






就在前天,Stability AI 正式发布了 Stable Diffusion 3.5版本,包括 3 款强大的模型:
-
Stable Diffusion 3.5 Large:拥有 80 亿参数,提供卓越的图像质量和精确的提示词响应,非常适合在 1 兆像素分辨率下的专业用例。
-
Stable Diffusion 3.5 Large Turbo:这是 Large 模型的加速版本,仅需 4 步即可生成高质量图像,速度更快。
-
Stable Diffusion 3.5 Medium(将于 10 月 29 日发布):拥有 26 亿参数,针对消费级硬件进行了优化,可在 0.25 到 2 兆像素分辨率下表现出色。
这些模型在 Stability AI 社区许可下免费供商业和非商业使用。
模型下载地址
国内可以通过modelscope下载:Stable Diffusion 3.5 Large下载:https://modelscope.cn/models/AI-ModelScope/stable-diffusion-3.5-large/resolve/master/sd3.5_large.safetensors
Stable Diffusion 3.5 Large Turbo下载:https://modelscope.cn/models/AI-ModelScope/stable-diffusion-3.5-large-turbo/resolve/master/sd3.5_large_turbo.safetensors
也可以在 Hugging Face 上下载:Stable Diffusion 3.5 Large下载:https://huggingface.co/stabilityai/stable-diffusion-3.5-large
Stable Diffusion 3.5 Large Turbo下载:https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

