












代码地址:GitHub - lllyasviel/ControlNet: Let us control diffusion models!
摘要
-
ControlNet架构的目的:
-
为大型预训练的文本到图像扩散模型添加空间条件控制功能。
-
-
ControlNet的核心设计:
-
锁定已有模型:ControlNet锁定了已经生产就绪的大型扩散模型,意味着这些模型的基本参数不再改变。
-
重用编码层:使用这些模型已预训练的深层和稳健的编码层作为学习多样化条件控制的强大基础。
-
-
特殊技术—零卷积:
-
使用“零卷积”(即参数从零开始逐步增长的卷积层),以确保训练过程中不引入有害噪声,保护模型在微调过程中的稳定性。
-
-
条件控制的应用测试:
-
测试了不同的条件控制,如边缘、深度、分割、人体姿态等。
-
使用Stable Diffusion模型进行测试,条件可单独或多重应用,可结合文本提示或不使用文本提示。
-
-
训练的稳健性:
-
显示ControlNet的训练在不同规模的数据集上(小于50k和超过1m的数据集)均表现出良好的稳健性。
-
-
广泛的应用潜力:
-
展示了ControlNet可能促进更广泛的应用,用于控制图像扩散模型的生成过程。
-
ControlNet主要有两点创新:
1.使用Stable Diffusion并冻结其参数,同时copy一份SDEncoder的副本,这个副本的参数是可训练的。这样做的好处有两个:
a.制作这样的副本而不是直接训练原始权重的目的是为了避免在数据集很小时的过拟合,同时保持了从数十亿张图像中学习到的大模型质量。
b.由于原始的权值被锁定了,所以不需要对原始的编码器进行梯度计算来进行训练。这可以加快训练速度;因为不用计算原始模型上参数的梯度,所以节省了GPU内存。
2.零卷积 :即初始权重和bias都是零的卷积。在副本中每层增加一个零卷积与原始网络的对应层相连。在第一步训练中,神经网络块的可训练副本和锁定副本的所有输入和输出都是一致的,就好像ControlNet不存在一样。换句话说,在任何优化之前,ControlNet都不会对深度神经特征造成任何影响,任何进一步的优化都会使模型性能提升,并且训练速度很快。
-
问题陈述:
-
当前的文本到图像扩散模型在控制图像的空间组成方面存在限制,难以通过文本提示精确表达复杂的布局、姿态、形状和形式。这通常需要多次试错,通过编辑提示、检查生成的图像然后重新编辑来匹配我们的心理图像。
-
-
提出解决方案的需求:
-
提出是否可以通过让用户提供直接指定他们所需图像组成的附加图像(如边缘图、人体姿态骨架、分割图等)来实现更精细的空间控制。
-
讨论了如何通过图像到图像的转换模型来学习从条件图像到目标图像的映射。
-
-
面临的挑战:
-
