







论文链接:https://arxiv.org/abs/2412.14015
代码链接:https://promptda.github.io/
训练数据集是真实的两个数据集和两个合成的数据集(RGD+LiDAR)
文章的研究动机主要源于单目深度估计领域中存在的尺度模糊性问题。尽管现有的深度基础模型(Depth Foundation Models)在相对深度估计方面取得了显著进展,能够生成高质量的深度图,但它们在实际应用中(如自动驾驶、机器人操作等)面临一个关键挑战:无法直接输出与真实世界一致的度量深度(Metric Depth)。换句话说,这些模型无法准确估计物体到相机的真实距离,因为它们缺乏对绝对尺度的感知能力。
为了解决这一问题,研究者们尝试通过微调(fine-tuning)深度模型或引入额外的输入(如相机内参)来实现度量深度估计,但这些方法仍存在局限性,无法完全解决尺度模糊性问题。因此,文章提出了一种新的思路:借鉴自然语言处理和视觉领域中提示(Prompting)技术的成功经验,将深度基础模型与外部的度量信息(如低成本LiDAR)结合,以实现高精度的度量深度估计。
研究的核心思想
文章的核心思想是将度量深度估计任务视为一种提示(Prompting)任务,通过向深度基础模型提供一个“提示”(即低成本LiDAR的深度信息),引导模型输出准确的度量深度。具体而言,研究者们提出了**Prompt Depth Anything(PDA)**方法,其核心思想包括以下几点:
-
提示融合架构(Prompt Fusion Architecture):
-
PDA通过一个简洁的提示融合模块,将低成本LiDAR的深度信息整合到深度基础模型的解码器中。这种融合方式不仅保留了深度基础模型的泛化能力,还通过LiDAR的度量信息解决了尺度模糊性问题。
-
-
多尺度提示整合:
-
提示融合模块在多个尺度上整合LiDAR深度信息,使得模型能够在不同分辨率下学习深度特征,从而提高深度估计的精度和鲁棒性。
-
-
可扩展的数据管道(Scalable Data Pipeline):
-
为了训练PDA模型,研究者们设计了一个可扩展的数据管道,包括合成数据的LiDAR模拟和真实数据的伪GT深度生成。这解决了现有数据集中缺乏同时包含LiDAR深度和精确GT深度的问题。
-
-
边缘感知深度损失(Edge-aware Depth Loss):
-
为了充分利用真实数据中的高质量边缘信息,文章提出了一种边缘感知深度损失函数。该损失函数结合了伪GT深度的梯度信息和高质量GT深度的整体信息,使得模型能够更好地学习物体边缘和纹理区域的深度。
-
研究的贡献
文章的主要贡献可以总结为以下几点:
-
提出了一种新的度量深度估计范式:
-
Prompt Depth Anything(PDA)是首次将提示技术引入深度估计领域,通过低成本LiDAR作为提示,实现了高精度的度量深度估计。这一范式为解决深度估计中的尺度模糊性问题提供了新的思路。
-
-
简洁高效的提示融合架构:
-
PDA设计了一个简洁的提示融合模块,仅增加了5.7%的计算开销,同时显著提高了深度估计的精度。这种融合架构能够充分利用深度基础模型的泛化能力和LiDAR的度量信息。
-
-
可扩展的数据管道和损失函数设计:
-
文章提出的可扩展数据管道和边缘感知深度损失函数,解决了训练数据有限的问题,并提高了模型在真实场景中的性能。
-
-
在多个数据集上取得新的最佳性能:
-
PDA在ARKitScenes和ScanNet++等数据集上取得了新的最佳性能,展示了其在高分辨率(4K)度量深度估计任务中的优越性。
-
-
良好的泛化能力和下游任务应用:
-
PDA不仅在室内场景中表现出色,还能够泛化到室外场景、动态场景以及不同分辨率的图像。此外,PDA在3D重建和机器人抓取等下游任务中也展示了其实际应用价值。
-
总结
