







1.介绍
线性统计模型、机器学习模型……针对不同细胞的空间依赖性,[9]建立了一种自编码器与LSTM网络相结合的策略[10]。然而,通过自编码器学习到的特征是原始数据的有损表示[11],可能无法完全表征相邻单元的空间依赖性。此外,上述方法主要集中在单个小区的流量预测上。如果应用于全市规模的网络,它们的计算成本很高,因为需要同时训练数百甚至数千个模型。
本文工作:密集连接的CNN是最先进的深度学习架构,它被用来集体模拟不同细胞中流量的时空依赖性。空间依赖性自然地被卷积运算捕获。使用两个cnn对两个时间相关性,即接近度和周期进行建模,并通过基于参数矩阵的方案进一步融合结果。
2.数据集和一些关键观察结果
A.数据集
米兰数据集,城市划分为H×W的网格,H=W=100,cell=100×100,流量数据记录的时间范围为 00:00 11/01/2013 - 00:00 01/01/2014,每隔10min记录一次。(但本文以1h作为时间单位)
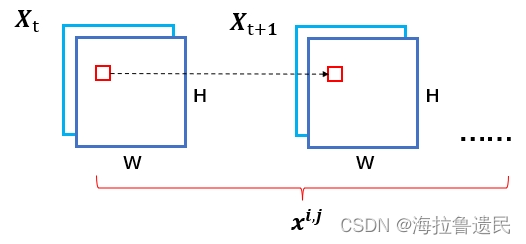
在第t个时隙里,所有cell中的in、out流量:

B.数据观察
主要探讨了流量的时间相关性和空间相关性。(笔记1论文的叙述结构和本文很像,意义也一样,都是为了表明考虑时空相关性的合理性和重要性)
1)时间上:
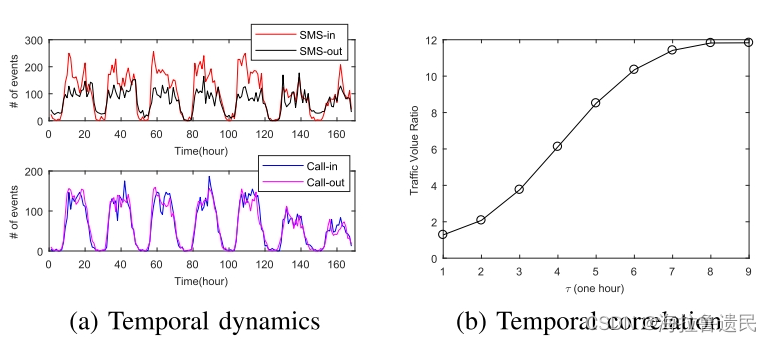
流量的日规律性非常大,与工作日相比,周末流量会下降。短信进出流量的差异要比电话的差异明显得多。 定义了平均流量比average traffic volume ratio:
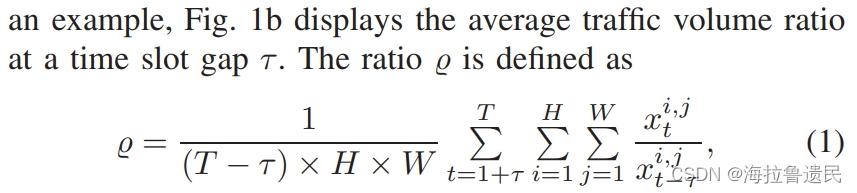
τ是时隙间隔,求和部分是(T-τ)×H×W个比值的和,所以前面进行了平均处理。
该比值的值表示无线业务量在时间序列上的时间相关性,即相邻时隙的业务量在时间上的相关性大于分开时隙(τ较大时)的业务量的相关性。
2)空间上:
采用皮尔逊相关系数,即归一化的协方差,这里和笔记1的论文思路完全相同,略。
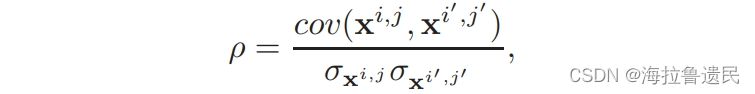
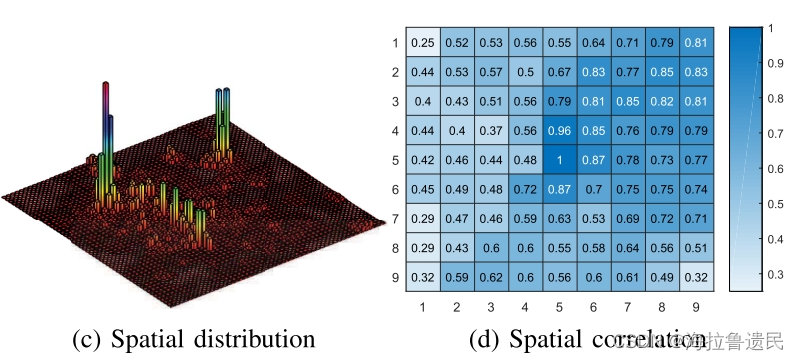
总之,预测模型需要同时捕获时空相关性。
3.预测模型
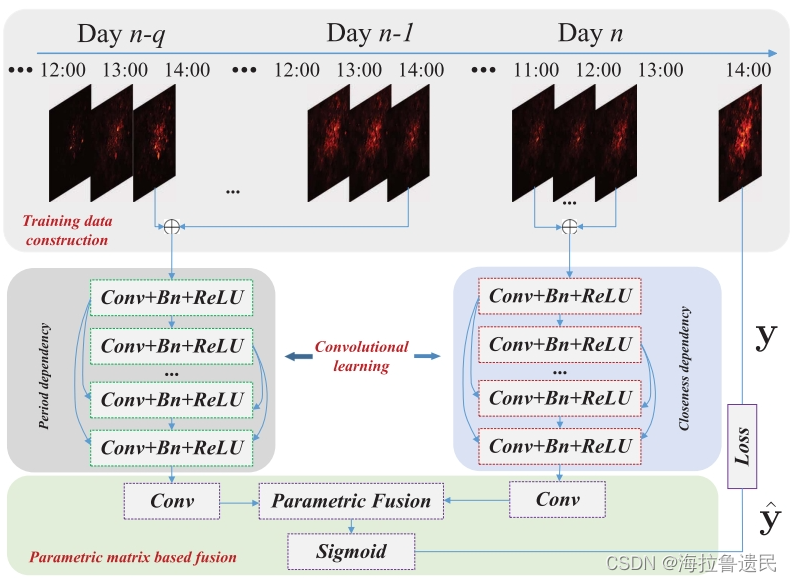
A.训练数据构建
预测目标是第t个时隙的流量(图上为14:00),则在此之前的历史流量数据可被分为两类:recent time and daily history,即距离目标时隙较近的近期数据(closeness)和每日的历史周期数据(period)(图中分别是Day n的11:00/12:00/13:00和Day n-1/.../Day n-q的14:00)

