







 本文探讨了存内计算技术的发展,特别是在AI、大数据和物联网领域的应用。介绍了清华大学、北京大学等高校的创新成果,如清华大学的忆阻器存算一体芯片和北京大学的模拟计算电路。同时,文中概述了企业如Mythic、Graphcore和国内企业如后摩智能、知存科技的商业进展,展示了存内计算芯片在提高计算效率和降低能耗方面的潜力。
本文探讨了存内计算技术的发展,特别是在AI、大数据和物联网领域的应用。介绍了清华大学、北京大学等高校的创新成果,如清华大学的忆阻器存算一体芯片和北京大学的模拟计算电路。同时,文中概述了企业如Mythic、Graphcore和国内企业如后摩智能、知存科技的商业进展,展示了存内计算芯片在提高计算效率和降低能耗方面的潜力。
随着科技的飞速发展,计算能力的提升已成为各行各业的关键需求。尤其是在人工智能、大数据和物联网等领域,对计算性能和能效的要求日益严格。为了满足这些需求,研究人员和企业正积极探索新型计算架构,以提高计算效率并降低能耗。存内计算(CIM, Computing-in-Memory)作为一种创新的计算架构,近年来受到了广泛关注。它将计算任务从传统的中央处理器(CPU)和图形处理器(GPU)转移到存储器内部,以减少数据传输带来的延迟和能耗。下面将对目前存内计算研究进度及相关应用进行简单介绍。
存内计算有许多的技术路线,其中SRAM存算一体已实现中算力芯片流片并向用户送测;Flash存算一体已有小算力场景的规模化应用,并在向中算力演进;新型材料未来更具潜力,但成熟度较低,处于技术攻坚阶段。目前存算一体主流技术路线最新总览图如下图1所示。
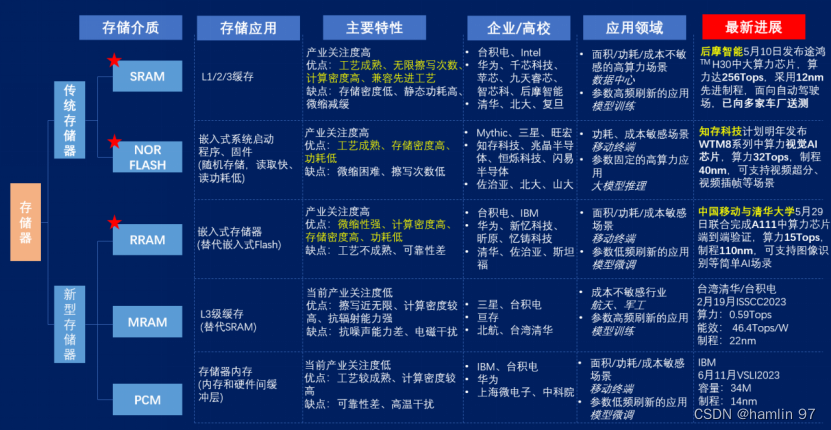
图 1 存算一体主流技术路线最新总览图
(来源:“未来芯片:算力塑造未来”论坛-中国移动通信有限公司研究院-存算一体助力AI大模型的思考与展望)
下面我们将分别从高校和企业方面简要介绍存内计算研究现状,并简述存内计算芯片的应用情况。由于笔者能力所限,高校和企业研究现状均来源于公开资料,所以可能未罗列全所有相关研究。
(一)高校研究进展
在高校研究进展方面,我们将简要介绍几所在存算一体领域的高校的重点研究成果,参考资料主要来自高校发表的论文和高校官网。
(1)清华大学[2]
清华大学集成电路学院教授吴华强、副教授高滨团队基于存算一体计算范式,研制出全球首颗全系统集成的、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器(RRAM)存算一体芯片,在支持片上学习的忆阻器存算一体芯片领域取得重大突破,有望促进人工智能、自动驾驶、可穿戴设备等领域发展。该研究成果以“面向边缘学习的全集成类脑忆阻器芯片”(Edge Learning Using a Fully Integrated Neuro-Inspired Memristor Chip)为题在线发表在《科学》(Science)上。
