







深度学习基础
代码练习
1、登录谷歌云盘,创建好工作区域,执行Colab语句,创建张量成功
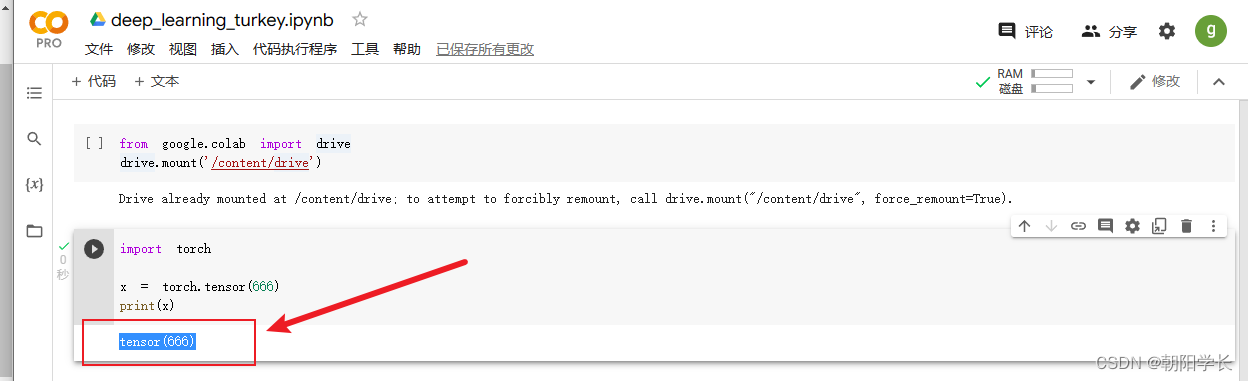
2、torch创建n维全1张量

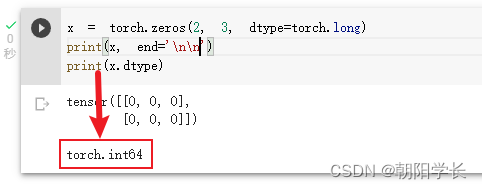
3、dtype指定张量内部的数据类型
4、new_ones基于现有的张量,创建一个新张量,利用dtype,device,size之类的属性信息

5、randn_like利用原有的张量大小,创建一个新的张量,并且填充的为均值为 0,方差为 1的浮点数。

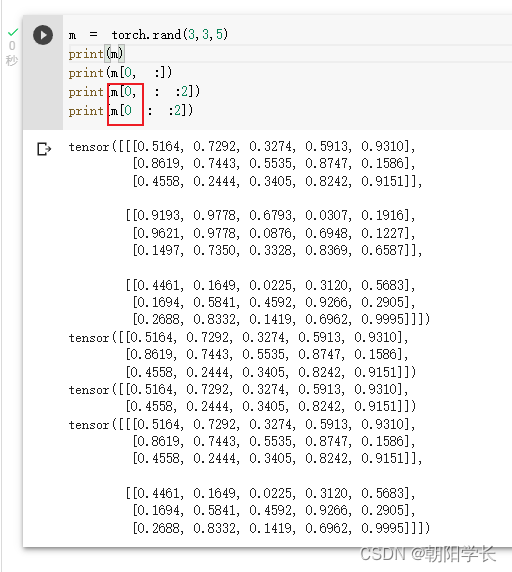
6、size用于返回张量维度大小的方法,未指定维度,则返回保存该维度的int

7、tensor支持下标索引
8、tensor支持切片,注意逗号的用法!
