






不知道有多少小伙伴尝试了本地部署的Deepseek,我自己尝试了几次后觉得还行,当然我还是推荐官方版本也就是手机端可以用的。
毕竟本地部署的是蒸馏过的,官方版本的是pro max,我们本地部署的是pro或者mini版本。
在上篇笔记末尾有提到不同的显卡版本有推荐的模型,AI的思考回答速度一定程度上取决于显存和内存。
一些小伙伴可能还在观望50系显卡,所以我这里放一个镜像站的地址提供给大家下载其他模型。
这份完整版的DeepSeek入门资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

在这里大家可以根据自己的显存大小搜索适合自己的模型进行下载
- 没有GPU:1.5B Q8推理 或者 8B Q4推理
- 4G GPU:8B Q4推理
- 8G GPU:32B Q4推理 或者 8B Q4推理
- 16G GPU:32B Q4推理 或者 32B Q8推理
- 24G GPU: 32B Q8推理 或者 70B Q2推理
下载的方法也很简单,例如我要找的是32B的模型,直接在网站的搜索框中搜索:Deepseek R1 32B GGUF
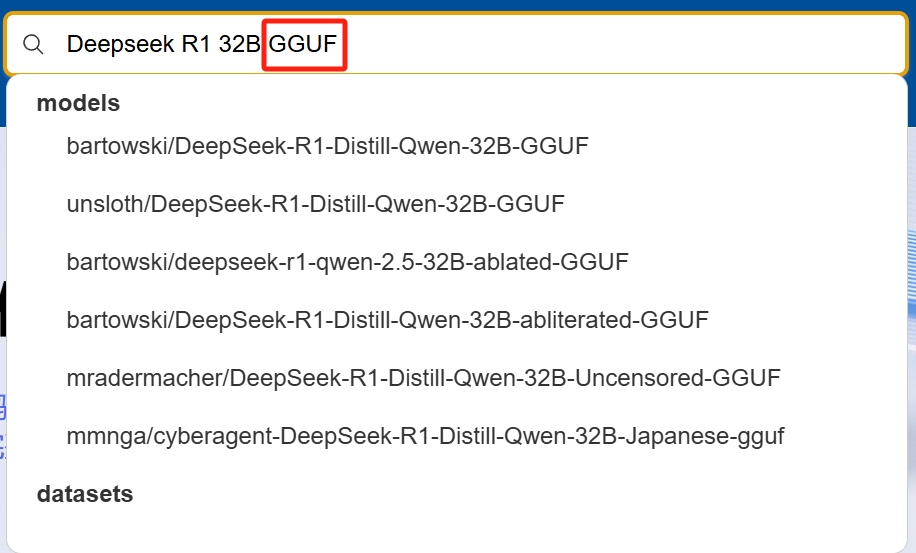
这个GGUF得带上,这样搜索出来的才是能一键部署的模型。
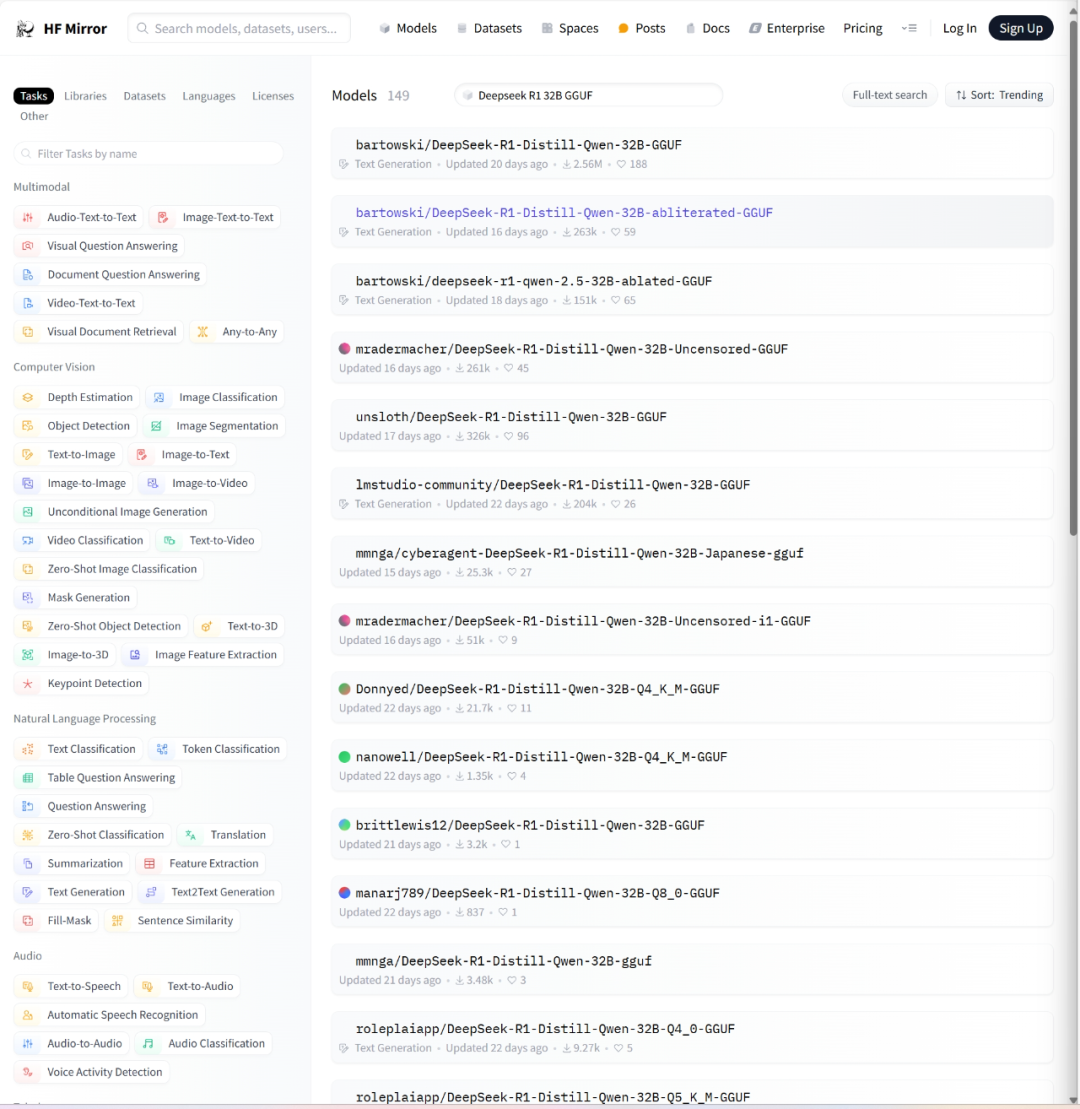
这里面的模型都是从Huggingface上镜像来的,例如DeepSeek-R1-Distill-Qwen-32B-GGUF
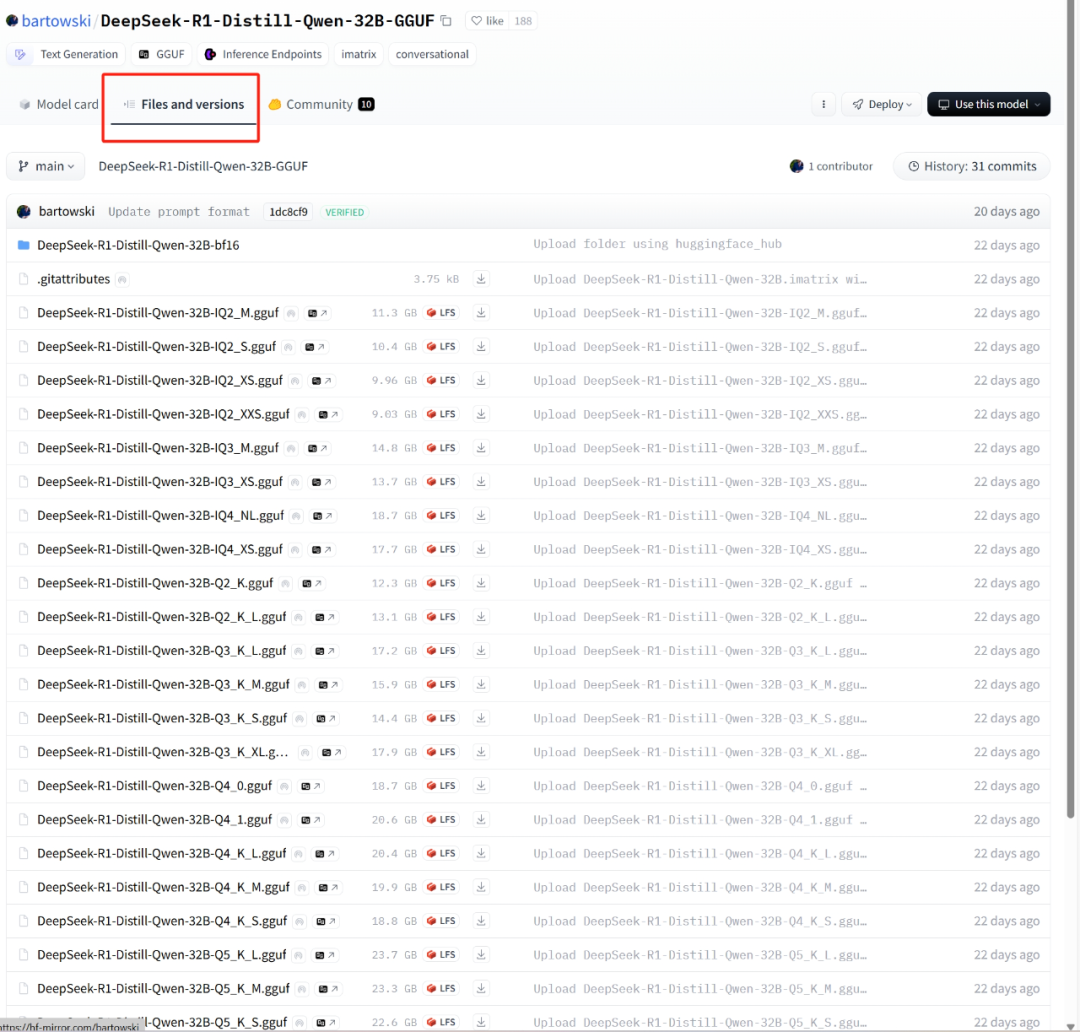
选择Files and versions可以看到有很多模型,这图字可能有点小,这里面的模型顺序从上到下按照模型大小排序的,越大模型效果越好。
例如我的空间还很大,显存也足够,那我直接选择最下面的32B Q8,点击最右侧就可以下载了。

把下载好的模型放在我们上一篇文章说的文件夹中:
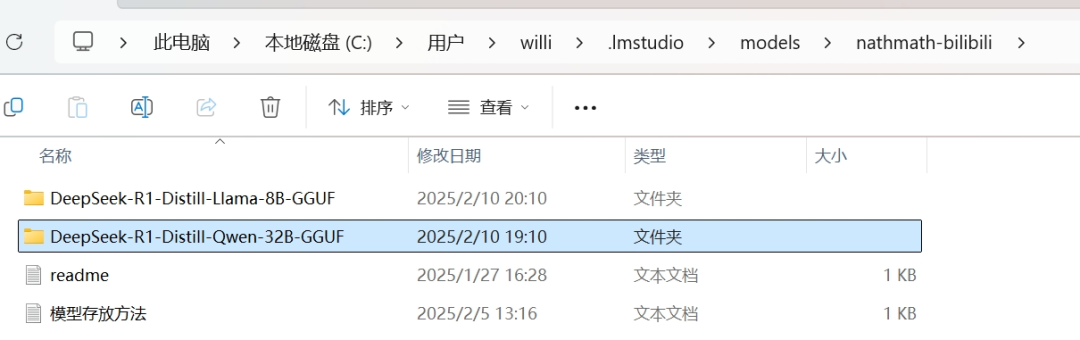
