






项目链接:GitHub - duanyiqun/DiffusionDepth: PyTorch Implementation of introducing diffusion approach to 3D depth perception
论文链接:https://arxiv.org/abs/2303.05021
摘要
本文介绍了DiffusionDepth,一种新的单目深度估计方法,将该任务重新表述为去噪扩散过程。该模型通过单目视觉条件的引导,迭代地将随机深度分布精细化为详细的深度图,克服了生成模型应用于稀疏真值深度场景的局限性。实验结果表明,在KITTI和NYU-Depth-V2数据集上,DiffusionDepth达到了最新的性能。
引言
单目深度估计在自动驾驶和机器人等应用中至关重要。传统方法面临过拟合和低质量深度图的问题。DiffusionDepth通过使用去噪过程,迭代地精细化深度图,捕捉粗细细节,解决了这些问题。
方法论
-
任务重述:DiffusionDepth将深度估计视为去噪过程。该模型学习将噪声深度分布转化为准确的深度图,使用输入图像的视觉引导。
-
网络架构:该框架在潜在空间中使用深度编码器和解码器,结合Swin Transformer提取的多尺度视觉特征,在扩散过程中进行引导。
-
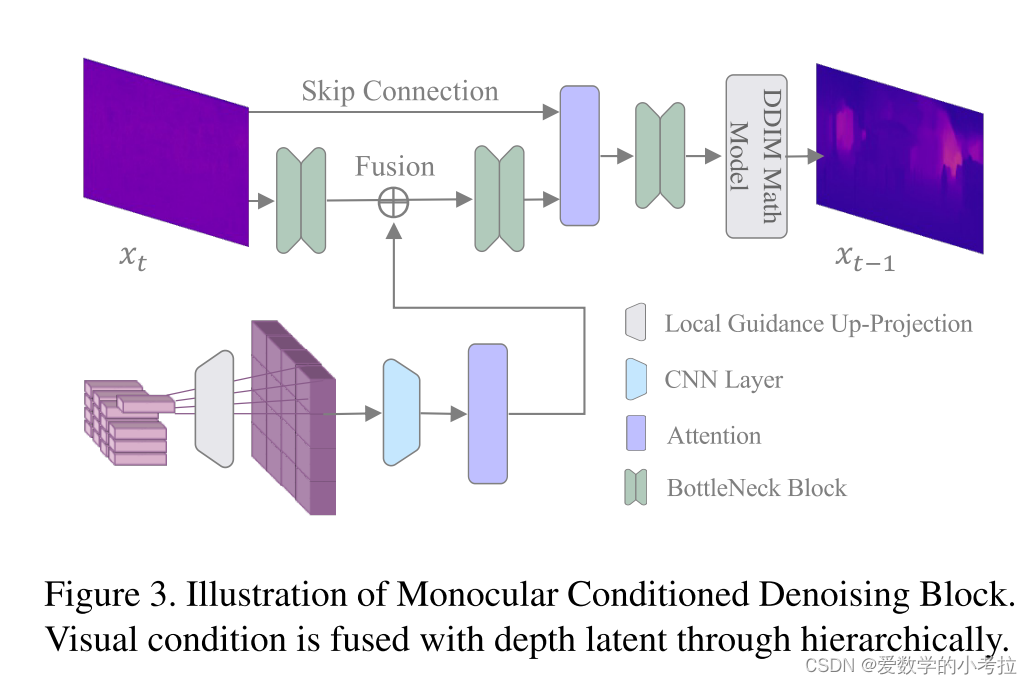
单目条件去噪块:此模块将视觉条件与深度潜在变量融合,通过迭代去噪步骤精细化深度图。
实验结果
DiffusionDepth在KITTI和NYU-Depth-V2数据集上表现出色,相比最新方法在RMSE和绝对相对误差指标上有显著提升,展示了其在室内和室外场景中的有效性。
消融研究
详细的消融研究强调了不同组件和设计选择的影响,显示了基于扩散方法的稳健性和效率。研究还揭示了使用自扩散处理稀疏真值深度数据的好处。
结论
DiffusionDepth引入了一种去噪扩散方法用于单目深度估计,生成高精度和详细的深度图。该方法的迭代精细化过程为深度估计任务提供了稳健的解决方案,并为未来3D视觉任务的研究提供了见解。
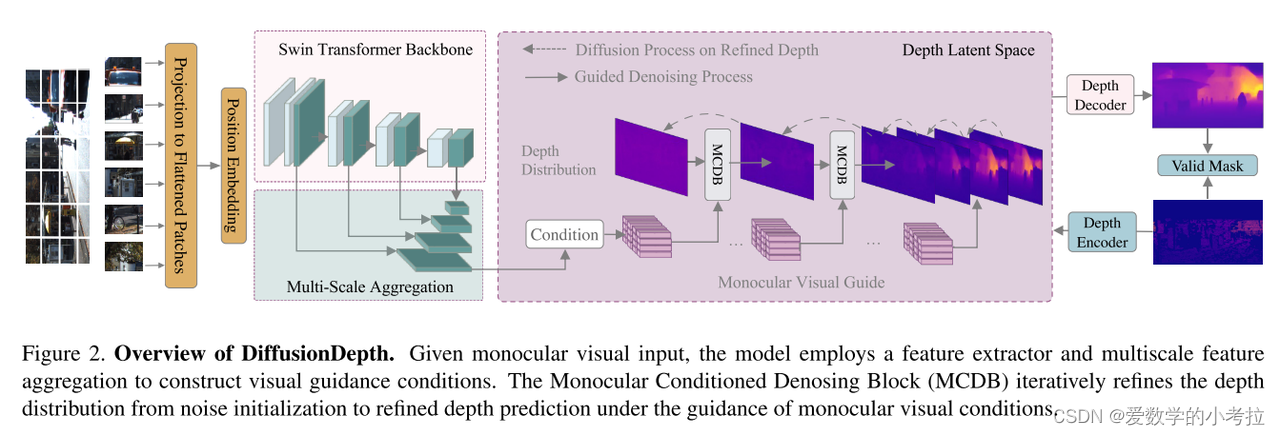
DiffusionDepth框架的工作流程
-
输入随机深度分布:
-
该框架首先接收一个随机的深度分布作为输入。这意味着输入的初始深度图是随机的,没有任何结构或信息。
-
-
迭代精细化:
-
框架通过迭代去噪步骤逐步精细化这个随机深度分布。每一步去噪过程都利用视觉条件的引导,使深度估计逐步接近真实的深度图。
-
-
潜在深度空间中的扩散-去噪过程:
-
