






目录
摘要
本文探讨了序列到序列(seq2seq)模型的应用范围,并详细阐述了Transformer模型的架构基础。文章中不仅对Transformer模型的各个组成部分进行了具体阐述,还介绍了其训练和推理过程。特别是,文章重点介绍了编码器和解码器的计算步骤和方法。
Abstract
This article explores the application scope of sequence-to-sequence (seq2seq) models and elaborates on the foundational architecture of the Transformer model. The article not only provides a detailed exposition of the various components of the Transformer model but also introduces its training and inference processes. In particular, the article highlights the computational steps and methods of the encoder and decoder.
Transformer
Transformer 是一种基于自注意力机制的深度神经网络模型,具有强大的并行计算能力和出色的对序列数据的处理能力。
transformer的核心组件:
- 自注意力机制:这是 Transformer 的核心。它能够计算输入序列中每个位置与其他位置之间的关联程度,从而确定每个位置的重要性权重。就像在一个句子中,它可以根据上下文来确定每个单词对于理解整个句子的重要性。例如,在处理 “The dog chased the cat because it was hungry.” 这句话时,自注意力机制能够明确 “it” 与 “dog” 的关联更强,从而更好地理解文本的语义。
- 多头注意力机制:由多个自注意力机制组成,每个头都可以关注输入序列的不同方面,捕捉更丰富的语义信息。不同的头可能会聚焦于不同的语义关系,如同义词、反义词、上下位词等,组合起来就能更全面地理解文本。
- 编码器和解码器:
- 编码器:负责将输入序列转换为一个固定长度的向量表示,这个向量包含了输入序列的所有重要信息。以机器翻译为例,编码器会将源语言句子编码成一个向量,供解码器使用。
- 解码器:根据编码器输出的向量和之前生成的输出序列,逐步生成目标语言的句子。它会在每个生成步骤中,结合编码器的信息和已生成的部分输出,预测下一个最可能的单词或符号。
transformer是一种 sequence to sequence (seq2seq)的模型 。seq2seq任务的输出长度和输入长度不一定相等,具体的输出长度是由模型决定的,例如,语音识别、机器翻译、语音翻译等任务、聊天机器人等 。
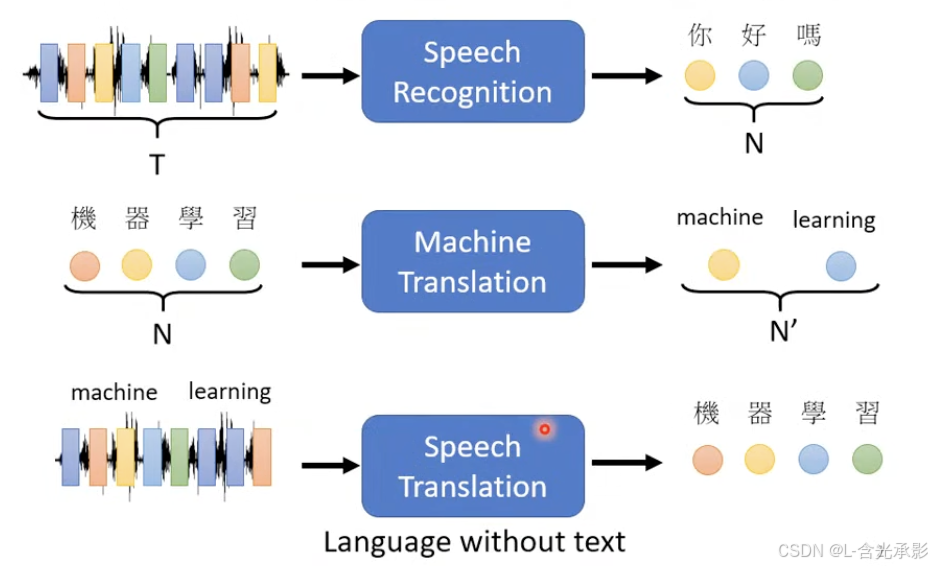
