







arXiv | https://arxiv.org/abs/2501.10120
GitHub | https://github.com/bytedance/pasa
Website | https://pasa-agent.ai

摘要:
我们提出了 PaSa,一种由大语言模型驱动的高级论文搜索智能体。PaSa 能够自主做出包括调用搜索工具、阅读论文和选择相关参考文献在内的一系列决策,以最终为复杂的学术查询获取全面且准确的结果。我们使用强化学习对PaSa进行了优化,并采用了一个合成数据集 AutoScholarQuery,该数据集包含 35,000 个学术查询及对应的论文,这些论文来源于顶级人工智能会议出版物。此外,我们还开发了 RealScholarQuery 基准,收集了现实世界的学术查询,以评估 PaSa 在更真实场景下的表现。
一、引言
学术论文检索处于研究的核心位置,却是一项极具挑战性的信息检索任务。它要求具备长尾的专业知识、全面的综述级覆盖范围以及处理细致查询的能力。大型语言模型(LLMs)的进展激发了众多利用 LLMs 来增强信息检索,特别是通过优化或重构搜索查询以提高检索质量。但学术搜索超越了简单的检索,研究者不仅使用搜索工具,还参与更深层次的活动如阅读相关论文和检查引用,以进行全面而准确的文献调查。
二、数据集
2.1 合成训练数据集 AutoScholarQuery
AutoScholarQuery 是一个合成但高质量的学术查询及相关论文数据集,专门为 AI 领域精心策划。
