









PuLID:面部特征一致性风格保持与迁移

随着文生图模型的技术发展成熟,在绘图中一直存在强述求:如何保持图像的身份特征风格一致性迁移或风格多样化变化?在这一技术领域也出现了越来越多的技术模型和组件实现身份特征的保持和迁移。今天文章内容主要就国内大厂字节跳动和小红书开源的几个主流技术评比:PuLID、IP-Adapter以及InstantId。
感兴趣同学可参考之前文章:
- • SD必备知识系列一:IPAdapterFaceID面部特征一致性保持与迁移,轻松搞定私人写真摄影,SDWebUI使用指南
- • SD必备知识系列二:InstantID面部特征一致性风格保持与迁移,轻松搞定私人写真摄影,SDWebUI使用指南
另外,本文中使用的绘图模型是来自哩布平台上发布了国产写实摄影模型:墨幽人造人XL。该模型是一款可出图商用的写实摄影模型。该模型在人物写实真实度方面有着优秀的图像质量,以及优秀的光影视觉冲击,丰富且富有感染力的情绪表达,不论是在影棚的时尚大片、真实感的户外摄影、自然的手机随拍、或是艺术写真方面均有不错的绘图表现。
*墨幽人造人XL*:https://www.liblib.art/modelinfo/e6c19f54cd164687a7384548742ad20b
PuLID模型简介
PuLID是最新字节开源的,因此本文主要介绍PuLID在SD-WebUI中安装指南。关于IP-Adapter以及InstantId请参考社区介绍。