seq2seq
seq2seq 模型在NLP领域上的应用非常广泛,很多NLP领域的任务可以看成是Question和Answering(QA)的任务,如翻译、文章摘要等等。

QA问题可以用seq2seq的模型来解决,将问题和原本的输入看作seq2seq模型的输入,将原本的输出看作answer。另外,对于NLP任务和多数的语音相关的任务而言,为这些具体任务客制化模型得到的效果通常会更好。
对于某些其他任务,也可以用seq2seq模型来解决,如语法解析、多标签分类任务、目标检测等任务。
seq2seq的结构
一般的 seq2seq 分为编码器和解码器两部分,编码器接收输入序列并进行处理,然后将处理结果传给解码器,解码器来生成输出序列。最典型的seq2seq就是transformer,接下来的编码器和解码器也是针对transformer来进行讲解。
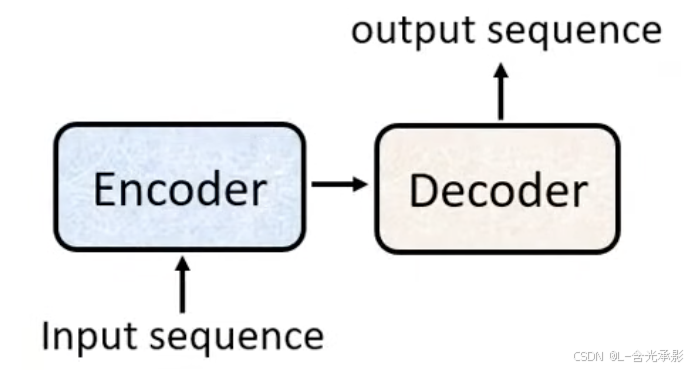
编码器(encoder)
编码器的任务就是接收一组向量,输出同样多的向量,这种任务用RNN,CNN和自注意力机制都可以做到,在Transformer的编码器中用到的是自注意力机制。
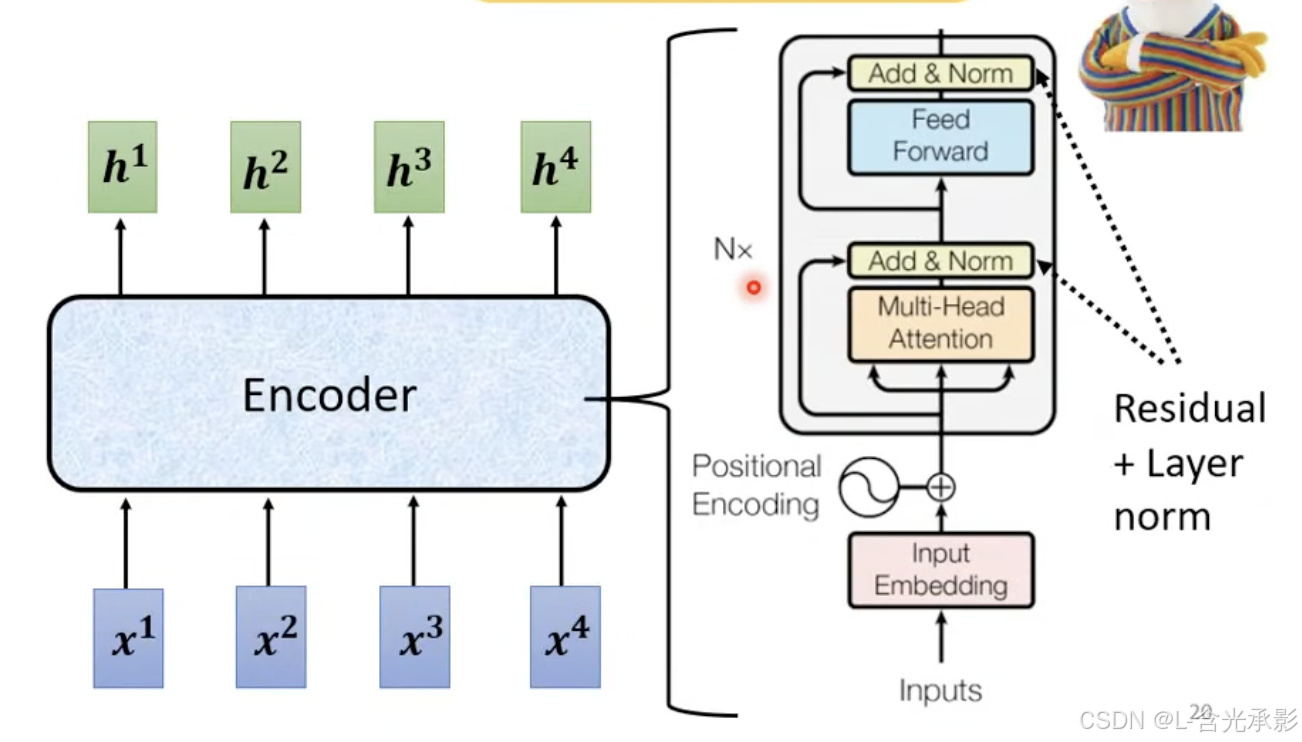
图中的Nx表示循环N次,这也就是说encoder里面有N个相同的Block,而每Block的任务如下:
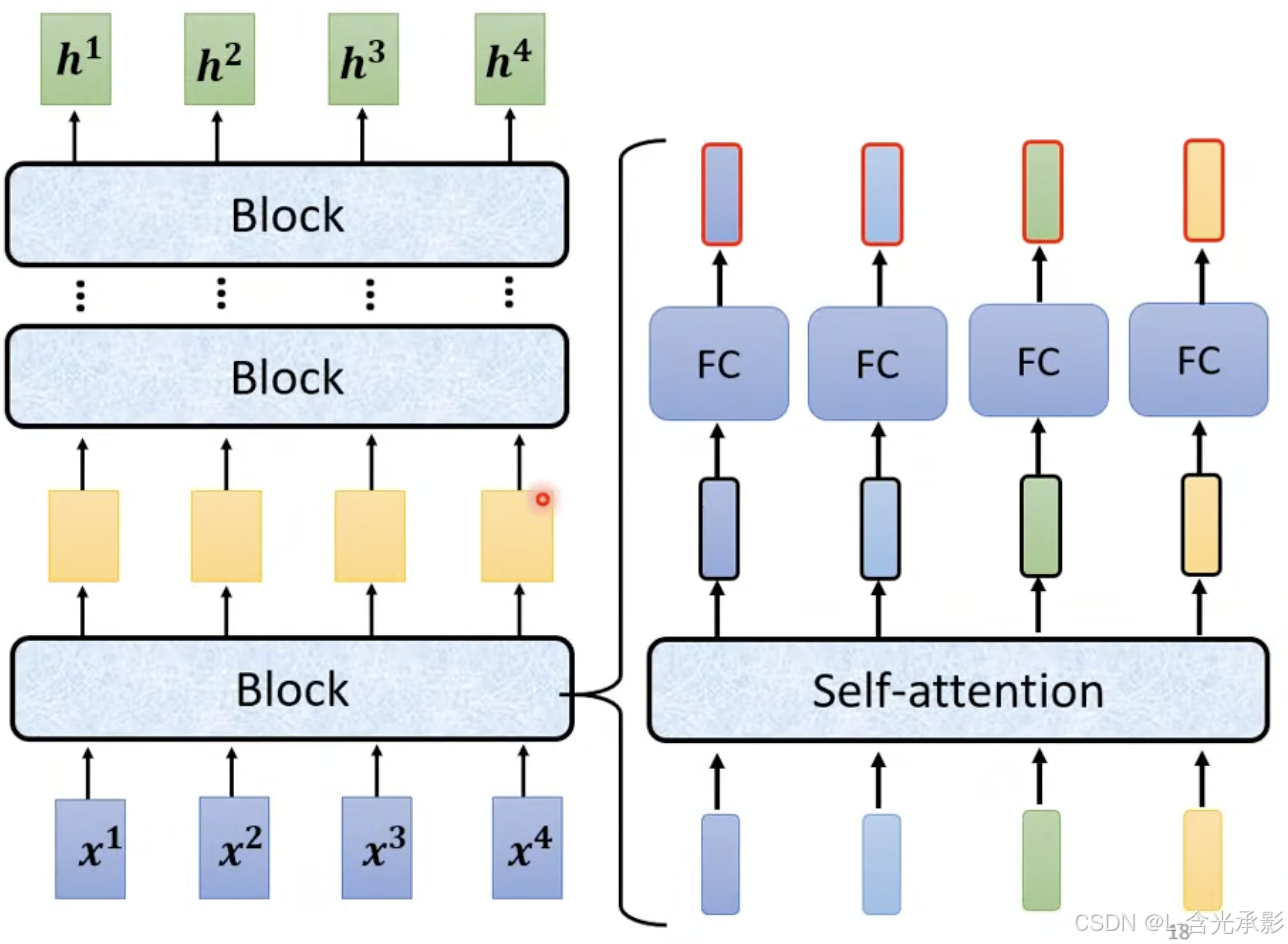
