









bilibili网站的视频
目录
效果图

完整代码
- 先上代码, 简单更改ip代理后可直接运行;
- 采用的是单线程, 如果需求量大自己改多线程吧
- reset_session() 函数需要改 添加自己的代理api
- if __name__ == '__main__': 更改要刷的次数和视频url
- 某站更新播放次数有1-2分钟左右的延迟, 如果正常运行 播放次数却没变化, 请等待几分钟再看
import re
import time
import uuid
import json
import random
import requests
def reset_session():
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35'
}
tiquApiUrl = r'隧道IP接口'
apiRes = requests.get(tiquApiUrl, timeout=5)
# apiRes.text == ip; 例: 117.94.127.67:11236
ipport = apiRes.text
global session
session = requests.session()
session.headers.update(header)
session.proxies = {'http': ipport, 'https': ipport}
def get_aid_cid(url):
# 这个请求还返回了两个cookie: b_nut、buvid3 ; session会自动保存
res = session.get(url)
res_text = res.text
str_data = re.search(r'__INITIAL_STATE__=(.+?);\(func', res_text, flags=re.S).groups()[0]
data_dict = json.loads(str_data)
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
# 当前播放量
count = data_dict['videoData']['stat']['viewseo']
return aid, cid, count
def set_cook_sid(aid, cid):
url = r'https://api.bilibili.com/x/player/v2'
p = {'aid': aid, 'cid': cid}
session.get(url, params=p)
def get_b_lsid():
# 8位的16进制字符串.字母大写_时间戳的16进制.字母大写
n = ''
for i in range(8):
n += hex(random.randint(1, 16))[2:].upper()
t = str(hex(int(time.time()) * 1000)).upper()
n = n + '_' + t
return n
def get_uuid():