条件控制的训练数据可能远小于一般文本到图像训练用的数据量,这可能导致过拟合和灾难性遗忘。文中提到了通过限制可训练参数的数量或等级来缓解这种遗忘。
-
-
ControlNet的设计和实施:
-
ControlNet是一个端到端的神经网络架构,用于为大型预训练的文本到图像扩散模型(例如Stable Diffusion)学习条件控制。
-
该架构通过锁定大模型的参数,并创建一个可训练的编码层副本来实现。这些层通过零卷积层连接,权重从零开始,逐步增长,以确保训练初期不引入有害噪声。
-
-
实验和应用:
-
展示了ControlNet在多种条件输入(如Canny边缘、霍夫线等)下控制Stable Diffusion的能力,无论是单一条件还是多重条件。
-
报告了ControlNet在不同大小数据集上的训练是稳健和可扩展的,甚至在单个GPU上的训练也能与大规模计算集群训练的工业模型竞争。
-
-
总结和展望:
-
提出了ControlNet,这是一种可以通过有效的微调将局部输入条件添加到预训练的文本到图像扩散模型中的神经网络架构。
-
展示了预训练的ControlNets如何控制多种条件,并通过用户研究与其他架构比较验证了方法的有效性。
-
贡献
-
ControlNet的提议:
-
提出了ControlNet,这是一个神经网络架构,可以通过有效的微调将空间定位的输入条件添加到预训练的文本到图像扩散模型中。这使得模型能够更精确地控制图像的生成,根据具体的空间条件调整输出。
-
-
ControlNet的实现和应用:
-
展示了预训练的ControlNet如何控制Stable Diffusion模型,以响应多种不同的条件输入,包括Canny边缘、霍夫线、用户涂鸦、人体关键点、分割图、形状法线、深度和卡通线条图。这表明ControlNet能够处理和融合多样化的视觉信息来生成图像。
-
-
方法的验证和用户研究:
-
通过消融实验和与其他架构的比较验证了ControlNet的有效性。同时,进行了针对不同任务的用户研究,这些研究集中于评估ControlNet与先前基线相比的表现。这些实验和用户研究帮助进一步证实了ControlNet在实际应用中的实用性和效果。
-
相关工作
2.1 微调神经网络的常规方法:
继续使用额外的训练数据对神经网络进行训练是一种常见方法,但这可能导致过拟合、模式崩溃和灾难性遗忘。
-
避免问题的先进策略:
-
HyperNetworks:最初用于自然语言处理,通过训练一个小型递归网络来影响更大网络的权重。已被应用于通过生成对抗网络(GANs)来生成图像,并用于改变Stable Diffusion的艺术风格。
-
Adapter方法:在自然语言处理中广泛用于通过添加新的模块层来定制预训练的转换模型,应用于计算机视觉中的增量学习和领域适应。
-
Additive Learning:通过冻结原始模型的权重并添加少量新参数来避免遗忘,使用了学习的权重掩码、剪枝或硬注意力。