每个Block都接收一组输入向量,通过自注意力机制得到另外一组向量,将得到的向量分别通过全连接层得到一组输出向量 。在原来的Transformer中每个Block的任务更为复杂,如下:
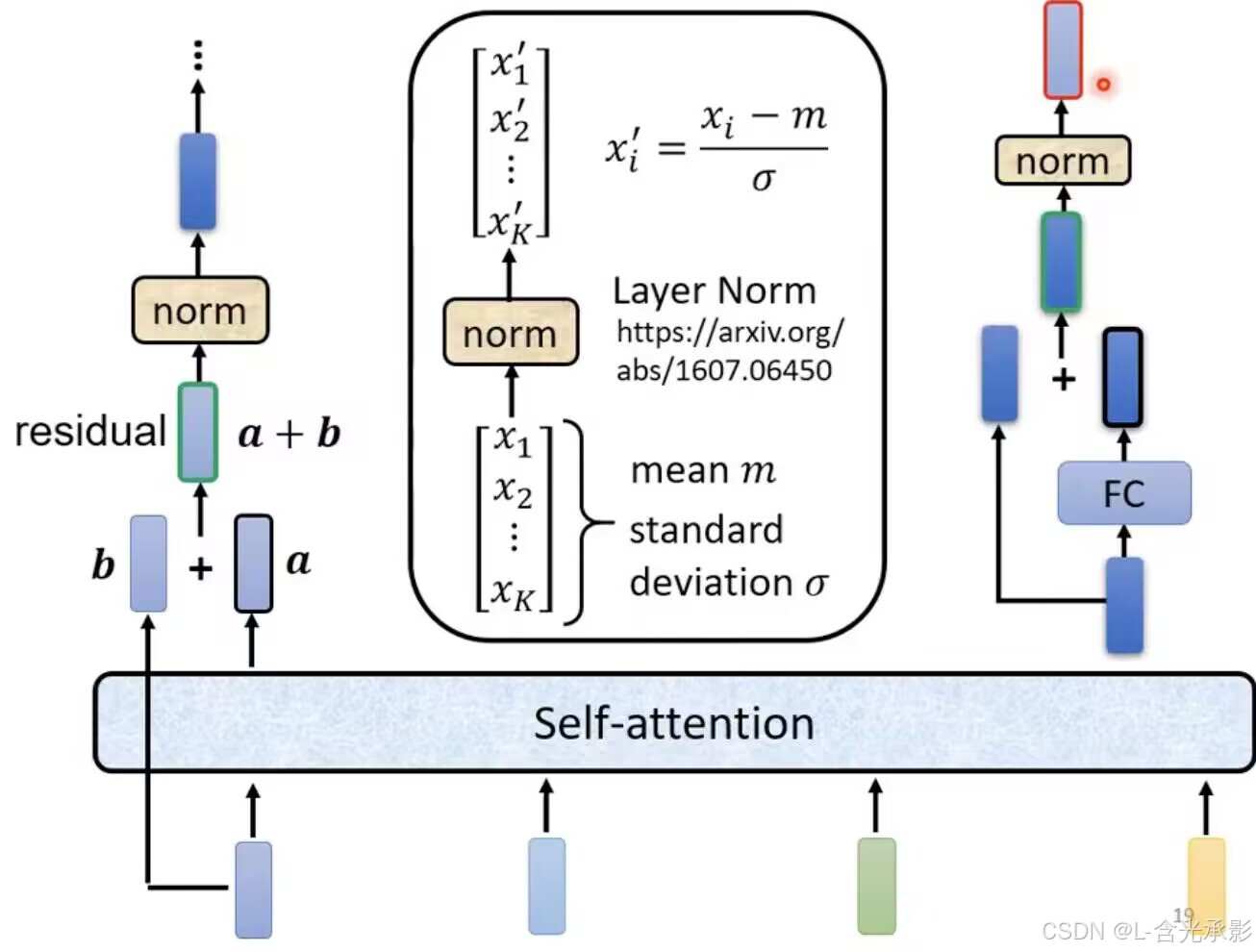
在自注意力层得到向量后,还要加上对应的输入向量(这种方法叫 residual connection),再进行 layer normalization,得到中间向量,中间向量加上其自身通过全连接后的结果,再做一次layer normalization,得到对应Block的对应输入向量的输出向量。在第一个Block的输入中,除了输入序列的编码向量外,还要包含位置编码,以考虑其位置信息。
Transformer的encoder的设计并不一定是最好的,还可以有别的方法。
解码器(decoder)
这里以语音识别为例介绍自回归的解码器(Autoregressive decoder,AT decoder)
自回归解码器(Autoregressive Decoder)是一种解码器架构。它的主要特点是在生成输出序列时,每个时间步的输出是基于之前已经生成的输出序列部分来计算的。也就是说,它假设输出序列的概率分布是一个自回归分布,当前位置的输出概率依赖于前面位置的输出
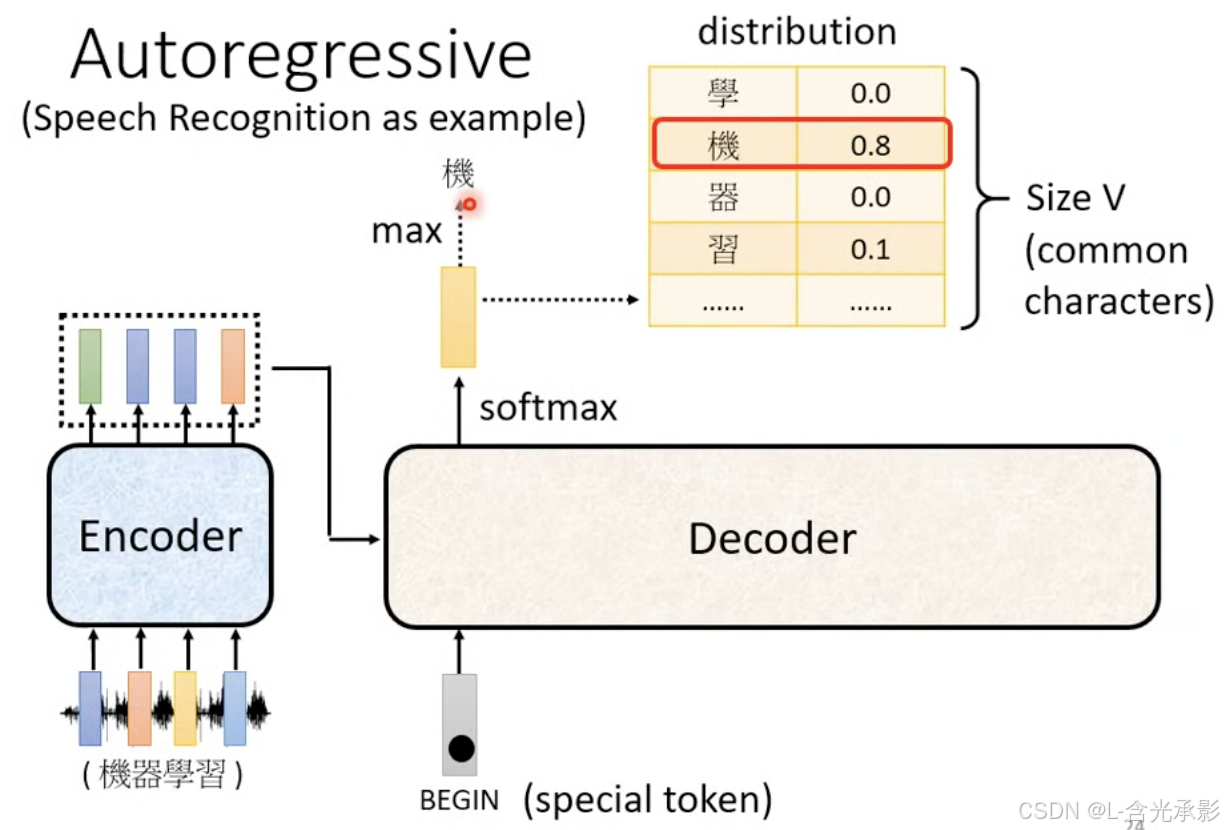