- 收集了在 ICLR 2023、ICML 2023、NeurIPS 2023、ACL 2024、CVPR 2024 会议上发表的所有论文。
- 针对每篇论文的**“相关工作”部分,利用 GPT-4o 生成学术查询,这些查询的答案对应于 “相关工作” 部分引用的参考文献**。

- 对于每个查询,我们仅保留可在 arXiv 上检索到的论文,并以 arxiv_id 作为数据集中的唯一文章标识符。
- 采用源论文的发布日期作为查询日期,在训练和测试过程中仅考虑查询日期之前发表的论文。
最终 AutoScholarQuery 数据集划分为用于训练、开发和测试的33,551、1,000 和 1,000个实例。每个实例由一个查询、相关的论文集合以及查询日期组成,每个划分中的查询均源自不同的源论文。

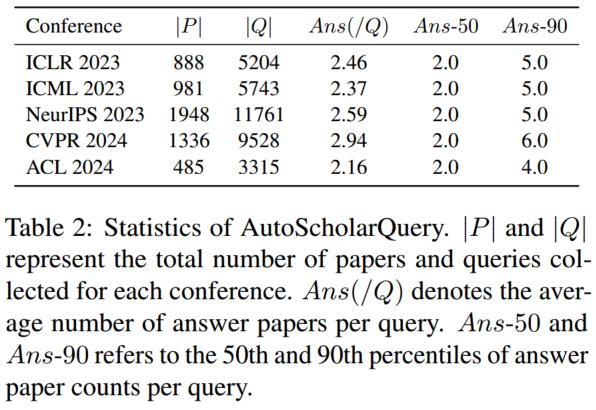
2.2 基准测试数据集 RealScholarQuery
RealScholarQuery 是一个由 50 个真实世界研究查询组成的测试数据集。
- 从几位 AI 研究人员提供的查询中随机抽取了一部分查询,并手动过滤掉过于宽泛的主题,收集了 50 个细致且现实的查询。
- 使用多种方法检索了更多论文,包括 PaSa、Google、Google Scholar、ChatGPT以及 Google 与 GPT-4o 结合用于改写查询,汇总到一个候选论文池中。
- 专业注释者审查了每个查询的所有候选论文,选择了符合查询特定要求的论文,以创建最终的相关论文集。 (平均每个查询需要注释者审查76篇候选论文)