-
Side-Tuning:通过在冻结模型和添加的网络之间线性混合输出,使用侧分支模型来学习额外的功能。
-
Low-Rank Adaptation (LoRA):通过低秩矩阵学习参数的偏移量来防止灾难性遗忘,基于过度参数化模型通常存在于低本质维度子空间的观察。
-
-
Zero-Initialized Layers:
-
在ControlNet中用于连接网络块,涉及到网络权重的初始化和操控。研究表明,与零初始化相比,高斯初始化可能风险较低。在Stable Diffusion模型中,对卷积层的初始权重进行缩放以改善训练效果,零模块是将权重缩放到零的极端案例。
-
2.2 图像扩散模型
-
图像扩散模型的发展:
-
图像扩散模型由Sohl-Dickstein等人首次提出,并已被广泛应用于图像生成。
-
潜在扩散模型(LDM)在潜在图像空间执行扩散步骤,降低了计算成本。
-
文本到图像的扩散模型如Stable Diffusion和Imagen通过编码文本输入到潜在向量实现了先进的图像生成。
-
-
控制图像扩散模型:
-
图像扩散过程提供了对颜色变化和图像修复的直接控制。
-
通过调整提示、操纵CLIP特征和修改交叉注意力等方法进行文本引导控制。
-
MakeAScene、SpaText和GLIGEN等工具通过编码分割掩码到令牌或学习新的注意力层参数来控制图像生成。
-
Textual Inversion和DreamBooth通过微调扩散模型和用户提供的示例图片来个性化生成内容。
-
Voynov等人提出了一个与草图相匹配的优化扩散过程方法。
-
2.3 图像到图像的转换
-
条件GAN和变换器:
-
条件GAN(如CocosNet v2)和变换器(如Taming Transformer和Palette)学习不同图像域之间的映射。
-
特定图像到图像的任务可以通过操纵预训练的GAN来处理,例如通过额外的编码器控制StyleGANs。
-
-
特定应用和技术:
-
PITI是基于预训练的条件扩散模型,用于图像到图像的转换。
-
StyleGANs等模型被用于通过添加额外的编码器来控制生成的图像,扩展了其应用范围。
-
Method
3.1 ControlNet
-
网络块的定义与功能:
-
网络块指的是神经网络中常见的几个神经层组成的单元,例如ResNet块、卷积-批标准化-ReLU块、多头注意力块、变换器块等。
-
这些块处理输入特征图 x,并转换成输出特征图 y,表示为 y=F(x;Θ)。
-
-
ControlNet的架构设计:
-
在引入ControlNet时,原始的神经块 Θ 被锁定(冻结),同时复制出一个可训练的副本 Θc。
-
可训练副本接收一个外部的条件向量 c,用于调整其对特定条件的响应。
-
-
零卷积层的实现与作用:
-
使用零初始化的1×1卷积层(零卷积层),标记为 Z(⋅;⋅),连接原始块和可训练副本。