文章通过将提示技术引入深度估计领域,提出了一种新的度量深度估计方法Prompt Depth Anything(PDA)。这种方法不仅解决了深度基础模型中的尺度模糊性问题,还通过简洁的提示融合架构和可扩展的数据管道,实现了高精度、高分辨率的度量深度估计。PDA在多个数据集上取得了优异的性能,并展示了良好的泛化能力和实际应用价值,为未来深度估计的研究提供了新的方向。
Introduction
-
引出问题:
-
高质量深度感知是计算机视觉和机器人领域的基础挑战。
-
单目深度估计近年来取得进展,但存在尺度模糊性,限制了其在自动驾驶和机器人操作中的应用。
-
-
现有方法的局限性:
-
当前解决尺度模糊性的方法(如微调或引入相机内参)未能完全解决问题。
-
-
提出新思路:
-
借鉴自然语言和视觉领域中**预训练和提示(Prompting)**的成功经验,提出将度量深度估计视为下游任务,通过提示基础模型来解决尺度模糊性。
-
-
介绍方法:
-
提出Prompt Depth Anything(PDA),基于Depth Anything模型,通过融合低成本LiDAR深度信息实现高精度度量深度估计。
-
-
解决训练数据问题:
-
提出可扩展数据管道:
-
为合成数据模拟LiDAR深度。
-
为真实数据生成高质量边缘的伪GT深度。
-
引入边缘感知深度损失以减少误差。
-
-
-
验证与贡献:
-
在ARKitScenes和ScanNet++数据集上验证PDA,展示其在度量深度估计中的优越性能和泛化能力。
-
提出的主要贡献:
-
提出PDA新范式。
-
设计简洁的提示融合架构、数据管道和损失函数。
-
展示在下游任务(如3D重建和机器人抓取)中的应用潜力。
-
-
问题引出 → 2. 现有方法的局限性 → 3. 提出新思路 → 4. 介绍方法 → 5. 解决训练数据问题 → 6. 验证与贡献
Overview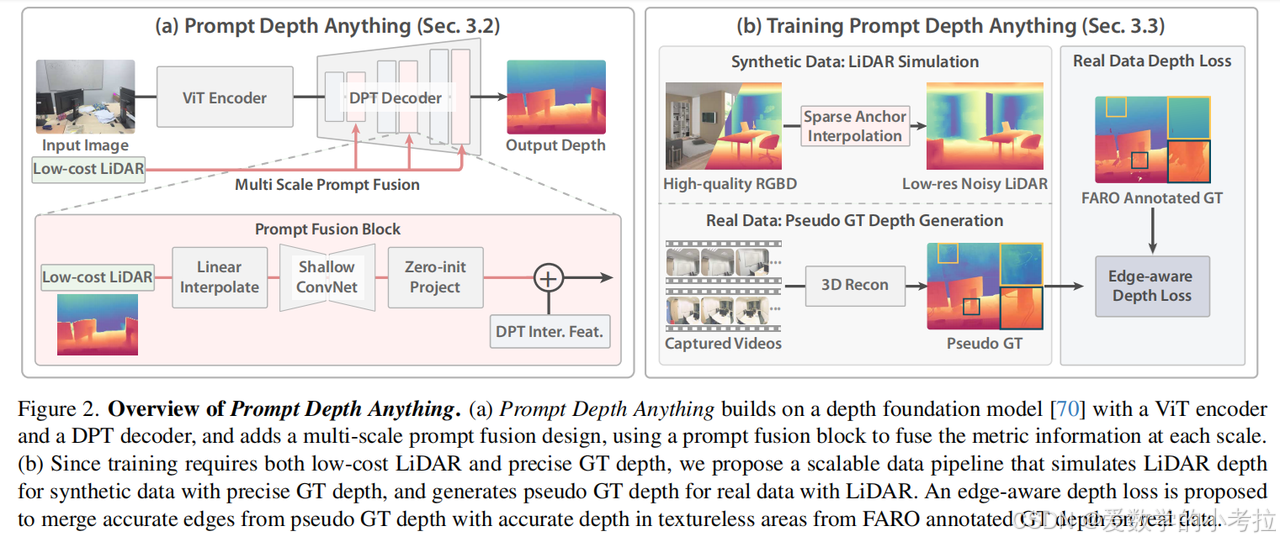
(a) Prompt Depth Anything (Sec. 3.2)
整体架构
-
输入图像(Input Image):
-
PDA方法的输入是一张RGB图像。
-
-
ViT Encoder(视觉Transformer编码器):
-
使用ViT(Vision Transformer)编码器对输入图像进行特征提取。ViT编码器通过多阶段的Transformer模块,将图像分割成多个patch,并提取这些patch的特征。
-
-
DPT Decoder(DPT解码器):
-
DPT(Dense Prediction Transformer)解码器将ViT编码器提取的特征重新组装成图像级别的表示。DPT解码器通过多尺度特征融合,生成最终的深度图。
-
-
Multi-scale Prompt Fusion(多尺度提示融合):
-
这是PDA的核心模块,用于将低成本LiDAR深度信息融合到DPT解码器中。通过多尺度提示融合模块,LiDAR深度信息在解码器的多个尺度上被整合,以指导深度解码。
-
-
Output Depth(输出深度):
-
最终输出的深度图,具有高分辨率和高精度的度量深度。
-
详细模块
-
Prompt Fusion Block(提示融合块):
-
Linear Interpolate(线性插值):将低分辨率的LiDAR深度图插值到与当前尺度相同的分辨率。
-
Shallow ConvNet(浅层卷积网络):通过浅层卷积网络提取LiDAR深度图的特征。
-
Zero-init Project(零初始化投影):将提取的LiDAR特征投影到与图像特征相同的维度,使用零初始化以确保初始输出与基础模型一致。
-
DPT Inter. Feat.(DPT中间特征):将投影后的LiDAR特征与DPT解码器的中间特征相加,进行深度解码。
-