u = str(uuid.uuid4()).upper()
# 因为time.time返回的是秒级别的时间戳; js中是毫秒级的, 1秒=1000毫秒,所以 * 1000
u = u + str(int(time.time() * 1000 % 1e5)).rjust(5, '0') + 'infoc'
return u
def get_buvid4(b_lsid, _uuid):
# 因为这个请求中携带了 b_lsid、_uuid、CURRENT_FNVAL、b_nut、buvid3 这几个cookie, 所以需要添加上
# b_nut、buvid3 这两个是aid和cid的请求返回的session自动添加上了
session.cookies.set('b_lsid', b_lsid)
session.cookies.set('_uuid', _uuid)
res = session.get(r'https://api.bilibili.com/x/frontend/finger/spi')
buvid = re.search('"b_4":"(?P<buvid4>.+?)"}', res.text).group('buvid4')
return buvid
def request_h5(aid, cid, buvid4):
url = r'https://api.bilibili.com/x/click-interface/click/web/h5'
data = {
'aid': aid,
'cid': cid,
'part': 1,
'lv': 0,
'ftime': str(int(time.time()) - random.randint(100, 500)),
'stime': str(int(time.time())),
'type': 3,
'sub_type': 0,
'refer_url': '',
'spmid': '333.788.0.0',
'from_spmid': '',
'csrf': '',
}
session.cookies.set('buvid4', buvid4)
res = session.post(url, data=data)
res_data = json.loads(res.json())
if res_data['code'] == 0:
return True
else:
return False
def run(c, url):
theory_count = 0
for i in range(c):
reset_session()
aid, cid, count = get_aid_cid(url)
if theory_count == 0:
theory_count = count
print(f'当前播放量: {count}')
set_cook_sid(aid, cid)
b_lsid = get_b_lsid()
_uuid = get_uuid()
buvid4 = get_buvid4(b_lsid, _uuid)
res = request_h5(aid, cid, buvid4)
