







公司项目,已申请专利

深度学习作为新兴技术在图像领域蓬勃发展,因其自主学习图像数据特征的性能避免了人工设计算法的繁琐,精准的检测性能、高效的检测效率以及对各种不同类型的图像任务都有比较好的泛化性能,使得深度学习技术在图像领域得到广泛应用,包括图像检测、图像分类、图像重构等。
显示屏的结构是多层形式,从上往下包括玻璃保护膜、CG盖板玻璃、OCA胶和显示像素层。在显示屏生产过程中,由于各种原因会在显示屏的各层结构之间造成灰层、脏污等异物,对于不同层次的异物关注度不同,比如玻璃保护膜-CG盖板玻璃的异物无关紧要,而CG盖板玻璃-OCA和OCA胶-显示像素层的异物则会影响显示屏的显示效果,因此对于显示屏不同结构层的异物需要将以区分检测,而显示屏各层结构厚度很小且连接紧密,各种异物自身体积也是像素级别的,因此显示屏的分层异物一直是行业难点。
基于深度学习的深度估计神经网络通过提取图像的特征信息,利用各个像素点之间的特征关系,得到各个像素的深度关系,从而根据深度估计值得到各个分层异物的分层位置。
本专利将通过使用对向打光的双相机斜视拍照方案,使用基于Deformable-Attention的Mixed-Attention机制组成双重特征金字塔结构,提取并融合两张图像中的特征信息,并进行特征向量对齐,使用基于Xception的多层神经网络,使用不同感受野的卷积对特征图进行深度信息提取,使用语义分割的方式得到最终的深度图。使用双相机的方案,融合两张斜视图像的特征信息,提取各自的像素深度信息,通过深度估计神经网络得到各个异物的深度信息。
本专利提出了一种使用双相机对向打光拍照,使用深度估计神经网络融合两种图像中的深度信息,通过神经网络得到所有像素点的深度值,根据深度值对各个异物加以分层检测。
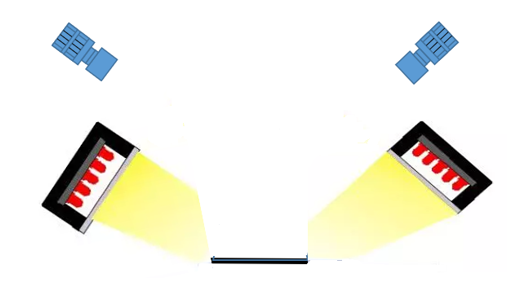
光学方案使用对向打光双斜视相机进行拍照,得到两张不同角度的斜视图像,这种拍照方法能更好的突出异物的深度信息。数据集标注方面,使用显微镜人工得到各个异物的层级位置,将不同层级位置处的异物像素标记不同颜色。设计了一种基于双相机视觉的深度估计神经的网络DDE-Net,在图像特征信息提取融合阶段,使用基于Deformable-Attention的Multi-Attention机制组成双重特征金字塔结构,提取并融合两张图像中的深度特征信息,并进行特征向量对齐。深度信息提取阶段,使用基于Xception的多层神经网络,使用不同感受野的卷积对特征图进行深度信息提取。深度信息估计阶段,使用Upsample模块进行深度信息的语义分割,最终得到图像各个像素的深度估计图。
目录:
1.光学方案及数据集标注
2.基于双目视觉的深度估计神经网络
3.三.深度信息提取模块(Neck)
4.深度估计语义分割网络
5.损失函数
一.光学方案及数据集标注
1.拍照方案