(b) Training Prompt Depth Anything (Sec. 3.3)
训练流程
-
合成数据:LiDAR模拟(Synthetic Data: LiDAR Simulation):
-
High-quality RGBD(高质量RGBD数据):使用合成数据集(如HyperSim [51]),这些数据集包含高质量的RGB图像和精确的GT深度。
-
Sparse Anchor Interpolation(稀疏锚点插值):通过稀疏锚点插值方法模拟低分辨率、带噪声的LiDAR深度图。具体步骤包括:
-
将GT深度图降采样到低分辨率(如192×256)。
-
使用扭曲的网格采样选择一些锚点,剩余的深度值通过RGB相似性(如KNN算法)插值得到。
-
-
-
真实数据:伪GT深度生成(Real Data: Pseudo GT Depth Generation):
-
Captured Videos(捕获的视频):使用真实数据集(如ScanNet++ [72]),这些数据集包含iPhone LiDAR数据和FARO LiDAR扫描的注释深度。
-
3D Recon(3D重建):使用3D重建方法(如Zip-NeRF [2])生成伪GT深度图。具体步骤包括:
-
从视频中检测无模糊帧,并使用DSLR视频提供高分辨率的多视角图像。
-
使用Zip-NeRF对每个场景进行训练,重新渲染伪GT深度图。
-
-
Pseudo GT(伪GT深度):生成的伪GT深度图具有高质量的边缘信息。
-
-
真实数据:深度损失(Real Data Depth Loss):
-
FARO Annotated GT(FARO注释的GT深度):使用FARO LiDAR扫描的高质量深度注释。
-
Edge-aware Depth Loss(边缘感知深度损失):为了减少3D重建带来的误差,提出了一种利用伪GT深度梯度信息的损失函数。
-
总结
-
Prompt Depth Anything(PDA):
-
通过将低成本LiDAR深度信息作为提示,融合到深度基础模型中,实现高精度的度量深度估计。
-
使用多尺度提示融合模块,将LiDAR深度信息在多个尺度上整合到DPT解码器中。
-
-
训练流程:
-
通过合成数据的LiDAR模拟和真实数据的伪GT深度生成,解决训练数据不足的问题。
-
引入边缘感知深度损失函数,减少3D重建带来的误差,提高深度估计的准确性。
-
这张流程图清晰地展示了PDA方法的整体架构和训练过程,帮助理解如何通过提示融合和数据管道实现高精度的度量深度估计。
存在的问题
-
传统方法的局限性:
-
传统方法依赖于手工设计的特征,泛化能力有限,通常局限于特定的场景或数据集。
-
-
深度学习方法的泛化问题:
-
尽管深度学习方法通过多样化数据集和更强大的网络架构提高了泛化能力,但它们仍然无法解决尺度模糊性问题,无法准确估计物体到相机的真实距离。
-
-
潜在扩散模型的局限性:
-
潜在扩散模型在相对深度估计方面表现出色,但它们仍然无法解决尺度模糊性问题,无法提供与真实世界一致的绝对深度值。
-
-
度量深度估计的挑战:
-
早期的度量深度估计方法通过全局分布分类或在度量深度数据集上微调深度模型,但这些方法仍然无法完全解决尺度模糊性问题。
-
最近的方法通过引入相机内参等方法解决单目度量深度估计中的模糊性问题,但这些方法仍然存在局限性,无法在所有场景中实现高精度的度量深度估计。
-
-
深度基础模型的固有模糊性:
-
尽管深度基础模型通过大规模数据训练具备了很强的泛化能力,但由于固有的模糊性(如尺度模糊性),它们在度量深度估计方面仍然存在挑战,无法准确估计物体到相机的真实距离。
-


















 3798
3798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