该过程在潜在深度空间中进行,利用一个精细的编码器和解码器来表示深度特征。潜在空间是指通过编码器压缩和解码器重建的特征空间。
-
-
视觉条件的引导:
-
去噪过程由视觉条件引导,这些视觉条件通过层次结构(如图3所示)与去噪块相结合。视觉条件是从单目视觉输入中提取的多尺度特征,结合了全局和局部的相关信息。
-
-
视觉主干网络提取多尺度特征:
-
框架中的视觉主干网络(通常是一个卷积神经网络或变换器网络)从单目视觉输入中提取多尺度特征。这些特征在不同尺度上捕捉了输入图像的不同层次信息。
-
-
特征金字塔(FPN):
-
这些多尺度特征通过特征金字塔网络(FPN)进行聚合。FPN是一种用于整合多尺度特征的结构,能够有效地结合来自不同层次的信息。
-
-
全局和局部相关性的结合:
-
在特征金字塔的基础上,框架结合了全局和局部的相关性,构建了强大的单目条件。这些条件用于引导去噪过程,使得深度估计更加准确和高分辨率。
-

总结
DiffusionDepth框架通过接收一个随机深度分布作为输入,利用视觉条件引导的迭代去噪过程,在潜在深度空间中逐步精细化深度估计。该过程依赖于视觉主干网络提取的多尺度特征,并通过特征金字塔结合全局和局部信息,最终实现高分辨率和高精度的深度估计。
问题描述
-
稀疏真实深度问题:在深度预测任务中,采用生成方法的一个严重问题是稀疏的真实深度数据(GT)。这种稀疏性可能导致正常的生成训练过程中的模式崩溃(mode collapse),即模型无法生成多样化且准确的深度图。
解决方案
-
自扩散过程(self-diffusion process):为了解决这一问题,DiffusionDepth引入了自扩散过程。该过程在训练期间逐步向当前去噪输出的精细化深度潜在变量中添加噪声,而不是直接对稀疏的真实深度值进行扩散。
具体实现
-
逐步添加噪声:模型在当前去噪输出的基础上,逐步向精细化的深度潜在变量中添加噪声。这使得模型能够更好地组织整个深度图,而不仅仅是对已知部分进行回归。
-
监督机制:监督通过在深度潜在空间和像素级深度上对齐精细化深度预测与稀疏真实深度值来实现。这种对齐是通过稀疏有效掩码(sparse valid mask)进行的。
-
数据增强:在训练过程中,通过随机裁剪、抖动和翻转等数据增强手段,进一步提升模型的鲁棒性和预测质量。
监督机制的工作原理
深度潜在空间和像素级深度
深度潜在空间:这是模型内部的一种特征表示空间,包含了深度信息的高维表示。简单来说,这是模型用来理解和处理深度信息的一种内部表示。
像素级深度:这是最终生成的深度图,每个像素都有一个深度值。
精细化深度预测
在每一步迭代中,模型生成一个深度图,这个深度图会越来越接近真实深度图,这就是精细化深度预测。
稀疏真实深度值(GT)
这是实际测量得到的深度值,但这些值是稀疏的,即只有部分像素有真实深度信息。
