






论文分享 | 多模态大模型相关研究进展
我们从2024-12-25到2024-12-31的44篇文章中精选出5篇优秀的工作分享给读者。
-
ETTA: Elucidating the Design Space of Text-to-Audio Models
-
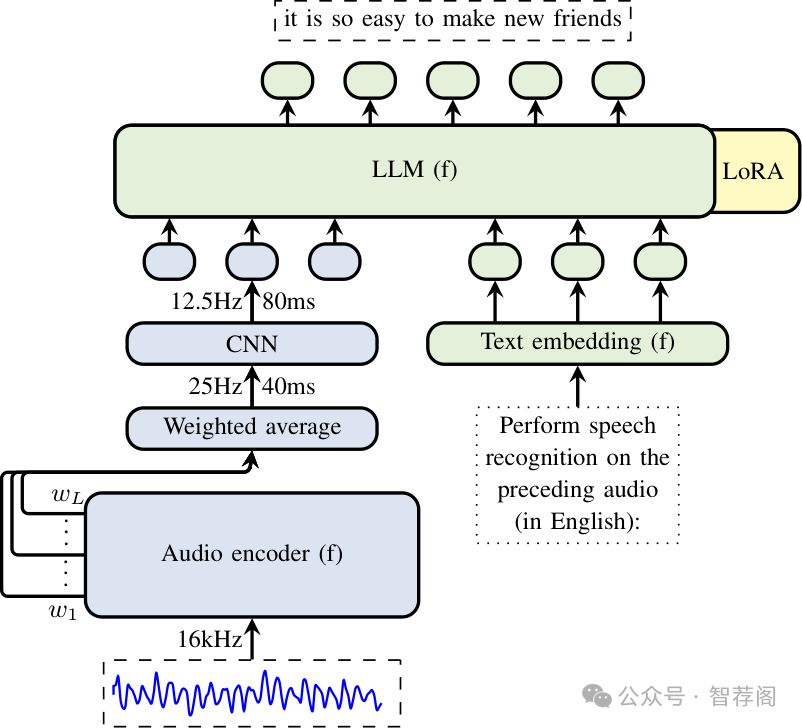
Zero-resource Speech Translation and Recognition with LLMs
-
CrossSpeech++: Cross-lingual Speech Synthesis with Decoupled Language and Speaker Generation
-
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
-
Are audio DeepFake detection models polyglots?
1.ETTA: Elucidating the Design Space of Text-to-Audio Models
Authors: Sang-gil Lee, Zhifeng Kong, Arushi Goel, Sungwon Kim, Rafael Valle, Bryan Catanzaro
https://arxiv.org/abs/2412.19351
论文摘要
Recent years have seen significant progress in Text-To-Audio (TTA) synthesis, en abling users to enrich their creative workflows with synthetic audio generated from natural language prompts. Despite this progress, the effects of data, model archi tecture, training objective functions, and sampling strategies on target benchmarks are not well understood. With the purpose of providing a holistic understanding of the design space of TTA models, we set up a large-scale empirical experiment focused on diffusion and flow matching models. Our contributions include: 1) AF-Synthetic, a large dataset of high quality synthetic captions obtained from an audio understanding model; 2) a systematic comparison of different architectural, training, and inference design choices for TTA models; 3) an analysis of sampling methods and their Pareto curves with respect to generation quality and inference speed. We leverage the knowledge obtained from this extensive analysis to pro pose our best model dubbed Elucidated Text-To-Audio (ETTA). When evaluated on AudioCaps and MusicCaps, ETTA provides improvements over the baselines trained on publicly available data, while being competitive with models trained on proprietary data. Finally, we show ETTA’s improved ability to generate creative audio following complex and imaginative captions– a task that is more challenging than current benchmarks.