模型特点
Stable Diffusion 3.5 在以下几个方面表现出色,成为市场上最具可定制性和可访问性的图像模型之一,同时在提示词响应和图像质量方面保持了顶尖水平:
-
可定制性:可以轻松微调模型以满足您的特定创作需求,或基于定制化工作流构建应用程序。
-
高效性能:经过优化,能够在标准消费级硬件上运行,尤其是 Stable Diffusion 3.5 Medium 和 Stable Diffusion 3.5 Large Turbo 模型。
-
多样化输出:无需复杂提示词,即可生成代表不同肤色和特征的图像,涵盖全球多样性。
-
多样风格:支持生成多种风格和美学,如 3D、摄影、绘画、线条画及几乎任何视觉风格。
此外,分析表明,Stable Diffusion 3.5 Large 在提示词响应性方面领先市场,并在图像质量上媲美更大规模的模型。Stable Diffusion 3.5 Large Turbo 在同类模型中具有最快的推理时间,同时在图像质量和提示词响应性方面仍具竞争力,即便与未精简的同类大小模型相比也是如此。
Stable Diffusion 3.5 Medium 超越了其他中型模型,在提示词响应性和图像质量方面表现出色,是高效、高质量表现的首选。
下图是官方提供的模型对比,可以看出其在提示词方面是效果最好的,但是美学方面不如Flux。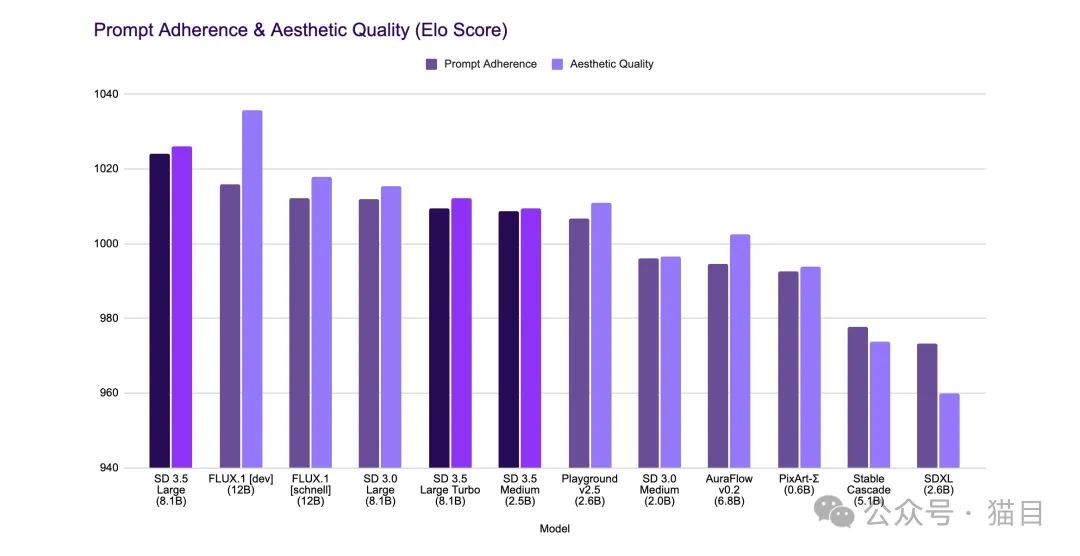
在ComfyUI中的使用
工作流截图
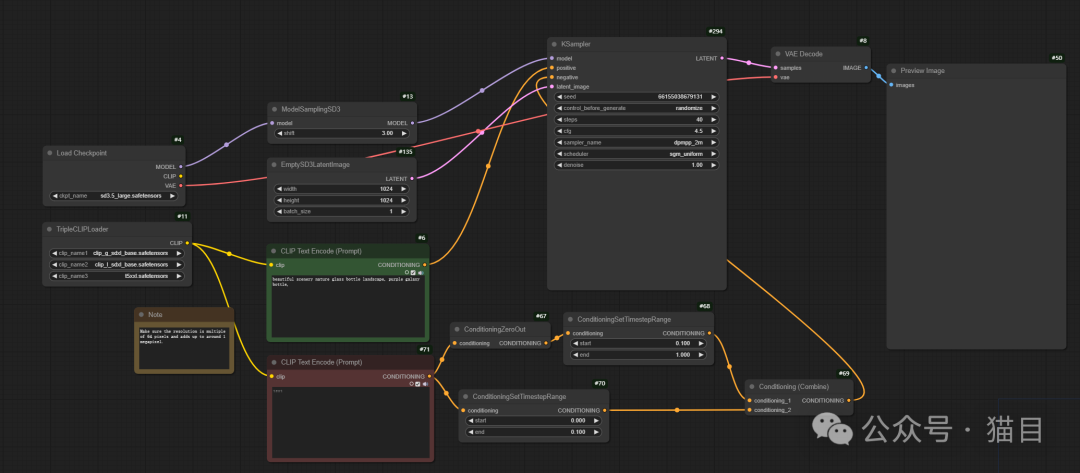 工作流下载地址猫目社区:https://maomu.com/workflow/DFVH8NiYXe
工作流下载地址猫目社区:https://maomu.com/workflow/DFVH8NiYXe
在ComfyUI中的使用步骤
第一步:先将ComfyUI更新到最新版本;第二步:将Stable Diffusion 3.5 Large或者Stable Diffusion 3.5 Large Turbo下载到ComfyUI\models\checkpoints 目录下;
以下是官方提供的工作流和模型:https://huggingface.co/stabilityai/stable-diffusion-3.5-large/tree/main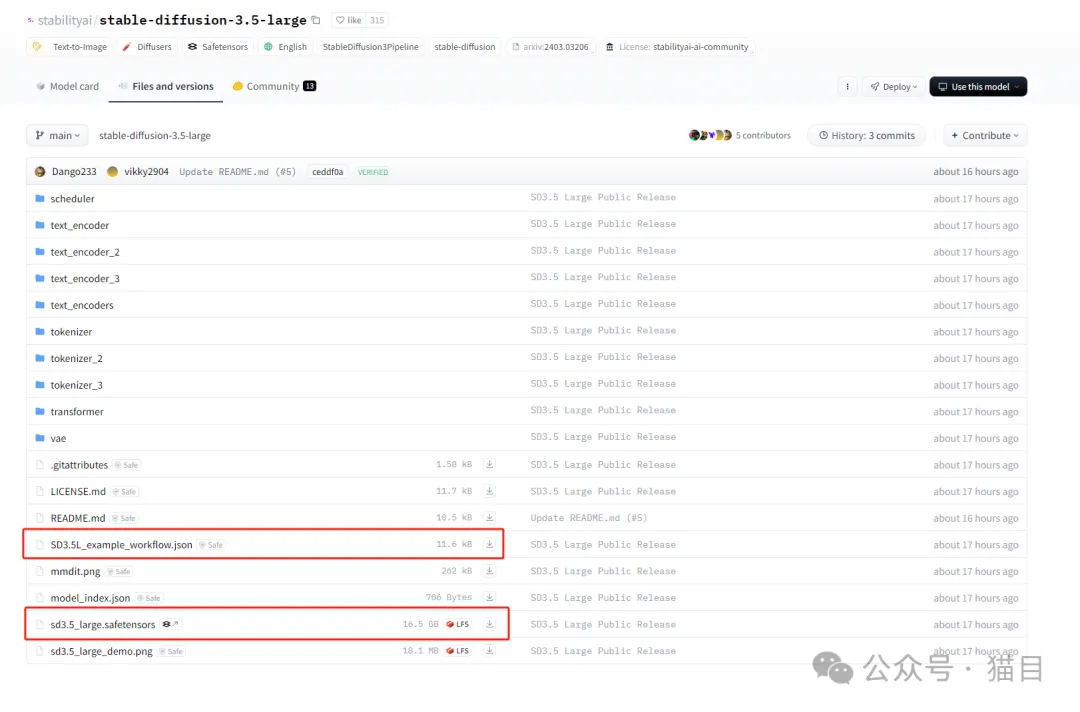