if res:
theory_count += 1
print(f'刷取成功, 理论播放量: {theory_count}')
session.close()
time.sleep(1)
continue
else:
print('未刷取成功, h5请求返回值不对')
if __name__ == '__main__':
url = 'https://www.bilibili.com/video/BV1tG41177xj/'
# 要刷的播放量次数, 视频连接
run(9999, url)
实现思路
步骤一: 测试哪个接口是增加播放量的
这边我测试出是名为 'h5'的接口; 主要是记录逆向, 所以就不细写怎么找的了
步骤二: 逆向分析请求携带的参数和cookie
知道是哪个接口增加播放量后, 开始逆向研究 'h5' 这个请求的参数和cookie是怎么来的
操作: 新建无痕浏览器窗口--按F12--点击'网络'选项卡--在地址栏输入链接并回车
任务一: 找 aid 和 cid
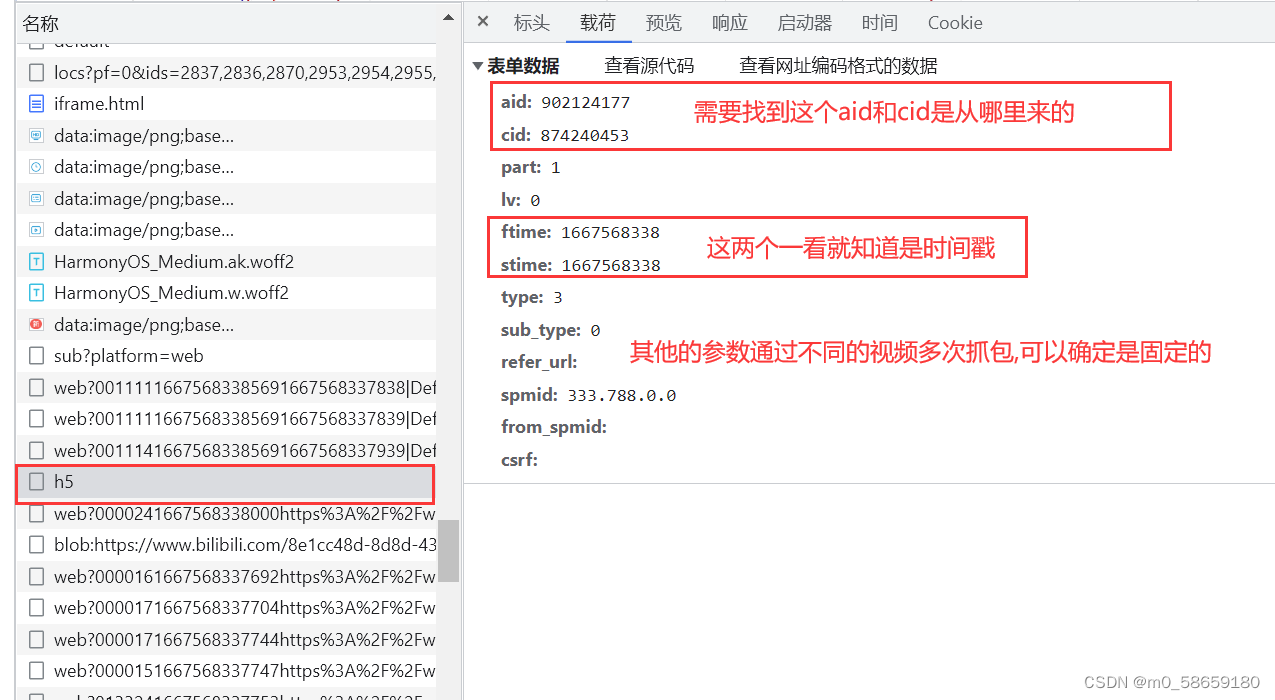
任务二: 找cookie中的 buvid3、b_nut、b_lsid、_uuid、sid、buvid4
CURRENT_FNVAL 通过测试发现是固定值,所以不用找
buvid_fp 通过测试发现不携带也是可以增加播放量的, 所以也不用找
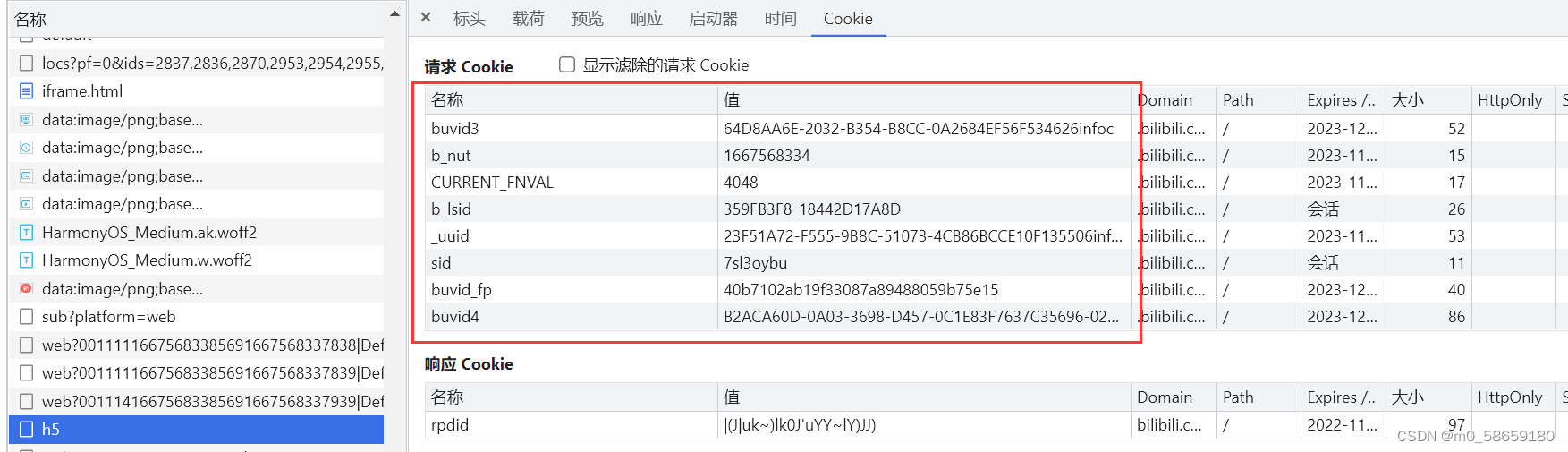
分析 aid、cid 和 cookie
aid、cid 和cookie的来源可能分为如下几种:
- 固定的
- 前期请求返回的数据:
- cookie
- 响应头
- 响应体
- JS算法内部生成的
步骤三:
任务一: 模拟 'h5' 请求
任务二: 判断是否刷播放量成功
每次刷播放量后 理论当前播放量手动+1, 对比实际播放量, 看是否刷新成功
步骤一实现
浏览器设置别自动播放, 新建无痕浏览器, 然后f12点到网络, 清空请求, 再然后播放视频, 就有几个请求, 实在看不出来就用最笨的方法 全部模拟 一个一个试
步骤二实现
请求参数
aid 和 cid
直接在第一个请求里就找到了, 还是比较幸运的
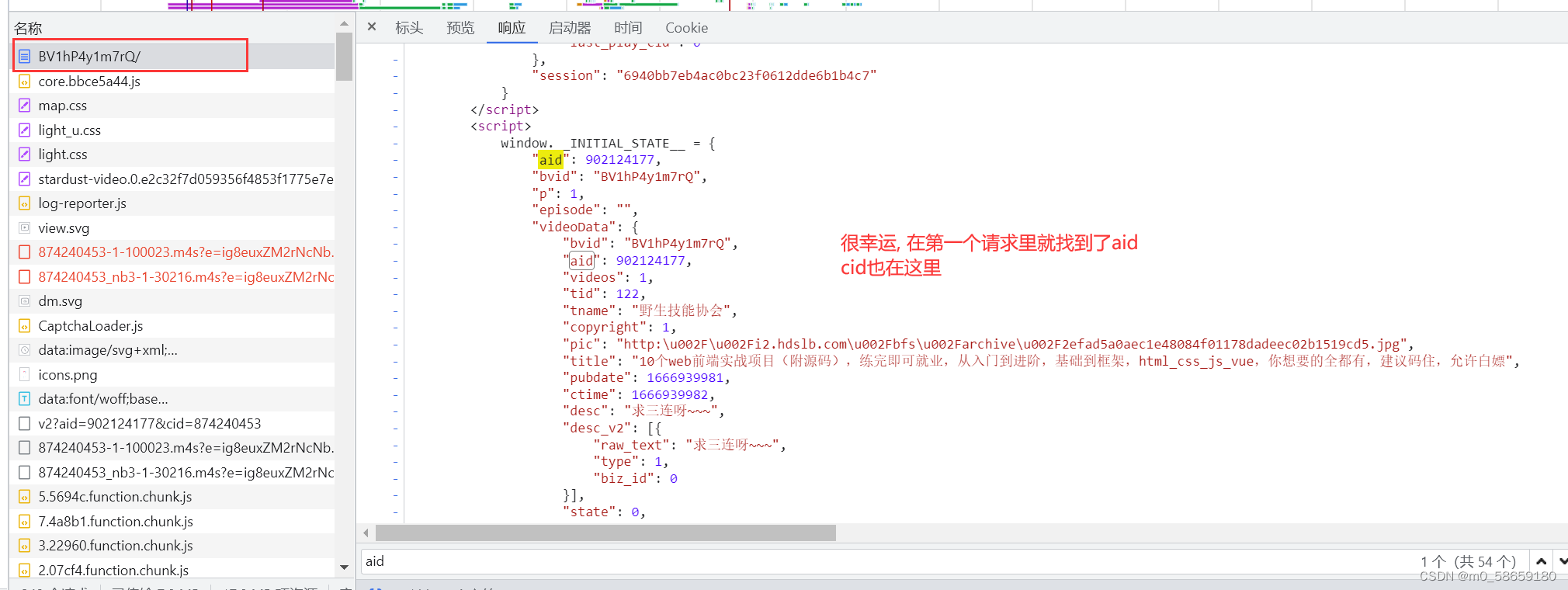
编写代码获取 aid和cid; ps: 搜索的时候发现当前播放量也在这个json里, 所以就一起带着获取了
def get_aid_cid(url):
# 这个请求还返回了两个cookie: b_nut、buvid3 ; session会自动保存
res = session.get(url)
res_text = res.text
str_data = re.search(r'__INITIAL_STATE__=(.+?);\(func', res_text, flags=re.S).groups()[0]
data_dict = json.loads(str_data)
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