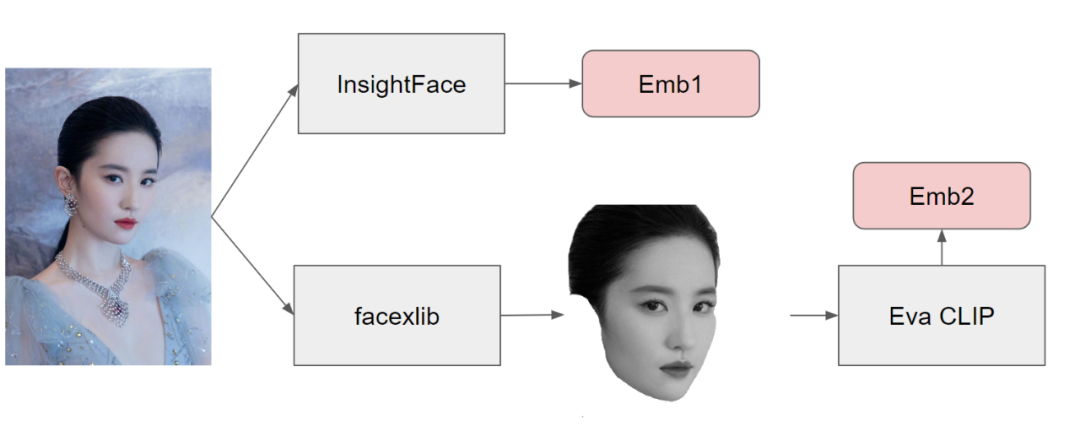
PuLID是一种类似于ip-adapter的方法,用于保持面部身份特征和风格迁移模型。PuLID同时使用了insightface嵌入和CLIP嵌入,这与ip-adapter faceid plus模型的做法类似。不过,在将图像传递给CLIP之前,PuLID会使用facexlib进行额外的步骤,即将面部从背景环境中遮罩出来。PuLID还使用了Eva CLIP代替了普通的CLIP。在attn overrides方面,PuLID也做了一些比IPAdapter做了更多的事情,比如它对张量进行了零填充,并添加到隐藏状态的正交性中。更多PuLID介绍参考之前文章:字节PuLID:高效身份ID特征定制,ComfyUI使用指南、字节PuLID:高效身份ID特征定制新方法,无需复杂微调仅一张图实现
PuLID安装指南
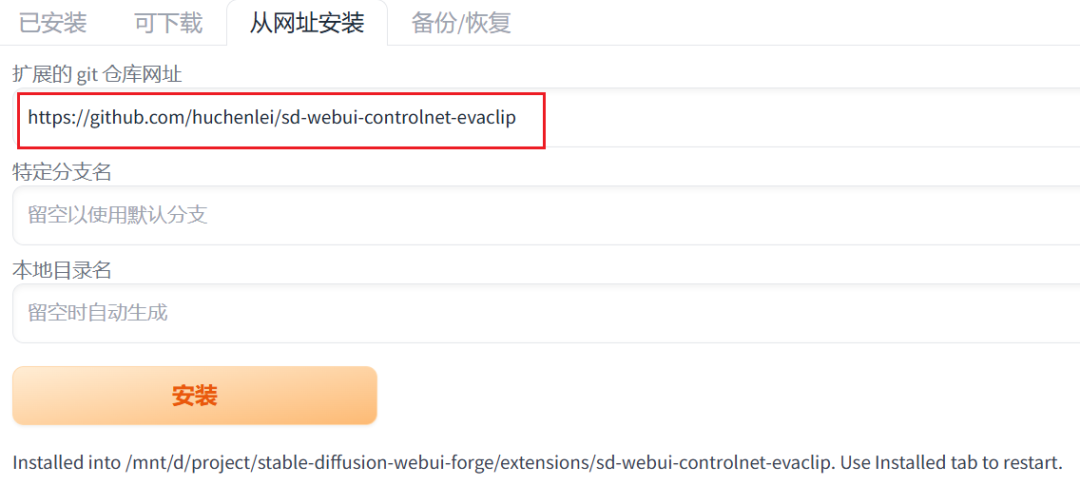
01. 安装sd-webui-controlnet-evaclip扩展
PuLID使用了evaclip嵌入和insightface嵌入作为proj模块输入。因此,为了使用这个特性,需要安装sd-webui-controlnet-evaclip插件,插件地址为:https://github.com/huchenlei/sd-webui-controlnet-evaclip。
02. 模型下载