论文简评
本篇论文通过系统性的研究,探讨了文本到音频(Text-to-Audio)模型的设计空间。通过对影响模型性能的各种因素进行全面的实证分析,提出了AF-Synthetic大型合成文本集,并对不同模型架构、训练目标以及采样方法进行了详尽比较。最终,提出的模型E-ETTA在多个基准数据集上表现出了显著提升,表明其具有实际应用价值和潜在影响力,对于推动该领域的发展起到了积极作用。这一系列研究成果不仅为未来TTS技术提供了新方向,也为人工智能领域的研究开辟了新思路。
2.Zero-resource Speech Translation and Recognition with LLMs
Authors: Karel Mundnich, Xing Niu, Prashant Mathur, Srikanth Ronanki, Brady Houston, Veera Raghavendra Elluru, Nilaksh Das, Zejiang Hou, Goeric Huybrechts, Anshu Bhatia, Daniel Garcia-Romero, Kyu J. Han, Katrin Kirchhoff
https://arxiv.org/abs/2412.18566
论文摘要
Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable of achieving BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
论文简评
本文提出了一种基于多语言大型语言模型(LLMs)的零资源语音翻译(ST)和自动语音识别(ASR)方法,并通过介绍一个轻量级适应模块来连接预训练的语音编码器到LLM的词嵌入空间。实验结果显示,在未见的语言上取得了令人满意的性能指标,表明了所提出方案的有效性。该研究解决了语音处理中的一个重大挑战,特别是对于没有配对音频-文本数据的语言。此外,利用一种新颖的方法,该方案结合了多语言语音编码器和LLMs,可能有助于推动语音处理领域的最新进展。实验结果展示了使用所提出的策略在语音翻译和语音识别任务上的可行性。
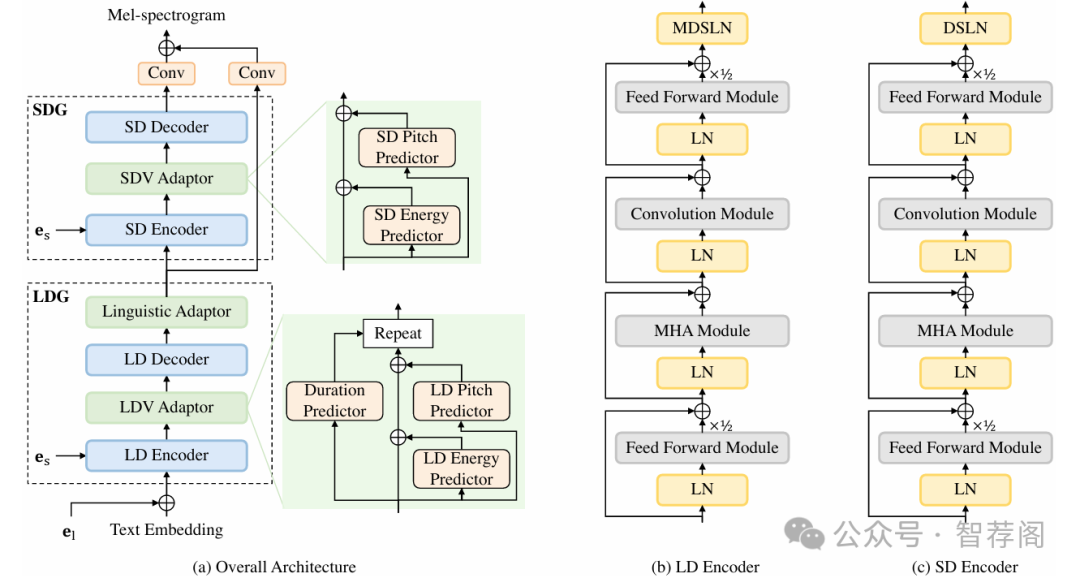
3.CrossSpeech++: Cross-lingual Speech Synthesis with Decoupled Language and Speaker Generation
Authors: Ji-Hoon Kim, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
https://arxiv.org/abs/2412.20048
论文摘要
The goal of this work is to generate natural speech in multiple languages while maintaining the same speaker identity, a task known as cross-lingual speech synthesis. A key challenge of cross-lingual speech synthesis is the language-speaker entanglement problem, which causes the quality of cross-lingual systems to lag behind that of intra-lingual systems. In this paper, we propose CrossSpeech++, which effectively disentangles language and speaker information and significantly improves the quality of cross-lingual speech synthesis. To this end, we break the complex speech generation pipeline into two simple components: language-dependent and speaker-dependent generators. The language-dependent generator produces linguistic variations that are not biased by specific speaker attributes. The speaker-dependent generator models acoustic variations that characterize speaker identity. By handling each type of information in separate modules, our method can effectively disentangle language and speaker representation. We conduct extensive experiments using various metrics, and demonstrate that CrossSpeech++ achieves significant improvements in cross-lingual speech synthesis, outperforming existing methods by a large margin.