# 当前播放量
count = data_dict['videoData']['stat']['viewseo']cookie
buvid3 和 b_nut
同样很幸运, 还是在第一个请求, 找到了 buvid3 和 b_nut

因为session保持会话连接 会自动保存返回的cookie信息, 所以这两个我们不需要进行处理
sid
然后继续一个一个向下找; 又发现了一个sid
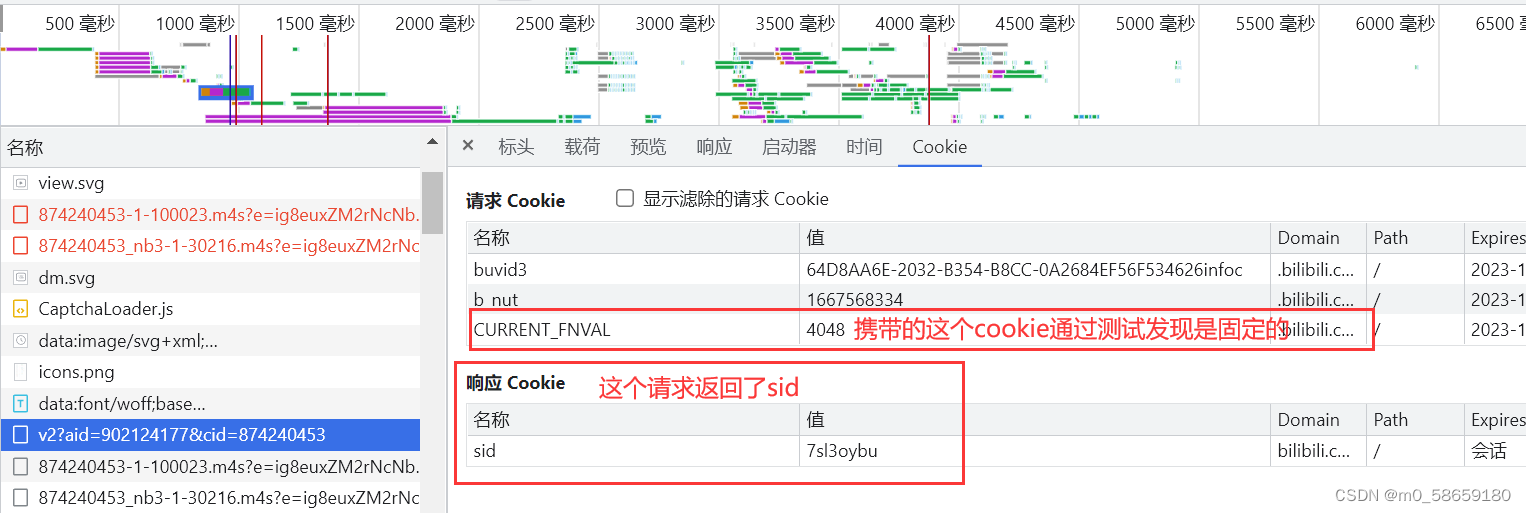
编写代码 这是个get请求; 并且传参了aid和cid; 用session访问一次, 自动保存sid
def set_cook_sid(aid, cid):
url = r'https://api.bilibili.com/x/player/v2'
p = {'aid': aid, 'cid': cid}
session.get(url, params=p)b_lsid
继续向下, 发现这个spi请求多了两个cookie; 并且在之前的响应头 和 响应体中 并没有这两个值的身影, 通过测试 发现也不是固定的, 所以 初步推断出是 内部JS生成的;
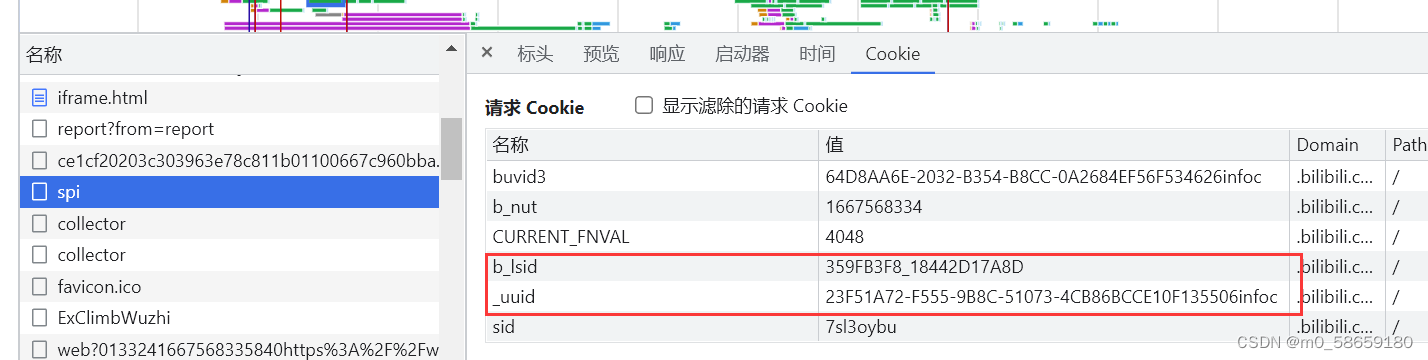
通过 搜索 找到 JS中setCookie的位置
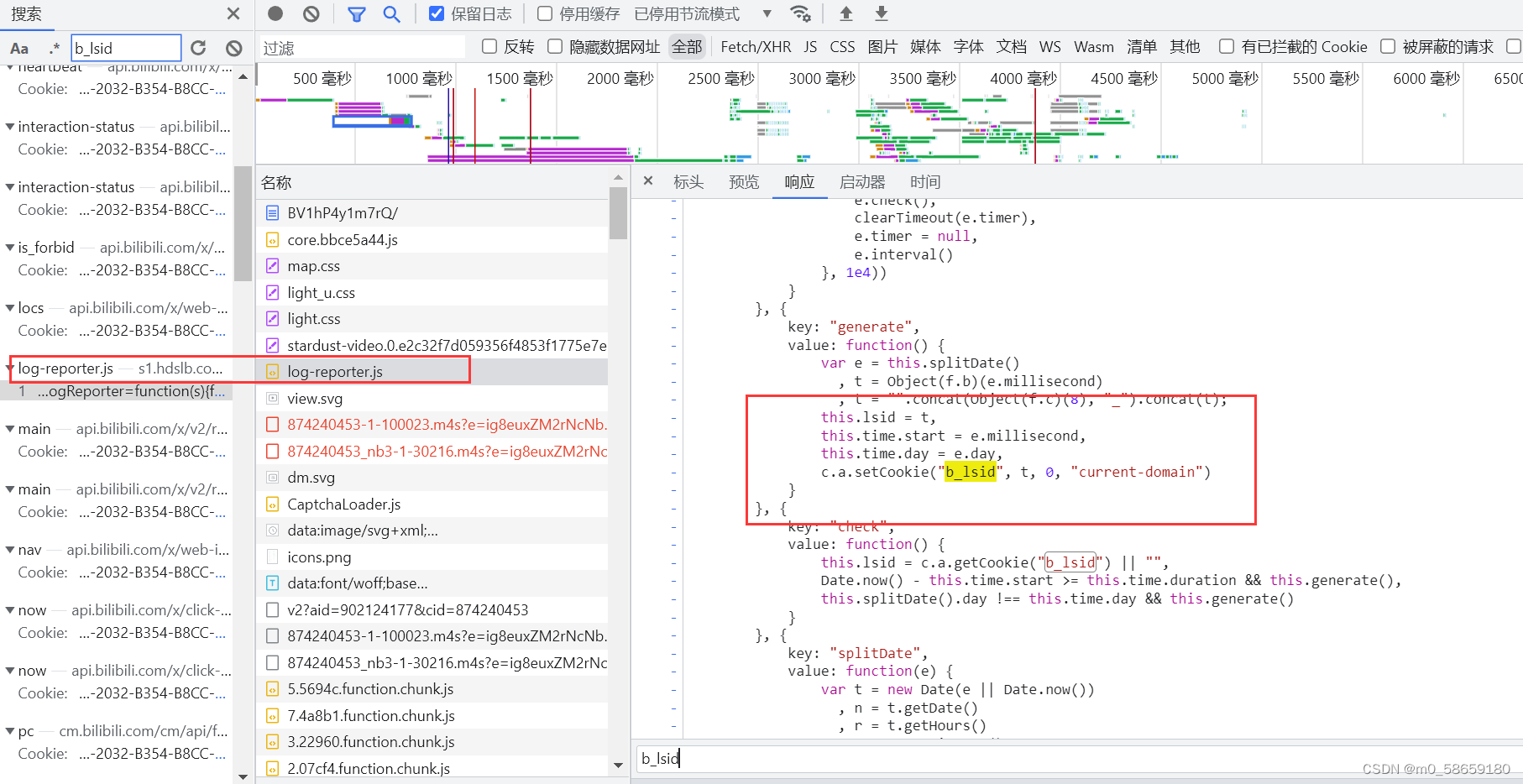 先把这段代码拷贝出来; 可以看到 setCookie("b_lsid", t, 0, "current-domain"), 可以确定 t 就是要找的值
先把这段代码拷贝出来; 可以看到 setCookie("b_lsid", t, 0, "current-domain"), 可以确定 t 就是要找的值
function() {
var e = this.splitDate()
, t = Object(f.b)(e.millisecond)
, t = "".concat(Object(f.c)(8), "_").concat(t);
this.lsid = t,
this.time.start = e.millisecond,
this.time.day = e.day,
c.a.setCookie("b_lsid", t, 0, "current-domain")
}要分析这个 't' 是怎么来的, 所以提取出了这三行要分析的代码
// 首先执行这个函数得到了 变量e
var e = this.splitDate()
// 又执行了 f.b() 把e当作参数传进去了
t = Object(f.b)(e.millisecond)
// 空字符串拼接(f.c(8))
t = "".concat(Object(f.c)(8), "_").concat(t);
c.a.setCookie("b_lsid", t, 0, "current-domain")第一行: var e = this.splitDate()
在资源面板打开这个JS文件 然后打断点 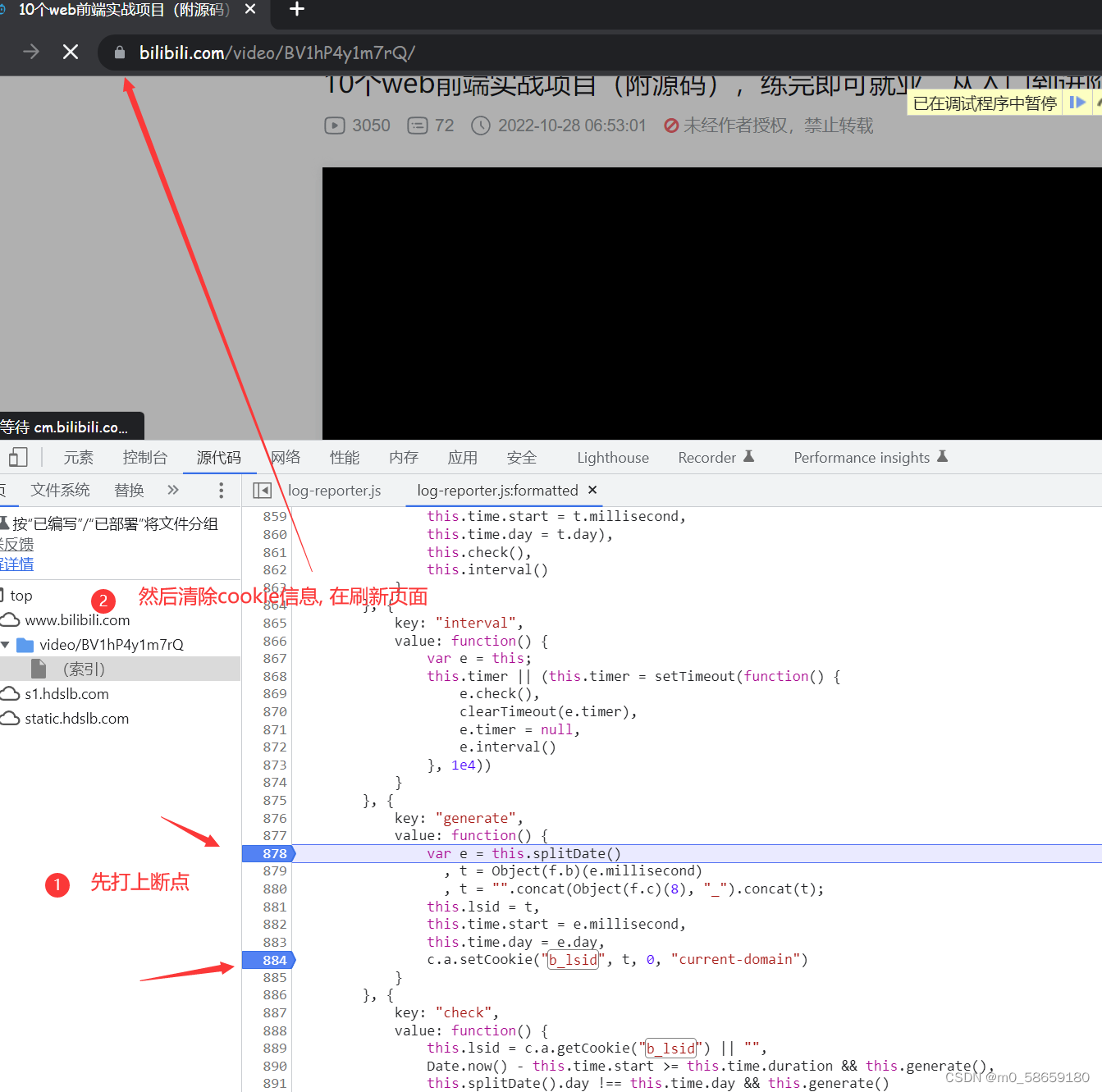