p和q分别是两类时间序列的长度。q*24是因为t是以小时为单位的。最终对[Xt-p,...Xt-1]和[Xt-q*24,...Xt-24]进行concat,得到Xc和Xd。(p个X张量concat,维度变为2p*H*W)

B.密集连接卷积神经网络
(k1,k2)的卷积核可以聚合k1*k2的cell的特征。利用CNN,在每一层进行一系列卷积后,可以捕获城市范围内流量的局部和全局空间依赖关系。
考虑到不同cell无论相邻还是相距较远,其进出流量都是相互依赖的,因此在CNN中采用密集连接模式,可以缓解梯度消失问题,加强特征传播,最终提高预测效率和精度。
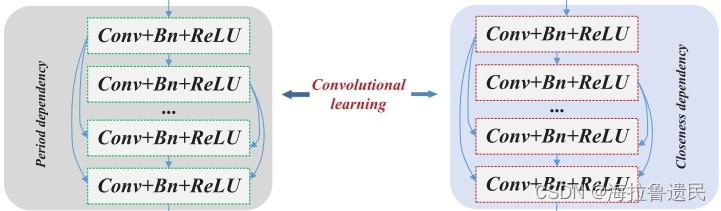
如图所示,设计了两个具有共享结构的网络,一个用于建模时间紧密closeness依赖,另一个用于建模时间周期period依赖。网络结构共有L层,每层实现一个非线性变换。该变换是一个具有三个连续操作的复合函数,即卷积(Conv),批量归一化(BN)和激活函数(ReLU)。

C.基于参数矩阵的融合
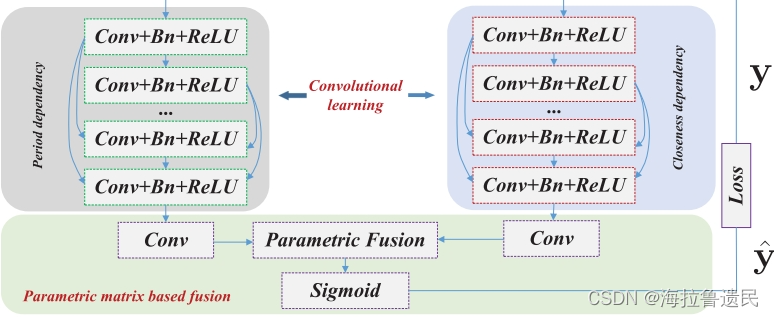
在网络的第l层上单独增加一个卷积层,得到基于参数矩阵的融合方案的特征(将closeness和period融合)。卷积层的输出分别为,
。