同时需要下载对应模型并放置在目录stable-diffusion-webui/models/ControlNet下,可以在线下载:https://huggingface.co/huchenlei/ipadapter_pulid/resolve/main/ip-adapter_pulid_sdxl_fp16.safetensors。
在这里需要注意facexlib和evaclip涉及的对应模型会首次运行时候自动下载。但在笔者测试中并未自动下载,经过调试插件代码和手动下载解决。
- • 需要下载模型detection_Resnet50_Final.pth、parsing_parsenet.pth、parsing_bisenet.pth、并放置在目录 /stable-diffusion-webui/models/GFPGAN/ 下,下载地址为:https://huggingface.co/damaimai/parsing_parsenet.pth/tree/main
- • 原则上这会利用huggingface包自动下载,不用急着手动下载,在上面问题解决后可以再次运行查看是否自动下载。模型为:QuanSun/EVA-CLIP放置 /stable-diffusion-webui/extensions/sd-webui-controlnet-evaclip/models,需要使用huggingface_cli下载整个repo:https://huggingface.co/QuanSun/EVA-CLIP/tree/main
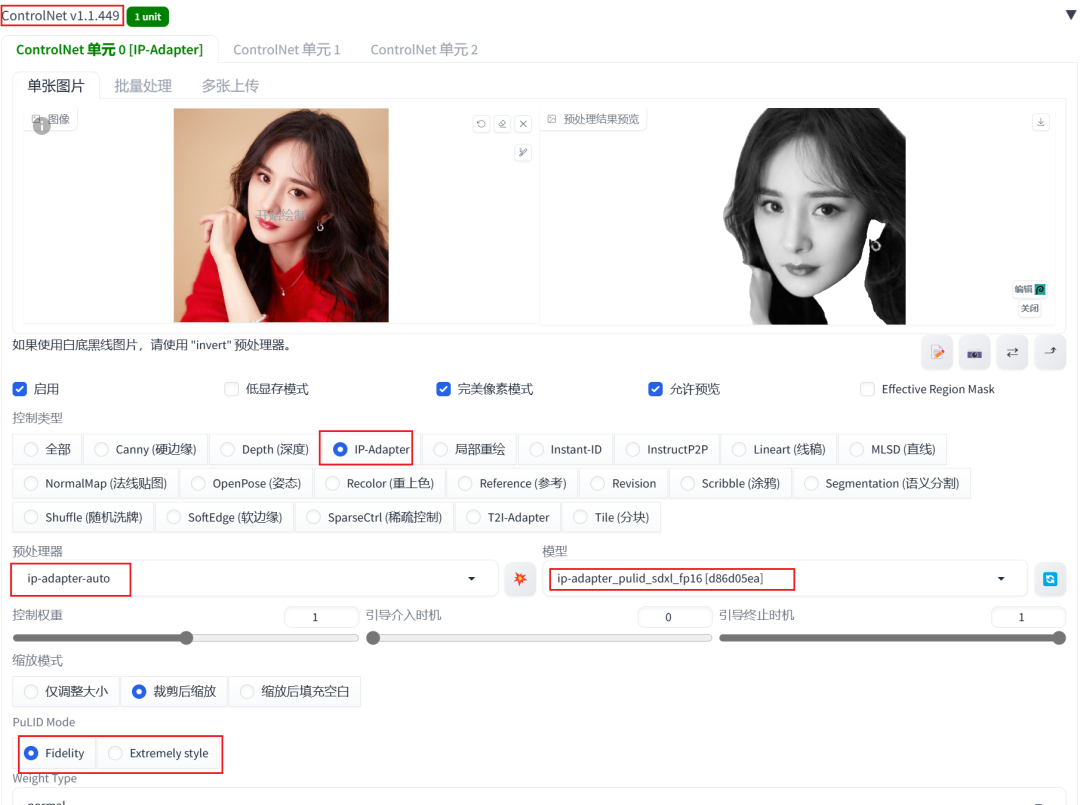
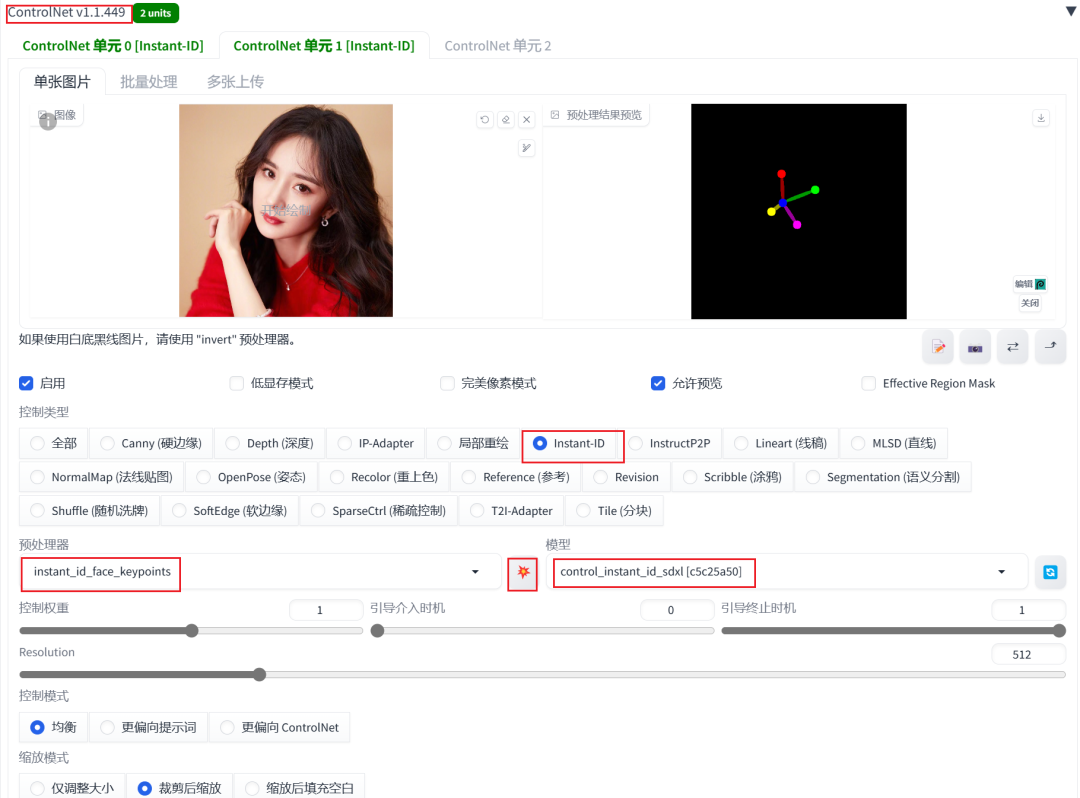
03. ControlNet单元设置
在ControlNet中需要设置一个额外的单选组选择PuLID模式,请注意升级ControlNet插件版本(请确保版本>=1.449)。
04. PuLID体验
绘图配置
- • 绘图模型:***墨幽人造人XL*模型
- • 迭代步数:30步
- • 采样器:DPM++ 2M Karras
- • CFG scale: 7
- 本文使用到模型下载地址(AIGC绘图问题可文末加群交流):
- • **墨幽人造人XL**模型** :https://www.liblib.art/modelinfo/e6c19f54cd164687a7384548742ad20b
- • add-detail-xl LoRA模型:https://www.liblib.art/modelinfo/1f290178083844fb9a22e6e76d8546fa
- • DetailedEyes_XL LoRA模型:https://www.liblib.art/modelinfo/68ece914e617433fa62410a8496edc53