论文简评
这篇关于跨语言语音合成的论文提出了CrossSpeech++框架,旨在解决跨语言语音合成中存在的一种挑战:语言与说话者之间的耦合问题。该文提出了一种新颖的方法,即分离语言依赖和说话者依赖特征生成器,通过大量的实验验证了这种方法的有效性,显著提高了合成语音的质量。
论文的核心亮点在于其提出的架构,它能够有效地解决语言与说话者之间的耦合问题,并且可以独立地处理两个维度的信息。这种创新的设计使得CrossSpeech++在解决跨语言语音合成中的关键技术问题上取得了突破性进展。
此外,该文还进行了广泛的实验测试,以评估不同方法的效果,证明了CrossSpeech++在性能上的优越性。这些实证研究不仅为相关领域的研究人员提供了宝贵参考,也为实际应用提供了一个可行的技术方案。
总的来说,CrossSpeech++是一个具有重要理论意义和实用价值的研究成果。它解决了跨语言语音合成领域的一个长期存在的难题,同时展示了强大的可扩展性和灵活性,有望在未来的发展中继续发挥重要作用。
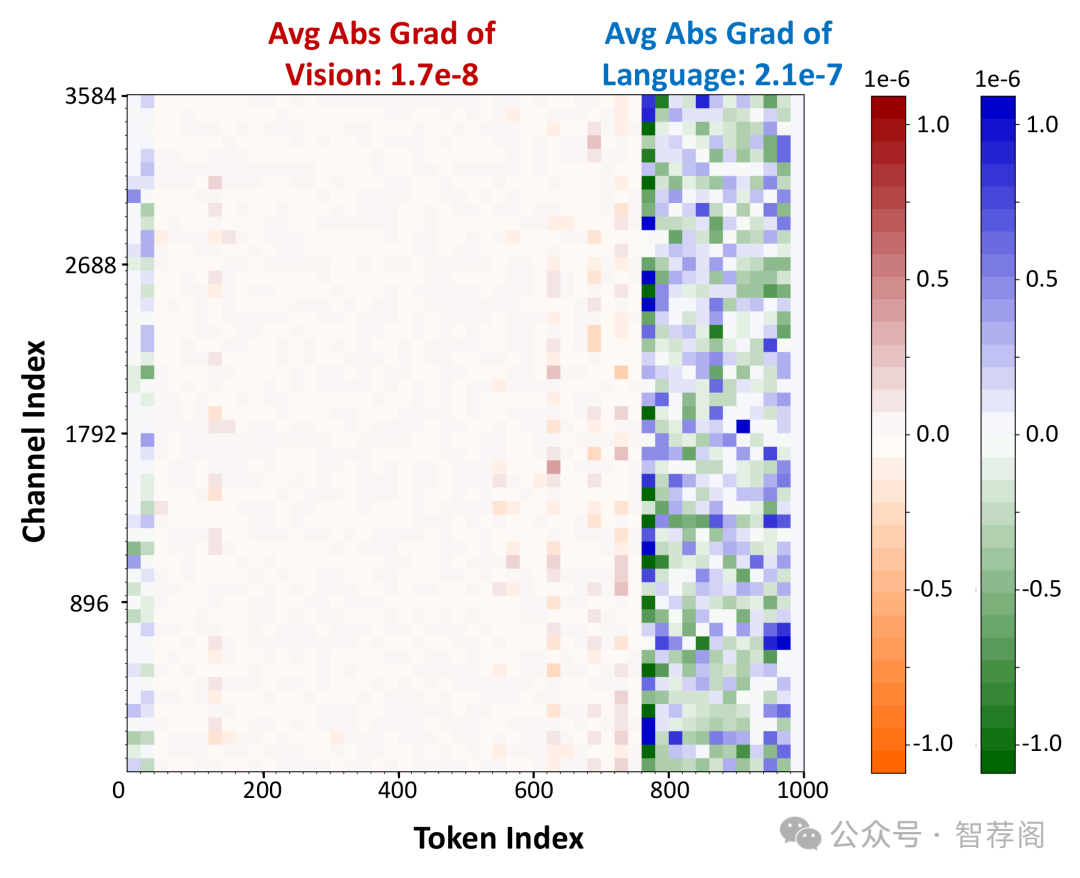
4.MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Authors: Shiyao Li, Yingchun Hu, Xuefei Ning, Xihui Liu, Ke Hong, Xiaotao Jia, Xiuhong Li, Yaqi Yan, Pei Ran, Guohao Dai, Shengen Yan, Huazhong Yang, Yu Wang
https://arxiv.org/abs/2412.19509
论文摘要
Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings significant memory and computation overhead, posing challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To address this issue, we propose a simple yet effective method, Modality-Balanced Quantization, for large VLMs. Specifically, this method incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that this method can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4× speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
论文简评
