






随着越来越多的AI应用推出,Prompt Optimization(提示词优化)逐渐成为AI模型性能提升的重要环节。北航、字节跳动与浙江大学最新合作的研究项目发布了一个名为ERM(Example-Guided Reflection Memory mechanism)的优化框架,为提示词的优化提供更加高效和准确的解决方案。

我将从多个角度简单剖析这一研究项目,力求为大家提供一篇科学严谨、通俗易懂的技术指南。
注意:研究者选择Doubao-pro(字节跳动,2024年)作为任务模型,并将其温度设置为0,以确保确定性输出。对于提示词优化器,研究者使用了gpt-4o-2024-05-13,这是GPT4o(OpenAI,2024年)的基础模型。其温度设置为1.0以促进多样化生成。

引言:当前Prompt优化的痛点
在当前的AI开发实践中,Prompt的质量直接决定了大语言模型的输出效果。然而,传统的Prompt优化方法存在两个关键问题:
-
反馈利用不充分:现有方法仅关注当前步骤的反馈,忽视了历史反馈中的宝贵信息。
-
示例选择欠优化:仅基于语义相似度选择示例,未考虑示例对任务性能的实际影响。
突破性创新:ERM框架
ByteDance和北航的研究团队提出了ERM(Exemplar-Guided Reflection with Memory)框架,这是一个非常有价值的Prompt优化方案,包含三个核心创新:
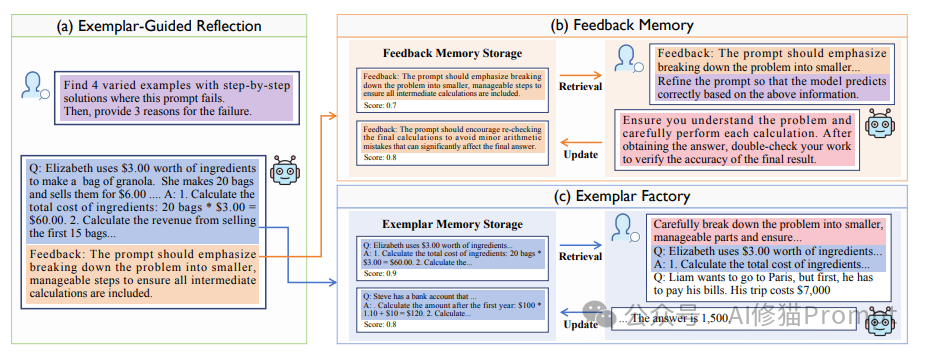
基于反馈的自动提示工程方法通常使用一个元提示,它指导大型语言模型(LLMs)评估当前案例,提供反馈,并生成精炼的提示。在这项工作中,研究者设计了一个指导性的元提示来选择具有详细解决方案过程的示例,并为当前案例生成反馈。这些反馈存储在反馈记忆中,并定期检索,以有效地指导提示的优化。此外,这些示例存储在示例工厂中,并进行评估,以提高预测准确性。
-
示例引导的反思机制
-
反馈记忆系统
-
示例工厂
以下是一个ERM 优化提示词示例:
ERM Optimized Prompt
## Task
You are tasked with determining the factual accuracy of statements based on their content,context, and widely accepted facts. Your goal is to decide whether the statement is false ("Yes") or true ("No"). For each example, you will be provided with:
1. **Statement**: The statement to be evaluated.
2. **Job title**: The job title of the person who made the statement (if available).
3. **State**: The state associated with the person who made the statement (if available).
4. **Party**: The political party of the person who made the statement (if available).
5. **Context**: The situation in which the statement was made, including any relevant background information.
Instructions:
1. **Evaluate the statement** based on verifiability and supporting evidence from **multiple reliable sources**.
2. **Cross-reference the statement** with verifiable data and widely accepted facts.
3. **Consider the context** in which the statement was made, including legislative, historical, and situational nuances.
4. **Ignore the political affiliation** and focus solely on the factual accuracy of the statement.
5. **If a statement is vague, lacks concrete details, or cannot be verified with reliable sources, answer "Yes."**
6. **If a statement is partially true but omits crucial context or presents facts misleadingly, answer "Yes."**
7. **If a statement is true and well-supported by reliable evidence, answer "No."**
8. **Pay special attention** to statements with mixed truths; if any part of the statement is misleading, answer "Yes."