masterpiece painting, buildings in the backdrop, kaleidoscope, lilac orange blue cream fuchsia bright vivid gradient colors, the scene is cinematic, (1girl:1.2), portrait,, emotional realism, double exposure, watercolor ink pencil, graded wash, color layering, magic realism, figurative painting, intricate motifs, organic tracery, pol, <lora:SDXL Detail:1> <lora:DetailedEyes_XL_v3.0:1>
01. Fidelity风格效果


02. Style风格效果

在两种模式之间仅存在微笑差别,笔者并未看出明显差异。
02. 多输入图像
SDWebUI配置
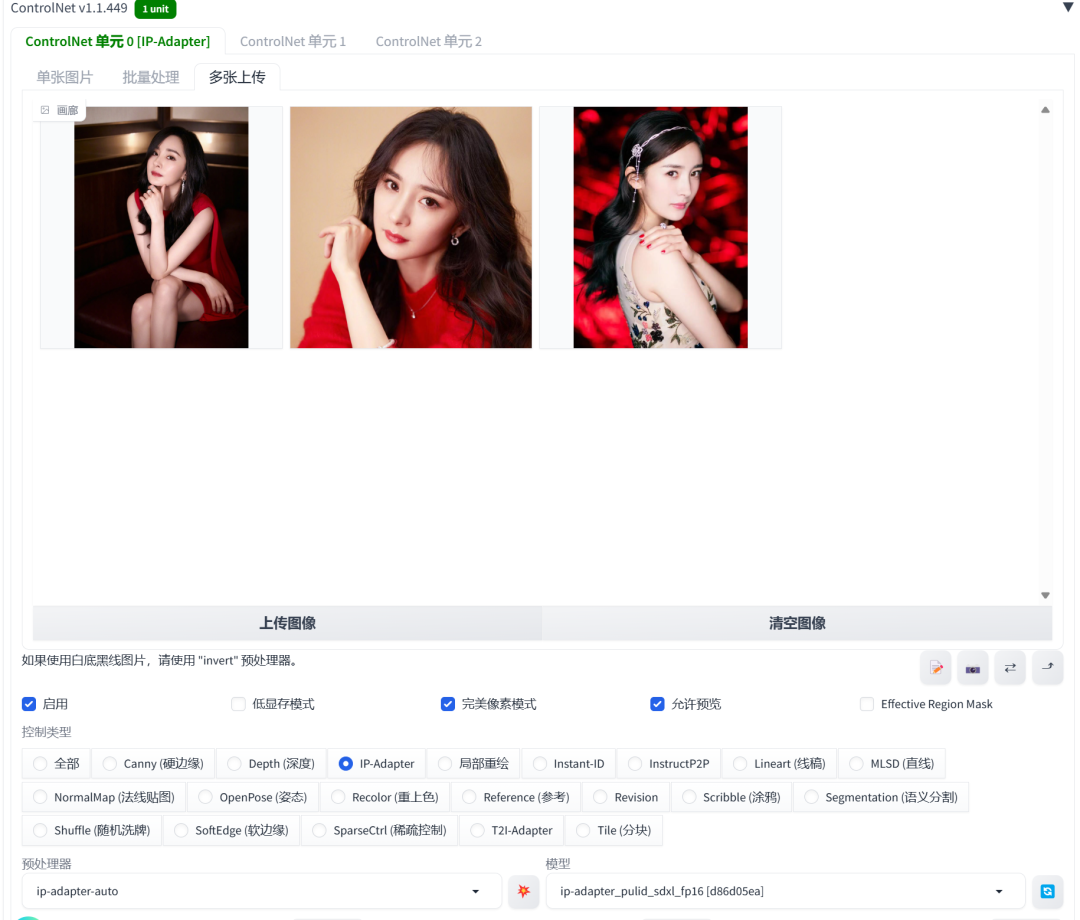
输出效果


注意:与InstantId相比,PuLID需要设置更强的提示才能使输出风格化。
多风格迁移模型评比
绘图配置和提示语等设置同上一小节,这里不在累述。
IP-Adapter配置
提示语中增加ip-adapter-faceid LoRA触发词:
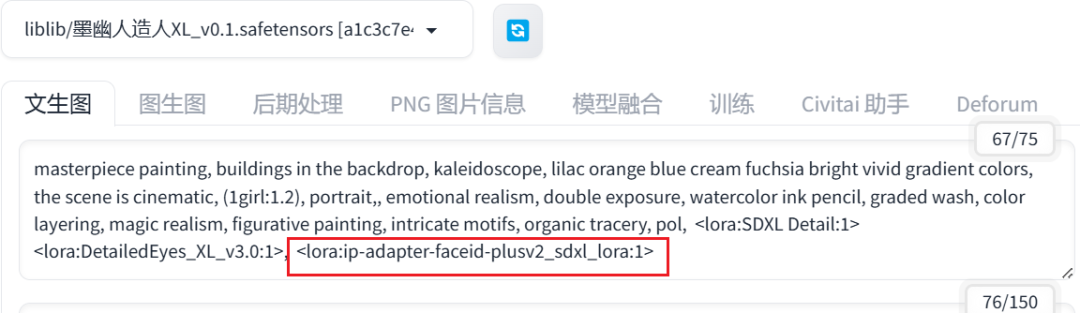