-
在ControlNet的结构中,包括两个零卷积层 Θz1 和 Θz2,它们帮助在保护模型稳定性的同时融合外部条件。
-
零卷积层在训练初期防止随机噪声影响模型,保证 yc=y。
-
-
模型的计算与保护:
-
ControlNet的输出 yc 通过以下公式计算:yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
-
由于零卷积层的权重和偏置初始化为零,确保训练开始时不引入有害噪声,使得可训练副本在保留原模型功能的同时,可以灵活适应新的输入条件。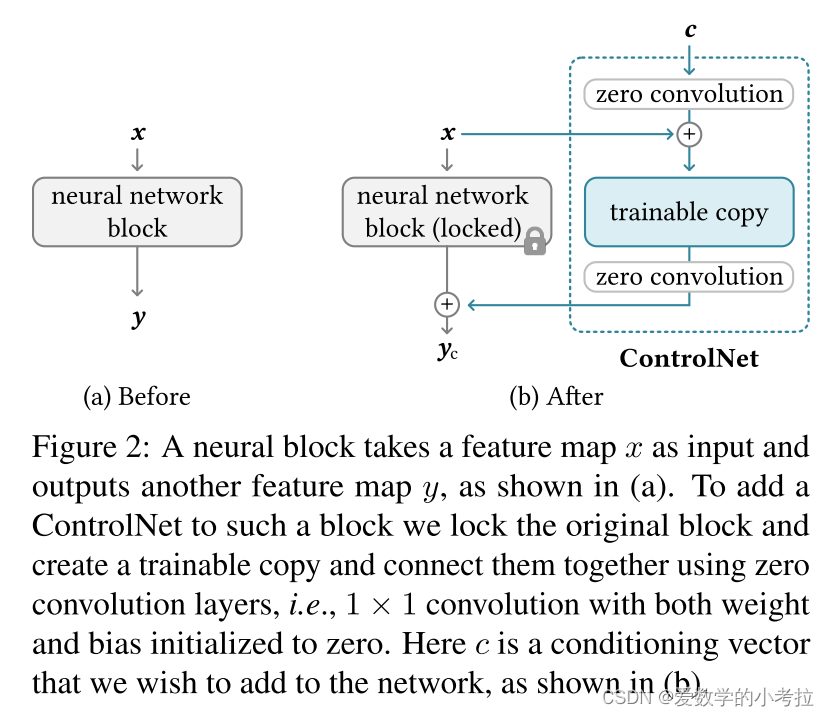
3.2 ControlNet应用于文本到图像的扩散过程
-
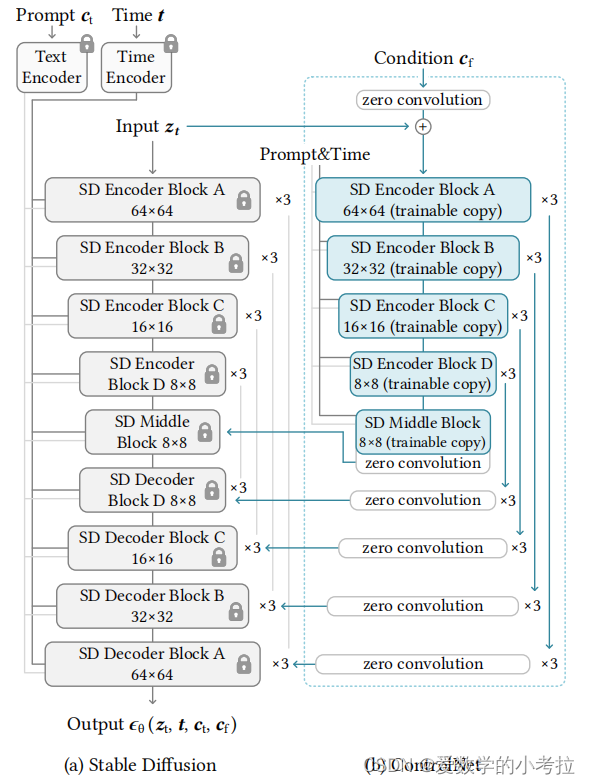
Stable Diffusion模型概述:
-
Stable Diffusion是基于U-Net架构,包含一个编码器、一个中间块和一个带跳跃连接的解码器。
-
模型共包含25个块,其中8个块为下采样或上采样卷积层,其余17个为包含4个ResNet层和2个视觉变换器(ViTs)的主要块。每个ViT包含多个交叉注意力和自注意力机制。
-
-
ControlNet的结构和集成方式:
-
ControlNet被应用到U-net的每个编码层,特别地,为Stable Diffusion的12个编码块和1个中间块创建了可训练的副本。
-
这些编码块以四种分辨率存在(64x64, 32x32, 16x16, 8x8),每个分辨率重复三次,并将输出加到12个跳跃连接和1个中间块。
-
-
计算效率和资源优化:
-
由于锁定副本的参数被冻结,微调时不需要在原始锁定编码器中进行梯度计算,这种方法加快了训练速度并节省了GPU内存。
-
在NVIDIA A100 PCIE 40GB上测试,与未使用ControlNet的Stable Diffusion相比,使用ControlNet优化Stable Diffusion只需要增加大约23%的GPU内存和34%的训练时间。
-
-
图像扩散和条件控制的实现:
-
Stable Diffusion通常在潜在空间中进行训练,使用类似于VQ-GAN的预处理方法将512×512像素空间图像转换为64×64的潜在图像,以稳定训练过程。
-
为将ControlNet加入到Stable Diffusion中,首先将每个输入条件图像(如边缘、姿态、深度等)从512×512转换为与Stable Diffusion大小匹配的64×64特征空间向量。
-
使用一个包含四个卷积层的小型网络E(·)(使用ReLU激活,初始化为高斯权重,并与整个模型一起训练)来编码图像空间条件ci到特征空间条件向量cf。
-
-
条件向量的传递和应用:
-
