






我们用最简单的线性回归模型去说明深度学习的工作流程,感受和理解什么是前向传播和反向传播。
目录
线性回归模型
线性回归模型的函数是 y-hat = wx + b,其中 y-hat 就是预测值,y 是真实值。
loss function = (y-hat - y)**2,
则 cost function = (y-hat - y)**2 / m
(假设有 m 个输入数据)
数据集
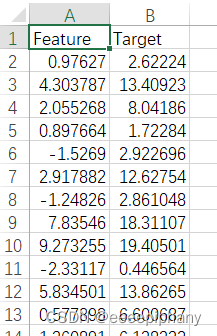
训练用的数据集是让 ai 生成的,其中一部分内容如下:
像不像一个一个的坐标点
全部代码
import numpy as np
# 计算给定点的平均误差
def calculate_average_error(b, w, points):
error_sum = 0.0
for i in range(len(points)):
x = points[i, 0]
y = points[i, 1]
error_sum += (y - (w * x + b)) ** 2
return error_sum / len(points)
# 执行梯度下降算法
def run_gradient_descent(points, starting_b, starting_w, learning_rate, num_iterations):
b = starting_b
w = starting_w
for i in range(num_iterations):
b_gradient = 0
w_gradient = 0
for j in range(len(points)):
x = points[j, 0]
y = points[j, 1]
b_gradient += -(2/len(points)) * (y - (w * x + b)) # 求出 b 的平均梯度
w_gradient += -(2/len(points)) * x * (y - (w * x + b)) # 求出 w 的平均梯度
b -= learning_rate * b_gradient # 更新 b 的值
w -= learning_rate * w_gradient # 更新 w 的值
return b, w
# 主程序
def main():
points = np.genfromtxt("data.csv", delimiter=",") # 读取数据点
learning_rate = 0.0001
initial_b = 0
initial_w = 0
num_iterations = 1000