IPA插件配置:
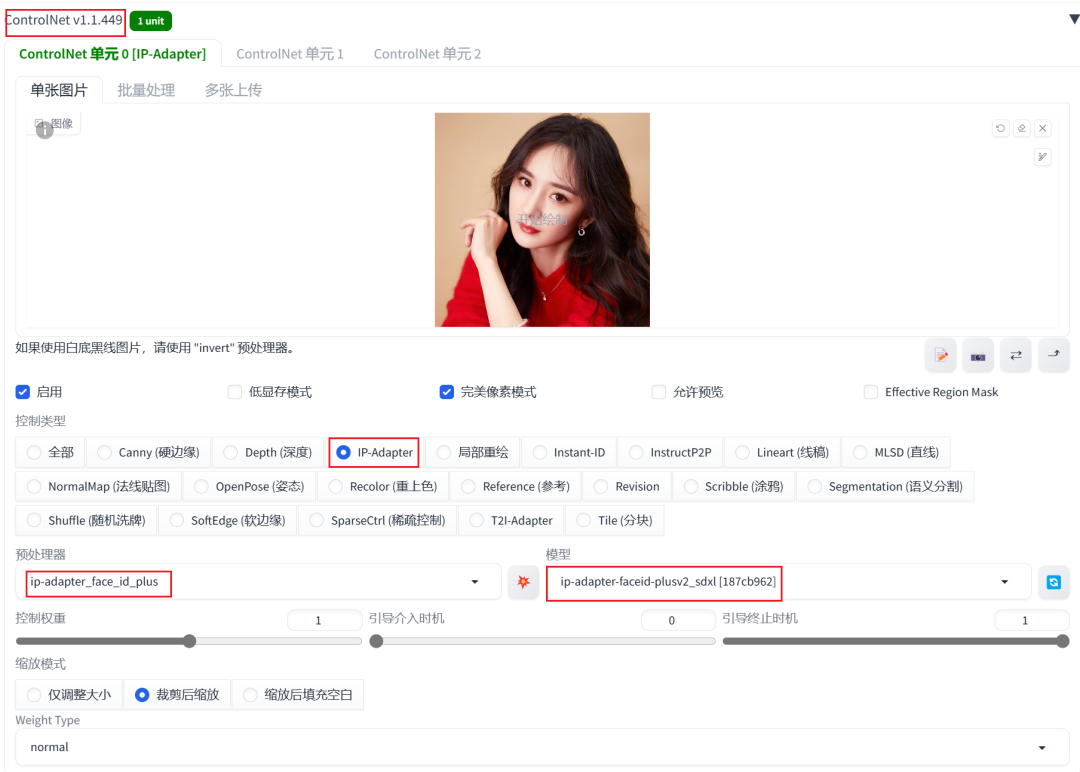
InstantId配置
InstantId插件则需要设置两个CN单元配置启用,并且请确保单元配置顺序:
CN单元0配置:
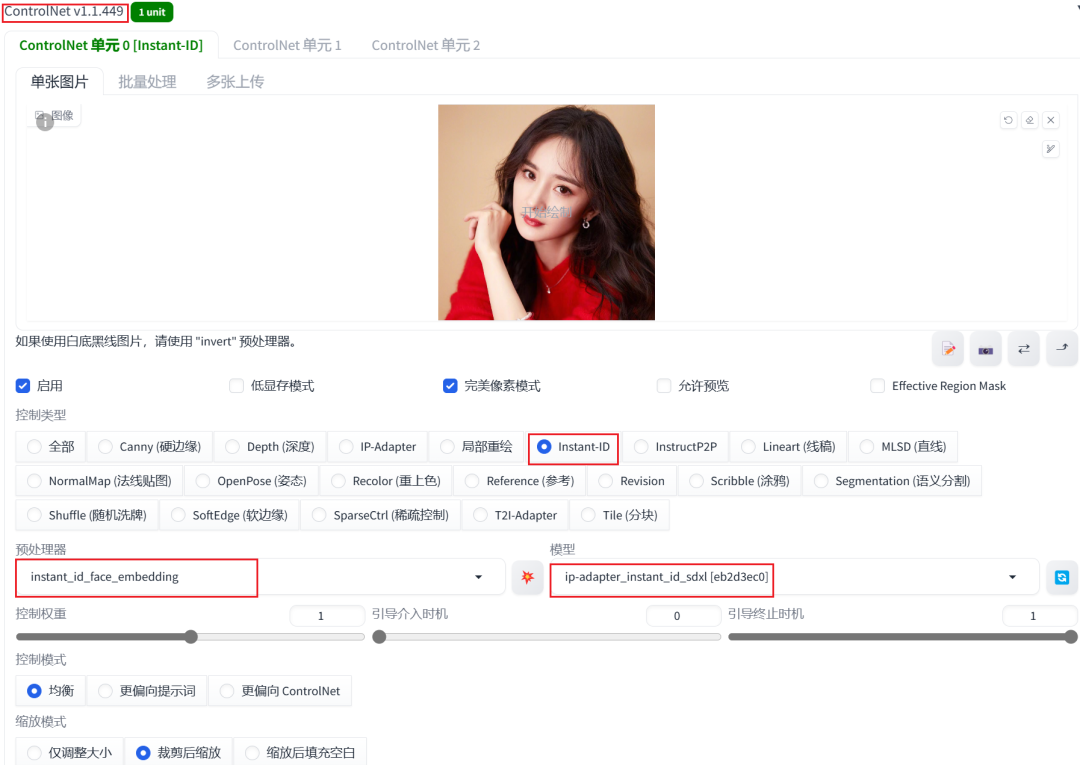
CN单元1配置:
输出效果对比
| PuLID | InstantId | IP-Adapter |
|---|---|---|
 |  |  |
 |  |  |
从从上面两组对比图中,能够显著看出面部特征保持ip-adapter是最弱的,PuLId和InstantId都是保持一致性比较好的,但是能够明显看出InstantId的风格更偏全景艺术风,而PuLId是面部特征更偏向输入图像,这导致也会受输入图的清晰度影响输出效果。但InstantId还存在问题是需要的显存资源较大。ip-adapter是不仅面识特征保持别更重要是作为特征提取重要基础设施应用广泛。因此,评估效果各有优势,各视场景选择格式技术框架是最优方案。
另外,因为PuLId使用了facexlib和eva clip,其资源利用效率不是很高。同时由于采用了正交计算,PuLId在推理过程中比普通的ip-adapter会慢不少。可能这也是官方演示时使用SDXL lightning的原因。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









