







引言:
在深度学习的世界里,模型的精度和效率往往如同鱼和熊掌,难以兼得。然而,随着技术的进步,量化技术的出现为我们提供了一种平衡二者的解决方案。witin-nn,一个创新的神经网络量化部署工具,以其独特的存内计算模拟和量化感知训练(QAT),开启了深度学习模型优化的新篇章。
witin-nn框架的设计理念源于对硬件特性的深刻理解与软件优化的不懈追求。它不仅支持从8位到12位的输入和输出量化,还实现了权重的8位量化,通过精确的量化策略,显著提升了模型在硬件上的运行效率,同时最大限度地保留了模型的原始精度。
我们的框架特别适合那些对模型大小和推理速度有着严格要求的应用场景。无论是在智能手机、嵌入式设备还是边缘服务器上,witin-nn都能够提供卓越的性能。它通过模拟电路噪声和量化效应,让模型在训练阶段就适应硬件环境,从而在部署时展现出更加稳定和高效的推理能力。
witin-nn的开源特性,进一步拓宽了其应用边界。它鼓励全球的开发者和研究人员共同参与到模型优化的探索中来,分享知识,贡献代码,共同推动人工智能技术的前进。通过witin-nn,我们不仅提供了一个工具,更是搭建了一个创新和协作的平台。
Witin-NN开源链接:https://github.com/witmem/Witin-NN-Tool-
Witin-NN 技术概述:
witin_nn 框架是基于 PyTorch 开发的,witin_nn 框架主要实现了适配知存科技芯片的量化感知训练(QAT)和噪声感知训练(NAT)方法,目前支持 Linear、Conv2d、ConvTranspose2d、GruCell 等算子。本框架通过在神经网络的正向传播链路上引入输入、权重、偏置以及输出的噪声,干预神经网络的反向传播(参数更新),从而增强网络的泛化能力。具体来说,witin_nn 模拟神经网络映射到知存科技存内芯片计算的过程,支持输入和输出的 8bits~12bits 位宽量化以及权重的 8bits 量化,实现 QAT,并引入模拟电路噪声,实现 NAT。
从训练效果来看,如果以浮点训练的浮点软跑性能作为 baseline,通常在增加量化感知训练(QAT)、噪声感知训练(NAT)之后,部署到芯片的性能会更加逼近 baseline。
量化优势:
1,高效的模型压缩
2,降低能耗
3,提升运行效率
4,精度损失可控
开源项目介绍:
由于知存科技存内计算方案的模拟噪声影响,单纯经过浮点训练的神经网络模型在部署到芯片后往往会出现性能下降,因此有必要引入噪声感知训练,使得神经网络在训练过程中感知到芯片的噪声特性,从而获得部署到芯片的更好性能。
- 下面以 witin_nn.WitinLinear 算子为例,简述 QAT 及 NAT 计算的过程(输入、输出均量化到 8bits)。
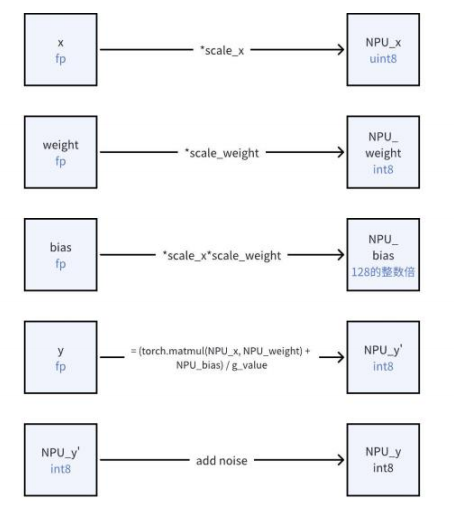
如上所示,输入 x 量化为 uint8 的 NPU_x,权重 weight 量化为 int8 的 NPU_weight,偏置 bias 量化为 128 的整数倍,即 NPU_bias,已知 NPU_x,NPU_weight,NPU_bias,可计算出 NPU_y',其中引入模拟电路噪声,得到 NPU_y,最终量化为 int8。最终,witin_nn.WitinLinear 算子输出为 NPU_y/y_scale(反量化回到浮点域)。
使用示例
1.4.1 定义一个简单的 torch 神经网络