本专利使用双相机摄像方式,利用两个相机和两个光源,进行对向斜视拍摄即开左光源使用右侧相机拍照,开右光源使用左侧相机拍照,得到两张斜视图像,这种拍照方法能更好的突出异物的深度信息,使用两张图像使得异物的深度信息优势互补,在后期的深度信息估计中能更好地得到异物的深度估计值。
2.照片预处理
对于通过拍照获取的缺陷图片,在送入AI神经网络进行训练前,需要对图片进行一些预处理工作,包括图片裁剪和图片数据集增强等。
图片裁剪缩放:使用相机拍摄得到的缺陷图像除了显示器屏幕部分外还包括一些周围背景部分,这部分图像是不需要的,可能会对AI神经网络的训练及检测带来影响,且多出来的图像也会增加AI神经网络训练和测试时的时间成本以及GPU显存消耗,因此需要通过裁剪的方式去除这些无用图像,只保留原图片内容。并使原图和拍照图的长宽为2的次方,便于后期AI运算。
数据集增强:AI神经网络训练时需要大量的样本图片,通过从大量样本中学习到的数据特征进行建模,有些时候数据集并不是那么充分且通过拍照增加数据集需要额外的时间人力成本,需要通过数据增强方式人为“增加”样本数据,数据增强包括对照片进行旋转、偏移、镜像、裁剪、拉伸、灰度变换等图像操作,使得新图片和原图“看起来”不一样,一定意义上生成了新的图片,扩充了数据集。
3.数据集标注
本专利使用有监督的神经网络,需要对数据集进行标注得到各个异物的深度参考值,使用显微镜对各个异物进行人工层级观察,采用语义分割的方式将不同层的异物像素使用不同颜色进行标注。

Fig2.5.1 语义分割的label图
二.基于双目视觉的深度估计神经网络
本专利DDE-Net神经网络分为图像特征提取融合的Backbone(左侧),深度信息提取的Neck(中间)以及作为深度估计的图像语义分割网络(右侧)。
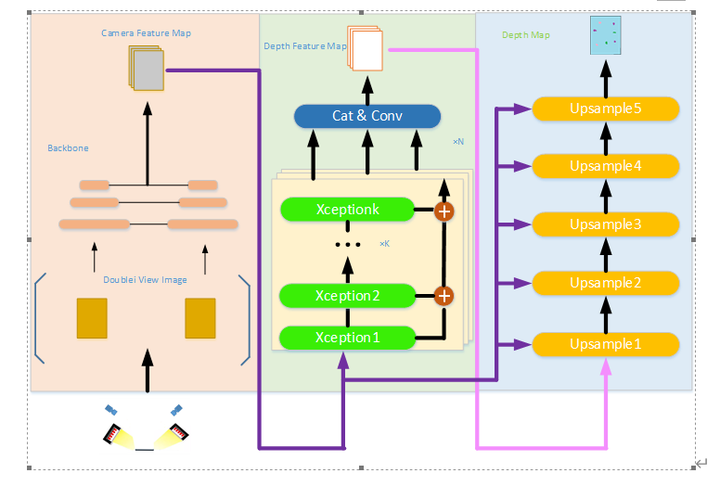
Fig2.6.1 DDE-Net神经网络架构图
整个神经网络分为三部分,左边为双相机图像特征提取融合模块,通过两台斜视相机拍照得到两张图像,通过Backbone提取各自的图像特征信息并进行融合,互补各自的像素深度信息,生成统一的高维特征信息空间;将特征信息送入中间的深度估计神经网络,使用基于Xception的多头卷积操作,得到较为精准的像素深度信息,送入深度估计的图像语义分割网络;右边的深度估计网络使用基于注意力的反卷积操作并结合Backbone的特征信息,输出最终的深度估计图像。
1.特征提取融合Backbone
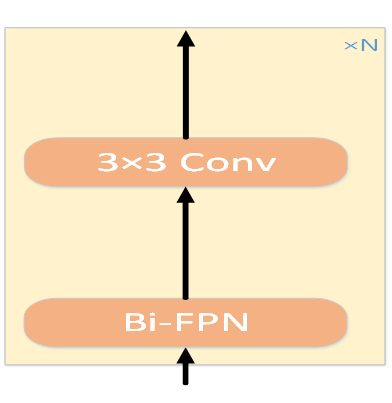
Fig2.6.2 Backbone结构
多次(n次)使用基于Deformable-Attention的Multi-Attention机制组成双金字塔结构,加上3×3卷积核提取并融合两张图像中的全面特征信息,并进行特征向量对齐,从两张图像中互补各自的像素深度信息。
1.双金字塔特征提取模块FPN
基于Deformable-Attention的Mixed-Attention机制组成双重特征金字塔结构。
