






yolov5模型转换rknn
安装virtualenv,用来来管理python环境
pip install virtualenvwrapper
mkdir ~/virtualenvs #创建存方环境的位置
查找virtualenvwrapper.sh脚本的位置
sudo find / -name virtualenvwrapper.sh
#/home/orangepi/.local/bin/virtualenvwrapper.sh
将virtualenvwrapper脚本的位置写入到.bashrc文件中,在.bashrc中添加
export WORKON_HOME=~/virtualenvs
source /home/orangepi/.local/bin/virtualenvwrapper.sh
运行: source ~/.bashrc
常用的一些命令
mkvirtualenv #创建环境
mkvirtualenv rknn --python=python3.9 #创建环境指定版本
workon # 进入|切换 环境
lsvirtualenv # 展示环境列表
rmvirtualenv #删除环境
cpvirtualenv # 复制环境
deactivate # 退出当前环境
新建一个名为yolo的环境
mkvirtualenv yolo
导出包到另一个系统
输出虚拟环境中已安装包的名称及版本号到 requirements.txt 文件中:
pip freeze > requirements.txt
将文件发送到新设备
scp requirements.txt orangepi@192.168.43.212:~/pi/rknn
新系统创建虚拟环境
mkvirtualenv rknn --python=python3.9 #创建虚拟环境
将 requirements.txt 包安装到虚拟环境里
pip install -r requirements.txt
图片标注
训练模型需要足够的目标照片,使用把视频提取一定数量的图片
import cv2
cap = cv2.VideoCapture('/home/libai/orangePi/flightVideo/logs/a.avi')
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
imageNumber = 80 #截图张数
interval = round(total_frames / imageNumber) #间隔桢数
frameNum = 0 #当前桢数
cnt = 0 #图片数
path = '/home/libai/orangePi/rknn_yolo/myTestUav/images'
print(f'tatal frames:{total_frames},interval:{interval}')
while True:
success, image = cap.read()
if frameNum % interval == 0 and success:
cv2.imwrite(path + '%d.jpg' % cnt,image)
cnt += 1
print('>>output %d picture' % cnt)
frameNum += 1
if frameNum >= total_frames:
print('ok')
break
cap.release()
安装labelimg
pip install labelImg
新建文件夹目录,image/train存放图片,labels/train存放标注文件

打开labelimg
open dir 打开图片文件夹
change save dir 保存标签的路经
change save format 设置标签格式这里用yolo格式
A: 切换上一张照片
D:切换下一张照片
W:标注十字架
使用下面程序,将图片与标注文件按比例移动到val验证集文件夹
参考:https://blog.csdn.net/didiaopao/article/details/119927280?spm=1001.2014.3001.5501
import os, random, shutil
def moveimg(fileDir, tarDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.1 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
print(sample)
for name in sample:
# print(fileDir + '/' + name, tarDir + "/" + name)
shutil.move(fileDir + '/' + name, tarDir)
return
def movelabel(file_list, file_label_train, file_label_val):
for i in file_list:
# filename = file_label_train + "\\" + i[:-4] + '.xml' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
filename = file_label_train + "/" + i[:-4] + '.txt' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
if os.path.exists(filename):
shutil.move(filename, file_label_val)
print(i + "处理成功!")