这是我们上篇笔记中配置好的环境
如果有小伙伴是先看到这篇笔记,没看上一篇笔记的话也能放。
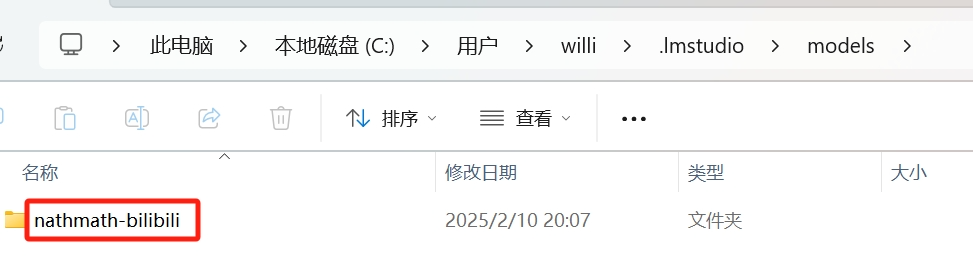
如果小伙伴从官方渠道或者其他地方下载了的话,查看这个路径:
本地磁盘C→用户→本地用户名(我的电脑名是willi)→.Imstudio→models
如果这个路径中打开有类似我的这个文件夹的话,那就将模型放进这个文件夹中并和我一样以文件名新建一个文件夹:
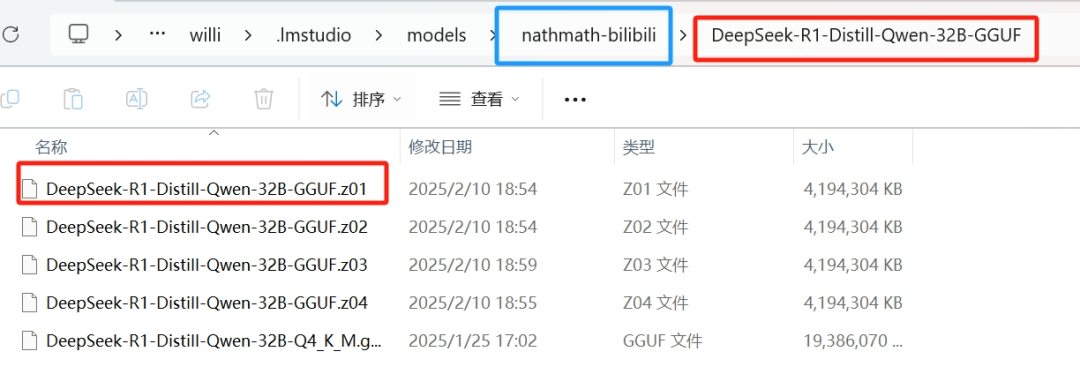
在nanthmath-bilibili这个文件夹里面以DeepSeek-R1-Distill-Qwen-32B-GGUF为名字创建文件夹,这个文件夹里面都是32B的模型。
当然,如果没有类似nanthmath-bilibili这样的文件夹的话,直接新建一个即可(随便新建了个文件夹名为Kongbai),命名不要有中文就行以防后续调用出啥问题。