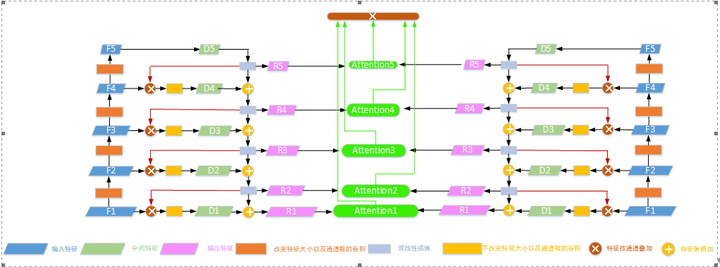
Fig2.6.3 双金字塔特征提取模块结构
该模块分为左右两个对称的金字塔和中间的注意力模块,左右金字塔用于分别提取左右斜视图的各层特征信息,将两张图像的各层特征信息使用基于Deformable-Attention的混合注意力模块,进行深度特征融合。
输入特征图F1经过4个卷积块生成4个分层特征(F2-F5),每个分层特征大小为前一层的一半,通道是前一层的两倍,F5特征层得到中间结果特征层D5。
D5进过双线性插值得到R5,使得特征大小尺寸和F4相同,R5再和F4按特征通道进行叠加,再进过一个1×1卷积块进行通道间特征融合得到中间结果特征层D4。
D4和R5进行加和操作,经过双线性插值得到R4,使得特征大小尺寸和F3相同,R4再和F3按特征通道进行叠加,再进过一个1×1卷积块进行通道间特征融合,得到中间结果特征层D3。
D3和R4进行加和操作,进过双线性插值得到R3,使得特征大小尺寸和F2相同,R3再和F2按特征通道进行叠加,再进过一个1×1卷积块进行通道间特征融合,得到中间结果特征层D2。
D2和R3进行加和操作,经过双线性插值得到R2,使得特征大小尺寸和F1相同,R2再和F1按特征通道进行叠加,再进过一个1×1卷积块进行通道间特征融合,得到中间结果特征层D1。
D1和R2进行加和操作,得到最终结果R1,R1的特征尺寸和F1相同,通道数比F1多。
混合注意力机制模块
输入两组特征编码得到两组Query和Value值,使用Query值互相进行基于Deformable-Attention的混合注意力计算,将结果进行通道叠加再使用1×1卷积进行通道特征融合,得到新的Z值。
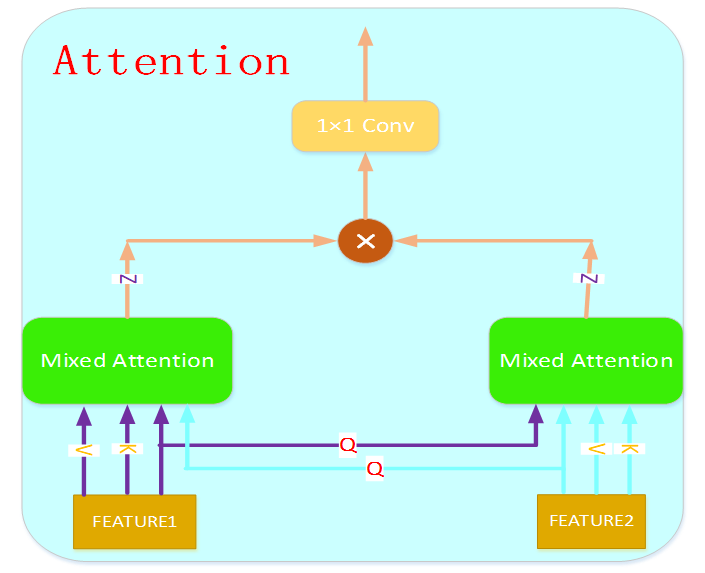
Fig2.6.8 Mixed-Attention机制
双图像的特征融合模块
Mixed-Attention模块包括自注意力模块(Self-Attention) 、互注意力模块(Cross-Attention)和加和标准化操作;
Cross Attention模块可以对两张图像进行特征信息的对齐以及融合,Deformable Attention模块通过只关注某个特征点附近有限个特征点的信息而计算所有特征点的信息,更加关注和该特征点关联大的其他特征点,有效解决缺陷图像大分辨率带来的计算量激增以及小尺寸缺陷难以检测的问题。
输入两个图像特征编码得到两组Query和Value值,这两组(Q,V)首先各自进行基于Deformable-Attention的自注意力计算,得到各自的Z值,再编码得到两组新的Query和Value值,进行互注意力计算,得到两组新的Z值,和之前的Z值进行加和操作并标准化。
三.深度信息提取模块(Neck)
通过使用多头(N个)深度估计模块,每个模块里多次(k次)使用基于Xception卷积模块提取深度空间信息,再将各个模块头的输出通过一个通道叠加以及卷积操作,得到统一的深度特征信息空间。