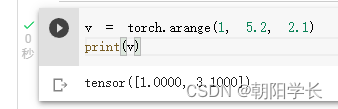
9、arange用于生成[start,end)的1*n张量
10、@符号表示矩阵乘法

11、linspace创建一个指定个数的步长均匀的一维张量

12、cat用于拼接两个tensor

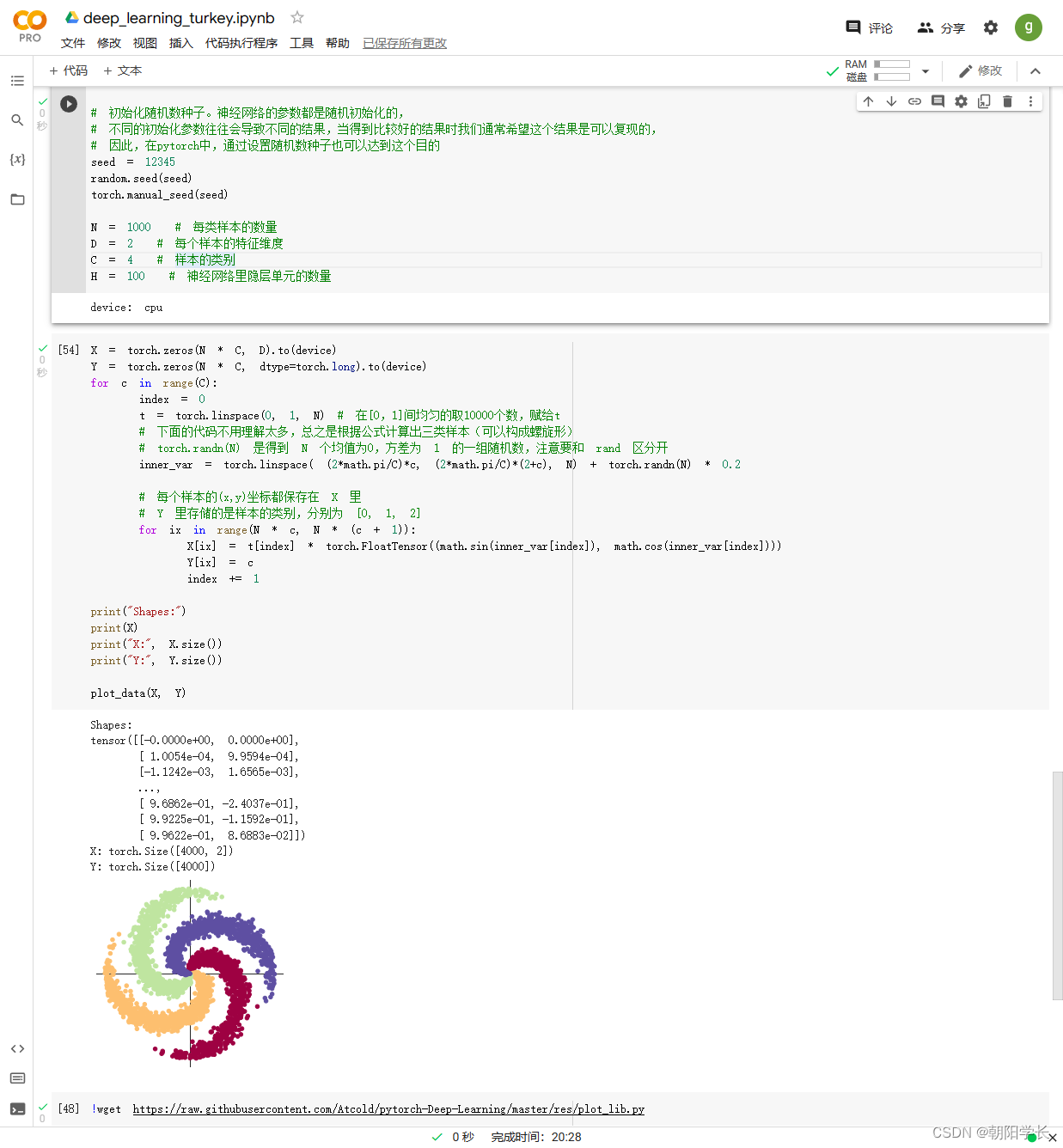
13、获取plot_lib工具函数,构建螺旋型数点
我修改了样本类别数量,改为了4
14、Linear用于构建线性变换,第一个参数为输入样本的大小,第二个参数为输出样本的大小
nn.Linear(D, H)
nn.Linear(H, C) #最后变为想要的种类数
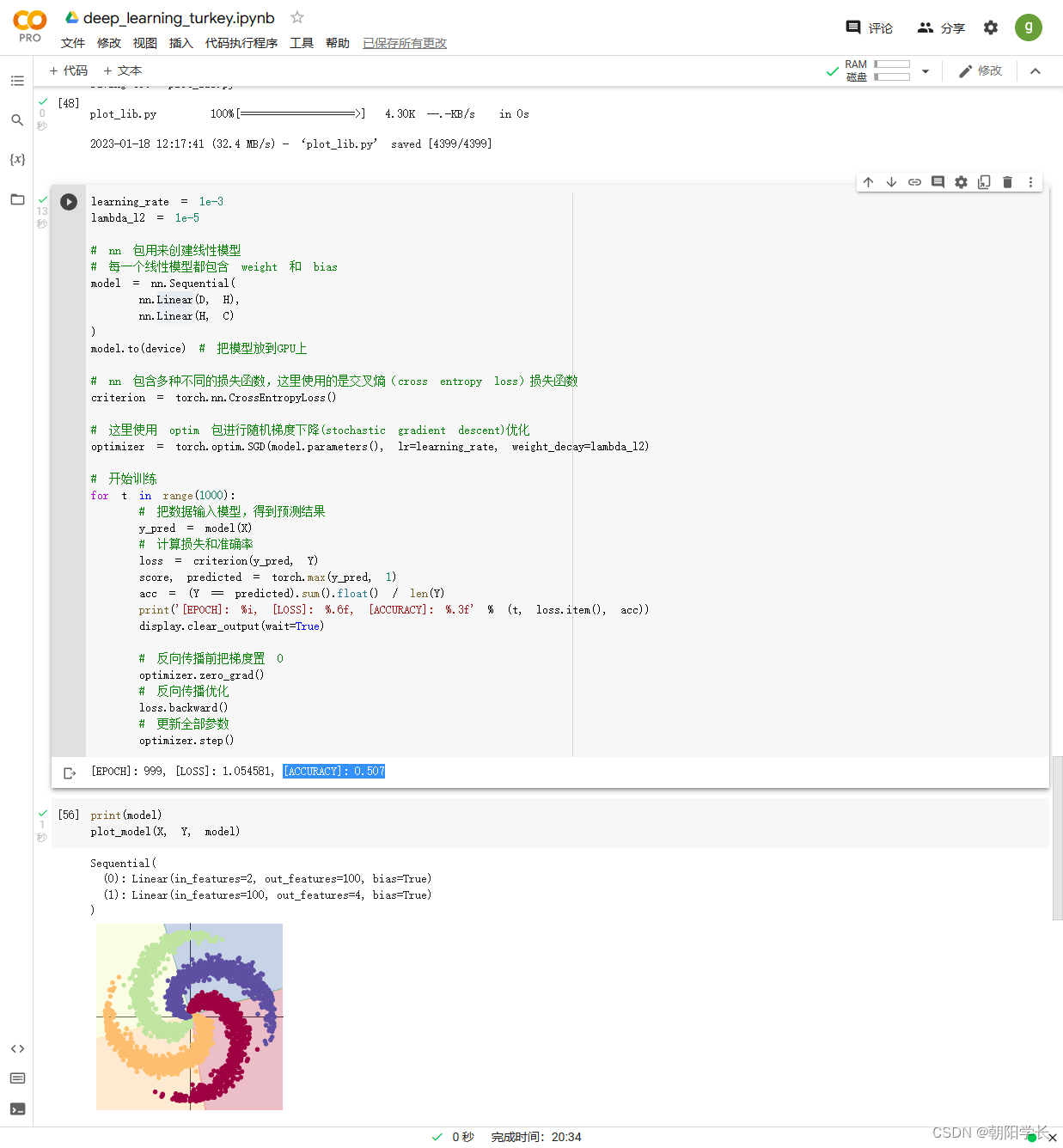