if __name__ == '__main__':
fileDir = r"/home/libai/orangePi/rknn_yolo/myTest/images/train" # 源图片文件夹路径
tarDir = r'/home/libai/orangePi/rknn_yolo/myTest/images/val' # 图片移动到新的文件夹路径
moveimg(fileDir, tarDir)
file_list = os.listdir(tarDir)
file_label_train = r"/home/libai/orangePi/rknn_yolo/myTest/labels/train" # 源图片标签路径
file_label_val = r"/home/libai/orangePi/rknn_yolo/myTest/labels/val" # 标签
# 移动到新的文件路径
movelabel(file_list, file_label_train, file_label_val)
安装yolo
yolov5
安装需求
git clone https://gitee.com/lmw0320/yolov5
cd yolov5
workon yolo #进入yolo虚拟环境
pip install -r requirements.txt
下载预训练权重文件,我用的是YOLOV5s.pt,放到yolov5/目录
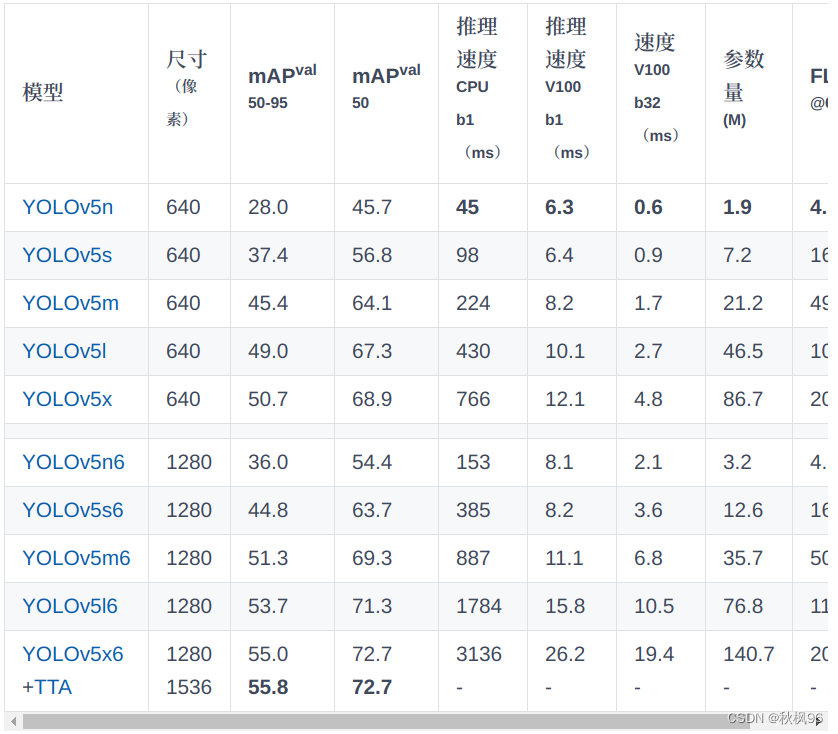
在yolov5/data文件夹新建mytext.yaml 文件,写入下面内容,根据需要更改
train: /home/libai/orangePi/rknn_yolo/myTestPeople/images/train #训练图片位置
val: /home/libai/orangePi/rknn_yolo/myTestPeople/images/val#验证图片位置
# Classes
nc: 1 # number of classes
names: ['object'] # class names
复制yolov5/models中yolov5s.yaml 重命名 mytextModel.yaml
将nc:80改为需要的数字,这里改为了1
修改train.py文件
–weights改为刚下载的yolov5s.pt位置
–cfg 改为刚新建的/models/mytestMode.yaml位置
–data 改为刚新建的/date/mytext.yaml位置
然后就可以训练自己的模型了
workon yolo
python train.py
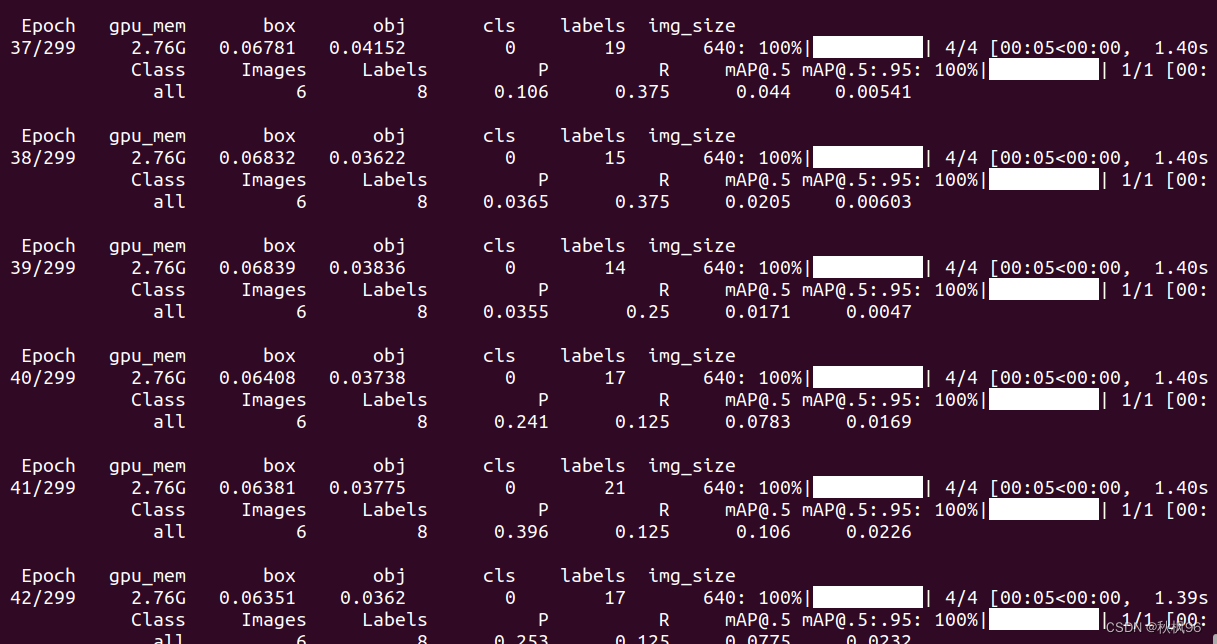
使用tensorbord查看训练的参数
tensorboard --logdir=runs/train/xxx
本机打开http://localhost:6006/ 地址查看训练的参数
训练好后导出.rknn模型,best.pt 文件在./run/中
python export.py --include onnx --rknpu RK3588S --weights ./best.pt
yolov8
- 下载源代码
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
- 在ultralytics/ultralytics/cfg/datasets文件夹新建mydata.yaml 文件,写入下面内容,根据需要更改
path: /home/libai/zheng/yolo/myTest # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: usb
- 在github下载yolov8s.pt放倒根目录
- 训练模型
model = YOLO('yolov8s.pt')
results = model.train(data='mydata.yaml', epochs=100)
在视频中找目标
model = YOLO('/home/libai/zheng/yolo/yolov8/ultralytics/runs/detect/train9/weights/best.pt')
# cap = cv2.VideoCapture(2)
video_path = "../b.mp4"
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
success, frame = cap.read()
if success:
results = model(frame)
annotated_frame = results[0].plot()
cv2.imshow("YOLOv8 Inference", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cap.release()
cv2.destroyAllWindows()
使用 airockchip/ultralytics_yolov8 导出适配rknpu的模型
git clone https://github.com/airockchip/ultralytics_yolov8.git
cd ultralytics_yolov8
然后修改./ultralytics/cfg/default.yaml文件,设置model为自己训练的模型路径
下面代码转换模型
python ./ultralytics/engine/exporter.py
onnx模型转换为rknn
下载RKNN-Toolkit2 工具 https://eyun.baidu.com/s/3eTDMk6Y密码rknn
新建rknn环境,安装依赖
mkvirtualenv rknn
cd rknn-toolkit2-1.4.0
pip3 install -r doc/requirements*.txt
安装RKNN-Toolkit2
cd package/
sudo pip3 install rknn_toolkit2-1.4.0_22dcfef4-cp38-cp38-linux_x86_64.whl
查看是否安装好了
from rknn.api import RKNN
没报错
修改rknn-toolkit2-1.4.0/examples/onnx/yolov5/text.py 文件,ONNX_MODEL为刚生成的.onnx文件,RKNN_MODEL为将要转换成.rknn的文件
ONNX_MODEL = 'best.onnx'
RKNN_MODEL = 'best.rknn'
IMG_PATH = './images4.jpg'
DATASET = './dataset.txt'
需要修改一个位置
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]],target_platform='rk3588')
然后运行程序就可以看到结果了


RK3588安装RKNN-toolkit
RKNN Toolkit Lite2 v1.4支持运行于 Debian 10 / 11 (aarch64) 操作系统支持python3.7 / 3.9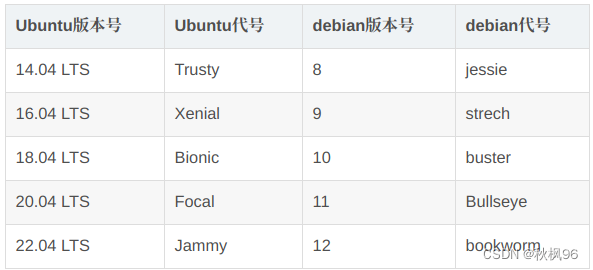
安装python3.9
sudo apt install python3.9
mkvirtualenv rknn --python=python3.9 #创建虚拟环境
安装 RKNN Toolkit Lite2
pip3 install rknn_toolkit_lite2-1.x.0-cp39-cp39m-linux_aarch64.whl
报错了
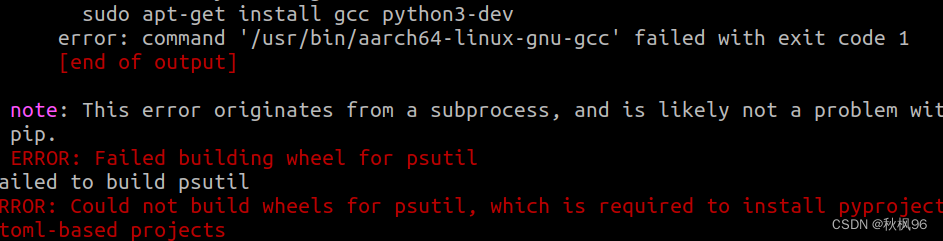
尝试安装python3.9-dev
sudo apt-get install python3.9-dev
import RKNNLite 如果没有报错就安装好了
import RKNNLite
用下面板载的程序,这个程序修改于rknn-toolkit2-1.4.0中的examples/onnx/yolov5/text.,测试一下,使用刚转换的best.rknn模型,推理名为images4.jpg的照片
import numpy as np
import cv2
from rknnlite.api import RKNNLite
import time
class YOLOV5():
def __init__(self):
self.RKNN_MODEL = './best.rknn'
self.IMG_PATH = './images4.jpg'
self.OBJ_THRESH = 0.25
self.NMS_THRESH = 0.45
self.IMG_SIZE = 640
self.CLASSES = ("person")
self.yoloInit()
def yoloInit(self):
# Create RKNN object
self.rknn = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = self.rknn.load_rknn(self.RKNN_MODEL)
# Init runtime environment
print('--> Init runtime environment')
ret = self.rknn.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2) #使用0 1 2三个NPU核心
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
def inference(self):
# Set inputs
img = cv2.imread(self.IMG_PATH)
img = cv2.copyMakeBorder(img, 0, 160, 0, 0, cv2.BORDER_CONSTANT, value=(0,0,0)) # add border
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Inference
a = time.time()
outputs = self.rknn.inference(inputs=[img])
b = time.time()
print('time:',b-a)
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = self.yolov5_post_process(input_data)
print(boxes,classes,scores)
self.rknn.release()
def sigmoid(self,x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(self,x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(self,input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = self.sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = self.sigmoid(input[..., 5:])
box_xy = self.sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(self.IMG_SIZE/grid_h)
box_wh = pow(self.sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(self,boxes, box_confidences, box_class_probs):
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= self.OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= self.OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(self,boxes, scores):
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= self.NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(self,input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = self.process(input, mask, anchors)
b, c, s = self.filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = self.xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = self.nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
yolo = YOLOV5()
yolo.inference()
推理时间大概0.018秒,此前在电脑上推理时间为1.2秒,说明板载的npu加速还是很厉害的

现在就可以使用这块芯片干更有意思的事情了















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









