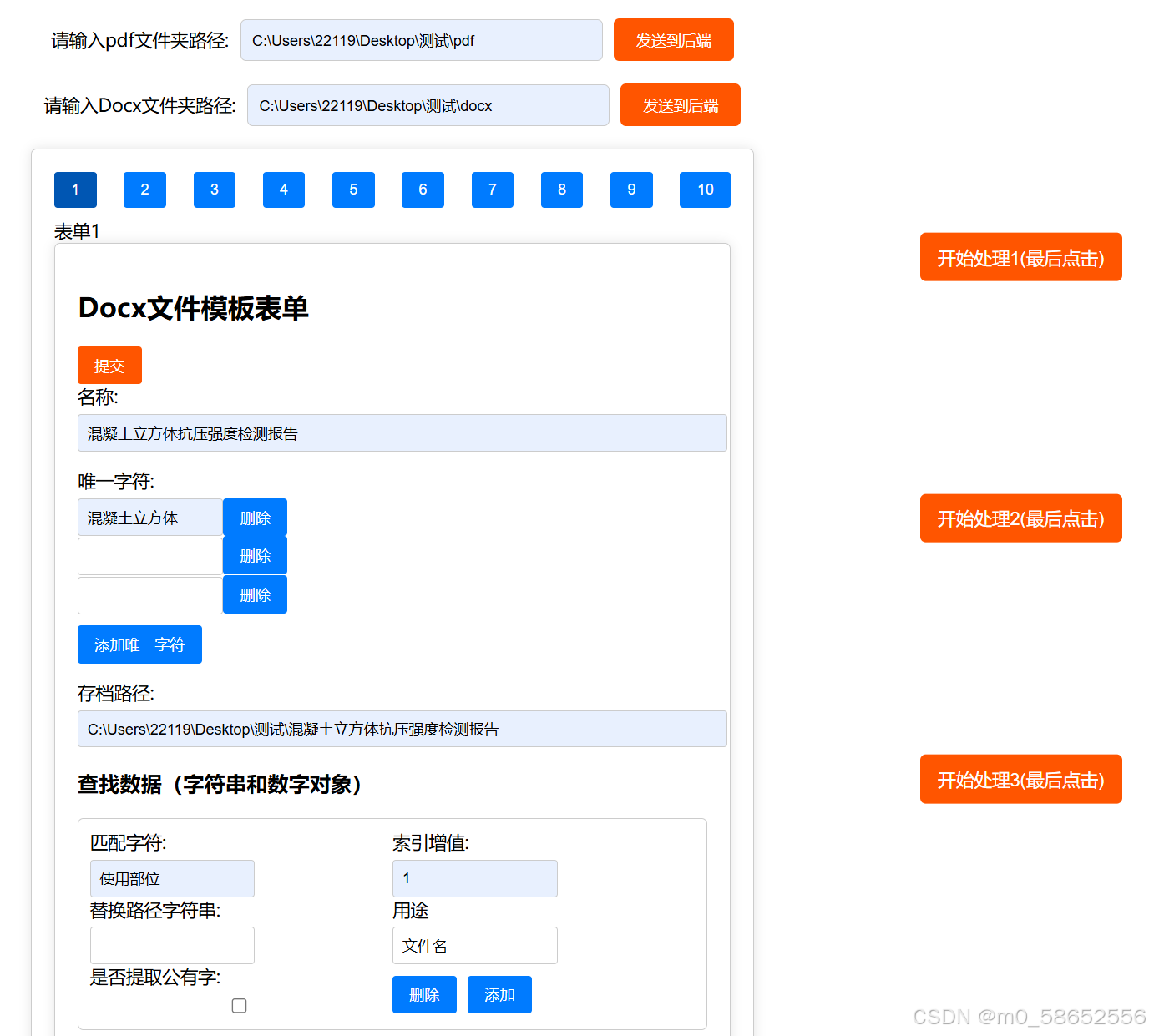
然后依次点击
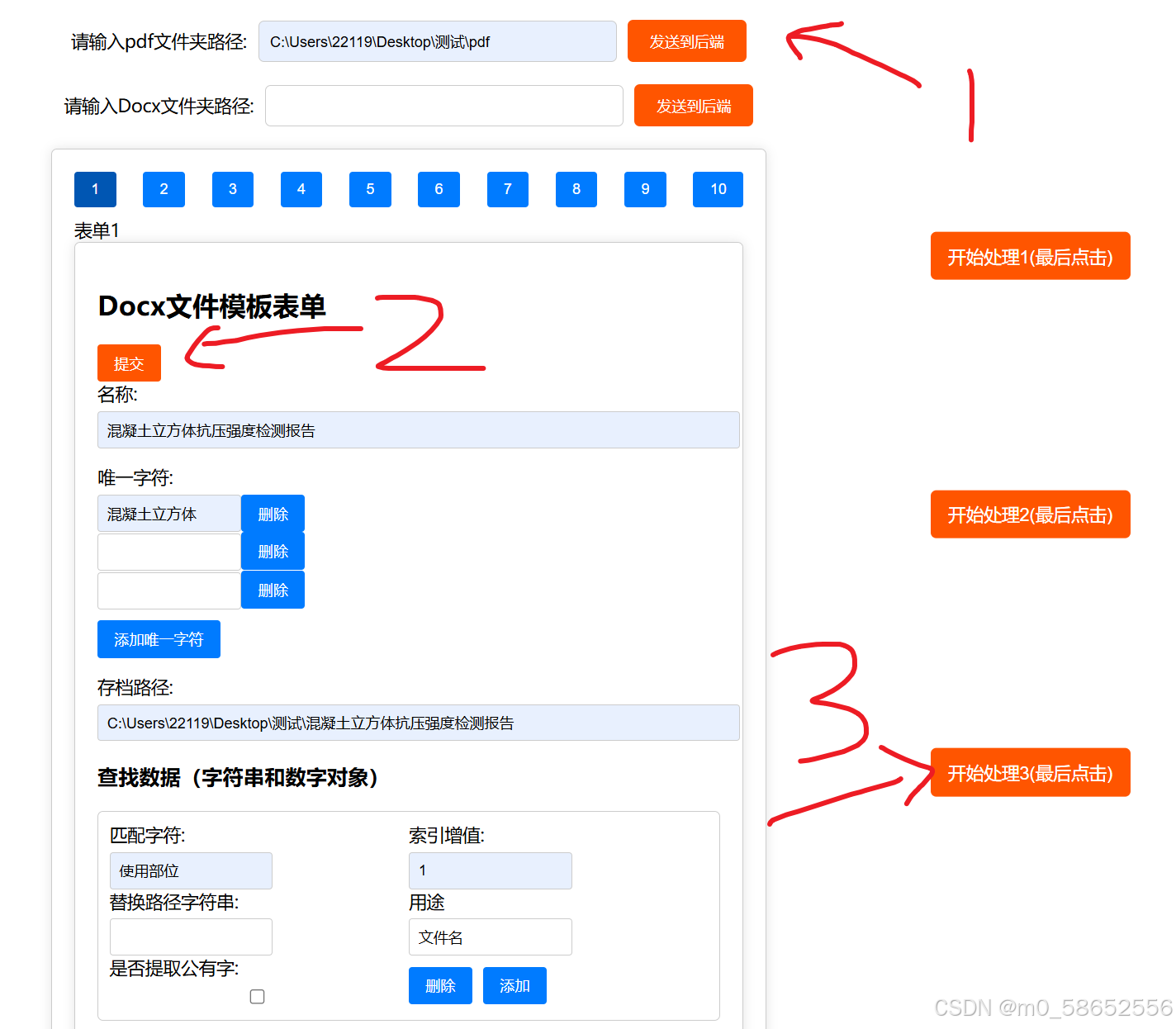
点击开始处理后会弹出处理完毕,是假的,只是一个提示,有一个黑窗口会显示进度