15、构建线性模型并且使用SGD进行梯度下降算法得到的结果图如下,ACCURACY=0.507
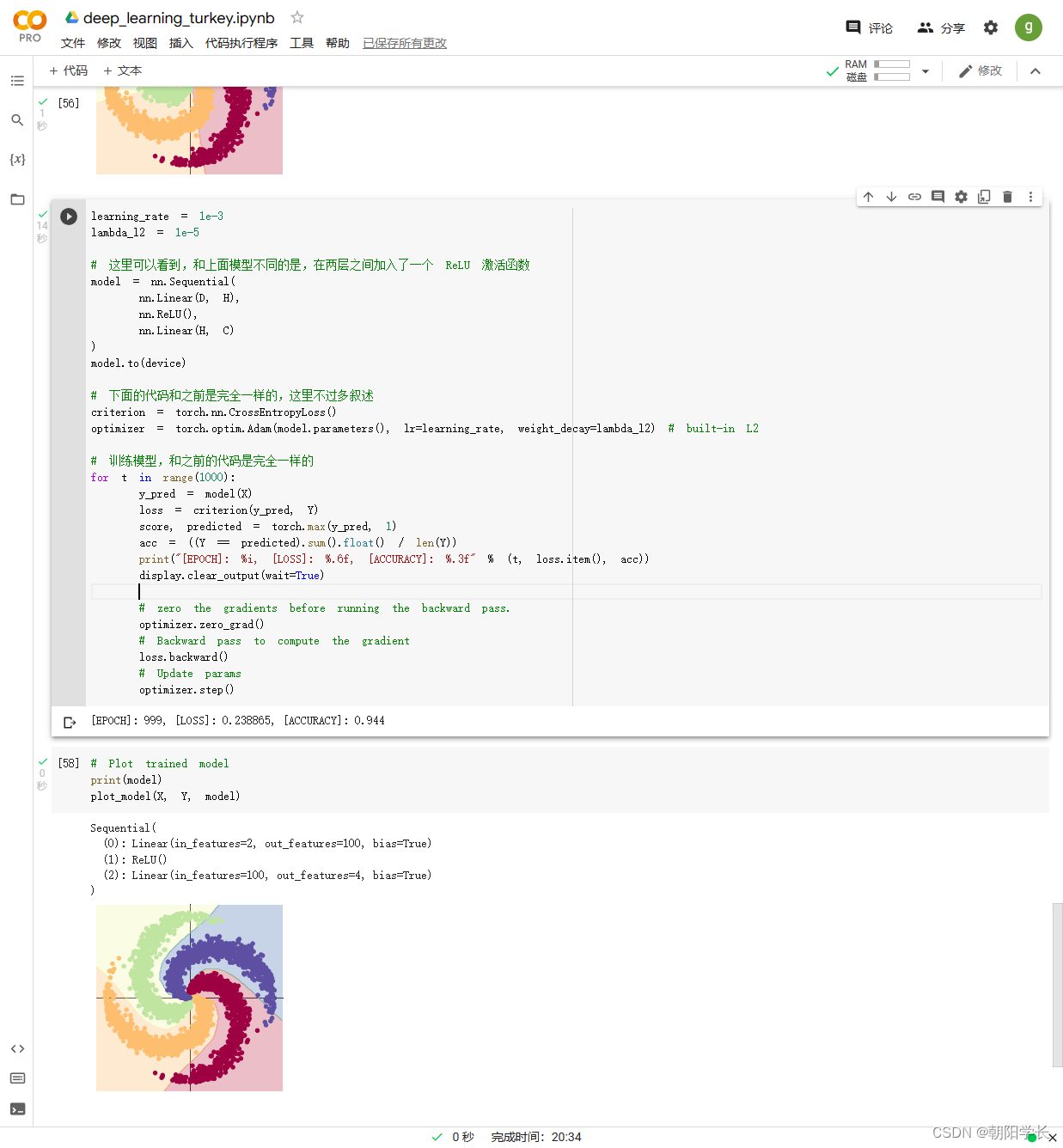
16、构建两层神经网络分类并且使用Adam进行梯度下降算法得到的结果图如下,ACCURACY=0.944
问题总结
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
AlexNet相较于LeNet, 网络更深。
AlexNet使用ReLu替换了LeNet的Sigmoid作为激活函数,验证了其效果在较深的网络中超过了Sigmoid,
成功解决了Sigmoid在网络较深时的梯度消失问题。
AlexNet引入了Dropout用于防止过拟合。保证了在训练数据和测试数据的准确率都较高。
2、激活函数有哪些作用?
激活函数最主要的作用就是用来增加非线性因素的.
如果不使用激活函数, 我们每一层的输入只是在上一层的输出做线性变换, 无论神经网络的深度有多深, 输出都是线性组合,
引入非线性因素之后就可以使得神经网络逼近任何非线性函数, 这样神经网络就可以应用到非线性模型中.
3、梯度消失现象是什么?
梯队消失是指随着隐藏层深度的增加, 神经网络的分类准确率反而下降.
在以梯度下降和反向传播训练人工神经网络中, 每次迭代权重的更新会与损失函数的偏导成正比, 但层数增加时最后一层的变化难以传递在前面的层,
前层不变又会导致后层无法更新, 最后导致神经网络失去调整能力, 甚至可能完全无法训练.