对齐过程
在深度潜在空间的对齐
模型在深度潜在空间中生成深度表示,这些表示需要与稀疏真实深度值对应。
通过对齐模型的精细化深度预测和真实深度值,模型可以在高层次特征空间中学习到与真实深度一致的表示。
在像素级深度的对齐
对于每个有真实深度值的像素,模型生成的深度值需要与真实值对齐。
这种对齐是直接在最终生成的深度图上进行的。
稀疏有效掩码(sparse valid mask)(只计算有真实深度像素值的损失)
定义:稀疏有效掩码是一个二值矩阵,标记哪些像素具有真实深度值(这些像素在掩码中标记为有效),哪些像素没有真实深度值(这些像素在掩码中标记为无效)。
作用:在计算损失函数时,只有掩码标记为有效的像素才参与计算。这样,模型只会在有真实深度值的地方进行学习和优化。
具体实现:在训练过程中,对于每一步迭代,稀疏有效掩码会指示模型哪些像素的预测需要与真实深度值对齐。这确保了模型不会在无效像素上浪费计算资源,而是集中在有真实深度信息的像素上进行学习。
数据增强
在训练中使用随机裁剪、抖动和翻转等数据增强方法,进一步提升模型的鲁棒性和预测质量。
总结
监督机制通过在深度潜在空间和像素级深度上对齐精细化深度预测与稀疏真实深度值来实现。稀疏有效掩码确保只有那些有真实深度值的像素才参与计算和学习。这样,模型能够有效利用稀疏的真实深度数据进行训练,逐步生成高质量的深度图。这种机制使得模型在训练过程中能够从部分真实深度值中学习,并应用到整个深度图的生成中。
结果
-
视觉质量提升:这种自扩散过程使得生成模型能够更好地组织和预测整个深度图,而不是仅仅依赖稀疏的真实深度数据进行回归,从而显著提升了深度预测的视觉质量。
潜在深度空间(Latent Depth Space)
-
问题背景:许多基于约束和分类的方法在生成高分辨率深度图方面表现不佳。
-
模型结构:DiffusionDepth采用了一种类似于潜在扩散(latent diffusion)的结构,在编码的潜在深度空间中进行扩散和去噪过程。
-
潜在深度表示:精细化后的潜在深度表示 x0 的维度为 H×2W×d。
深度解码器(Depth Decoder)
-
功能:将潜在深度表示 x0 转换为最终的深度估计 de,其维度为 H×W×1。
-
组成:深度解码器由一系列连接的卷积层组成,包括1x1卷积、3x3反卷积、3x3卷积,以及Sigmoid激活函数。
-
深度计算公式:深度估计 de 的计算公式为 de=sig(x0).clamp(η)1−1,其中 η 是最大输出范围,设定为 1e6 适用于室内和室外场景。
训练过程
-
稀疏真值深度(GT)编码:考虑到稀疏的真实深度值 de^,使用具有通道维度 d 和核大小 1x1 的瓶颈卷积块(BottleNeck CNN block)将真实深度值编码为潜在深度表示 x0^。