跳转到 this.splitDate() 这个函数
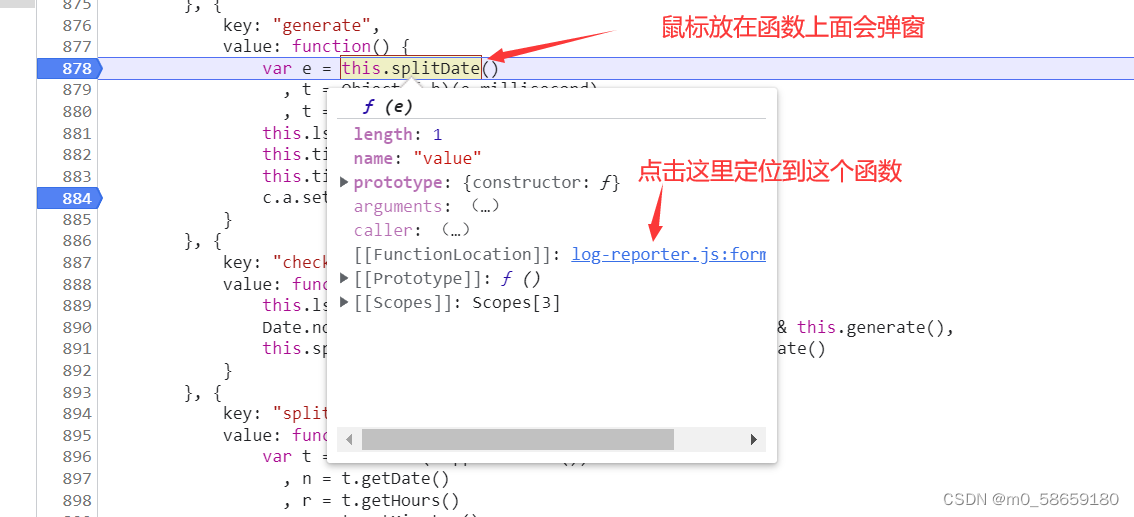 拷贝出来
拷贝出来
function(e) {
// 3. t = 实例化了一个时间对象
var t = new Date(e || Date.now())
, n = t.getDate()
, r = t.getHours()
, e = t.getMinutes()
// 4. 到这里可以知道 第二行分析的代码 e.millisecond == 时间戳
, t = t.getTime();
// 1.先看返回值 返回了一个对象
return {
day: n,
hour: r,
minute: e,
second: Math.floor(t / 1e3),
// 2.因为上面我们要分析的第二行代码是获取这个对象里的millisecond属性,所以直接看t怎么来的
millisecond: t总结 第一行作用: 创建变量 e = 时间戳
第二行: t = Object(f.b)(e.millisecond)
现在 参数e.millisecond 知道是时间戳, 然后开始分析f.b函数
一样的操作 定位到函数位置
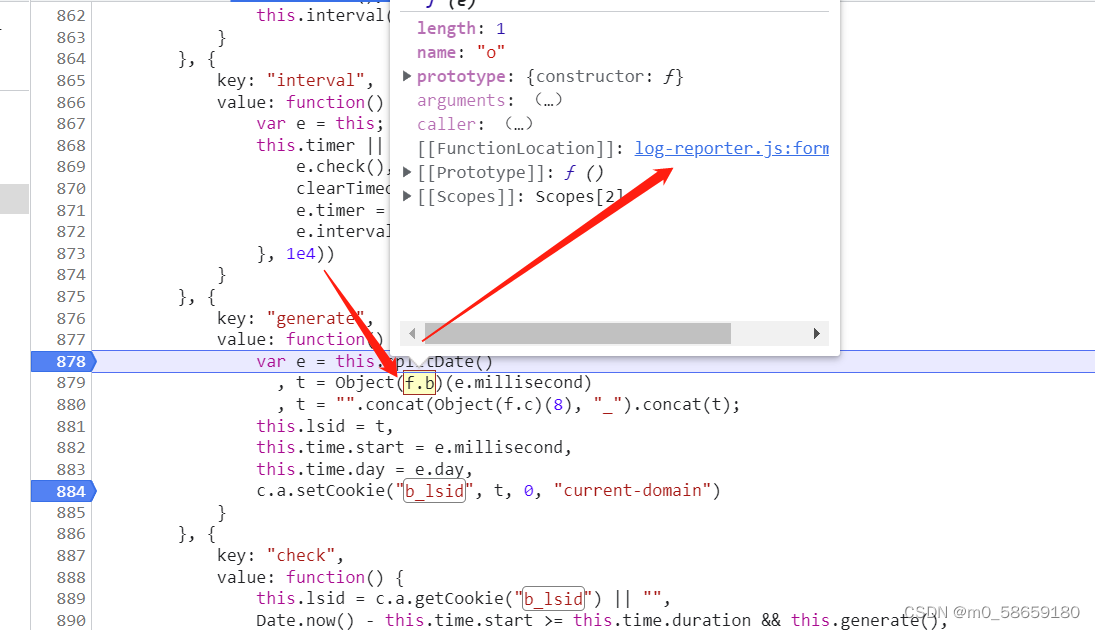 看到了这个函数; 这个函数有个参数e; 我们知道是 时间戳
看到了这个函数; 这个函数有个参数e; 我们知道是 时间戳
function(e) {
return Math.ceil(e).toString(16).toUpperCase()
}
// Math.ceil(e) 时间戳 向上取整(删除小数并+1, 无小数则不变)
// toString(16) 转换成16进制字符串
// toUpperCase() 小写字母转大写总结 第二行作用: 变量 t = 时间戳的16进制, 16进制中的字母是大写
第三行: t = "".concat(Object(f.c)(8), "_").concat(t);
老样子 先定位函数, 这里传了个参数 8 进去
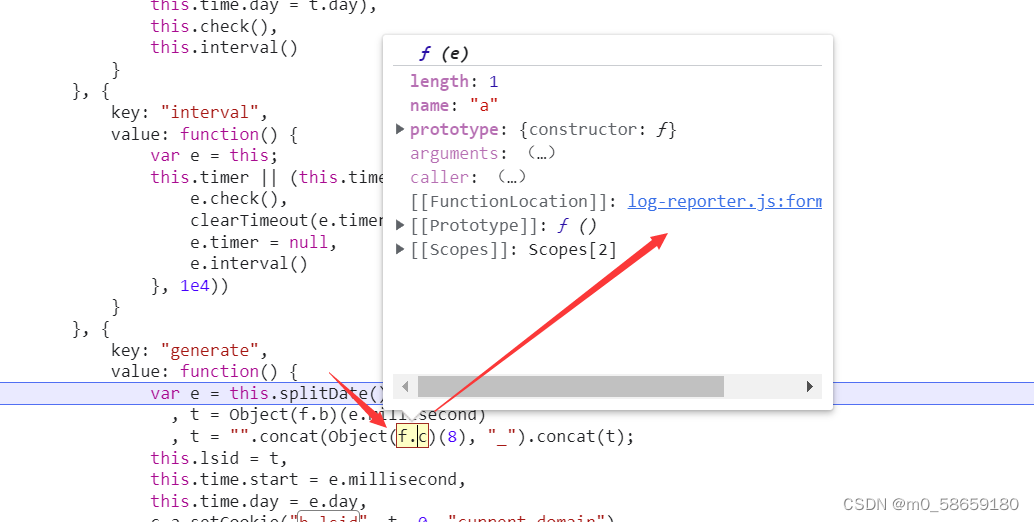
// ================== 一 =============
// 1.已知 e == 8
function(e) {
// 2.已知 循环8次, t = ""
for (var t = "", n = 0; n < e; n++)
// 3.先分析参数 16 * Math.random() == 16以下的小数 不包含16
// 4. 再看o, 打断点 同样的方式 找到o函数
// 7. 已知 t = 8个 字母大写的 16进制 字符串
t += o(16 * Math.random());
// 8. 这里返回了一个函数s 并传参了 t 和 e; 两个参数都已知了, 继续打断点 看s
// 14. 现在 已知 返回了 8位的16进制字符串, 其中的字母都大写
return s(t, e)
}
// Math.random() 随机生成一个 0-1 之间的小数