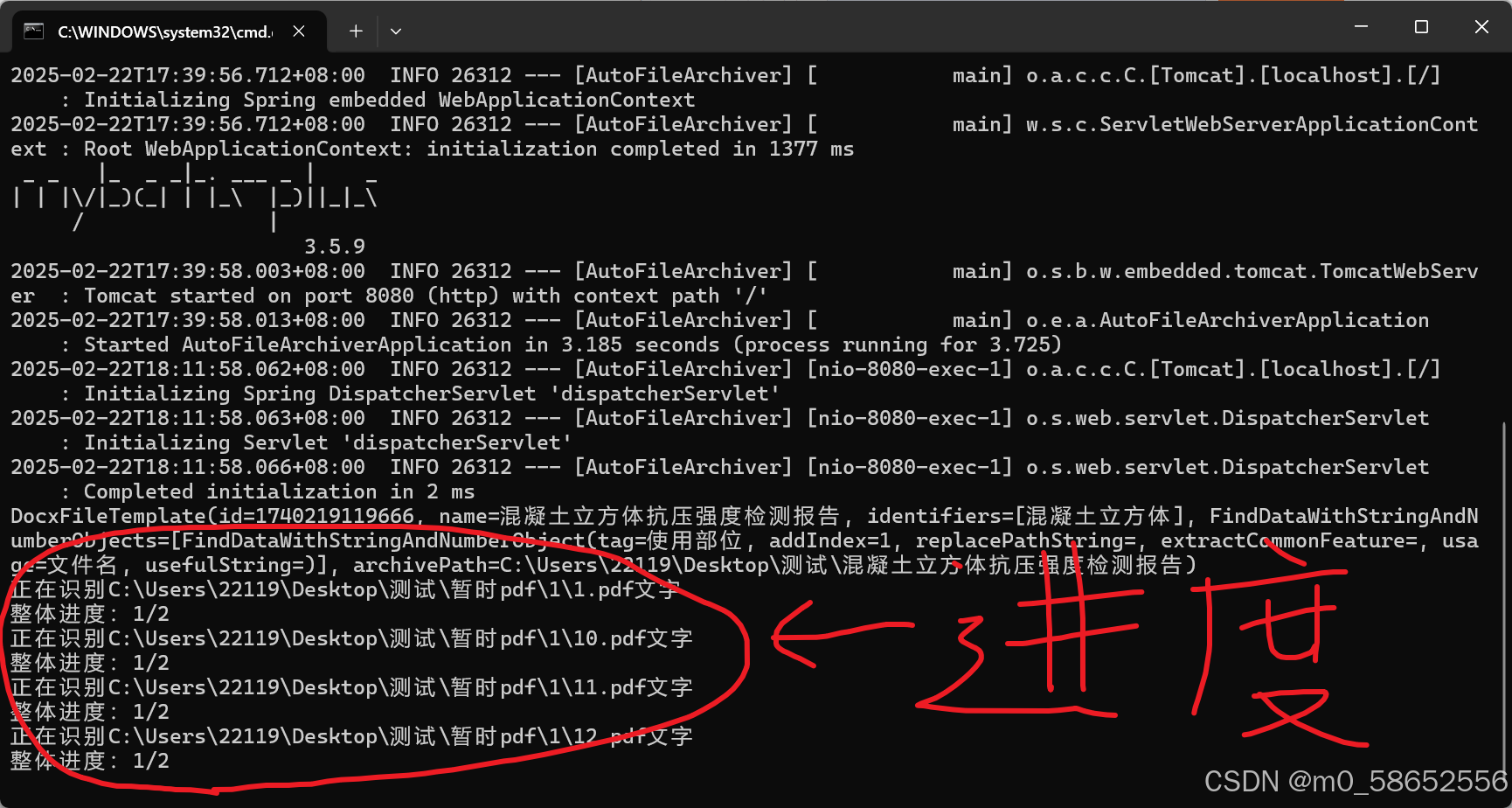
大概10几秒一页
黑窗口出现归档完毕,才是真的完毕
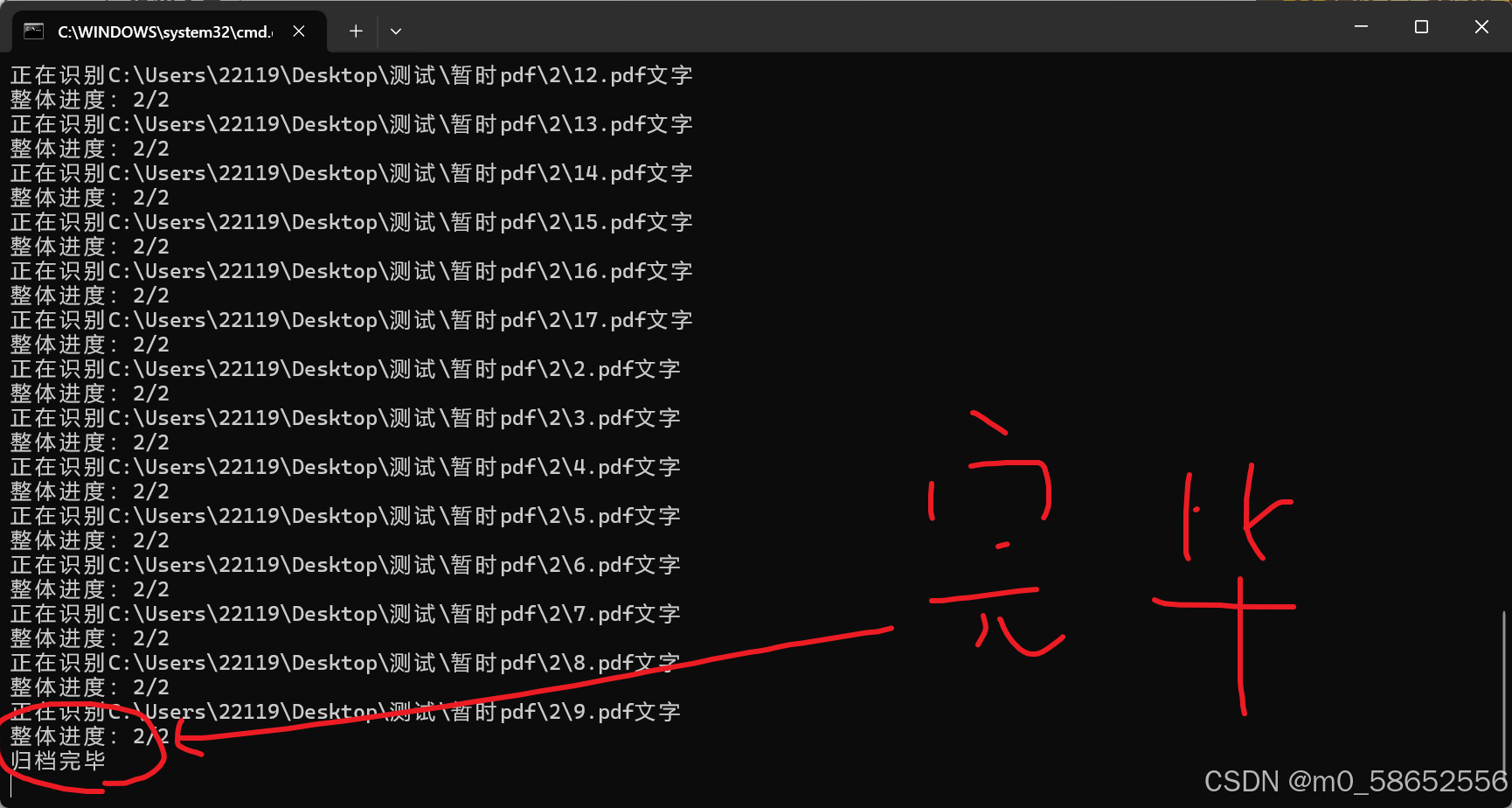
查看自己写的归档的文件夹,文件都重命名在里面的,可以自动拆页的
再看一眼源文件,是这样的