先看推理过程,解码器先获得编码器的输出,并自动获得一个 special token 作为初始输入,以这个输入去预测第一个输出,这里是一个分类问题,就是以初始输入为条件,计算词表(词表里应该包含表示生成结束的special token)中哪一个token 的概率最大,这个 token 就是第一个输出;生成第二个 token 是以第一步的输入和第一步的输出为输入的,同样是计算得到的哪个token的概率大,哪个token就是第二部的输出;往后,每个时间步的输出是基于之前已经生成的输出序列部分来计算的,直到某个时间步的输出是表示结束的special token,此时推理结束。
词表中应当包含能够表示推理开始和结束的 special token,这两个special token可以是相通的,也可以是不同的。
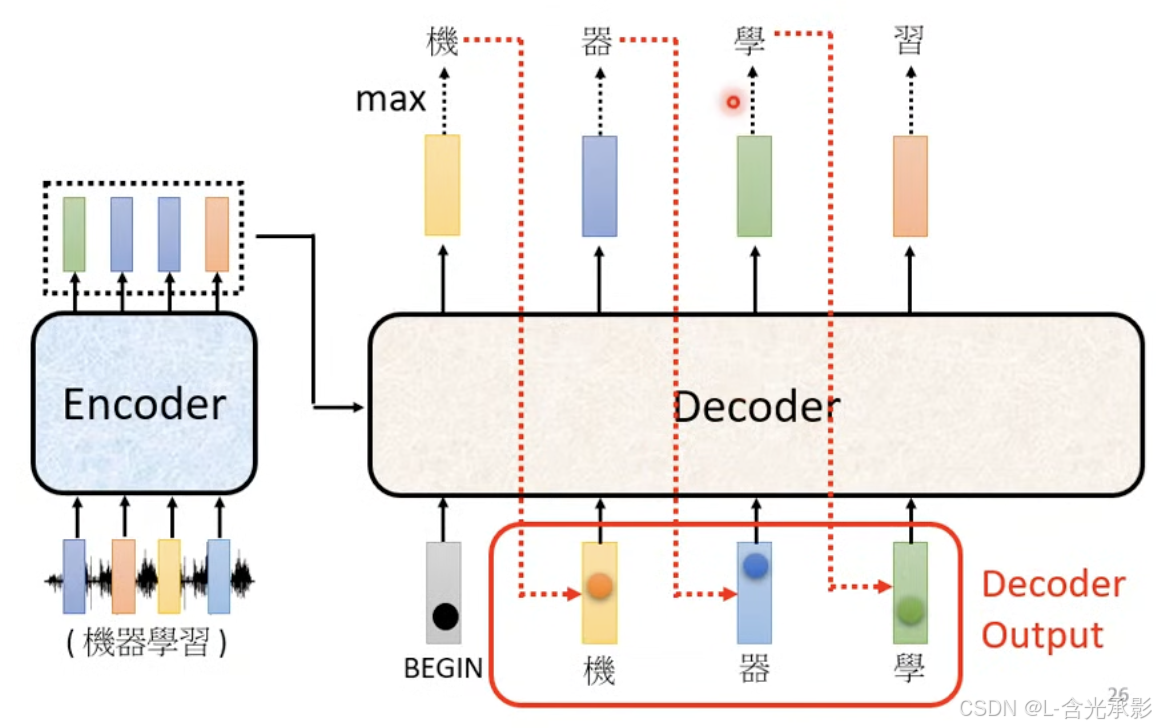
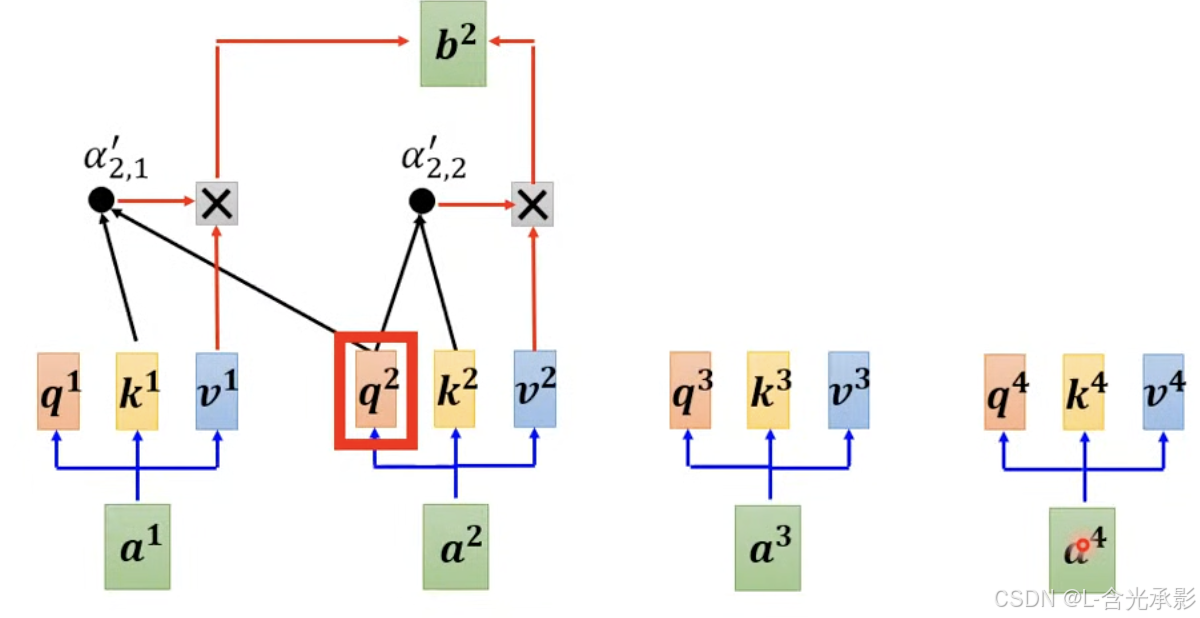
控制推理中 每个时间步的输出都基于之前已经生成的输出序列部分来计算,就需要用到 masked self-attention,举个例子,若要计算第二个预测输出,方法如下:
非自回归的解码器(Non-autoregressive decoder,NAT decoder)
AT decoder是逐个生成 token,而 NAT是一次性生成所有 token。
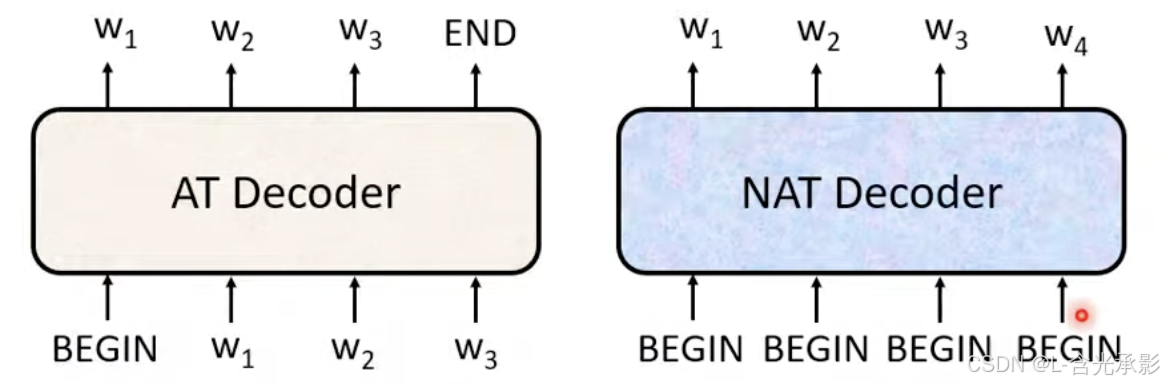
那么,NAT decoder 中,如何确定输出的长度呢 ?