RealScholarQuery 中所有实例的查询日期均为 2024-10-1。

三、方法
PaSa 系统由两个 LLM 智能体组成:爬虫器(Crawler)和选择器(Selector)。
- 爬虫器读取用户的查询,生成多个搜索查询并检索相关论文,检索到的论文被添加到一个论文队列中。进一步处理论文队列中的每篇论文,以识别值得进一步探索的关键引用,并将任何新相关的论文附加到论文列表中。
- 选择器对论文列表中的每篇论文进行彻底审查,以评估其是否满足用户的查询需求。
总之,爬虫器旨在最大化相关论文的召回率,而选择器则强调在识别满足用户需求的论文时的精确性。
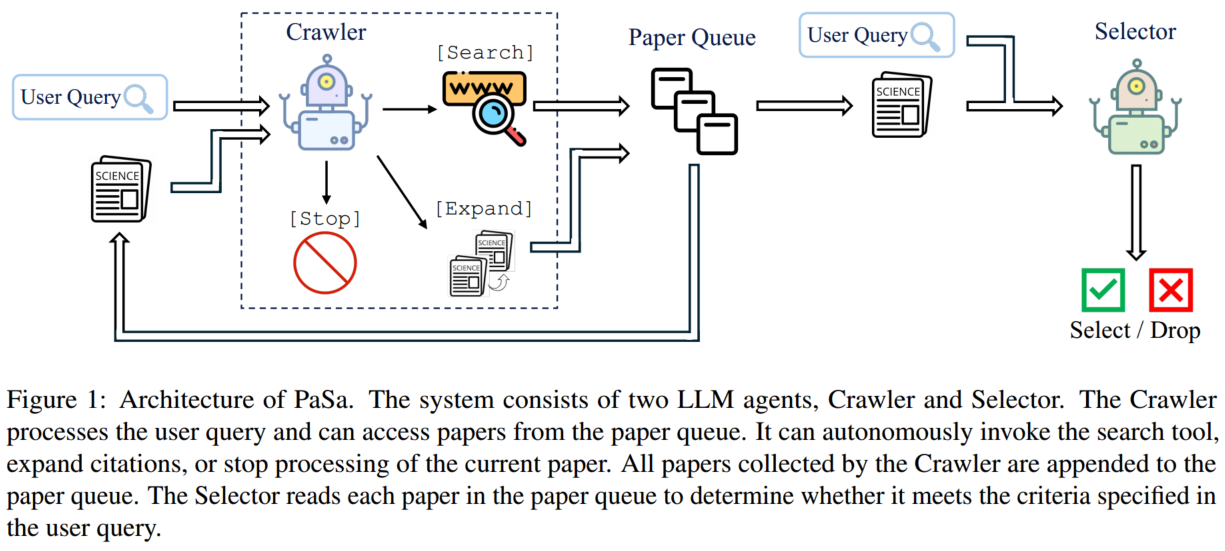
3.1 爬虫器 Crawler
爬虫器执行一个基于标记的马尔可夫决策过程(MDP)。动作空间 A 对应于大型语言模型(LLM)的词汇表,其中每个标记代表一个动作;LLM 充当策略模型;代理的状态由当前的 LLM 上下文和论文队列定义。
爬虫器通过三个注册函数进行操作,当某个动作与函数名称匹配时,执行相应的函数,进一步修改代理的状态。
- **[Search]:**生成搜索查询并调用搜索工具。将所有结果论文附加到论文队列中。
- **[Expand]:**生成子节名称,然后将子节中所有引用的论文添加到论文队列中。
- **[Stop]:**将上下文重置为用户查询和论文队列中的下一篇论文。