损失函数:最小化预测值和真实值的Frobenius范数来训练。(区别损失函数和评价指标)(arg min是指使后者min时变量θ的取值)

4.实验结果与分析
A.预处理和参数设置
在原始数据集的10分钟时间间隔内,有很大比例的小区流量为零,使得数据非常稀疏。此外,10分钟级的资源规划是一项非常困难的任务,可能会导致网络不稳定或开销过大。因此,本文以小时为单位统计流量值。
由于使用sigmoid函数来激活所提出模型的输出,因此使用Min-Max归一化将流量缩放为[0,1]。在评估中,预测值被重新调整回正常值,并与真实值进行比较。另外,选取最近7天的流量作为测试数据,之前的所有流量设置为训练数据。
优化算法采用adam。小批量是32batch,epoch=100,初始学习率设置为0.01,在总训练次数的50%和75%处除以10。
除了最后一层有2个大小为3 × 3的滤波器外,所有卷积层都有32个大小为3 × 3的滤波器。
对于相关序列的长度,p和q都设为3。采用均方根误差(RMSE)作为评价指标。
B.整体性能
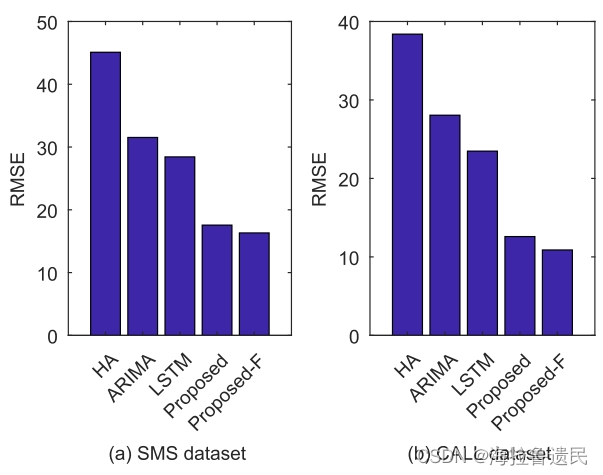
用两种类型的数据集(SMS和Call)进行了实验。
Proposed-F:有基于参数矩阵的融合。Proposed:没有融合。
选择历史平均值(Historical Average value, HA)、ARIMA和LSTM三种算法作为基线。Call数据集上的RMSE值相对低于SMS数据集,因为Call数据集中隐藏的模式比SMS数据集更“规则”。
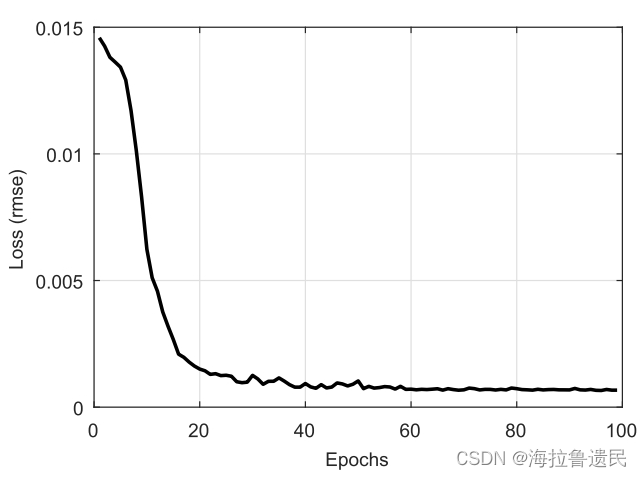
为了显示本文方法的收敛速度,每个历元后的训练损失如图所示。结果表明,在前20个epoch损失快速下降,在40个epoch后逐渐收敛到稳定状态,表明该方法的训练过程具有时间效率。
C.预测结果
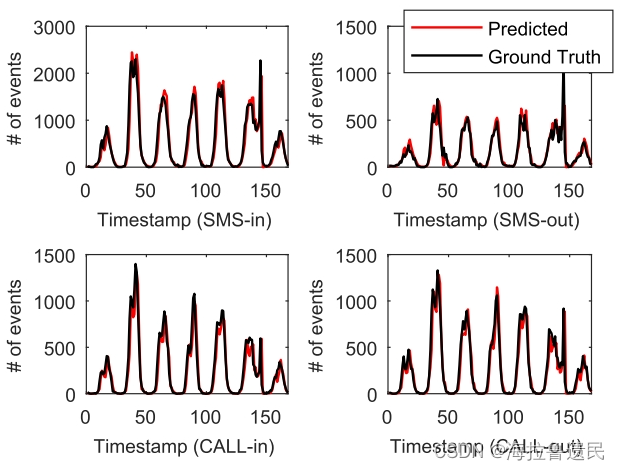
在第130 ~ 160时段,即使流量变得不稳定,预测结果也与地面真实趋势吻合较好。可以有效地捕获和预测进出流量的峰值。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