// ================== o函数 =============
// 5.已知e == 16以下的小数
o = function(e) {
// 6. 这里返回了16进制(字母大写)的1-16之间的某个数字 (包含1和16)
return Math.ceil(e).toString(16).toUpperCase()
}
// Math.ceil(e) 向上取整
// toString(16) 转换成16进制 字符串
// toUpperCase() 小写字母转大写
// ================== s函数 =============
// 9.注意这里 e和t接收参数的位置; 已知e == 16进制字符串 和 t == 8
s = function(e, t) {
var n = "";
// 10.如果字符串长度 < 8
if (e.length < t)
// 11.循环 8-字符串长度 的次数
for (var r = 0; r < t - e.length; r++)
// 12. n拼接0;
n += "0";
// 13. 返回了 循环次数的 0, 拼接上 16进制字符串; 也就是说 如果16进制字符串不足8位 左侧补0
return n + e
}小总结: Object(f.c)(8) == 8位的16进制字符串.字母大写
再看第三行代码 t = "".concat(Object(f.c)(8), "_").concat(t);
总结 第三行代码作用: t = 8位的16进制字符串.字母大写_时间戳的16进制.字母大写
上述分析后, 得知b_lsid = 8位的16进制字符串.字母大写_时间戳的16进制.字母大写
python进行还原
def get_b_sid():
n = ''
for i in range(8):
n += hex(random.randint(1, 16))[2:].upper()
t = str(hex(int(time.time()) * 1000)).upper()
n = n + '_' + t
return n_uuid
先看一下是不是其他请求的 响应体 和 响应头里发现都没有, 于是通过搜索发现了还是在刚才的这个js文件里
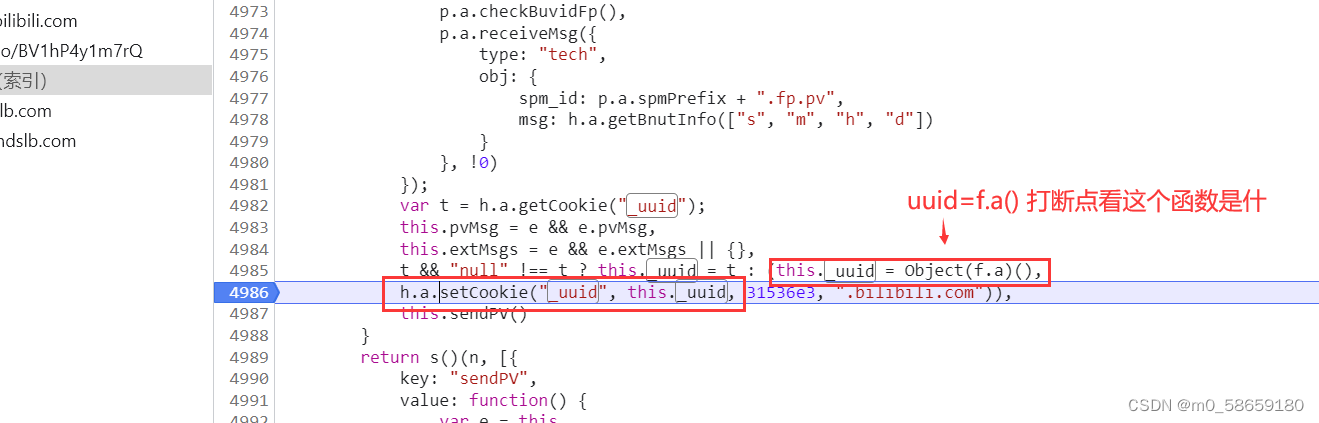
// 0. uuid通用格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12). 其中每个 x 是 0-9 或 a-f 范围内的一个十六进制的数字
// 1.跳转到这里可以看到 他们都调用了 a函数 并分别传参了 8、4、4、4、12
// 这里可以确定就是UUID格式, 所以 a函数 可以直接跳过
var r = function() {
var e = a(8)
, t = a(4)
, n = a(4)
, r = a(4)
, o = a(12)
// 2.这里 i = 时间戳
, i = (new Date).getTime();
// 3. uuid + s(时间戳 % 1e5, 5)并转换成字符串; 看s函数是什么, 打断点跳转