9. **If a statement is statistically accurate but requires nuanced interpretation or context to be fully understood, answer "No."**
10. **Be mindful of hyperbolic, rhetorical, or satirical elements**. If the core factual content is accurate and verifiable, answer "No." If hyperbole or rhetoric leads to a misleading impression, answer "Yes."
11. **Prioritize factual accuracy** and ensure your decision is based on concrete evidence and context.
12. **For statements with mixed or nuanced truths**, focus on whether the core message is accurate. If the core message is misleading or omits critical context, answer "Yes." If the core message is accurate despite requiring nuanced interpretation, answer "No."
Example 1:
- Statement: "Every 28 hours an unarmed black person is shot by a cop."
- Job title: Activist
- State: California
- Party: none
- Context: a speech at a rally
- Answer: Yes
Example 2:
- Statement: "Congressman Renacci is under FBI investigation."
- Job title: Politician
- State: Ohio
- Party: republican
- Context: a news interview
- Answer: Yes
Example 3:
- Statement: "You can’t build a Christian church in Saudi Arabia."
- Job title: Radio/TV host
- State:
- Party: none
- Context: a broadcast on the Sean Hannity radio show
- Answer: No
## Output format
Answer Yes or No as labels.
## Prediction
Text: {input}
Label:
核心机制解析
1.1 示例引导的反思机制
研究者设计了一个指导性的元提示(meta-prompt),它能够:
-
识别典型的错误样本
-
为这些样本生成详细的解决方案
-