4、神经网络是更宽好还是更深好?
当节点数一致的时候, 忽略梯度消失带来的前提下, 神经网络越深越好.
随着深度提升带来的效益也不是线性的, 应该找到效率最好的深度.
5、为什么要使用Softmax?
Softmax的公式表示如下: S i = e z i ∑ j = 1 K e z j , i = 1 , 2 , . . . , K S_i=\frac{e^{z_i}}{\sum_{j=1}^{K}e^{z_j}},i=1,2,...,K Si=∑j=1Kezjezi,i=1,2,...,K
Softmax主要用于深度学习中的多分类, 它的主要作用是将输出层的数值映射成概率, 各项数值概率和为1.
求解概率为e的指数, 可以把输入的负数变为正数, e的函数曲线呈现递增趋势, x轴很小的变化反映到y轴可以看到明显变化, 它可以把差值大的值拉的更大.
6、SGD 和 Adam 哪个更有效?
SGD和Adam都是用于梯度下降的优化算法, SGD没有动量的概念, 它是从样本中随机抽出一组,训练后按梯度更新一次,
然后再抽取一组,再更新一次, 保持一个单一的学习速率. Adam集成了SGDM的一阶动量以及RMSProp的二阶动量, 做到了计算不同参数的自适应学习速率.
在前期Adam的效率更高, 它适用于解决包含很高噪声或稀疏梯度的问题, 超参数可以很直观地解释,并且基本上只需极少量的调参.
SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点.
2023.7.12日更新
Attention机制
注意力机制是为了让神经网络能具备处理重点特征的处理方式,通过让网络学习权重比的方式更灵活的捕捉全局信息和局部信息之间的联系。它的目的是为了让模型获得需要重点关注的目标区域,并对该部分投入更大的权重,突出显著有用的特征,抑制和忽略无关特征。
【CVPR2018】SENet
Squeeze-and-Excitation Networks.
SENet目的是为了重新得到一个权重矩阵,把初步的特征进行重构(在下图中用不同颜色表示)。它一共有4个步骤,包含了Transformation、Squeeze 、Excitation、Scale。
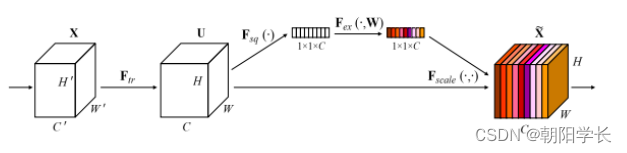
Transformation ( F t r ) (F_{tr}) (Ftr): 在传统的CNN中可以是一个简单的卷积操作。
Squeeze( F s q F_{sq} Fsq): 具体为采用全局平均池化(GAP),将每个通道上的空间信息( H ∗ W H*W H∗W)压缩到了一个数值,最终将维度从 H ∗ W ∗ C H*W*C H∗W∗C变为 1 ∗ 1 ∗ C 1*1*C 1∗1∗C。
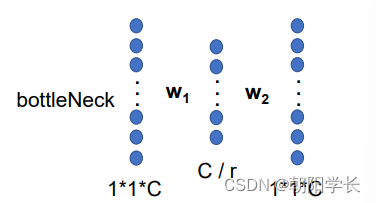
Excitation( F e x F_{ex} Fex): 将输入的矩阵经过两个全连接层(bottleNeck)先经过Relu激活,再经过Sigmoid激活得到的就是我们想要的权重值。在这一步中存在一个超参数r,会影响参数的数量,被作者证实在16的情况下效果最优,见下图。
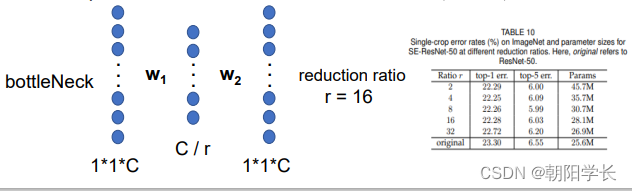
Scale( F s c a l e F_{scale} Fscale): 将权重施加到U的每一个通道上,就完成了特征图的重校准。
【ECCV2018】CBAM
Convolutional Block Attention Module.