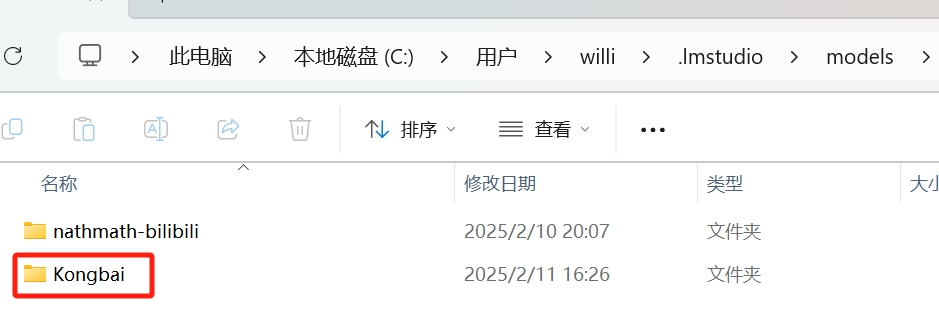
然后再新建的文件夹(Kongbai)里面再重复上面这个蓝色字体的步骤。
模型一定要放在Models的下两层文件夹中:Models→文件夹(模型提供者名称)→文件夹(模型名称)→模型本身
更改模型目录
如果有些小伙伴C盘(模型目录默认位置)不够的话,可以将模型放置到D或者F盘。
这里打开LM studio,如果有没安装的小伙伴可以看看上一篇笔记。
在这里先点击主界面右下角的齿轮,然后将语言改为中文
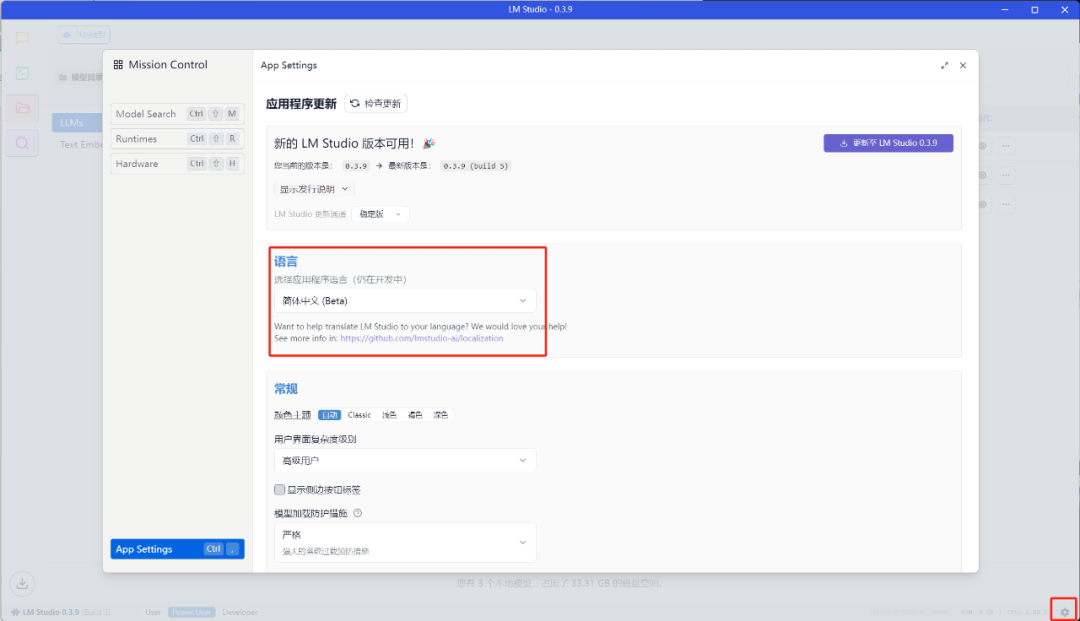
在界面最左下角有三个选项:User、Power User、Developer
在选用Power User或者Developer之后回到页面最左上方,点击第三个红色的选项:
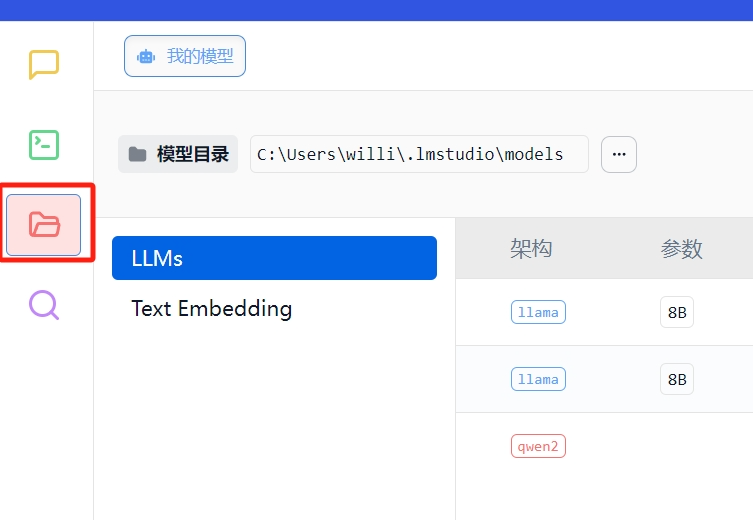
这里是我们之前所下载安装的一系列语言模型,在这里可以进行模型目录的更改。
点击模型目录最右侧的三个小点:

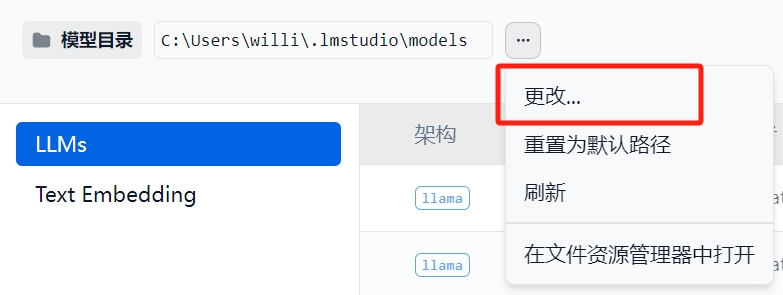
例如我的模型放置在了其他的位置(也是需要models的下两层文件夹),这里我就可以更改文件夹(选择的不是最后一个文件夹),然后选择完后再点击第三个的刷新即可。
选择到这个models下层文件夹即可,就不用再点进去了。
如果显示模型加载Failed的话,可以试试把models以外的文件夹保留在.Imstudio下,只把model放在想放的目录。
模型参数设置:
一般在模型成功导入好之后,点击LM studio最上方的搜索框就可以看到已经导入的模型。
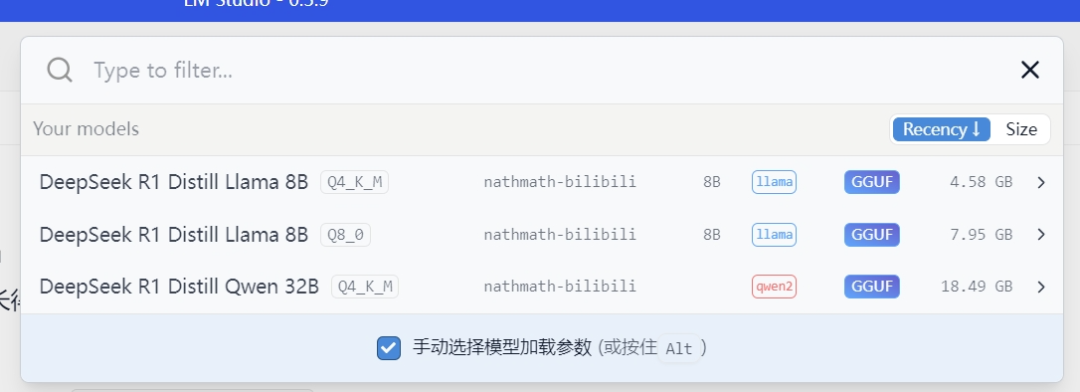
选择任意一个模型之后会弹出有很多参数的一个页面
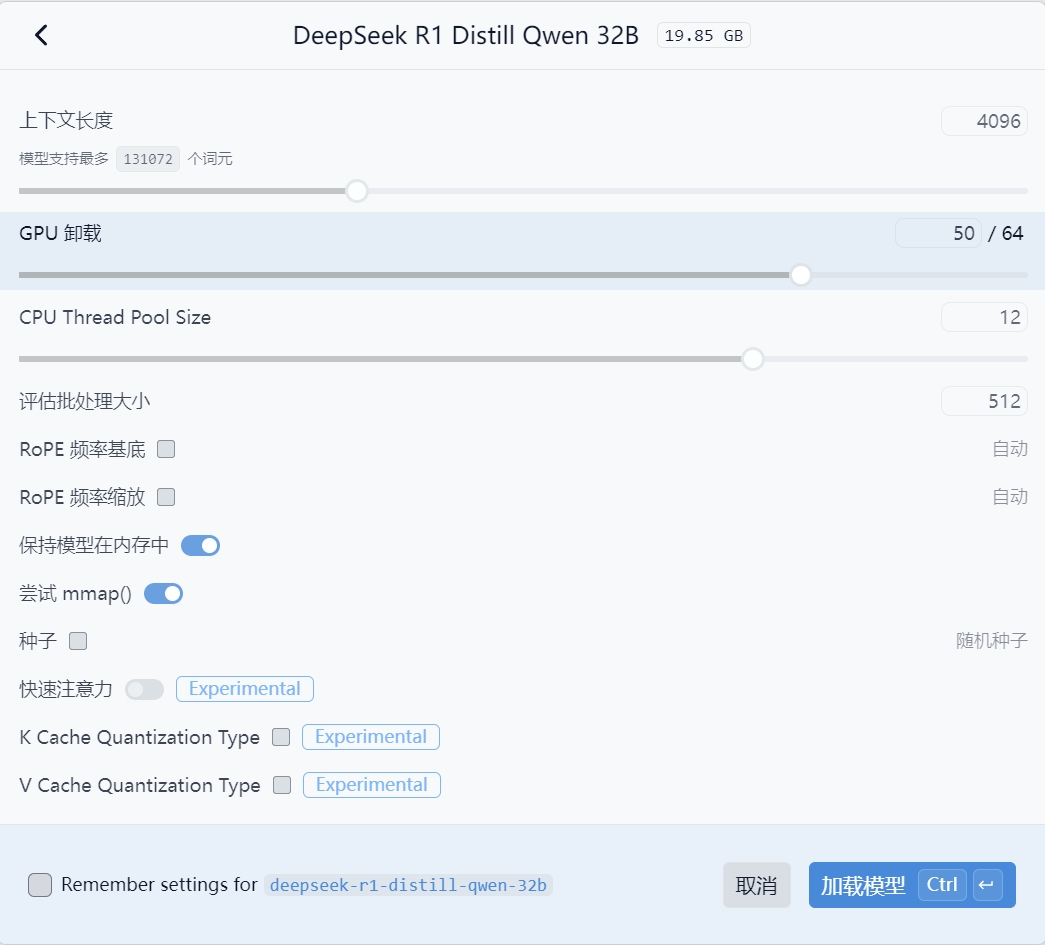
这里一个一个参数讲解:
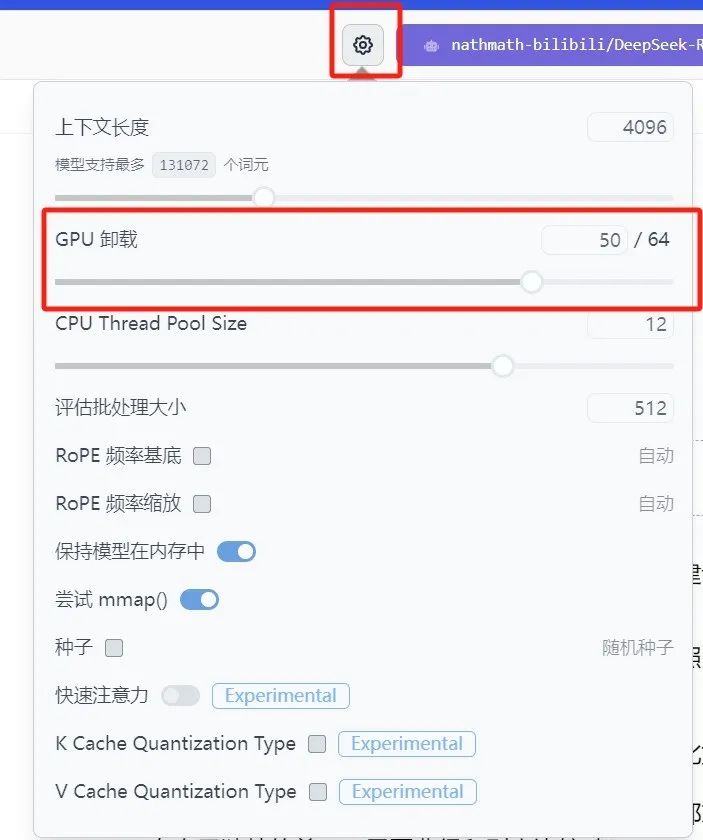