我这例子里不止混凝土抗压强度报告,懒得写其它,大概就是有几种报告就得点123切换,每种报告写一个,每种报告都得点一次提交,这里没把每种报告都写一遍,没识别到的报告就会附在前一页。意思就是假如你的报告是几页一份的,就在第一页找独特字,这样就会把后几页默认附在第一页后,几页一份的报告也能处理。
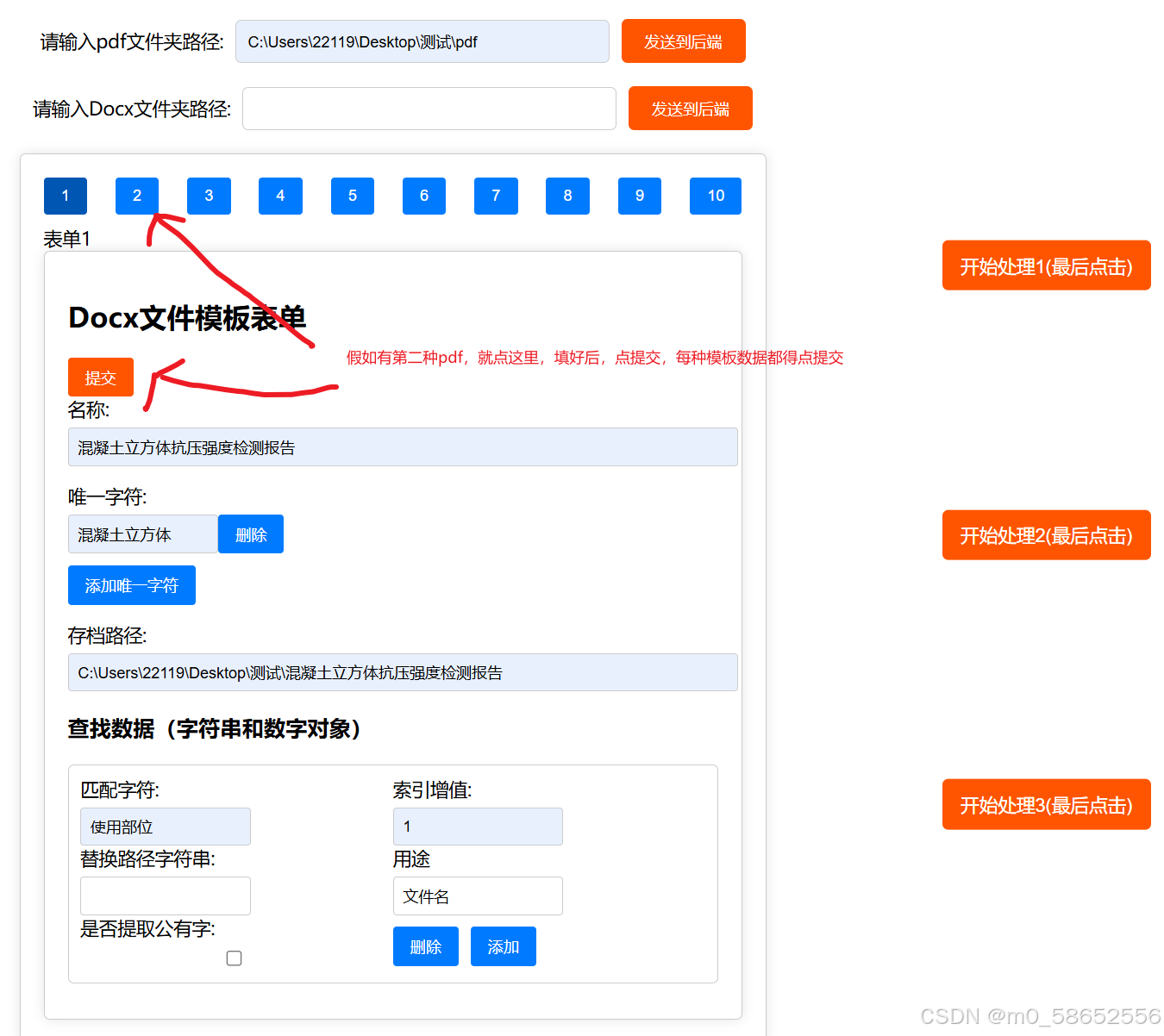
注意事项
把python,java,node硬塞进去。无需安装,解压既用。python下载了paddleocr,可自动识别扫描件文字。由于是硬塞的各种环境,文件很多很大估计2个多g,解压要10分钟,源代码也都塞进去了,可以自己改。
方法2怎么获得经过ocr识别的pdf,用wps,要开vip


















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