此外,2022年,清华大学集成电路学院魏少军教授、尹首一教授团队提出的可重构数字存算一体架构可兼顾算力、精度、能效和灵活性,首次在存算一体架构上实现了高精度浮点与高精度整数计算,可满足数据中心级的云端AI推理和训练需求。研究团队在ISSCC 2022上发表题为“A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration”的论文。研究团队提出AI芯片设计的新范式,将可重构计算与数字存内计算架构融合,兼顾能效、精度和灵活性,设计出国际上首款面向云端AI场景的可重构数字存内计算芯片ReDCIM。该芯片首次在存内计算架构上支持高精度浮点与整数计算,可满足云端AI推理和训练等各种任务需求。如下图2所示,ReDCIM芯片在TSMC 28nm工艺上成功流片,可达到29.2TFLOPS/W的BF16浮点能效和36.5TOPS/W的INT8整数能效。
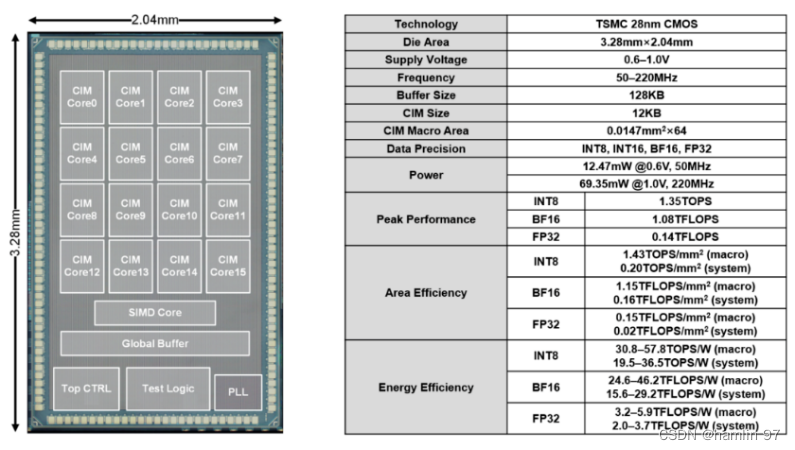
图 2 ReDCIM芯片及硬件指标[3]
2023年9月14日,清华大学吴华强及高滨共同通讯在Science在线发表题为《Edge learning using a fully integrated neuro-inspired memristor chip》的研究论文[4]。作者使用该芯片运行CNN网络实现目标追踪任务,该CNN网络由6个卷积层和2个全连接层组成,其网络结构如下图3所示。其中6个卷积层在片外上运行,2个全连接层在片上运行,并且仅有最后的全连接层可通过片上学习更新参数。虽然该工作对于存内计算和片上学习有着重要意义,但不可否认的是该芯片的神经网络集成度较差,只能运行网络的部分层。
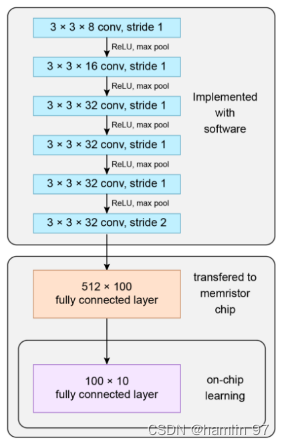
图 3 清华science论文的神经网络结构
(2)北京大学[5]
2023年,北京大学孙仲研究团队在《科学‧进展》(Science Advances)在线发表了题为“存内模拟计算一步求解压缩感知还原”(In-memory analog solution of compressed sensing recovery in one step)的研究论文。基于阻变存储器(忆阻器)阵列,该论文设计了一步实现矩阵-矩阵乘法的存内计算单元,并基于该单元设计了模拟计算电路,实现一步求解压缩感知还原算法。
此外,2022年,北京大学集成电路学院与人工智能研究院黄如院士——燕博南助理教授课题组关于存内计算的的学术文章《A 1.041Mb/mm2 27.38TOPS/W Signed-INT8 Dynamic Logic Based ADC-Less SRAM Compute-In-Memory Macro in 28nm with Reconfigurable Bitwise Operation for AI and Embedded Applications》发表在ISSCC 2022上。如下图4所示,此工作提出高效的无ADC架构SRAM存内计算加速引擎,基于28nm工艺搭建模块可以达到27.38TOPS/W@INT8的高能效比,同时实现高达1.041Mb/mm2密度,达到国际领先指标并实现技术突破。
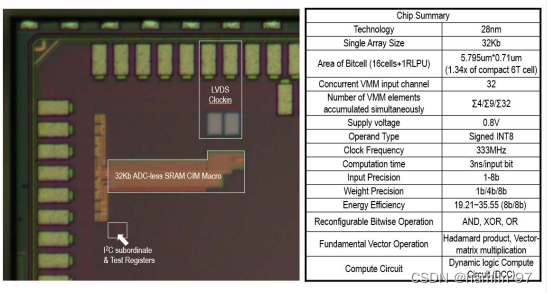
图 4 芯片显微照片和关键指标比较表[6]
(3)北京航空航天大学[7]
北京航空航天大学集成电路科学与工程学院赵巍胜教授和聂天晓教授团队瞄准科研前沿方向,长期致力于二维磁性材料及二维自旋电子器件的研究,并取得一系列进展。相关成果发表于《自然·通讯》(Nature Communications)、《先进材料》(Advanced Materials)、《应用物理评论》(Applied Physics Reviews)、《ACS–纳米》(ACS Nano)等国际知名期刊。