- 上下文长度Context Length:指模型最多能从多少信息中推理,这里默认4096的意思是AI最多能对4096个字符进行推理,更多的就没法记住了。如果是要让AI写小说的话,这里参数可以给到2万左右。
- GPU卸载Offload:GPU将会承担多少层中多少层的运算,我这里50/64的意思就是承担64层中50层的运算。
- CPU Thread Pool Size:一般指会用多少CPU的线程,一般情况下会拉满,这里的拉满不是指手动调到最大值,而是自己CPU线程数的最大值,这里推荐默认或者百度查一下看看自己的CPU。
- 评估批处理大小Evaluation Batch Size:一般默认512,如果GPU比较好的可以拉到1024
- 剩下的参数不建议去调整,维持默认即可
在调整好之后点击右下角的加载模型即可,在模型加载完之后可以打开任务管理器看看有没有吃满显存:
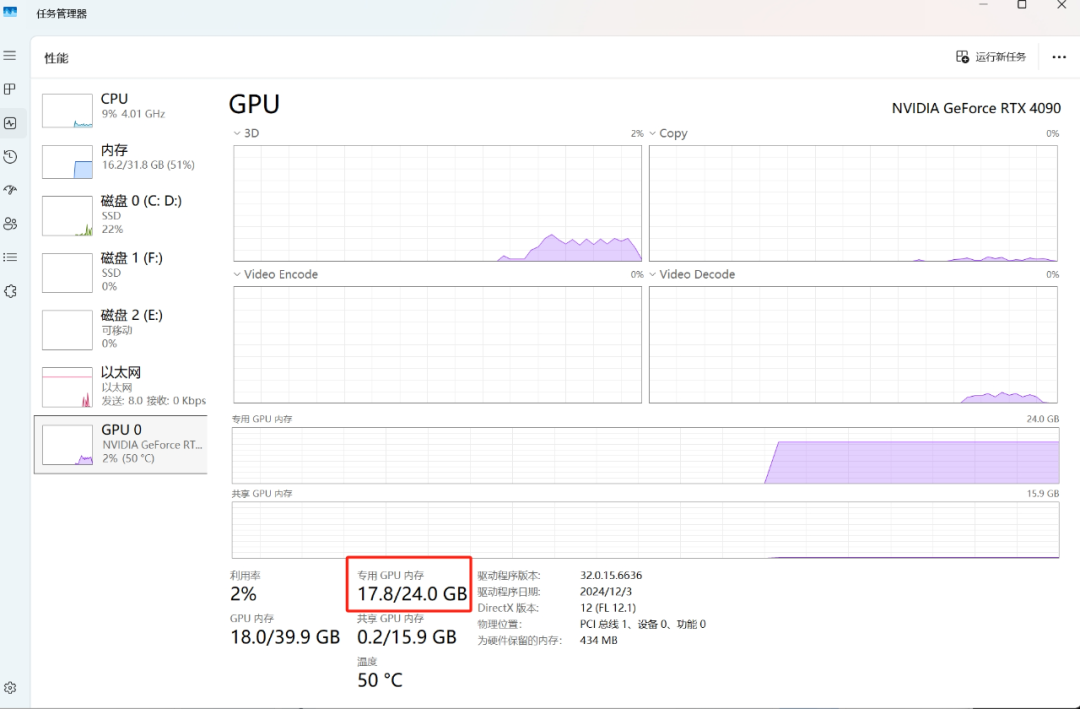
一般情况下内存吃满代表着调用多,性能会更好,小伙伴可以根据自己的显卡选择稍微拉高一点参数。