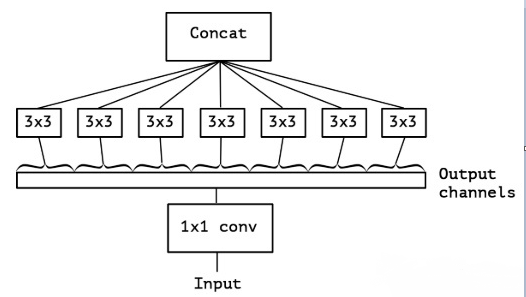
Fig2.7.1 Xception卷积模块
四.深度估计语义分割网络
从深度信息提取网络中得到深度信息的特征空间后,使用Upsample模块和从Backbone得到的特征信息进行深度估计的语义分割操作,最终得到每个像素的深度估计图。
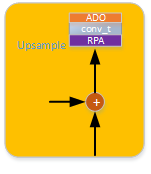
Fig2.8.1 Upsample模块
5个Upsample模块包括特征加和、区域像素注意力模块(RPA) 、反卷积操作(conv_t)和AttentionDropOut模块(ADO)。
1.区域像素注意力模块
RPA给输入特征的每块区域像素分配一个权重,使得神经网络对于图像特征明显的区域更加关注。输入特征(B,C,H,W)先经过一个BatchNorm-DefConv-ReLU进行通道压缩为(B,C*r,H/2,W/2),r<1;再经过一个BatchNorm-DefConv还原成(B,C,H/4,W/4),通过SigMoid函数生成每个像素值的权重,最后使用双线性插值还原成(B,C,H,W),和原输入特征一对一相乘相乘。
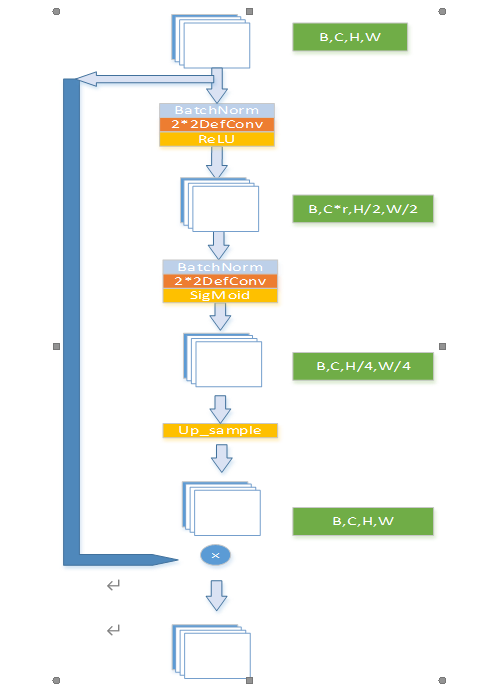
Fig2.8.2 RPA模型结构图
2.注意力Dropout
基于注意力的Dropout方法,不同于一般Dropout使用的随机方式,利用注意力保留更重要的特征信息,使得神经网络的性能和泛化性更好。
对输入特征经过两个批次归一化+可变性卷积+ReLU/SigMiod,生成和原特征形同尺寸的注意力矩阵,根据注意力矩阵的值,将注意力小于阈值的原特征矩阵对应位置神经元置零。
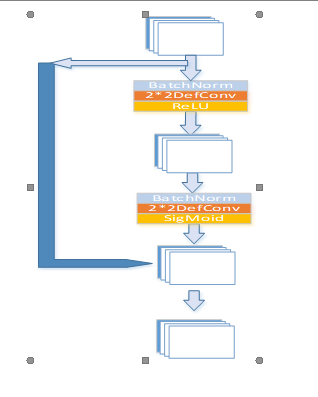
Fig2.8.3 ADO模块结构图
五.损失函数
本专利使用Scale-Invariant Error损失函数:
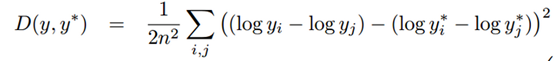
这里y是真实的深度,y*是合成的深度,i,j分别为深度图中的某一对像素点。
本专利通使用双相机拍摄对向打光的方式得到两张斜视图像;使用显微镜人工进行分层异物的层次标记,得到图像的语义分割形式的label;使用双重特征金字塔结构分别提取两张斜视图像的特征信息;使用基于Deformable-Attention的Mixed-Attention机制对两张图像的各层特征进行融合提纯;使用多头Xception卷积对图像的特征信息进行深度估计;最后多次使用Upsample模块得到图像各个像素的深度估计值。

















 4806
4806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