SENet是通道域的注意力机制,CBAM是混合域的注意力机制。
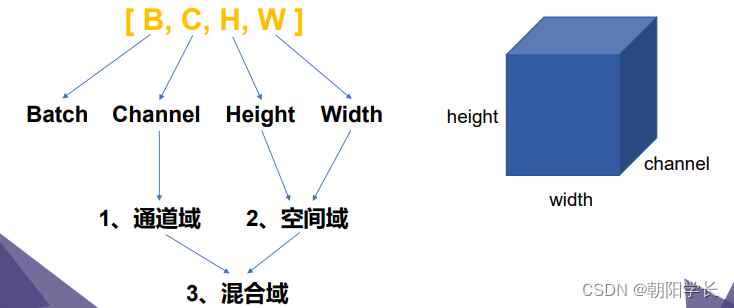
对于通道域来说,本文采用了全局平均池化和全局最大池化代替了SENet中只采用全局平均池化,作者认为仅通过GAP得到的是一个子优化注意力特征,存在更优解。作者通过消融实验论证了他的观点。
具体做法与SENet中的Excitation操作较为类似,得到两个 1 ∗ 1 ∗ C 1*1*C 1∗1∗C的描述算子后,通过两个使用Relu的FC之后直接相加,在使用Sigmoid激活得到通道注意力向量。
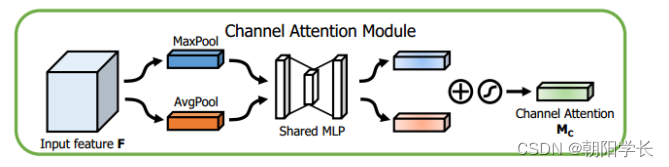
对于空间域来说,本文沿着通道维度同时经过GAP和GMP,通过拼接后得到一个channel为2的描述算子,对它再进行一个卷积核为 7 ∗ 7 7*7 7∗7的卷积操作,在经过Sigmoid最后得到空间注意力向量。
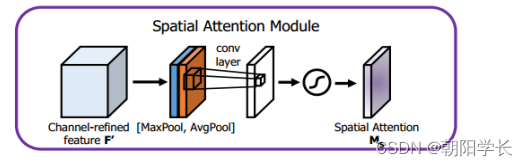
对于混合域的构建,本文消融实验对比了多种通道域与空间域的组合方式(二者并行、先通道后空间串行、先空间后通道串行),得出了先通道域后空间域的串行方式是最优解。
【ICCV2019】SKNet
Selective Kernel Networks
本文提出了一个模拟自适应感受野的方法,通过动态重组特征得到新的特征矩阵。本文主要存在 S p l i t 、 F u s e 、 S e l e c t Split、Fuse 、Select Split、Fuse、Select三种操作。
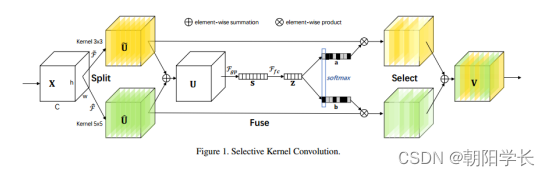
Split: 对于给定的输入X,通过 3 ∗ 3 3*3 3∗3和 5 ∗ 5 5*5 5∗5两种大小的卷积核进行组/深度可分离卷积,会得到两个特征图。
Fuse: 对于Split得到的两个特征图进行相加后,通过全局平均池化得到长度为channel的全局信息s,s经过FC层压缩后得到向量z。这个步骤就像是SENet中Excitation操作的前面半步。
Select: 通过z与最开始的两个特征图进行softmax归一化可以得到新的两个特征图,最终将特征图进行加法后得到最终的特征图。
【CVPR2019】DANet
Dual Attention Network for Scene Segmentation
作者提出了一种基于混合域的注意力机制用于完成场景分割的问题。作者认为在特征图中任何两个现有的相似特征位置可以互相贡献提升,而不管它们之间的距离。网络结构如下图:
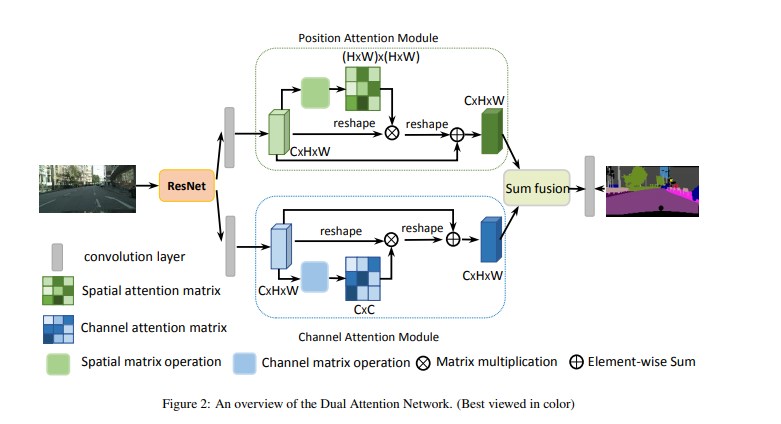
对于空间注意力模型来说,对于输入的特征图A分别通过3个卷积层得到3个特征图 { B , C , D } ∈ R C × H × W \{B,C,D\}\in R^{C\times H\times W} {B,C,D}∈RC×H×W。