-
监督机制:
-
像素级深度损失:通过最小化像素级深度损失 Lpixel 进行监督,公式为 Lpixel=T1∑iδi2+T2λ(∑iδi)2,其中 δi=de^−de 表示有效像素上的像素级深度误差, T 为有效像素的总数, λ 设为 0.85。
-
潜在空间损失:在潜在空间中,通过L2损失对齐编码的真实深度潜在表示 x0^ 和深度潜在表示 x0,公式为 Llatent=∥x0−x0^∥2。
-
总损失函数:综合损失函数 𝐿L 通过加权求和各部分损失计算,公式为 L=λ1Lddim+λ2Lpixel+λ3Llatent。
-
总结
通过在潜在深度空间中进行扩散和去噪,DiffusionDepth能够生成高分辨率的深度图。训练过程中,模型通过像素级和潜在空间的监督机制,利用稀疏的真实深度数据进行有效学习。稀疏有效掩码用于标记哪些像素具有真实深度值,从而确保监督的有效性。这种方法提高了深度估计的精度和质量。
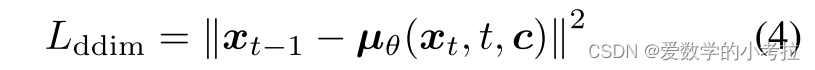
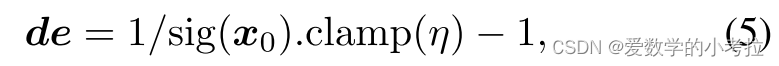
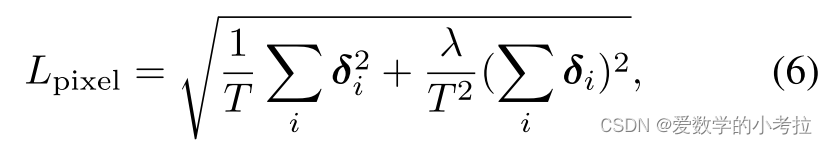
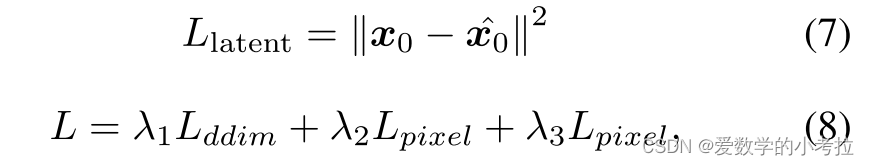
论文细节理解
motivation
-
稀疏真实深度问题:在深度预测任务中,采用生成方法的一个严重问题是稀疏的真实深度数据(GT)。这种稀疏性可能导致正常的生成训练过程中的模式崩溃(mode collapse),即模型无法生成多样化且准确的深度图。
-
现有方法:插值方法,扩散模型生成
传统的生成模型通常是从真实深度开始,通过添加噪声一步步扩散到一个随机分布,然后再从这个随机分布反向生成深度图。而DiffusionDepth模型采取了不同的策略:它从模型自己生成的精细化深度图开始,逐步添加噪声,使其变成随机深度分布,然后再学习如何从这个随机分布反向生成精细化的深度图。这种自扩散(self-diffusion)策略解决了在稀疏真实深度数据场景下使用生成模型的难题,因为模型不用依赖稀疏的真实深度数据进行训练,而是通过自己的生成结果进行训练,提升了生成深度图的质量和细节。
step1:使用模型对深度进行估计
step2:利用扩散模型对生成的深度图进行出来(在潜在空间进行扩散处理latent diffusion)

代码实现!!!


















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