爬虫器的训练过程分为两个阶段。第一阶段,我们为训练数据的一小部分生成轨迹,随后进行模仿学习。第二阶段,应用强化学习。(强化学习训练的具体实施细节见原文)
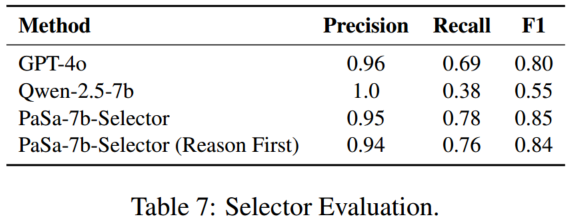
3.2 选择器 Selector
**两个输入:**学者查询和研究论文(包括其标题和摘要)
两个输出:
- 一个单一决策标记 d,即 “True” 或 “False”,指示论文是否满足查询;
- 一个支持该决策的 m 个标记推理 r = ( r 1 , r 2 , … , r m ) r=(r_1,r_2,…,r_m) r=(r1,r2,…,rm)
推理的目的:
- 通过联合训练模型生成决策和解释来提高决策准确性,并通过在 PaSa 应用中提供推理来提高用户信任度。
- 为了优化爬虫的训练效率,决策标记在推理之前呈现,使得选择器在爬虫训练期间可以充当单一标记的奖励模型。
- 此外,决策标记的标记概率可用于对搜索结果进行排序。
通过模仿学习来优化选择器。(训练的具体实施细节见原文附录B)
四、实验
4.1 实验设置
训练基于 Qwen2.5-7b 的选择器和爬虫器,开发最终智能体 PaSa-7b
- **选择器:**使用了附录B中描述的训练数据集进行微调,以 1e-5 的学习率和 4 的批量大小进行了单轮监督微调。训练在 8 个 NVIDIA-H100 GPU 上运行。