近日,北京航空航天大学集成电路科学与工程学院赵巍胜教授和聂天晓教授团队在室温二维磁性自旋轨道矩领域取得重要进展。相关研究成果以“Room temperature energy-efficient spin-orbit torque switching in two-dimensional van der Waals Fe3GeTe2induced by topological insulators”为题在线发表于《自然 通讯》(Nature Communications)期刊。
(4)复旦大学[8]
针对传统芯片架构的问题,复旦大学芯片与系统前沿技术研究院刘明院士团队提出了多芯粒的存算一体集成芯片——COMB-MCM(Computing-on-memory boundary – Multi-Chiplet-Module)。
相关研究成果以《COMB-MCM: Computing-on-Memory-Boundary NNProcessor with Bipolar Bit-wise Sparsity Optimization for Scalable Multi-Chiplet-Module Edge Machine Learning》被集成电路设计领域奥林比克旗舰会议——国际学术会议ISSCC 2022录用。
(二)企业商业进展[9]
在企业商业进展方面,我们列表整理不同企业近年来的一些典型成果/产品参数的模式,信息均源于企业的公开资料。由于笔者能力有限,可能未罗列全所有存算企业的优秀产品,列举的可能也并非该企业的最新产品,因为企业往往只会公开产品发布时间点对其有利的部分数据,部分以提升倍数表示的数据无法转化为具体数值,未公开的数据用“-”表示,数据带有宣传性质,请酌情采信。
表 1 企业存算一体产品总结
| 海外 | 国内 | ||||
| 品牌 | Mythic | Graphcore | 后摩 | 知存 | 千芯科技 |
| 产品名称 | M1076 AMP | Bow IPU | 鸿途H30 | WTM2101 | G40710E |
| 发布时间 | 2021年6月 | 2022年3月 | 2023年5月 | 2021 | - |
| 存储介质 | Flash | SRAM | SRAM | Flash | SRAM |
| 算力 | 25TOPS | 350TFLOPS | 256TOPS | 50Gops | 4000TOPS |
| 制程 | 40nm | 7nm | 12nm | 40nm | 7nm |
| 计算精度 | INT4、INT8 和 INT16 | FP16 | INT8 | INT8 | INT8/16 FP16/32 |
| 面积 | 19✖ 15.5mm | - | - | 2.6✖ 3.2mm² | - |
| 功耗 | 3-4w | - | 35w | 5uA-3mA | - |
| 备注 | 相比上一代IPU性能提升40%,能效提升16% | 大型AI运算加速卡定位 | 高算力低功耗定位,用于如智能可穿戴设备的智能语音和智能健康 | 大型AI运算加速卡定位 | |
下面列举部分企业产品及企业自身的详细信息,部分企业宣传材料较少且同质化严重,故没有介绍。
(1)Mythic(海外)