1.4.2 witin_nn 浮点训练示例

1.4.3 witin_nn 量化训练示例

1.4.3 witin_nn 量化及加噪训练示例

2.5 量化位宽大于 8bit 指导
存算核支持的是 8bits 数据计算,但是为了提高精度,希望量化后输入位宽大于 8bits。witin_nn 将模拟映射到芯片的拆分过程(即低 8 位用模拟计算,高位用数字计 算)。需要注意的是,bias 也可能会涉及到拆分以保证映射后模拟计算的输出尽量不出 现饱和,在此引入额外参数 bias_d(d 意为 digital)来表示拆出到数字计算的偏置。
下面以 witin_nn.WitinLinear 为例,以 10bits 输入、 10bits 输出说明该过程。
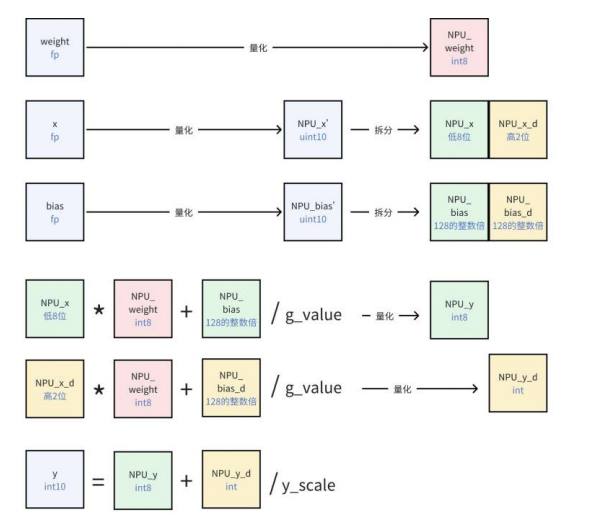
如上图所示:
(1) 对输入 x 、权重 weight 分别量化为 uint10(0~1023)、int8(-128~127)的 整型;对偏置 bias 量化为 128 的整数倍;
(2) 将量化后的 x 拆分为低 8 位 NPU_x 和高 2 位 NPU x d、量化后的 bias 拆 分为模拟计算部分的偏置 NPU_bias 和数字计算部分的偏置 NPU_bias_d;
NPU_weight 为量化后的权重。
(3) 进行计算并得到模拟计算输出 NPU_y、数字计算输出 NPU_y_d;
(4)最终输出 y 先将 NPU_y 与 NPU_y_d 求和并量化为 int10,再除以 y_scale (反量化回到浮点域)。
2.6 auto-scale 策略理解
量化方式为对称量化,按照数据的 min-max 确定量化参数,对算子的输入,输出,权 重(如果有)进行量化。
举例如下:量化一组数据,量化位宽为 int8,量化参数按如下方式确定:
| Python #量化位宽 int8 |
| x_quant_bits = 8 x = torch.randn(1,10) x_max = x.abs().max() scale_x = 2 ** (x_quant_bits - 1) / 2 ** (torch.log2(x_max).ceil()) ''' x: tensor([[ 0.1875, -1.3344, 0.5350, 1.5472, -0.9712, -1.4459, 0.1024, -0.8054, -1.7309, -0.8548]]) x_max: 1.7309 scale_x: 128 ''' |
• 在模型训练阶段,配置 use_auto_scale = True,假定训练 M 个 epoch,每个 epoch 包含 N 个 iter。
(1)在训练启动时,会预先训练 n 个 iter,量化参数 data_scale 为用户设置的初始值 (scale_x, scale_weight, scale_y)。训练期间统计数据的绝对值的最大值 data_max ,n 由用户自己配置,对应参数 auto_scale_updata_step。
(2)在训练 iter 超过 n 之后,根据 data_max 计算 data_scale,并更新 data_scale, 后续的 N-n 个 iter 的训练都将使用该 data_scale。
(3)在下一个 epoch 开始后,重复(1)(2)步,data_max 重新统计,data_scale 重 新计算。
(4)训练完成后,在保存的模型文件中,模型的每一层均包含参数 io_max,即该层的 data_max。
• 在模型推理阶段,配置 use_auto_scale = True
witin_nn 自动读取模型中的参数 io_max,并自动计算量化参数。
• 如果配置 use_auto_scale = False,量化参数固定,始终为用户配置的 scale_x, scale_weight, scale_y。
• 如果需要提取量化参数,首先要提取 io_max,再手动计算量化参数。
• 启用 auto-scale 时,需要特别注意量化参数初值的选择,过小或者过大会影响最终 scale 的确定。
总结:
具体来说,witin_nn 模拟神经网络映射到知存科技存内芯片计算的过程,支持输入和输出的 8bits~12bits 位宽量化以及权重的 8bits 量化,实现 QAT,并引入模拟电路噪声,实现 NAT。
从训练效果来看,如果以浮点训练的浮点软跑性能作为 baseline,通常在增加量化感知训练(QAT)、噪声感知训练(NAT)之后,部署到芯片的性能会更加逼近 baseline。















 3680
3680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