- 将B,C都reshape为 R C × N , N = H × W R^{C\times N},N=H\times W RC×N,N=H×W,然后将B与C的转置相乘,再通过softmax得到 S ∈ R N × N S\in R^{N\times N} S∈RN×N。
- 将D reshape为 R C × N R^{C\times N} RC×N与S的转置相乘,得到的结果是 R C × H × W R^{C\times H\times W} RC×H×W。再乘以一个自适应学习的尺度系数 α \alpha α,初始化为0逐渐分配到更大的权重。最后与A相加得到输出E。
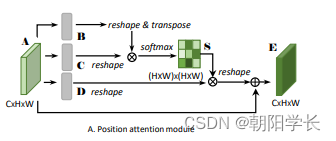
值得注意的是 S j i = e x p ( B i C j ) ∑ i = 1 N e x p ( B i C j ) S_{ji}=\frac{exp(B_iC_j)}{\sum_{i=1}^Nexp(B_iC_j)} Sji=∑i=1Nexp(BiCj)exp(BiCj),S相当于一个attention它的每一行计算的是所有像素与某个像素之间的依赖关系,softmax之后它的值越大越可信,作者通过这样的方式忽略了特征图中的距离问题。
与此类似的还有通道注意力模型,它的结构如下图:
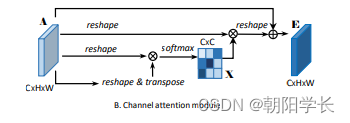
最后做个总结就是:作者提出了一种用于场景分割的双注意网络(DANet),该网络利用自注意机制自适应地融合局部语义特征。同时,作者引入了Position attention module 和 Channel attention module 去捕获空间和通道维度上的全局依赖关系。
【CVPR2020】ECA-Net
Efficient Channel Attention for Deep Convolutional Neural Networks
作者改进了SENet中的Excitation操作,在SENet的Excitation中通过了两个FC层进行注意力的计算,然后通过一个超参数r控制了网络参数大小,所以存在一个先降维再升维的过程。ECANet的作者就认为这样迂回的方法破坏了通道与注意力权重之间的直接对应关系。
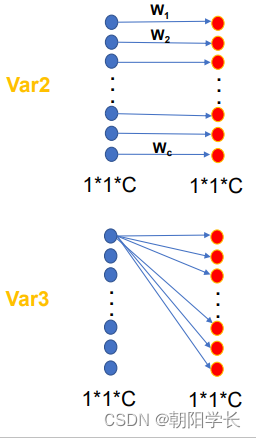
作者采用了三种变体来验证他的思想,分别是SE-Var1、SE-Var2、SE-Var3。
SE-Var1: 没有参数,但是性能优于Besiline, 证明了通道注意力机制的确有效。
SE-Var2: C C C个参数,但是性能优于SE, 证明了通道与权重的直接连接很重要。
SE-Var3: C 2 C^2 C2个参数,性能仍然优于SE, 证明了单FC层的跨通道交互比维度削减效果好。