- **爬虫器:**第一阶段,在 12,989 个训练数据上进行 1 epoch 的模仿学习,学习率为 1e-5,每个设备的批量大小为 4,使用 8 个 NVIDIA H100 GPU。第二阶段,应用PPO训练,首先冻结策略模型并训练价值模型,然后同时训练策略和价值模型。(在模仿学习阶段,模型处理了 5,000 个查询,而在强化学习训练阶段,模型总共处理了 16,000 个查询)
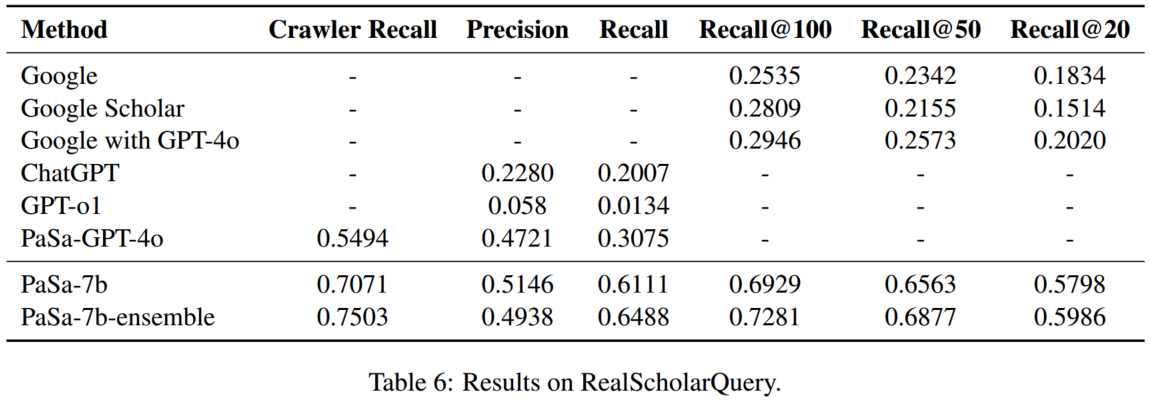
**基线方法:**谷歌、谷歌学术、谷歌结合 GPT-4o、ChatGPT、GPT-o1、PaSa-GPT-4o
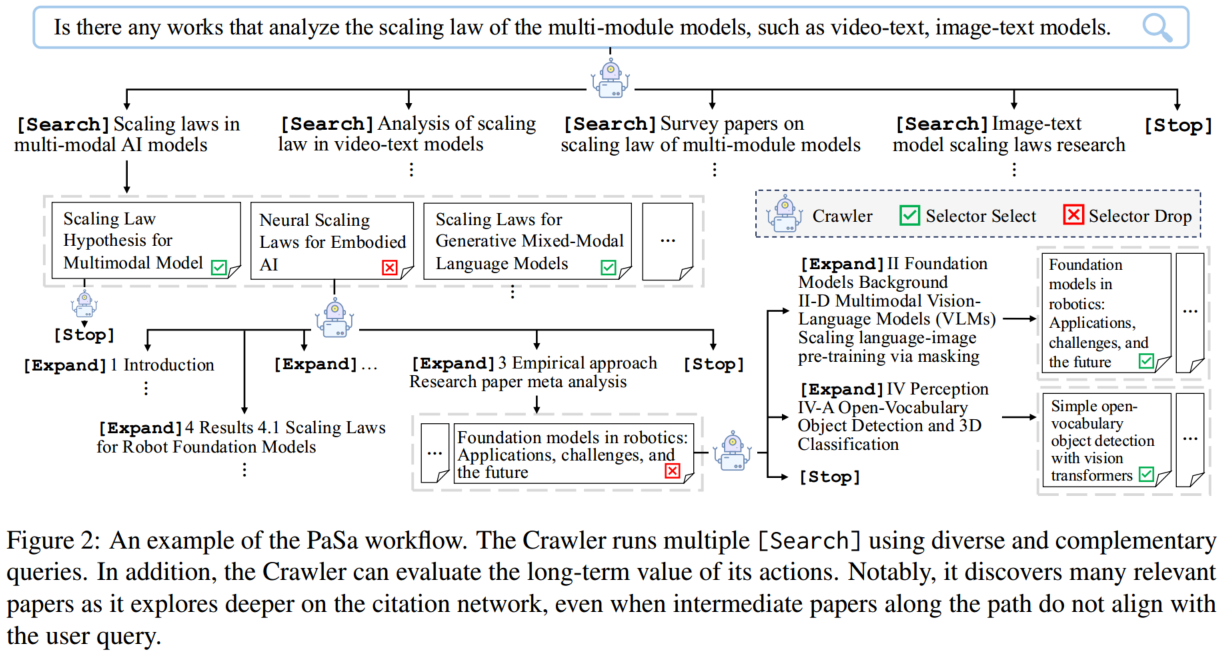
PaSa 的爬取过程可视化为一篇论文树。在实际操作中考虑到计算成本,将 Crawler 的探索深度限制为三层。
ensemble:在推理过程中运行两次 Crawler。
4.2 主要结果
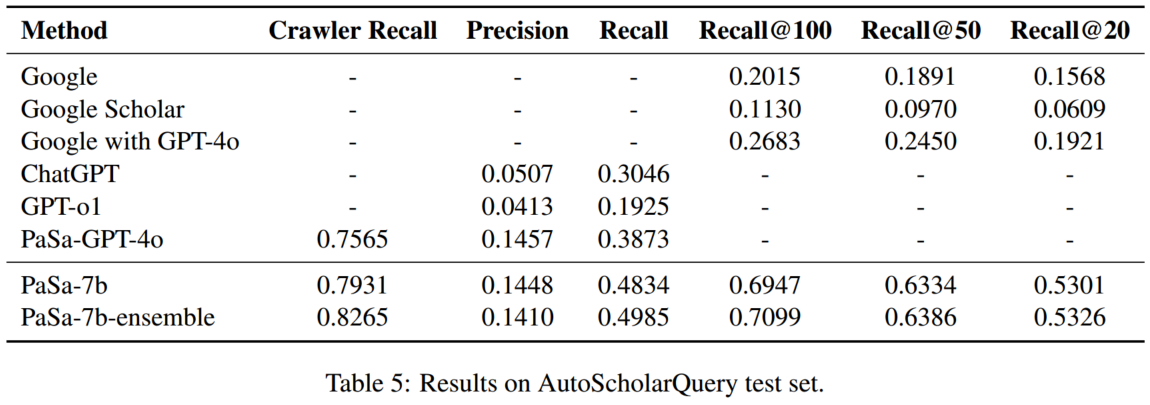
选择器比较:
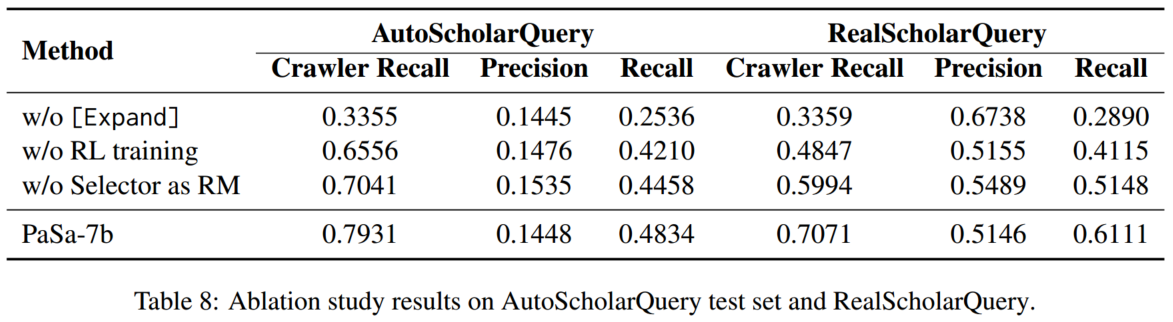
4.3 消融实验
移除 [Expand] 操作会导致召回率显著下降
RL 训练效果
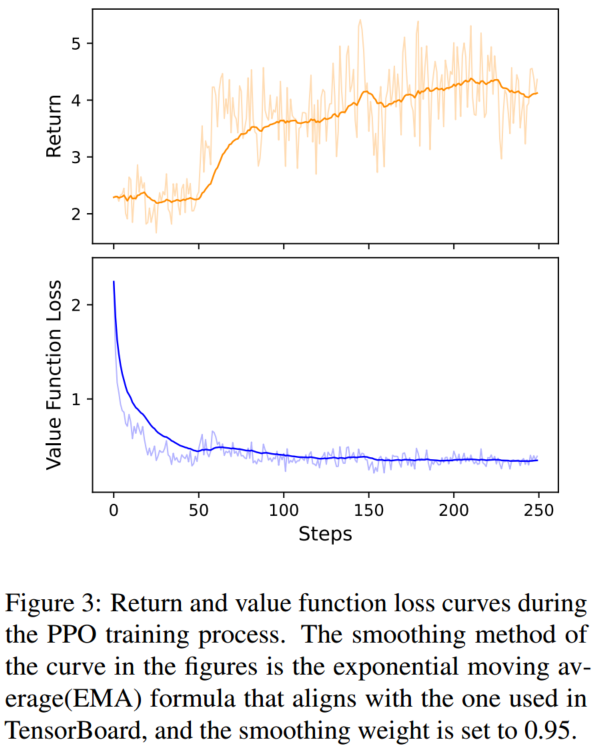
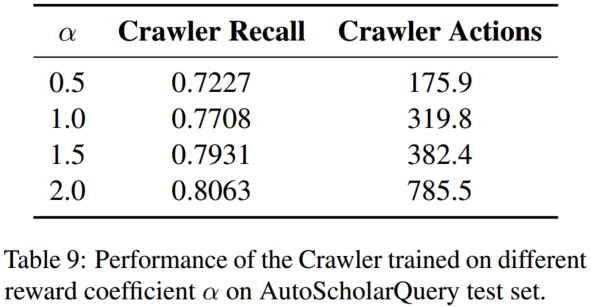
调整 RL 训练中的奖励
9J0-1739252904041)]
RL 训练效果

调整 RL 训练中的奖励


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