initial_error = calculate_average_error(initial_b, initial_w, points)
print(f"Starting gradient descent at b = {initial_b}, w = {initial_w}, initial average error = {initial_error}")
print("Running...")
b, w = run_gradient_descent(points, initial_b, initial_w, learning_rate, num_iterations)
final_error = calculate_average_error(b, w, points)
print(f"After {num_iterations} iterations, b = {b}, w = {w}, final average error = {final_error}")
if __name__ == '__main__':
main()上面代码看到比较复杂,我们简化一下,即大致流程如下:
main (){
run_gradient_descent(...){
for i in range(num_iterations){
for i in 坐标点的数量 {
求 w 和 b 的平均梯度
}
}
}里面的 for 循环是用来求 w 和 b 平均梯度的;
外面的 for 循环是用来更新 w 和 b 的值的。
形象说明
上述代码更形象的说明:
(假设有 m 个坐标点)

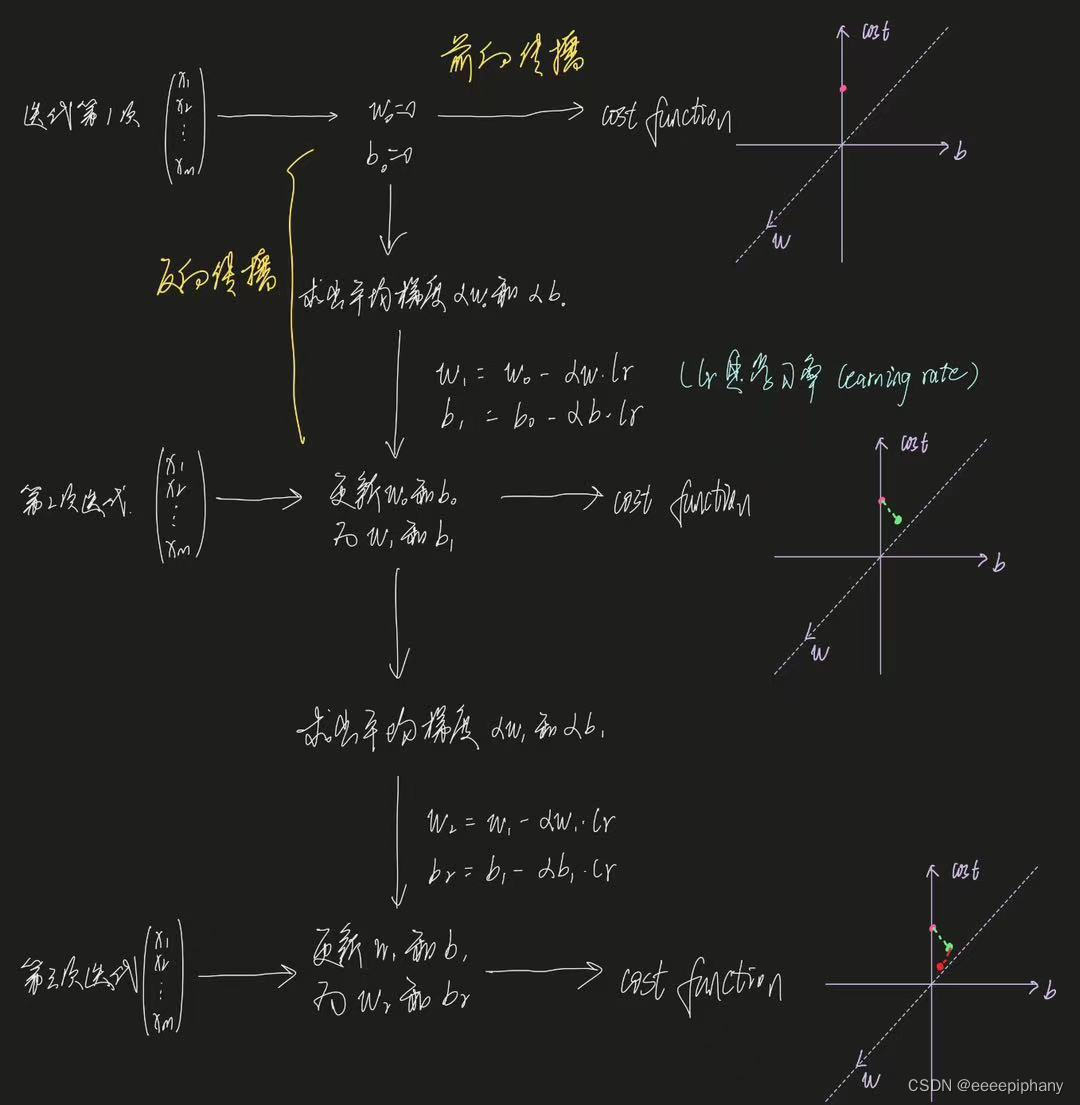
其中,
- 输入数据,根据当前迭代次数中的 w 和 b 求出 y-hat(预测值),再求出 loss function 的过程就是正向传播的过程
- 每次迭代中根据求出来的平均梯度 αw 和 αb,求出新的 w 和 b 的过程就是反向传播的过程。
full batch 和 mini batch
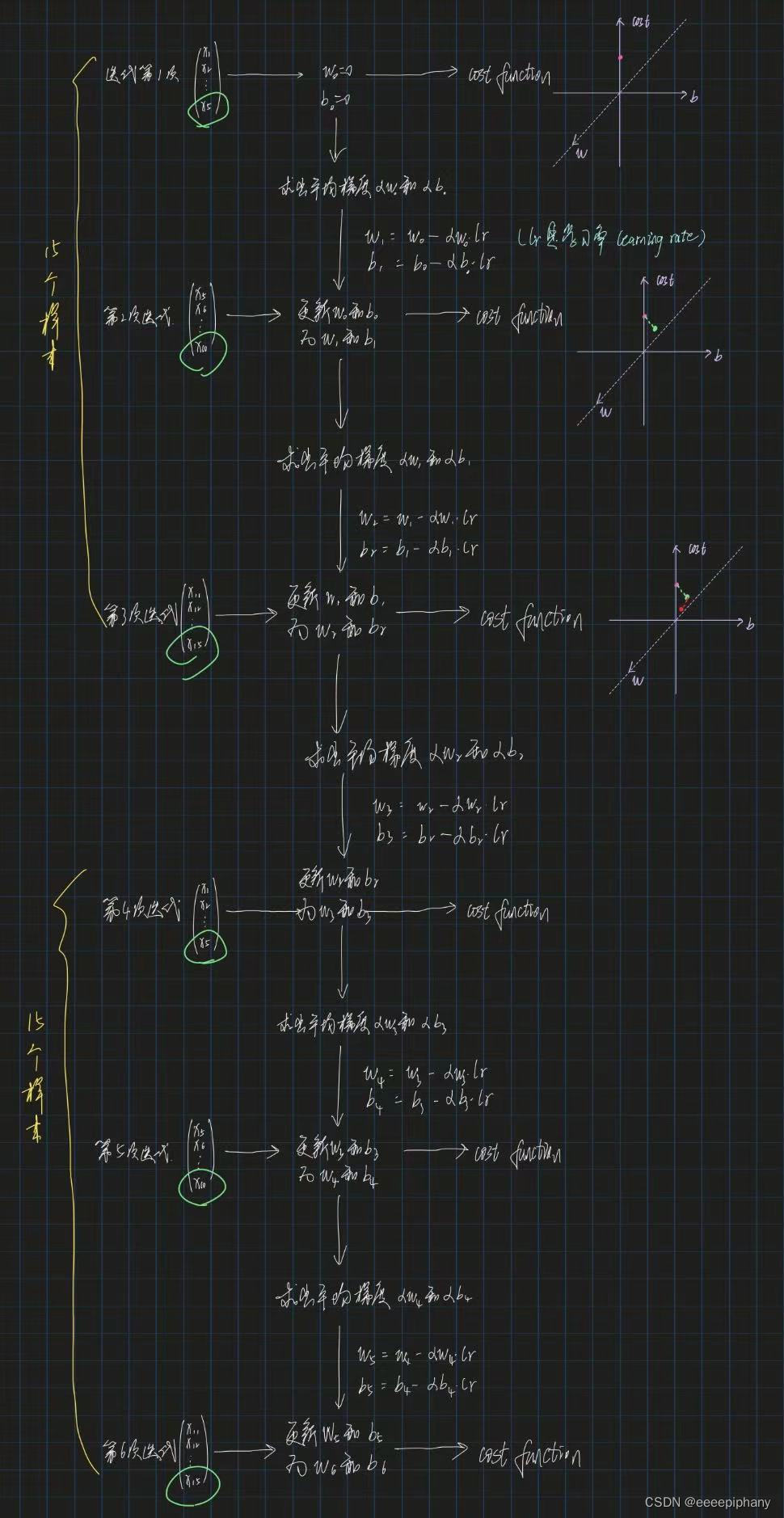
上述情况就是 full batch,即每次迭代都会使用整个数据集。
而 mini batch 就是把数据集分成多个小 batch。如果上述的线性回归模型采用了 mini batch,则效果如下:
(假设一共有 15 个样本,且设置 mini batch size = 5)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