一个方法是,另外用一个预测器来预测输出的长度,然后在 NAT decoder中输入对应长度的 begin special token ;另外一个方法是,给一个很长的 begin special token,这样也会得到一个很长的输出,输出中会有一个 end special token,只保留此 token之前的输出而丢弃后面的输出。
NAT的优点:
相较于 AT ,NAT 生成序列是并行的,一次性生成所有 token,而不像是 AT 只能逐个生成 token;另外,NAT 可以控制输出的长度,以语音合成为例,可以通过控制输出的长度来控制语音的语速。但目前来说,NAT 的效果没有 AT 那么好。
交叉注意力(cross attention)
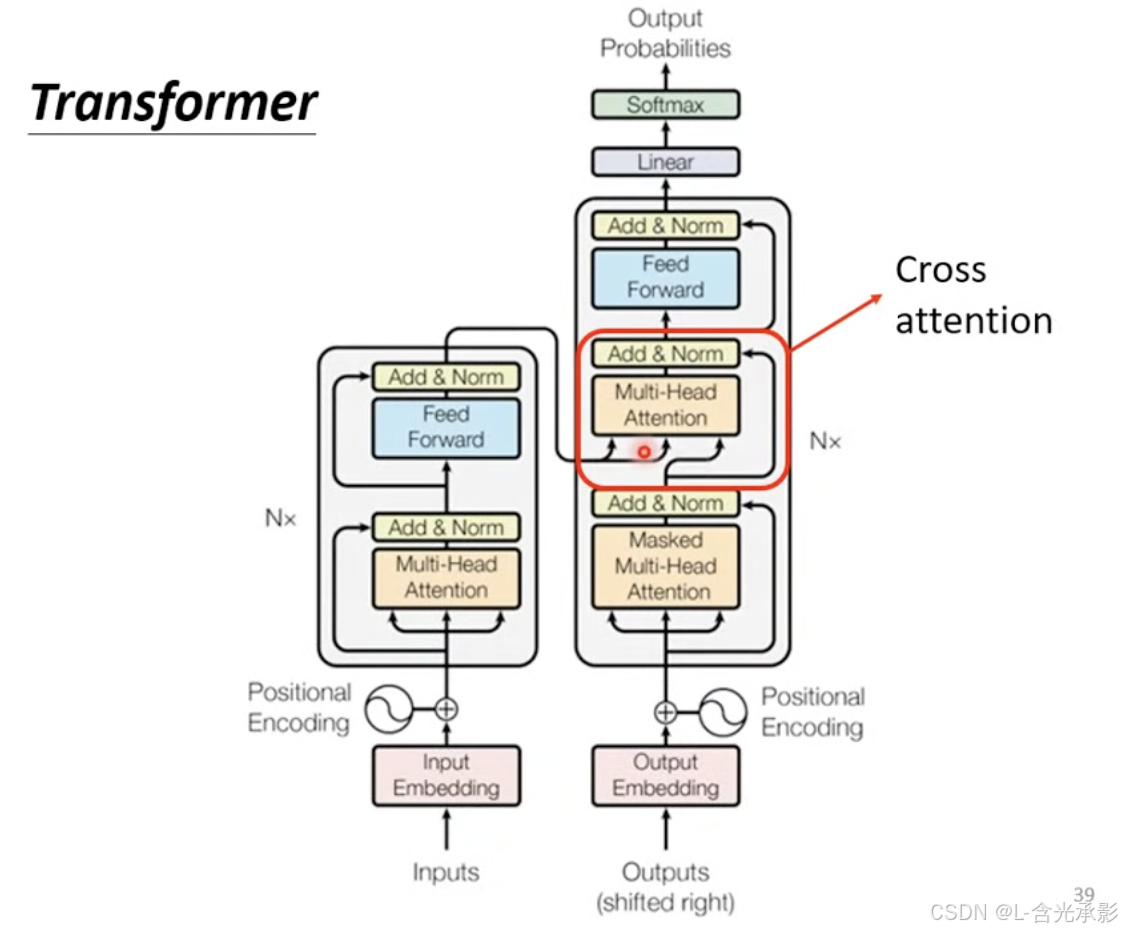
在 Transformer 中,cross attention 是用来连接编码器和解码器的方法。其具体计算方法如下:
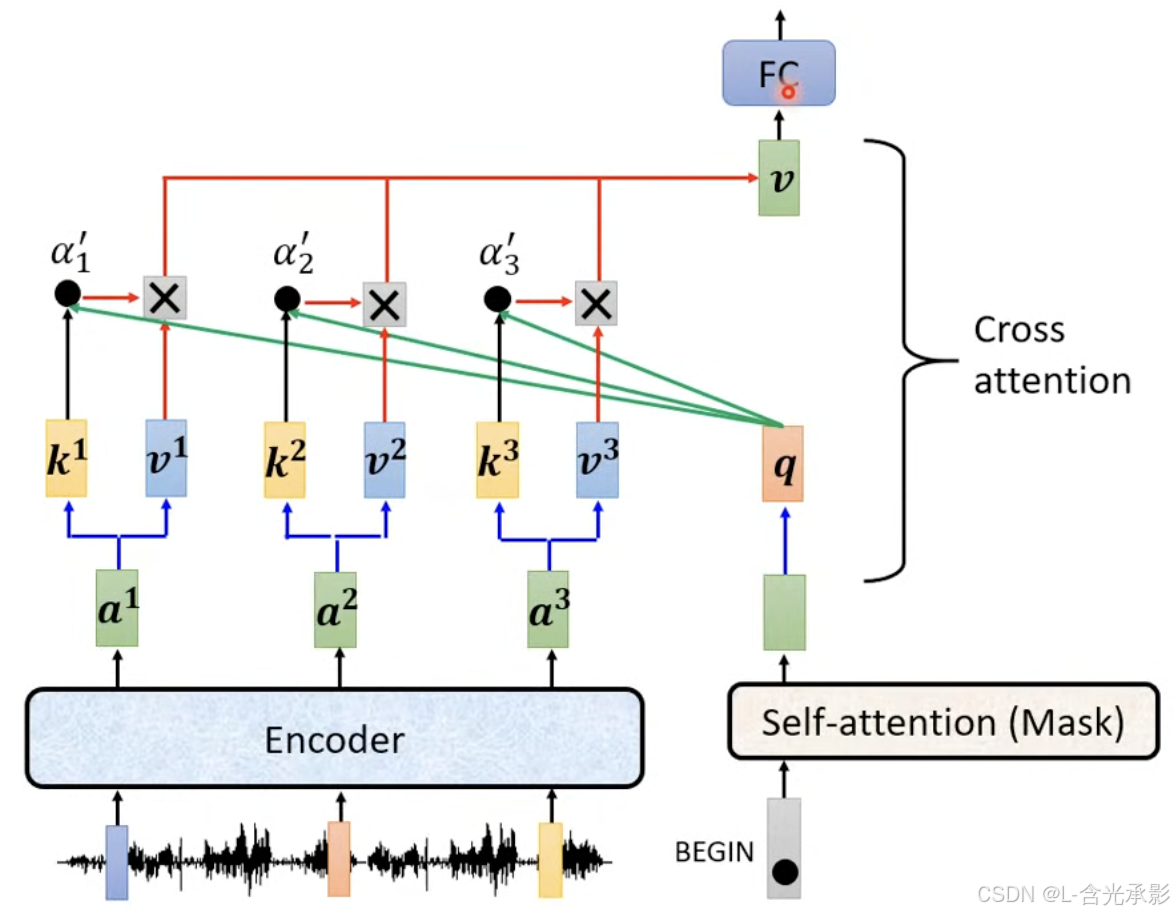
masked self-attention 的输出提供注意力机制中的 q ,而encoder的输出提供 k 和 v ,经过注意力机制的计算后,在经过全连接层得到交叉注意力的输出。
但交叉注意力并不一定要连接encoder的最后一层的输出,也可连接encoder的其他层。可以针对具体任务进行试验得到合适的连接方式。
训练
以上所述均是推理过程,现在还是以语音翻译为例,来学习训练过程。
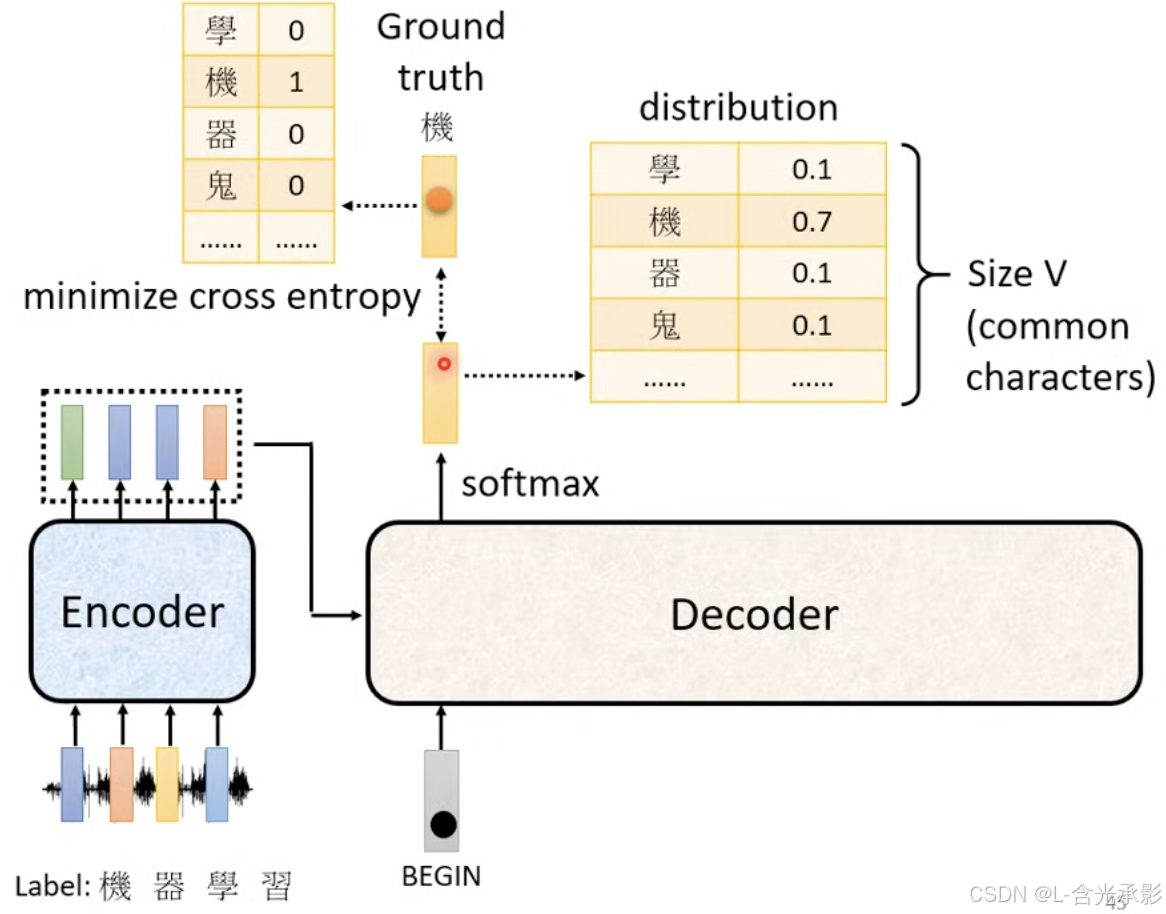
当decoder接收begin输入时,会预测第一个token输出,此时计算其与标签上的第一个token的交叉熵损失(输出和标签都是独热编码形式,输出其实就是一个几率的分布),其实decoder就是做的分类问题。