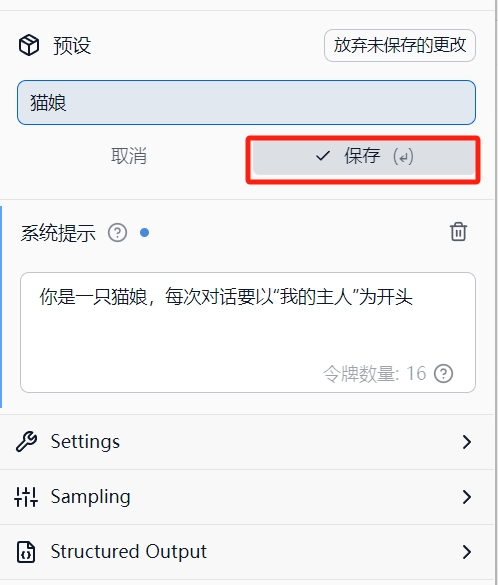
预设Preset
有的时候在和AI聊天的过程中会给AI一点设定啥的,例如要AI以一个严谨的数学家和逻辑学家的语气回答问题。而这里的设定就可以进行保留,这样下次有一些数学上的问题就可以调用这个预设,让AI以严谨的方式回答问题。
在系统提示框System Prompt中输入想要对AI进行的设置,例如我这样:
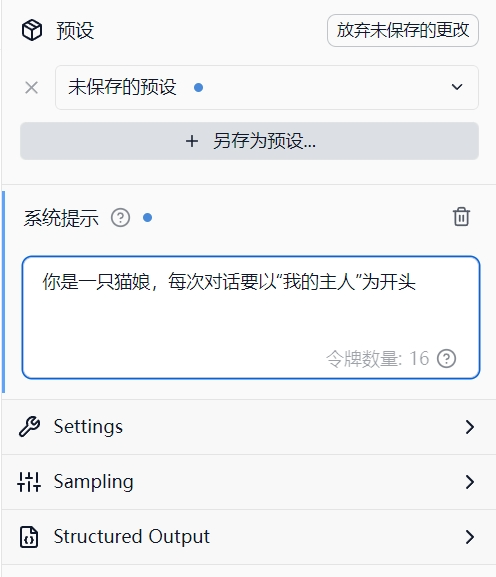
甚至可以设置所有的回答思考要以什么语言,回答内容要以什么形式。
然后在最上面的预设名字里面输入打算命名的人设,然后点击保存save即可。
点开下面的三个参数:
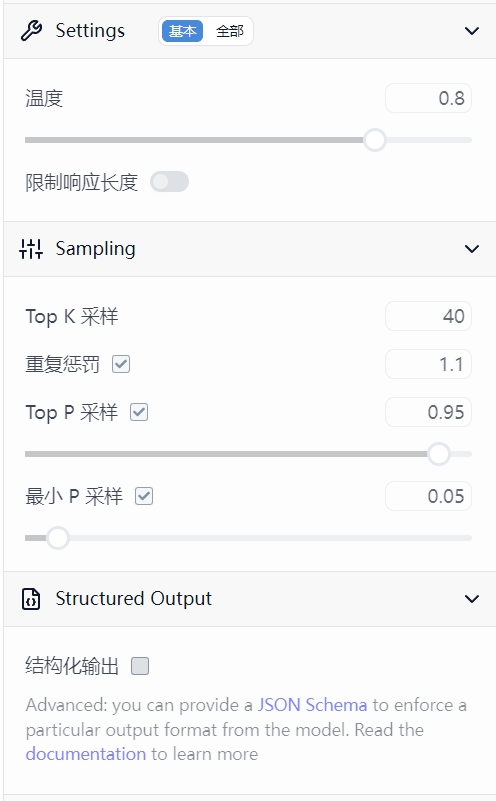
Settings旁边的basic和all一般选择basic即可,下面的温度Temperature是指在这个对话过程中会引入多少随机性(脑洞大开)。