条件向量cf被传递到ControlNet中,参与调整生成图像的条件控制过程。
-

3.3 训练过程
-
图像扩散算法的基本原理:
-
输入图像 z0 经过扩散算法逐步添加噪声,生成噪声图像 zt,其中 t 表示噪声添加的次数。
-
扩散算法考虑时间步长 t、文本提示 ct 以及特定任务的条件 cf,学习一个网络 ϵθ,来预测添加到噪声图像 zt 的噪声。
-
学习目标 L 通过最小化预测噪声与实际噪声之间的差异来定义,即:
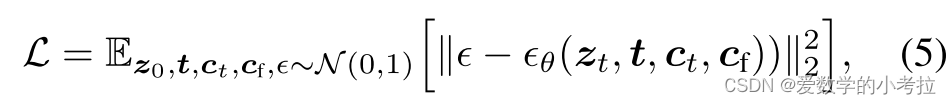
-
微调扩散模型的实施:
-
该学习目标直接用于使用ControlNet微调扩散模型。
-
-
训练过程中的文本提示处理:
-
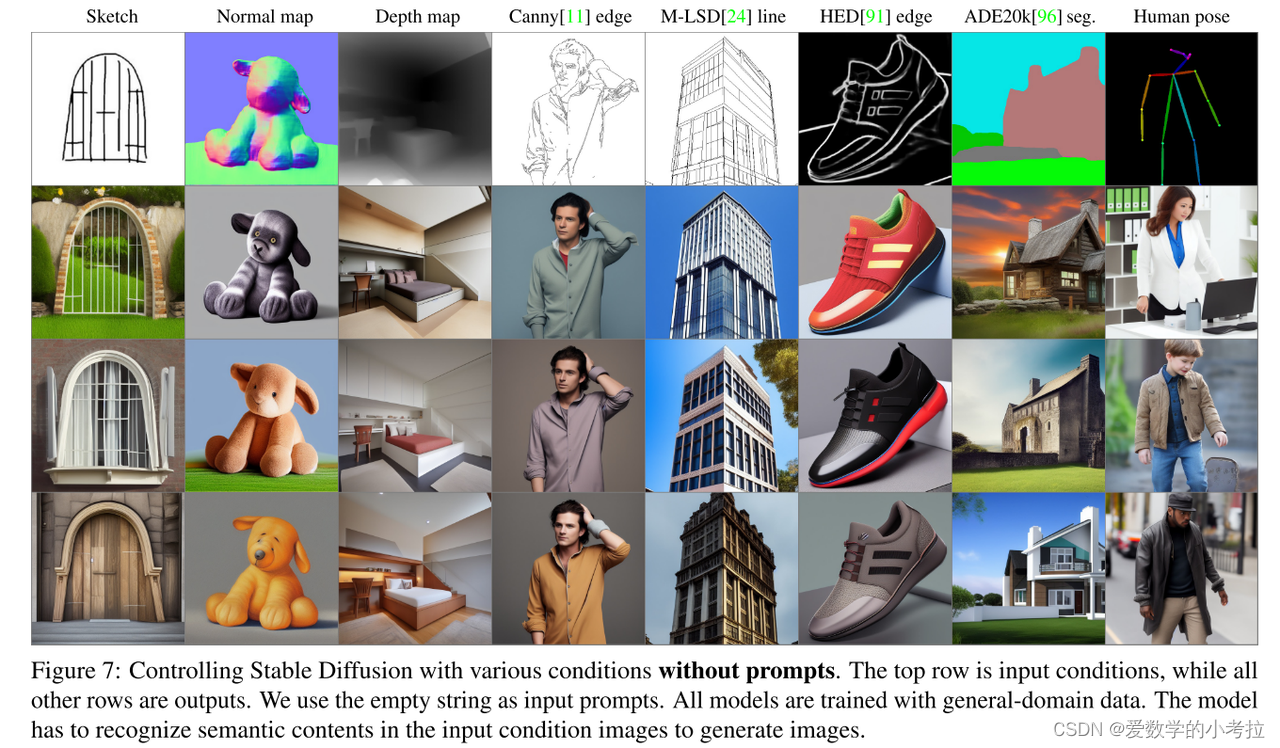
在训练过程中,随机将50%的文本提示 ct 替换为空字符串,这增强了ControlNet直接从输入条件图像(如边缘、姿势、深度等)识别语义的能力,代替了文本提示。
-
-
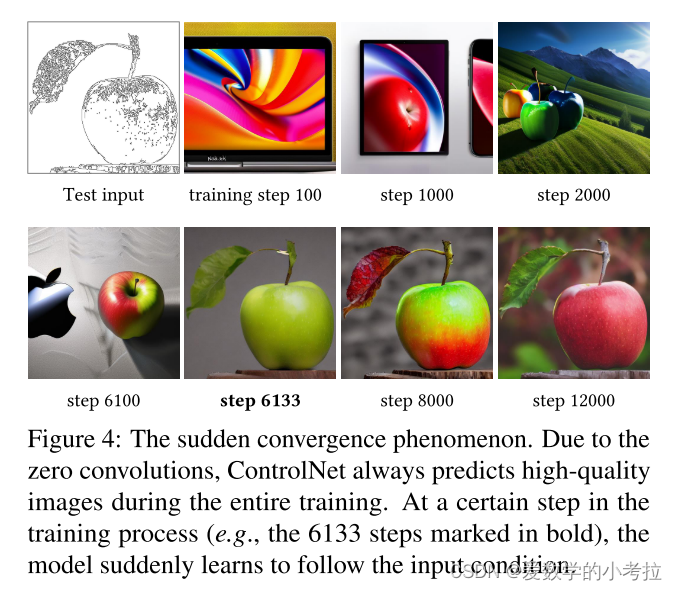
训练过程中的突然收敛现象:
-
由于零卷积层不向网络添加噪声,模型应始终能够预测高质量的图像。
-
观察到模型不是逐渐学习控制条件,而是在通常不到10K的优化步骤中突然成功地跟随输入的条件图像,这种现象称为“突然收敛现象”。
-
3.4 推断过程
-
基于分类器的无指导分辨率加权:
-
Stable Diffusion依赖于一种称为Classifier-Free Guidance (CFG)的技术来生成高质量的图像。
-
CFG公式化为 ϵprd=ϵuc+βcfg(ϵc−ϵuc),其中 ϵprd是模型的最终输出,ϵuc是无条件输出,ϵc是有条件输出,βcfg是用户指定的权重。
-
当通过ControlNet添加条件图像时,可以将其同时添加到 ϵuc 和 ϵc,或者仅添加到 ϵc。
-
我们的解决方案是首先将条件图像添加到 ϵc,然后根据每个块的分辨率 hi (h1 = 8, h2 = 16, ..., h13 = 64)为 Stable Diffusion 和 ControlNet 之间的每个连接乘以一个权重 wi=hi64。
-
通过降低 CFG 引导的强度,可以实现如图5d所示的结果,我们将其称为 CFG 分辨率加权。
-

-
组合多个ControlNet:
-
要将多个条件图像(例如,Canny边缘和姿势)应用于单个 Stable Diffusion 实例,可以直接将相应的ControlNet的输出添加到 Stable Diffusion 模型中。
-
对于这种组合,不需要额外的加权或线性插值。
-

结论
















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









