







基于 PyTorch 的模型量化、剪枝和蒸馏
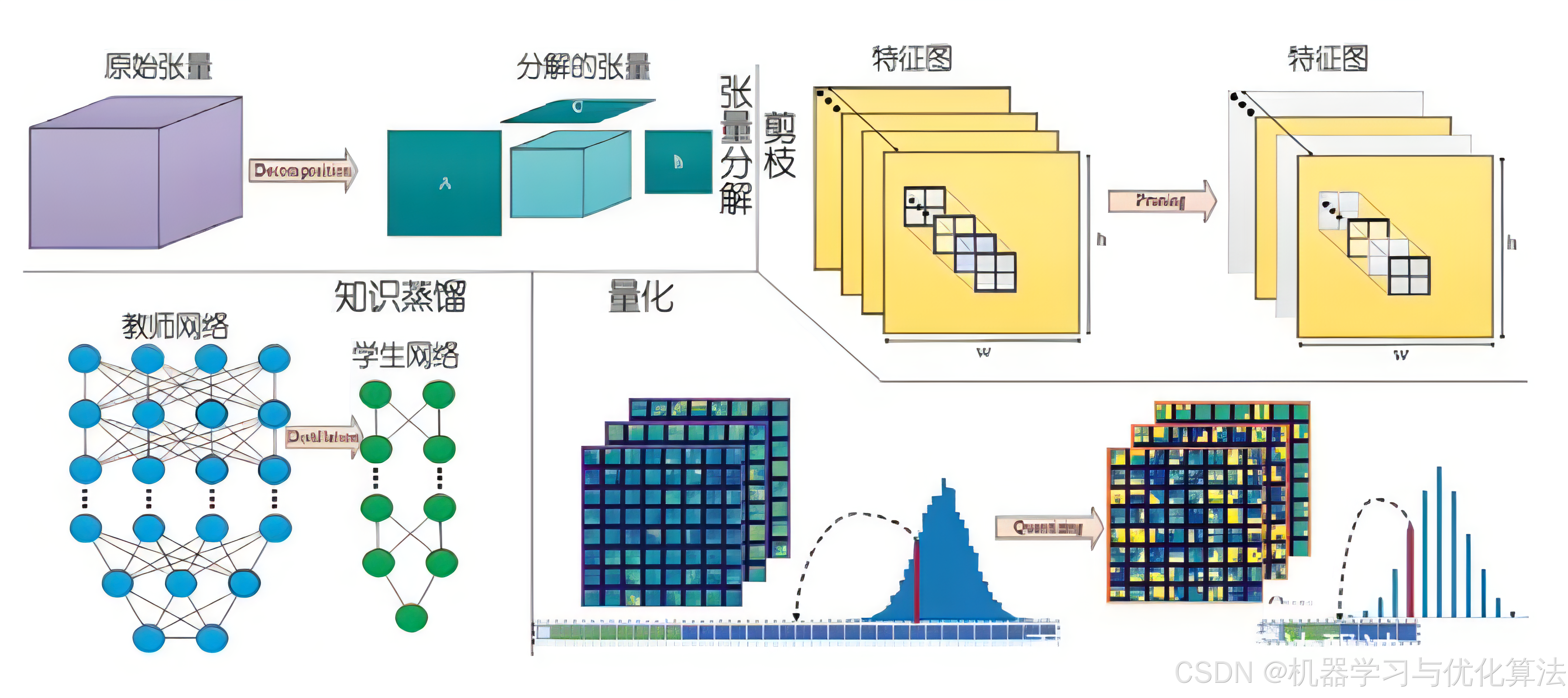
1. 模型量化
1.1 原理介绍
模型量化是将模型参数从高精度(通常是 float32)转换为低精度(如 int8 或更低)的过程。这种技术可以显著减少模型大小、降低计算复杂度,并加快推理速度,同时尽可能保持模型的性能。

量化的主要方法包括:
-
动态量化:
- 在推理时动态地将权重从 float32 量化为 int8。
- 激活值在计算过程中保持为浮点数。
- 适用于 RNN 和变换器等模型。
-
静态量化:
- 在推理之前,预先将权重从 float32 量化为 int8。
- 在推理过程中,激活值也被量化。
- 需要校准数据来确定激活值的量化参数。
-
量化感知训练(QAT):
- 在训练过程中模拟量化操作。
- 允许模型适应量化带来的精度损失。
- 通常能够获得比后量化更高的精度。
1.2 PyTorch 实现
import torch
# 1. 动态量化
model_fp32 = MyModel()
model_int8 = torch.quantization.quantize_dynamic(
model_fp32, # 原始模型
{
torch.nn.Linear, torch.nn.LSTM}, # 要量化的层类型
dtype=torch.qint8 # 量化后的数据类型
)
# 2. 静态量化
model_fp32 = MyModel()
model_fp32.eval() # 设置为评估模式
# 设置量化配置
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_fp32_prepared = torch.quantization.prepare(model_fp32)
# 使用校准数据进行校准
with torch.no_grad():
for batch in calibration_data:
model_fp32_prepared(batch)
# 转换模型
model_int8 = torch.quantization.convert(model_fp32_prepared)
# 3. 量化感知训练
model_fp32 = MyModel()
model_fp32.train(</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