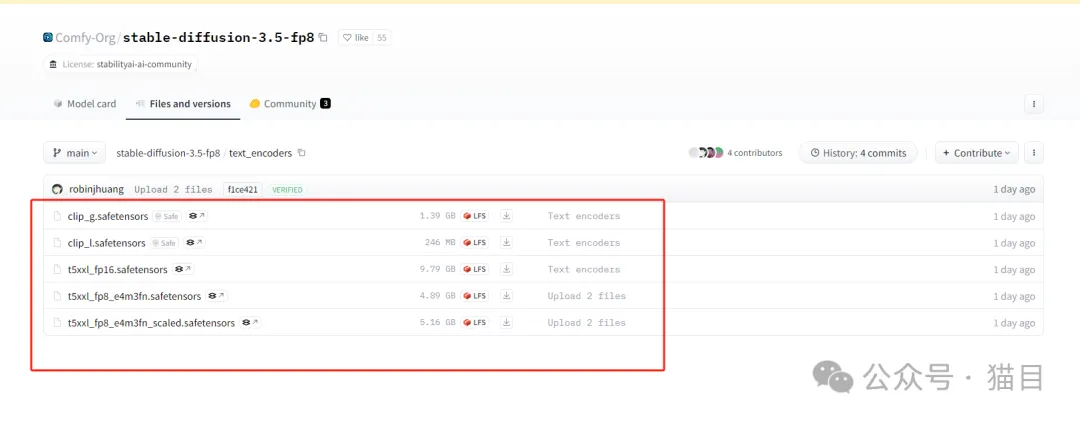
第三步:加载 Clip 模型,将将clip_g.safetensors、clip_l.safetensors和t5xxl_fp16.safetensors下载到 ComfyUI\models\clip 目录下,(如果之前有下载过的,就不用再次下载)
以下是官方提供的 Clip 模型:https://huggingface.co/stabilityai/stable-diffusion-3.5-large/tree/main/text_encoders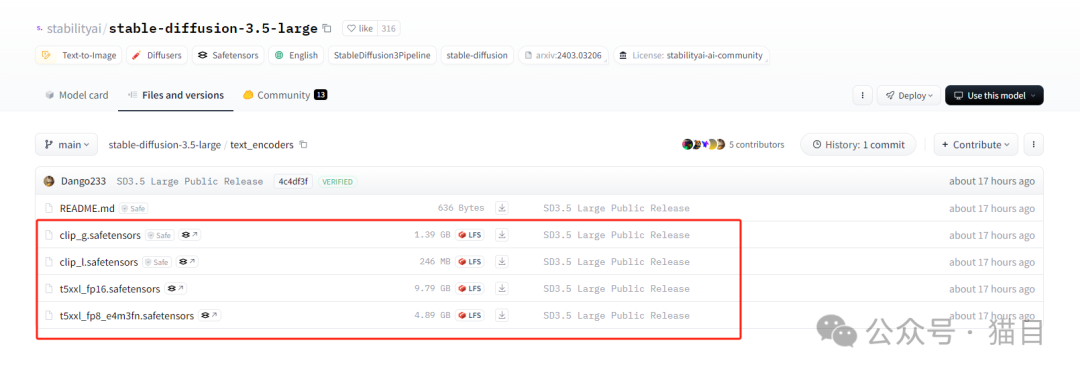 第四步:将工作流拖入ComfyUI中,如果有缺失的节点那就进行安装。
第四步:将工作流拖入ComfyUI中,如果有缺失的节点那就进行安装。
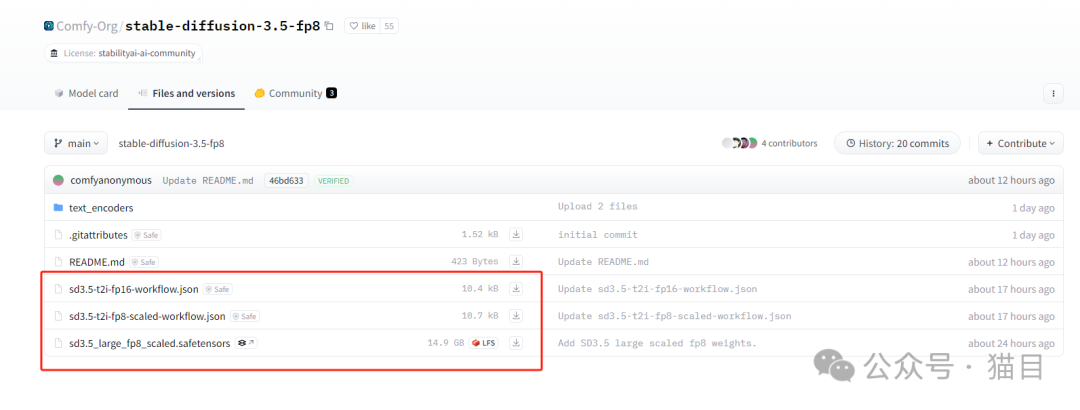
低内存解决方案
如果在生图的过程中崩溃,可能是内存不足,可以通过以下方法解决:
-
使用fp8_scaled 工作流 json(实验性)和fp8 缩放模型作为低 vram 选项。
-
可以尝试使用t5xxl_fp8_e4m3fn_scaled.safetensors或t5xxl_fp8_e4m3fn.safetensors代替 t5xxl_fp16 以降低内存使用率。但是,如果你的 RAM 超过 32GB,建议使用 t5xxl_fp16。
工作流和模型下载地址:https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8/tree/main
出图测试:
为了全面比较 FLUX 和 Stable Diffusion 3.5 的出图效果,我们可以比较它们在风格、细节、色彩和构图等方面的差异。覆盖不同风格的提示词,涵盖了写实、插画、3D建模等风格。
写实风格
提示词:A highly detailed, ultra-realistic portrait of a young woman, smooth skin, morning light, deep eyes 中文:高度详细、超现实的年轻女子肖像,光滑的皮肤,晨光,深邃的眼睛