// 5. 返回 uuid + 时间戳 % 1e5 且 长度为5的字符串 + 'infoc'
return e + "-" + t + "-" + n + "-" + r + "-" + o + s((i % 1e5).toString(), 5) + "infoc"
}
// ==============4. s函数==================
// 已知e == 时间戳% 1e5; t == 5
s = function(e, t) {
var n = "";
// 如果 时间戳长度 < 5
if (e.length < t)
for (var r = 0; r < t - e.length; r++)
n += "0";
// 返回 时间戳% 1e5, 长度不足5位 左侧补0
return n + e
}总结: _uuid = uuid + 时间戳 % 1e5 且 长度为5的字符串 + 'infoc'
现在需要做的就是模拟算法:
1. uuid 直接就可以通过python的uuid模块随机生成
2. 时间戳 % 1e5 , 不足5位左侧补0
3. 拼接 infoc
上代码
def get_uuid():
u = str(uuid.uuid4()).upper()
# 因为time.time返回的是秒级别的时间戳; js中是毫秒级的, 1秒=1000毫秒,所以 * 1000
u = u + str(int(time.time() * 1000 % 1e5)).rjust(5, '0') + 'infoc'
return ubuvid4
继续向下点 在这个请求里多了个buvid4, 那么就向上一个一个点, 看是不是其他请求返回的
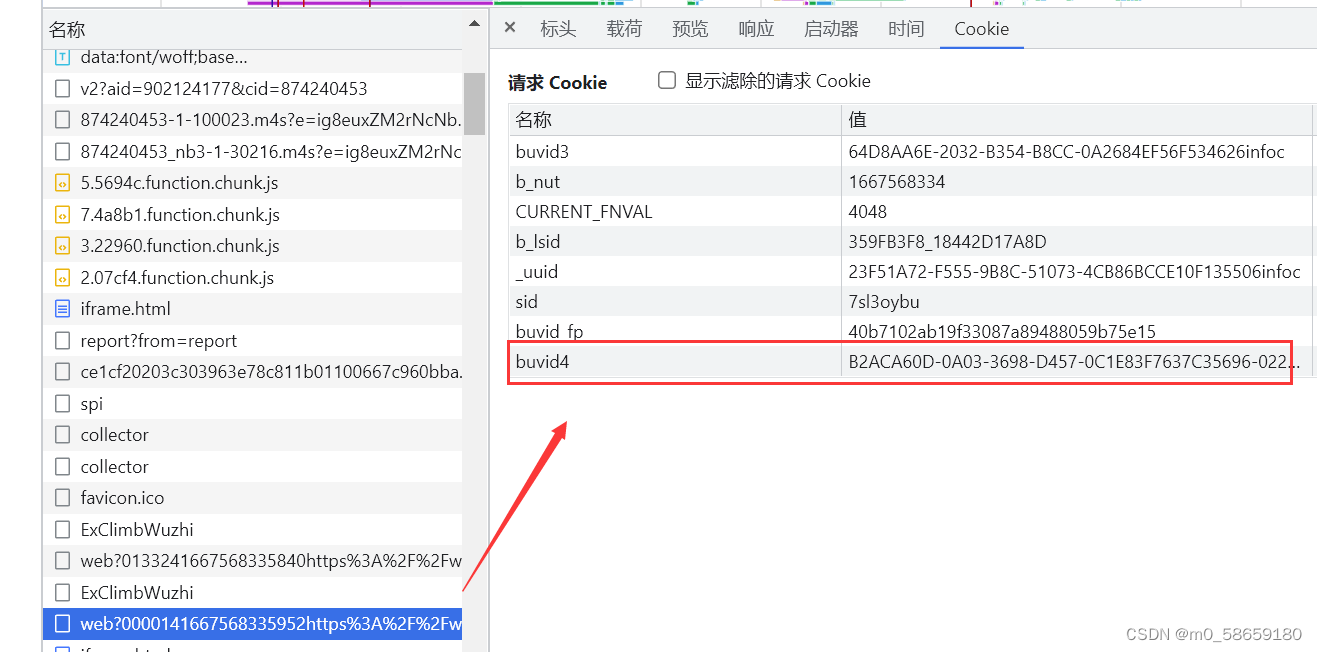
发现spi这个请求返回值中 b_4的值和 buvid4的值是一样的
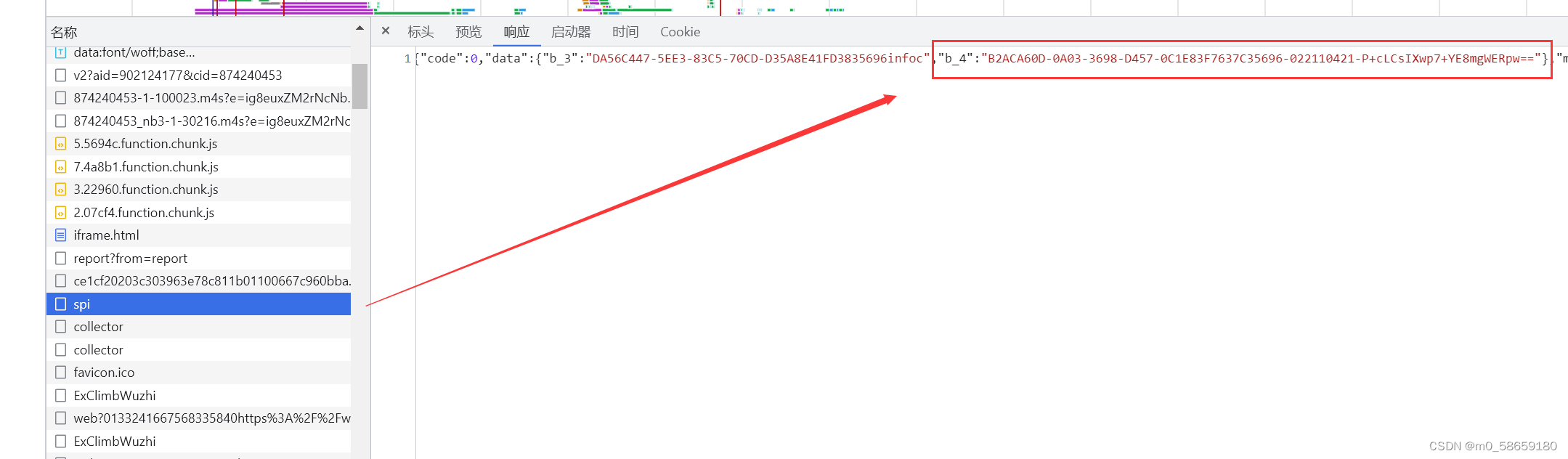
那么直接模拟这个请求, 然后获取他的返回值; 上代码
def get_buvid4(b_lsid, _uuid):
# 因为这个请求中携带了 b_lsid、_uuid、CURRENT_FNVAL、b_nut、buvid3 这几个cookie, 所以需要添加上
# b_nut、buvid3 这两个是aid和cid的请求返回的session自动添加上了
session.cookies.set('b_lsid', b_lsid)
session.cookies.set('_uuid', _uuid)
res = session.get(r'https://api.bilibili.com/x/frontend/finger/spi')
buvid = re.search('"b_4":"(?P<buvid4>.+?)"}', res.text).group('buvid4')
return buvid步骤三实现
模拟h5请求
def request_h5(aid, cid, buvid4):
url = r'https://api.bilibili.com/x/click-interface/click/web/h5'