基于解决方案生成更有针对性的反馈
这种机制确保了反馈的质量和可操作性,深入剖析问题根源并为改进提供具体指导。
1.2 反馈记忆系统
反馈记忆系统是ERM的核心创新之一,它通过存储、检索和遗忘机制有效管理反馈信息。
存储机制:
-
为每条反馈分配优先级分数,确保重要信息得以保留。
-
使用反馈过滤策略,仅保存能够提升模型性能的反馈。
-
通过语义相似度计算,避免冗余反馈存储。
检索机制:
-
基于优先级分数选择最相关的反馈。
-
利用温度参数τf控制反馈选择的偏好,平衡探索与利用。
-
从高优先级反馈中随机选择若干条用于优化。
遗忘更新机制:
-
根据反馈效果动态调整其优先级分数。
-
成功反馈增加优先级,无效反馈降低优先级。
-
优先级低于阈值的反馈将被移除,确保知识库的精简和有效性。
1.3 示例工厂
示例工厂是ERM中的智能示例管理模块,有效存储、检索和更新有用的示例:
存储策略:
-
验证示例是否符合预期标签,确保存储的可靠性。
-
采用概率替换机制,避免重复存储和冗余。
-
为每个示例分配优先级,确保有效管理和更新。
检索策略:
-
结合优先级分数和语义相似度选择最合适的示例。
-
推理阶段选择最相关的示例以提高生成质量。
-
动态调整示例优先级,确保示例库保持最新和有效。
实现过程:技术细节与架构解析
2.1 架构概述
ERM优化框架整体由三个模块组成:
-
示例存储模块:存储先前所有交互的Prompt、生成结果及其相应的评价指标。
-
反思模块:在每次生成结束后,对生成内容进行分析、回顾,并根据评估反馈优化提示词。
-
提示生成模块:结合当前任务及反思模块的输入,生成优化后的提示词。
这种模块化架构的设计使得ERM框架的功能可以更为灵活地扩展或调整,适应不同的应用场景和优化需求。
2.2 反思模块的工作机制
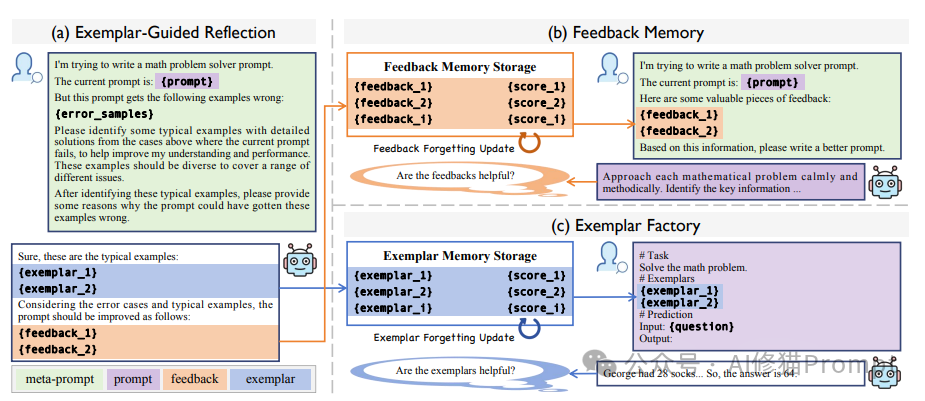
反思模块是ERM的核心组件之一。下图是一个ERM流程图。在错误预测样本中,使用指导性反思元提示来选择具有详细答案过程的示例,随后进行反馈生成。这些反馈存储在反馈记忆存储中,而示例存储在示例记忆存储中。这些存储的反馈定期检索,以有效地指导提示优化,根据其在增强优化中的有效性进行选择性遗忘。此外,这些示例被评估以提高预测准确性。
该模块采用了一种基于强化学习和启发式搜索相结合的方法:
-
强化学习:反思模块通过深度强化学习的手段不断评估Prompt与生成结果之间的对应关系。通过评估成功和失败案例,模型能够不断更新其策略,使得未来的Prompt生成更加准确。
-
启发式搜索:启发式搜索机制用于在知识库中检索最相关的提示词示例。这种方法可以显著减少搜索空间,并提高提示词优化的效率,使得模型能够快速找到相似的参考示例,避免重复试错。
通过强化学习与启发式搜索的结合,反思模块能够形成对每个任务的动态反馈机制,这使得提示词能够随着任务变化而自适应调整,优化效率和准确性得以提升。
2.3 提示生成模块:生成与优化的结合
提示生成模块结合了反思模块的输出,并通过对反思过程中识别的模式进行抽象,生成最优的提示词。在该模块中,研究者们使用了一种多层的Transformer架构,通过不同层级的嵌入表示,将生成过程中积累的反思经验与当前任务的目标结合,确保生成的提示词具有更强的上下文理解能力和生成针对性。