美国处理器公司Mythic推出M1076模拟矩阵处理器,这款模拟AI(人工智能)处理器的耗电量是传统模拟处理器的十分之一。这款处理器由72个AMP切片构成,每个切片内部集成一系列闪存单元、ADC阵列、1个32位RISC纳米处理器、1个16位SIMD矢量处理器、SRAM和1个片上网络(NOC)路由器。该M1076模拟矩阵处理器如下图5所示。
(2)Graphcore(海外)
Graphcore发布的Bow IPU采用3D Wafer-on-Wafer(WoW)技术封装,把两个晶圆结合在一起产生一个新的3D裸片,其中一个晶圆用于AI处理,另一个晶圆拥有供电裸片。在供电裸片中添加了深沟槽电容器,位于处理内核和存储旁,用于供电。内部集成1472个IPU-Core,具有600亿个晶体管,900MB的片内存储,能够处理8832个独立并行程序。
(3)后摩智能(国内)
后摩智能发布鸿途™H30存算一体智驾芯片,该芯片基于存算一体创新架构,提供高达256TOPS物理算力,可为智能驾驶,泛机器人等边缘场景提供强大的计算核心。
(4)知存科技(国内)
知存科技旗下WTM2101存算一体SoC芯片基于知存科技的存内计算技术,积累了全球化的用户经验和需求,具有低功耗、高算力、多应用的三大优势,可助力智能可穿戴设备实现产品体验升级,实现多元化和差异化的应用,大力推动智能穿戴行业创新和发展。

图 8 知存科技SoC芯片WTM2101
(来源:知存科技)
3.知存工作[1]
下面以知存科技SoC芯片WTM2101为例,简要介绍存内计算芯片应用现状。
在了解WTM2101芯片之前,我们需要简要了解“云端、边缘端、终端”的知识。随着万物互联的不断发展,智能设备主要包括3类:云端、边缘端和终端。云端设备的要求主要是高算力、大吞吐量、高可靠性,当前的存内计算进展还难以满足需求。边缘端设备,如安防、自动驾驶等,对算力、时延、功耗、安全性等具有相对综合的需求;终端设备则主要关注功耗、成本和隐私。目前存内计算芯片应用方面尚处于起步阶段,下面以知存科技推出的量产SoC芯片WTM2101为例,讨论其在边缘端和终端的应用。
WTM2101结合了RISC-V指令集与NOR Flash存内计算阵列,其阵列结构与芯片架构如图9所示,包括1.8 MB NOR Flash存内计算阵列,一个RISC-V核,一个数字计算加速器组,320kB RAM以及多种外设接口。
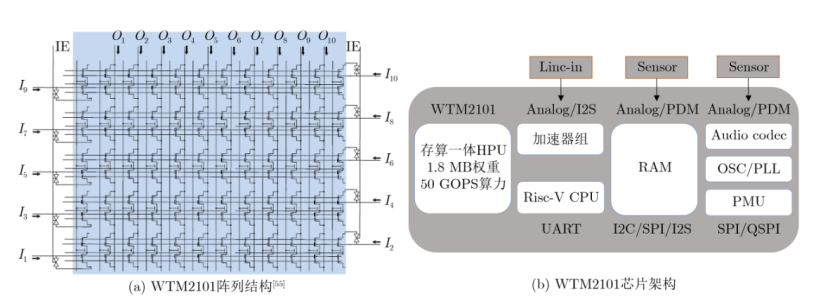
图 9 WTM2101阵列结构及芯片架构
WTM2101基于40 nm工艺制造,单个NOR Flash器件最高可存储8bit权重,可以进行8bit精度的矩阵乘加运算。从结构的角度来看,WTM2101具有4大优势特点:
1)基于存内计算架构,可高效地实现神经网络语音激活检测和上百条语音命令词识别;
2)以超低功耗实现神经网络环境降噪算法、健康监测与分析算法,典型应用场景下,工作功耗在 5uA-3mA;
3)采用2.6×3.2mm²的极小封装尺寸;
4)采用数模混合的方式实现存内计算,降低功耗和元器件成本,带来有效算力提升。
由于该芯片内集成完整的神经网络,由于终端推理与存内计算高度契合,可以执行轻量级AI应用,如语音识别、语音降噪/增强、轻量级视觉识别、健康监测和声纹识别等。
得益于该芯片极小的封装尺寸和工作功耗,WTM2101芯片可应用于智能可穿戴设备、智能家居、安防监控、玩具机器人等多种场景。