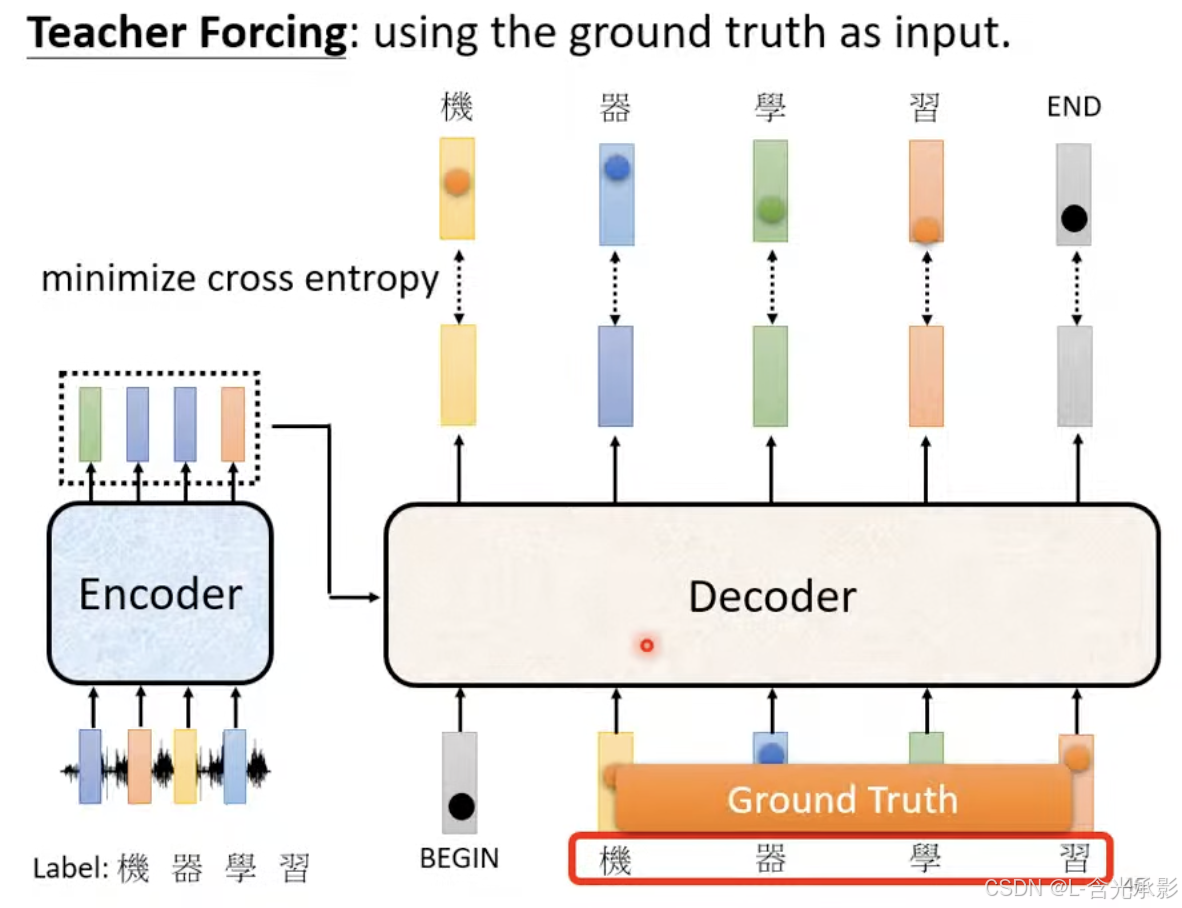
在训练时,会采用 teacher forcing 的方法,给 decoder 进行输入,即预测当前时间步用到前面的输入都是正确的,如预测“学”时,decoder的输入是“begin机器”。对于decoder的每个输出,包括end位置对应的预测输出,都要计算交叉熵损失,训练目标就是使交叉熵损失之和最小。
总结
本周学习了 Transformer 的基本结构,并理解了其训练和推理的基本步骤,也了解了masked self-attention 和 cross attention 的基本计算方法。transformer 的应用非常广泛,下周将继续加强对transformer 的理解。

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