插画风格
提示词:A vibrant and colorful fantasy landscape with towering castles, dragons flying in the sky, and magical creatures in the foreground, in the style of a digital painting 中文:充满活力、色彩缤纷的奇幻景观,有高耸的城堡、飞翔的巨龙、前景中的神奇生物,具有数字绘画的风格

3D 渲染风格
提示词:A highly detailed 3D render of a futuristic city at night, with glowing neon lights, flying cars, and tall skyscrapers, cyberpunk aesthetic. 中文:高度详细的 3D 渲染未来城市的夜晚,闪烁的霓虹灯、飞行的汽车和高耸的摩天大楼,赛博朋克美学。

漫画风格
提示词:A dynamic action scene of a superhero flying through the city, with exaggerated expressions, bold lines, and vibrant comic book colors. 中文:超级英雄飞越城市的动态动作场景,夸张的表情、大胆的线条、充满活力的漫画色彩。

复古风格
提示词:A sepia-toned, 1920s vintage photograph of a couple dancing in an elegant ballroom, with antique decor and dim lighting. 中文:一张深褐色色调的 1920 年代复古照片,照片上是一对情侣在优雅的舞厅跳舞,舞厅拥有古色古香的装饰和昏暗的灯光

极简风格
提示词:A minimalist black and white abstract line art of a cat, clean lines and simple shapes. 中文:一只猫的简约黑白抽象线条艺术,干净的线条和简单的形状
 以上效果都是第一次生图的效果。
以上效果都是第一次生图的效果。
结语
最后期待官方出的 Stable Diffusion 3.5 Medium和相关的sd3.5 ControlNet模型。

这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