这篇论文主要探讨了大规模视觉语言模型(VLM)中视觉与语言符号之间的敏感性差异,并提出了一种名为Modality-Balanced Quantization(MBQ)的方法来提升这些模型的性能。该方法通过调整对视觉和语言符号敏感性的处理,来优化量化过程中的参数选择,从而提高了任务的准确率。实验结果表明,在多种量化方案下,这种方法都能显著提高VLM的性能,尤其是在不同架构和量化条件下。因此,这篇论文为如何有效处理视觉与语言数据之间复杂关系提供了新思路,对于推动视觉语言模型的发展具有重要意义。
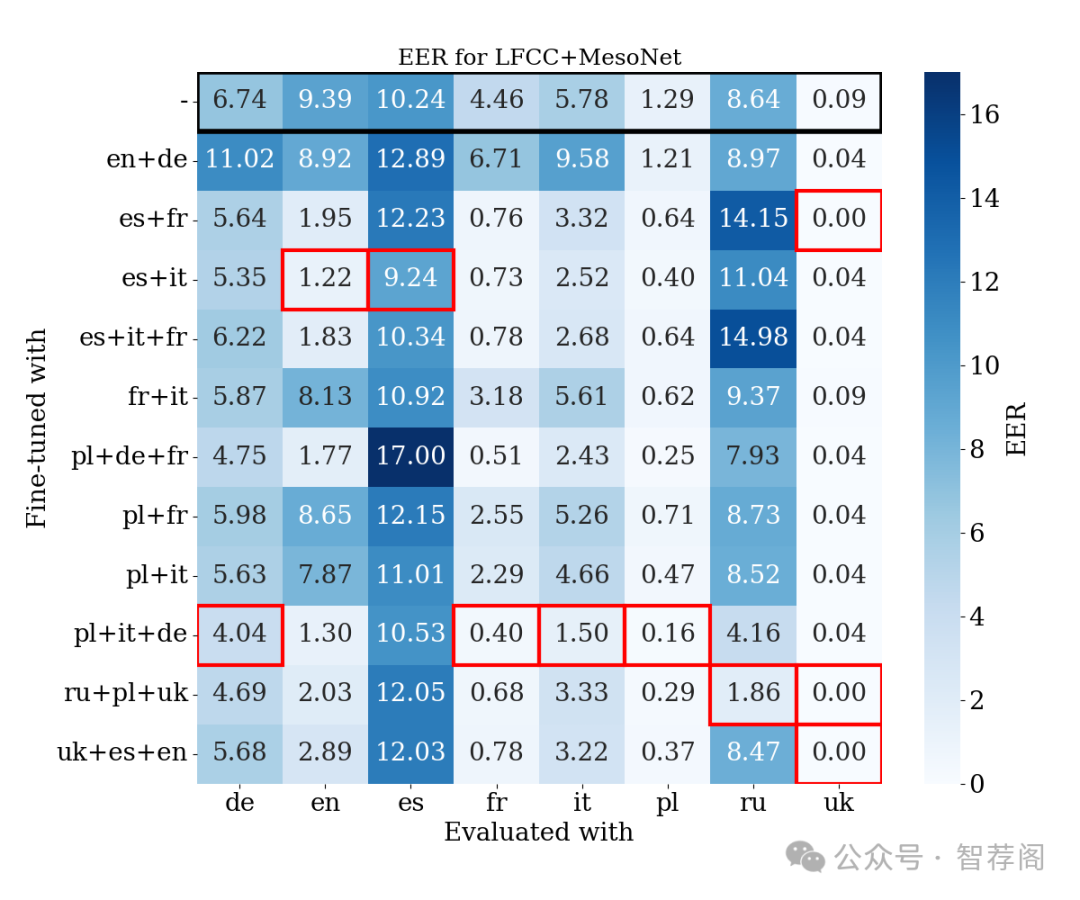
5.Are audio DeepFake detection models polyglots?
Authors: Bartłomiej Marek, Piotr Kawa, Piotr Syga
https://arxiv.org/abs/2412.17924
论文摘要
Since the majority of audio DeepFake (DF) detection methods are trained on English-centric datasets, their applicability to non-English languages remains largely unexplored. In this work, we present a benchmark for the multilingual audio DF detection challenge by evaluating various adaptation strategies. Our experiments focus on analyzing models trained on English benchmark datasets, as well as intra-linguistic (same-language) and cross-linguistic adaptation approaches. Our results indicate considerable variations in detection efficacy, highlighting the difficulties of multilingual settings. We show that limiting the dataset to English negatively impacts efficacy, while stressing the importance of data in the target language.
论文简评
该论文针对音频深度伪造检测领域的一个重要问题——如何在非英语语言中有效检测音频深度伪造进行了深入研究。通过比较和分析现有模型的表现,该文揭示了多语境下音频深度伪造检测的有效性,并强调了语言特定训练的重要性和跨语言设置带来的挑战。此外,论文还提出了一项多语言音频深度伪造检测基准,旨在为解决这一问题提供参考框架。整体来看,该文不仅对音频深度伪造检测领域具有重要的理论意义,也为实际应用提供了实践指导。因此,可以认为该论文是一个有价值的学术成果。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









