






《长相思》
花似伊 柳似伊 叶叶声声是别离 雨急人更急
湘江西 楚江西 万水千山远路迷 相逢终有期
最近正在玩StyleGANs,需要一些动漫图片做训练数据集,所以搞个爬虫从百度图片爬取国漫美女图片。
工程师的乐趣就是这么简单!
GitHub代码:
 https://github.com/tklk610/Python-Crawlies-for-Baidu-Image-Seach
https://github.com/tklk610/Python-Crawlies-for-Baidu-Image-Seach爬取B站漫画的爬虫:
爬取彼岸图网的爬虫:
本文介绍一下爬取的方法。
首先,这是爬取成果:





目录:
1.网页分析;
2.爬取流程;
3.魔高一丈之反反扒
1.网页分析
百度图片使用的是Ajax技术,所以当前HTML里没有图片url,按F12进入开发者工具 -> 选择network -> 选择XHR,如下图:
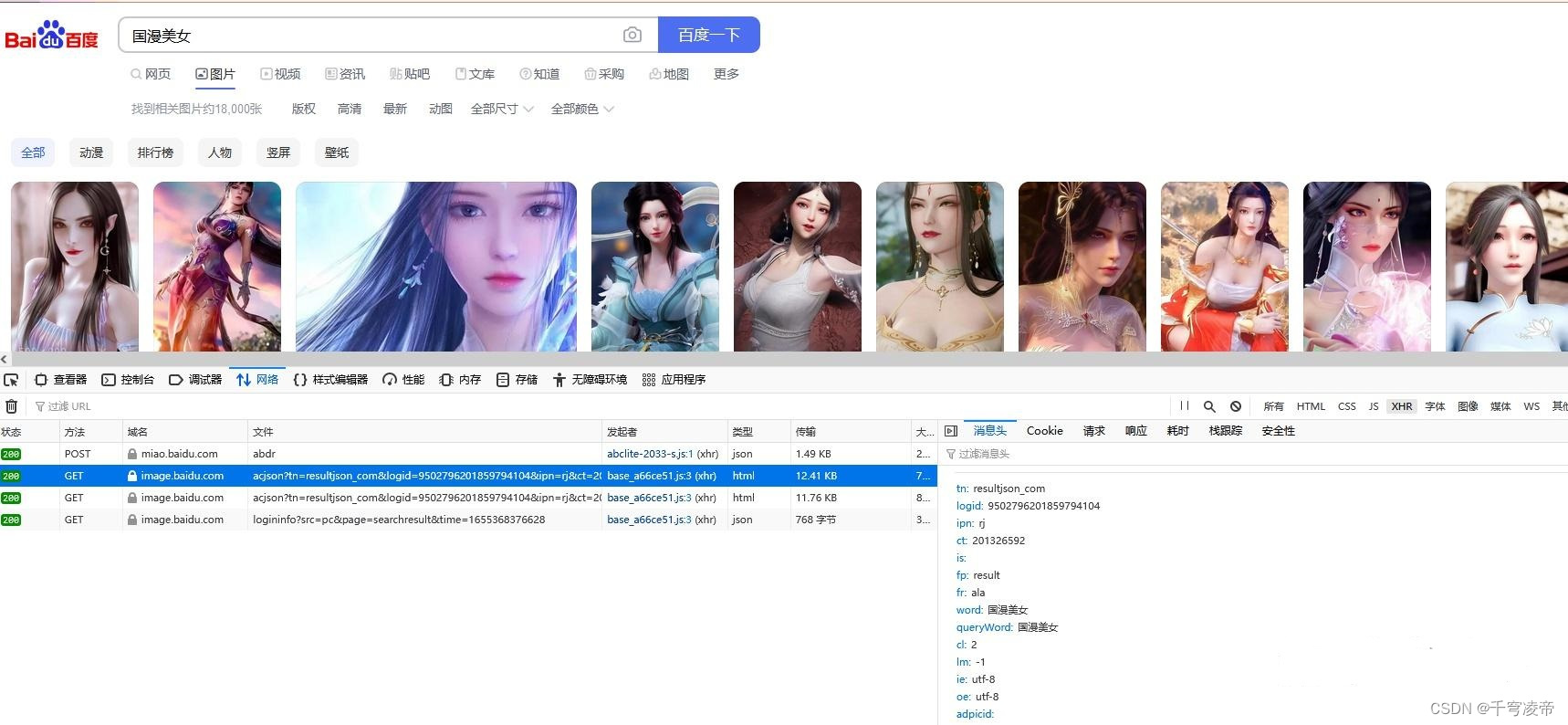
基础url = 'https://image.baidu.com/search/acjson',加上一堆参数。“rn”是每页显示图片张数,“pn”是每页显示的图片序列数,30/60/90.......。照抄headers,发起GET请求。
得到含有图片url的HTML,如下图:

查找“Objurl”对应的值,就是需要的图片URL,找到的URL分为两类,一类是正常字符串,包含很多转义字符“\”,如下图:
![]()
第二类是经过处理的字符串,需要重新反编码,如下图:
![]()
之后使用得到的正确URL发起GET请求就可以下载图片了。
2.爬取流程
第一步,对基础网址发请求,得到HTML文件,headers和params照抄页面上的。
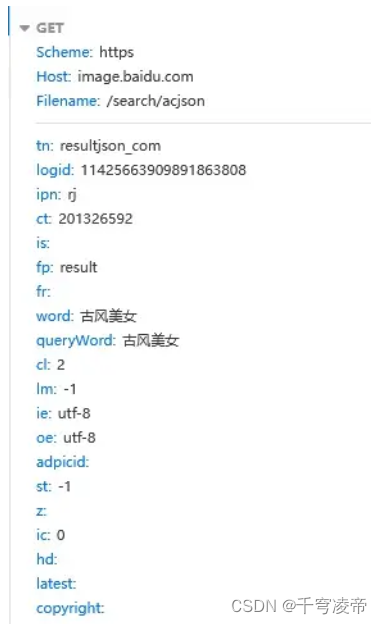
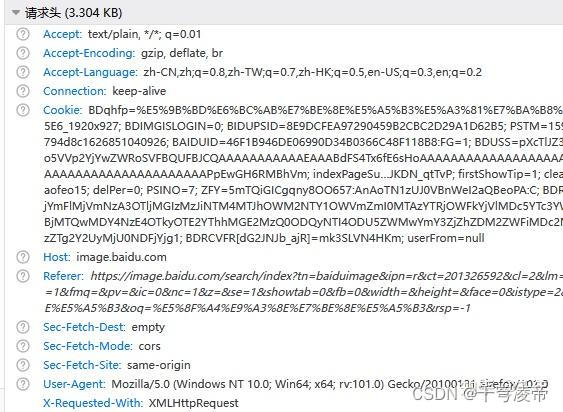
第二步,从HTML里收集Objurl数据,处理一下转义字符串和编码问题。
for url in image_url_list :
if url.startswith('https'):
url = url.replace('\\', '')
else :
url = baidtu_uncomplie(url)反编码:
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d= {'w':'a', 'k':'b', 'v':'c', '1':'d', 'j':'e', 'u':'f', '2':'g', 'i':'h', 't':'i', '3':'j', 'h':'k', 's':'l', '4':'m', 'g':'n', '5':'o', 'r':'p', 'q':'q', '6':'r', 'f':'s', 'p':'t', '7':'u', 'e':'v', 'o':'w', '8':'1', 'd':'2', 'n':'3', '9':'4', 'c':'5', 'm':'6', '0':'7', 'b':'8', 'l':'9', 'a':'0', '_z2C$q':':', '_z&e3B':'.', 'AzdH3F':'/'}
j= url
for m in c :
j = j.replace(m,d[m])
for char in j :
if re.match('^[a-w\d]+$', char):
char = d[char]
res= res + char
return res第三步,使用正确的URL发起GET请求下载图片。
3.魔高一丈之反反扒
1.headers,GET请求不能写全;
2.随机休息,时间可以长一点;
time.sleep(random.randint(5, 20))3.headers里随机更换浏览器;
![]()
4.使用代理IP;


















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