如下表2所示,相较于市场同类产品,WTM2101具有显著的性能优势,具有极大的应用潜力,期待未来以WTM2101为代表的一系列存内计算芯片产品走入市场,进入人们的生活
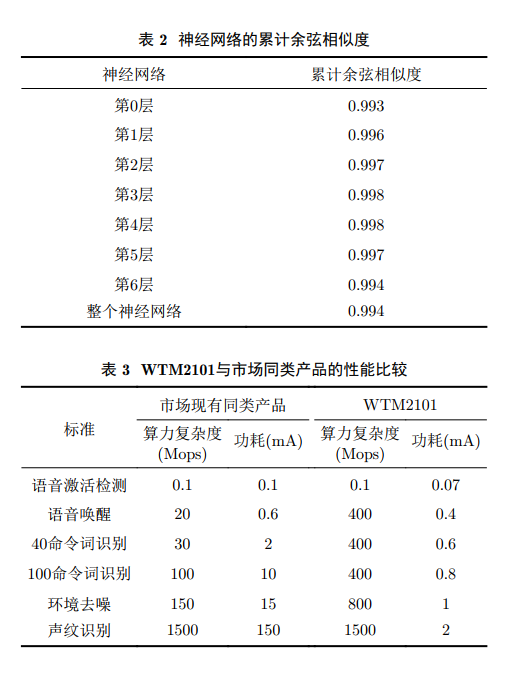
表 2 WTM2101与市场同类产品的性能比较
总之,存内计算作为一种具有巨大潜力的新型计算架构,正逐渐成为解决当前计算性能瓶颈和能耗问题的关键技术。通过将计算任务集成到存储器内部,存内计算可以有效减少数据传输带来的延迟和能耗,从而提高计算效率。虽然目前存内计算技术仍面临一些挑战,如编程模型的复杂性和硬件设计的挑战,但随着研究人员和企业的不断努力,这些难题将逐步得到解决。
在未来,我们有理由相信存内计算将在人工智能、大数据处理和物联网等领域发挥重要作用,为各行各业带来更高效、节能的计算解决方案。
参考文献
[1] 郭昕婕,王光燿,王绍迪.存内计算芯片研究进展及应用[J].电子与信息学报,2023,45(05):1888-1898.
[2] 清华大学:集成电路学院高滨课题组在支持片上学习的忆阻器存算一体芯片领域取得重要突破
[3] F. Tu et al., "A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731762.
[4] Wenbin Zhang et al. ,Edge learning using a fully integrated neuro-inspired memristor chip.Science381,1205-1211(2023).DOI:10.1126/science.ade3483
[5] 北京大学/集成电路高精尖创新中心研究团队在模拟计算领域取得重要进展
[6] B. Yan et al., "A 1.041-Mb/mm2 27.38-TOPS/W Signed-INT8 Dynamic-Logic-Based ADC-less SRAM Compute-in-Memory Macro in 28nm with Reconfigurable Bitwise Operation for AI and Embedded Applications," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 188-190, doi: 10.1109/ISSCC42614.2022.9731545.
[7] 北航集成电路科学与工程学院在《Nature Communications》期刊发表研究成果
[8] 复旦大学芯片与系统前沿技术研究院存算一体集成芯片成果亮相ISSCC 2022
[9] AI芯天下:趋势丨存算一体芯片迈进开源
[10] D. Niu et al., "184QPS/W 64Mb/mm23D Logic-to-DRAM Hybrid Bonding with Process-Near-Memory Engine for Recommendation System," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731694.

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