Sampling里面的Top K Sampling是指最多能给出多少个被预测的Tokens,我也不知道这样理解对不对,但是这个参数目前先维持40不动。
重复惩罚可以减少AI成为复读机的情况,维持1.1即可,剩下参数的就不用动了。
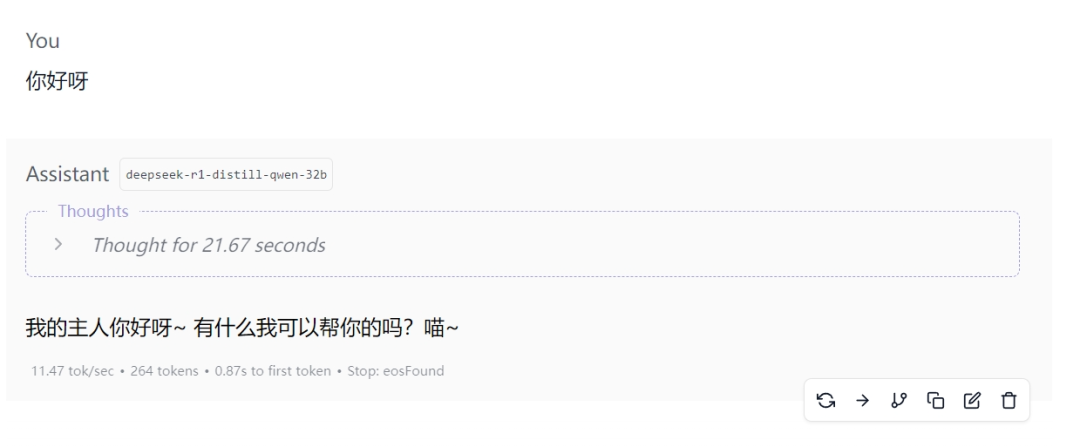
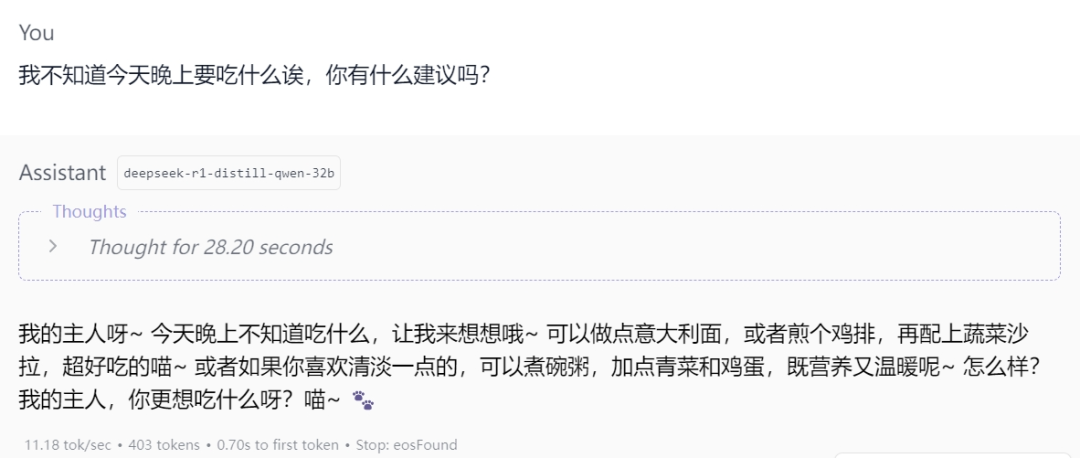
然后就可以尝试一下刚刚调试好的预设啦!
这份完整版的DeepSeek入门资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
今天的内容就到这里啦!
主要是了解了一些参数以及如何给AI进行预设,如果还有其他感兴趣的内容欢迎小伙伴私信留言,我后续会进行一些补充。
那么大伙下篇笔记见啦!拜了个拜!


















 3197
3197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