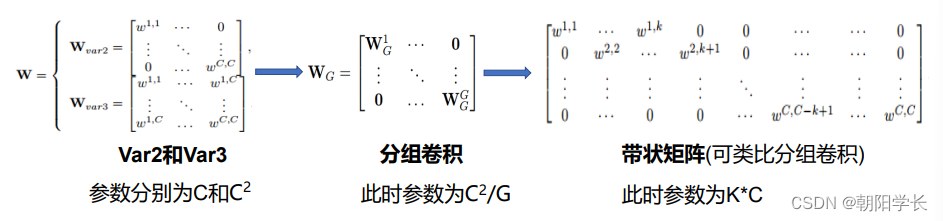
然后作者发现var3方法虽然性能优于var2但是参数量大大增加。var2方法可以写成一个对角矩阵的卷积形式,var3方法可以写成一个二维矩阵的卷积形式,那么分组卷积的方法就被作者考虑,但是准确率却不够高,原因是分组卷积之后通道之间没有交互,导致了效果不好,所以作者选择了一个滑动窗口的卷积形式,这样通道之间就有交互了,也就是一维卷积的卷积形式。
这时还需要考虑卷积核的大小K如何取值,随着网络的加深图像的channel是在二的幂次增大的,所以作者给k找了一个一次函数映射 C = ϕ ( K ) , ϕ ( K ) = r ∗ K − b C=\phi(K),\phi(K)=r*K-b C=ϕ(K),ϕ(K)=r∗K−b。其中 r = 2 , b = 1 r =2 ,b = 1 r=2,b=1,k为计算出来临近的奇数值。
【CVPR2021】CANet
Coordinate Attention for Efficient Mobile Network Design
作者指出在CBAM中存在长程依赖问题没用解决,在SENet中没有考虑空间位置信息,所以作者提出了一种基于Coordinate Attention的方法,将CBAM中的Spatial Attention切割出了H和W两个维度上的注意力。网络结构如下图:
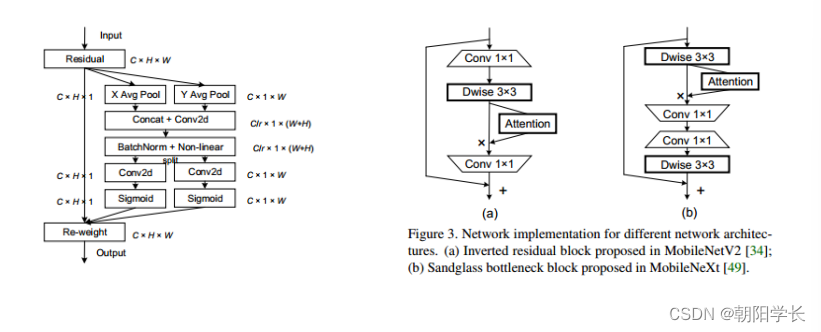
Coordinate Information Embedding: 给定一个输入 F ∈ R H × W × C F\in R^{H\times W\times C} F∈RH×W×C, 将全局池化分为两步操作(一对1D池化),即用两个池化核(H,1)和(1,W)沿着特征图的两个不同方向进行池化,得到两个嵌入后的信息特征图。在对Coordinate操作时可以忽略channel这个维度,等价于将一个二维的压缩成了一维的。
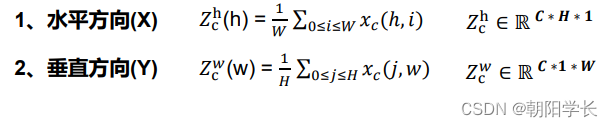
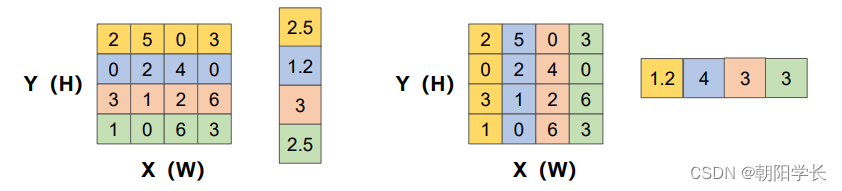
Coordinate Attention Generation: 将得到的两个嵌入特征图 Z c h Z_c^h Zch和 Z c w Z_c^w Zcw沿着空间维度进行 拼接,经过 1 ∗ 1 1*1 1∗1卷积变换后激活。随后沿着空间维度进行Split操作得到两个分离的特征图, 再对它们进行transform和sigmoid,最后得到了注意力向量 g h g^h gh和 g w g^w gw,详细描述如下:
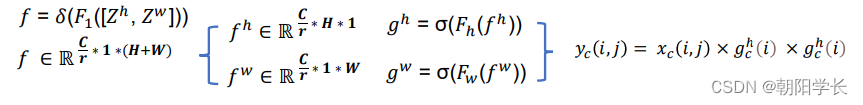














 4237
4237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