提示生成模块还加入了一个细化的微调过程,通过小批量的数据训练和人类反馈进一步优化提示词生成结果,最大限度减少误差和不精确性。
实验与结果分析
2.4 数据集与实验设置
研究者们使用了多个公开的数据集和内部收集的数据进行实验,数据覆盖了文本生成、代码补全、对话生成等不同的任务类型。基线对比中用了大家都熟悉的提示优化方法进行了对比(以下这些方法中OPRO、PromptBreeder、EvoPrompt、GPO我曾在之前的文章介绍过,也曾在赞赏群里分享过一些用于优化的系统提示词,具体您也可以搜一下之前的文章):

实验验证了ERM框架在多种任务下的适应性和有效性。为了评估ERM的表现,研究者们设计了以下实验步骤:
-
基线对比:将ERM与其他提示优化方法进行对比,包括人工优化、基于规则的优化、强化学习优化等。
-
多任务测试:使用不同任务类型的数据集,测试ERM在不同任务间的泛化能力。
-
人类评估:邀请经验丰富的Prompt工程师对生成结果进行主观评价,从生成质量、准确性和创意性等多个角度打分。
2.5 实验结果与性能突破
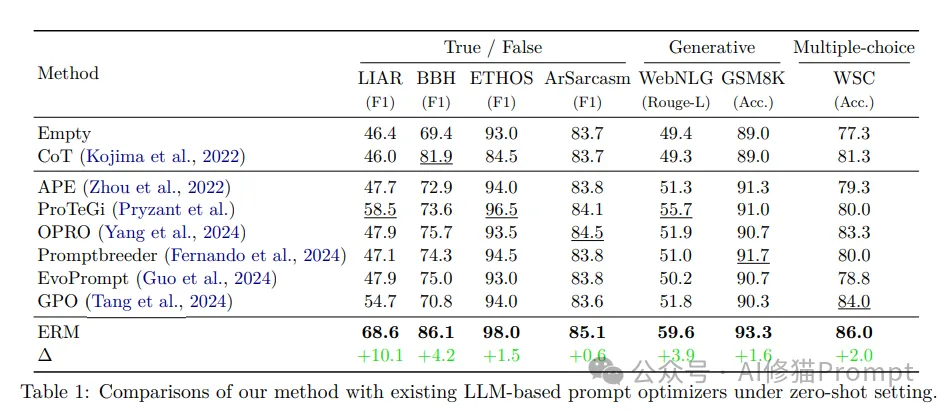
研究团队在7个标准数据集上进行了全面评估,结果令人振奋:
- 显著的性能提升:
-
LIAR数据集:F1分数提升10.1。
-
BBH数据集:准确率提升4.2。
-
WebNLG数据集:Rouge-L分数提升3.9。
-
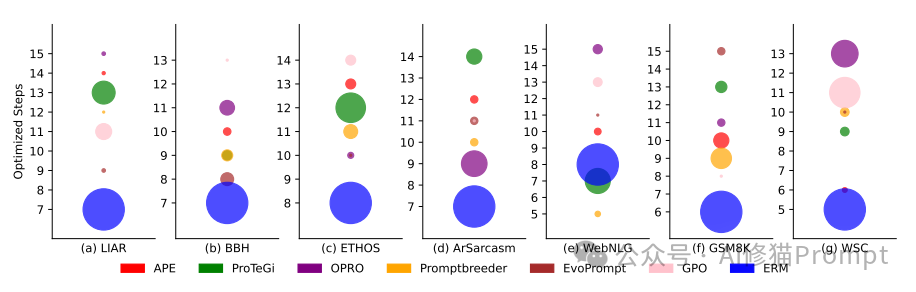
优化效率的大幅提升:
-
与ProTeGi相比,优化步骤减少了约50%。
-
在保持高性能的同时显著提升了收敛速度。
-
各组件的贡献:
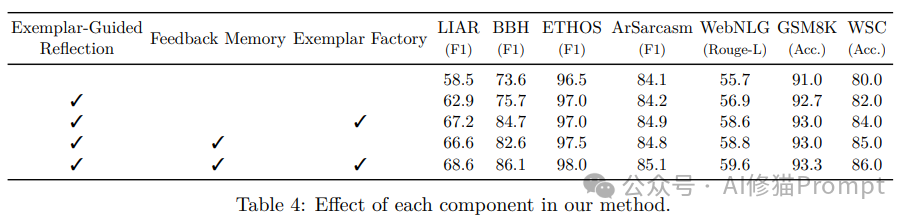
-
示例工厂:在LIAR数据集上提升3.7个F1分数。
-
反馈记忆:带来2.0的性能提升。
-
三个组件的协同效应带来最佳性能。
对Prompt工程师的实践启示
3.1 反馈管理的重要性
-
建立系统化的反馈收集机制。
-
重视历史反馈的价值。
-
实施动态的反馈评估系统。
3.2 示例选择的优化策略
-
不要仅依赖语义相似度。
-
建立示例效果评估机制。
-
维护动态更新的示例库。
3.3 优化流程的改进
-
采用渐进式优化策略。
-
建立效果评估反馈循环。
-
重视优化过程的效率。
ERM的实际应用与未来前景
4.1 在AI产品中的应用
对于Prompt工程师而言,ERM的最大优势在于其能够自适应地优化提示词,这意味着在产品开发过程中,可以显著降低人工调试的工作量。例如,在对话AI中,ERM能够根据用户的历史对话示例快速生成高质量的Prompt,从而提高对话的自然性和流畅性。
此外,ERM在代码生成任务中也展现了极大的潜力。通过使用以往类似代码片段作为示例,ERM能够帮助工程师快速生成符合规范且精确的代码提示词。这对于开发者在日常工作中高效生成代码、降低错误率具有重要意义。
4.2 持续学习与反思:ERM的扩展性
ERM的设计初衷不仅是作为一个提示词优化框架,而是作为一个具有持续学习和反思能力的系统。在未来,ERM可以扩展为一个跨任务、跨领域的知识存储与自我改进系统,使得AI在应对未知任务时能够从历史经验中更好地汲取教训,进行自我优化。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