data = {
'aid': aid,
'cid': cid,
'part': 1,
'lv': 0,
'ftime': str(int(time.time()) - random.randint(100, 500)),
'stime': str(int(time.time())),
'type': 3,
'sub_type': 0,
'refer_url': '',
'spmid': '333.788.0.0',
'from_spmid': '',
'csrf': '',
}
session.cookies.set('buvid4', buvid4)
res = session.post(url, data=data)
print(res.text)挂ip代理
def reset_session():
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35'
}
tiquApiUrl = r'隧道IP接口'
apiRes = requests.get(tiquApiUrl, timeout=5)
# apiRes.text == ip; 例: 117.94.127.67:11236
ipport = apiRes.text
global session
session = requests.session()
session.headers.update(header)
session.proxies = {'http': ipport, 'https': ipport}启动函数
def run(c, url):
theory_count = 0
for i in range(c):
reset_session()
aid, cid, count = get_aid_cid(url)
if theory_count == 0:
theory_count = count
print(f'当前播放量: {count}')
set_cook_sid(aid, cid)
b_lsid = get_b_lsid()
_uuid = get_uuid()
buvid4 = get_buvid4(b_lsid, _uuid)
res = request_h5(aid, cid, buvid4)
if res:
theory_count += 1
print(f'刷取成功, 理论播放量: {theory_count}')
session.close()
time.sleep(1)
continue
else:
print('未刷取成功, h5请求返回值不对')if __name__ == '__main__':
url = 'https://www.bilibili.com/video/BV1tG41177xj/'
# 要刷的播放量次数, 视频连接
run(9999, url)

















 4523
4523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











